
Einführung
Heute, in der Welt der LLMs (Large Language Models) und KI-Agenten, sind die Formate, die wir zum Senden strukturierter Daten verwenden, wichtiger denn je. Hier kommt TOON (Token-Oriented Object Notation), ein aufkommendes Serialisierungsformat, das verspricht, den Token-Verbrauch zu reduzieren und gleichzeitig Struktur, Lesbarkeit und Schemabewusstsein zu bewahren. Aber was genau ist TOON, und könnte es JSON in LLM-basierten Workflows tatsächlich ersetzen? In diesem Artikel untersuchen wir das Design von TOON, wie es sich im Vergleich zu JSON (und anderen Formaten wie YAML und komprimiertem JSON) schlägt und ob es eine praktische Alternative für reale KI-Agenten ist.
Wünschen Sie sich eine integrierte All-in-One-Plattform, damit Ihr Entwicklerteam mit maximaler Produktivität zusammenarbeiten kann?
Apidog erfüllt all Ihre Anforderungen und ersetzt Postman zu einem wesentlich günstigeren Preis!
Was ist TOON?
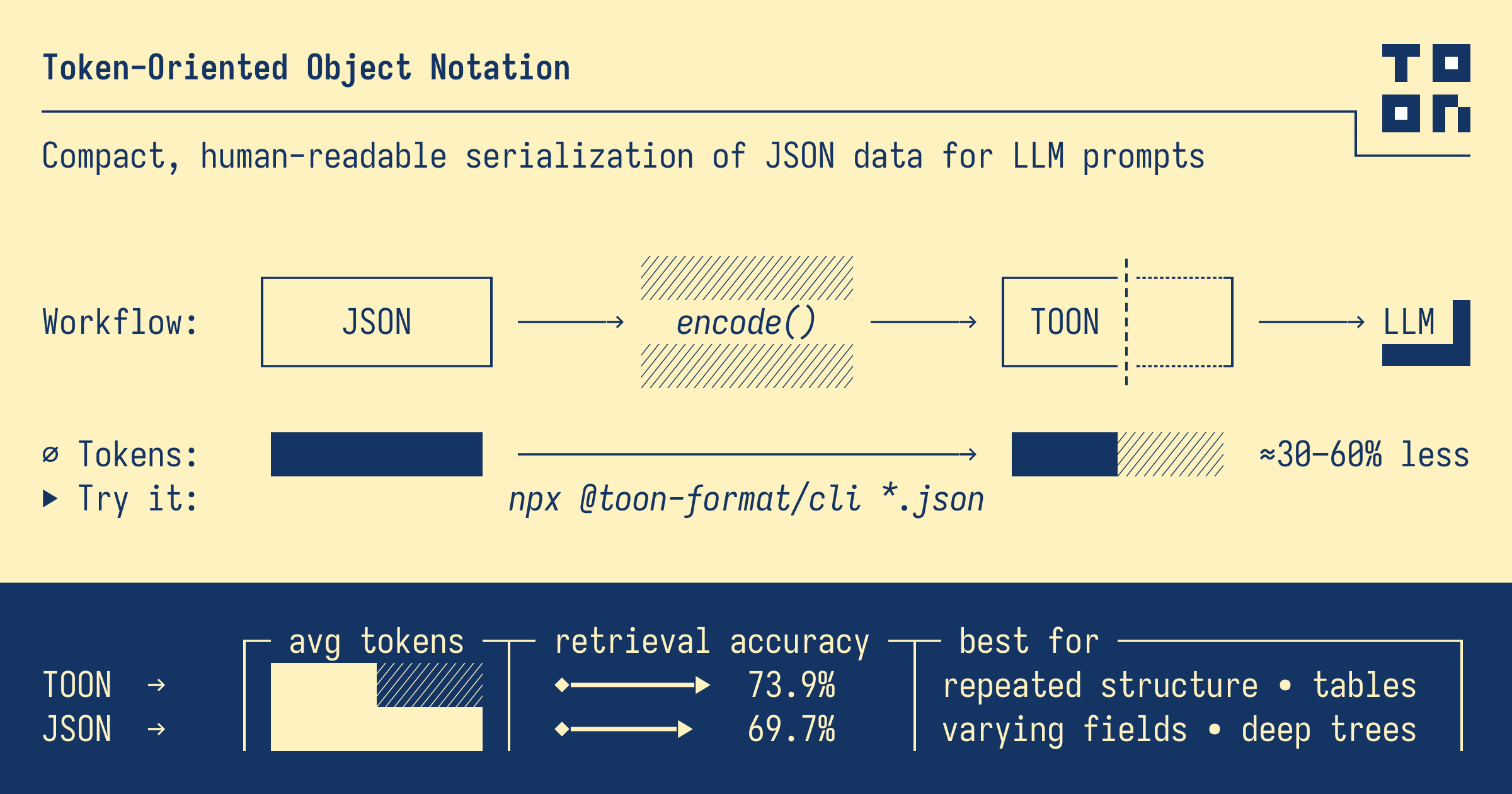
TOON, kurz für Token-Oriented Object Notation, ist ein menschenlesbares, schema-basiertes Serialisierungsformat, das speziell für LLM-Eingaben optimiert wurde. Laut seinen Entwicklern behält es dasselbe Datenmodell wie JSON bei – Objekte, Arrays, primitive Typen – verwendet aber eine kompaktere Syntax, die darauf ausgelegt ist, die Anzahl der Tokens beim Einspeisen in Modelle zu minimieren.
Hauptmerkmale von TOON sind:
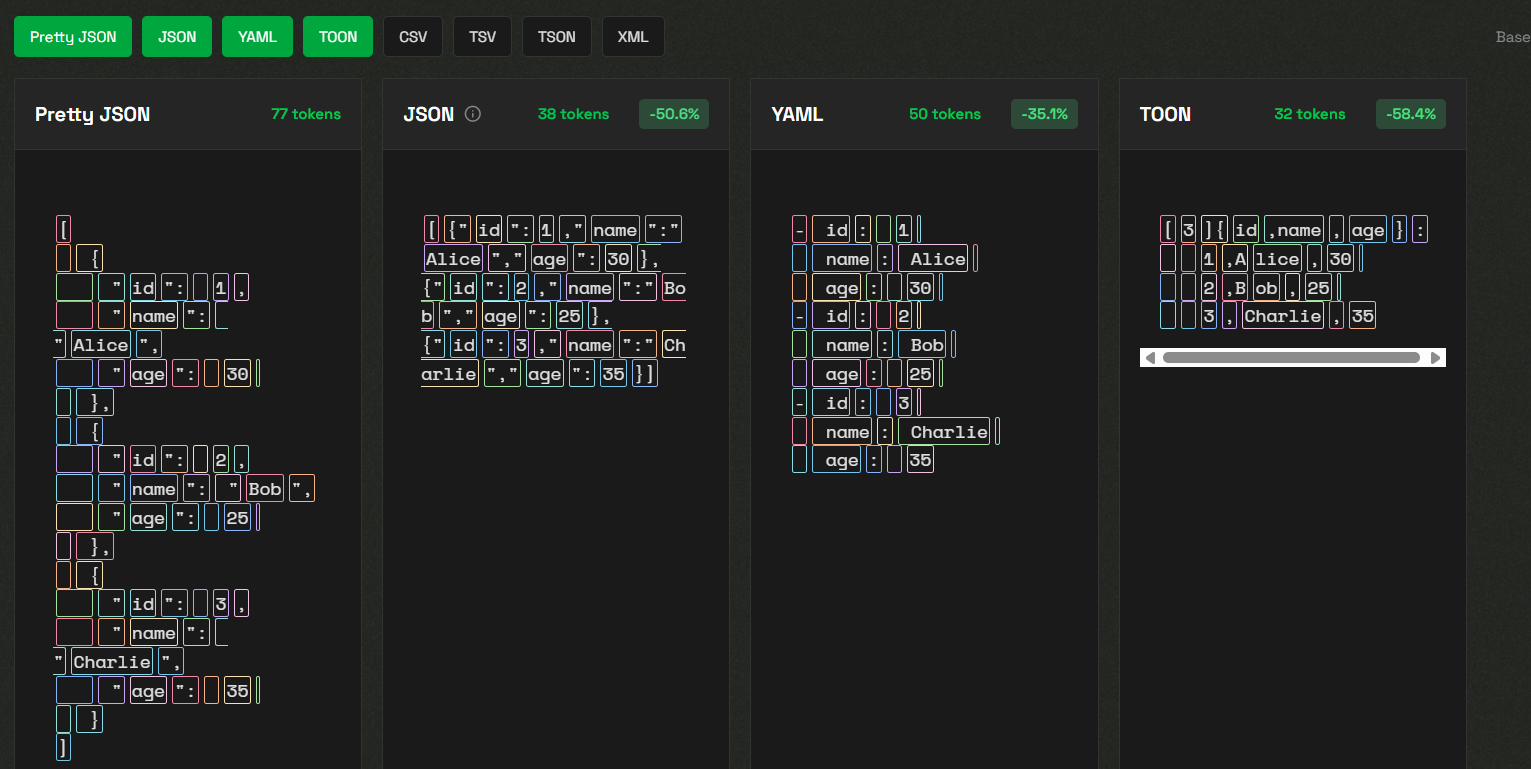
- Token-Effizienz: TOON verwendet oft 30-60 % weniger Tokens im Vergleich zu schön formatiertem JSON für große, gleichförmige Arrays.
- Schema-basierte Definitionen: Es definiert explizit Array-Längen (z. B.
users[3]) und Feld-Header ({id,name}), was LLMs hilft, die Struktur zuverlässig zu validieren und zu interpretieren. - Minimale Syntax: TOON entfernt einen Großteil der mit JSON verbundenen Satzzeichen (Klammern, eckige Klammern, die meisten Anführungszeichen) und setzt auf Einrückungen und Kommas, ähnlich wie YAML und CSV.

- Tabellarisches Format für gleichförmige Arrays: Wenn Sie mehrere Objekte mit denselben Schlüsseln haben, verwendet TOON ein kompaktes, zeilenbasiertes Layout (CSV-Stil), das Felder einmal deklariert und dann Werte in Zeilen auflistet.
Im Wesentlichen ist TOON, wie auf GitHub beschrieben, kein neues Datenmodell – es ist eine Übersetzungsschicht: Sie schreiben Ihre Daten in JSON oder nativen Datenstrukturen und konvertieren sie in TOON, wenn Sie sie an LLMs senden, um Tokens zu sparen.
TOON im Vergleich zu JSON, YAML und komprimiertem JSON
Um zu verstehen, ob TOON JSON für LLMs und KI-Agenten ersetzen könnte, ist es hilfreich, es mit anderen gängigen Serialisierungsformaten zu vergleichen, einschließlich YAML und komprimiertem JSON.
JSON
- Vertrautheit: JSON ist allgegenwärtig und wird von nahezu jeder Programmiersprache, Bibliothek und API unterstützt.
- Ausführlichkeit: JSON enthält viele strukturelle Zeichen – Anführungszeichen, geschweifte Klammern, eckige Klammern –, was die Token-Anzahl erhöht, wenn es in LLM-Prompts verwendet wird.
- Kein Schemabewusstsein: Standard-JSON kommuniziert Array-Längen oder Feld-Header nicht explizit, was potenziell zu Mehrdeutigkeiten führen kann, wenn ein LLM strukturierte Daten rekonstruiert.
[
{
"id": 1,
"name": "Alice",
"age": 30
},
{
"id": 2,
"name": "Bob",
"age": 25
},
{
"id": 3,
"name": "Charlie",
"age": 35
}
]Komprimiertes JSON (oder Minified JSON)
- Kompaktheit: Durch das Entfernen von Leerzeichen, Zeilenumbrüchen und Einrückungen reduziert minifiziertes JSON die Größe im Vergleich zu schön formatiertem JSON.
- Immer noch Token-intensiv: Selbst komprimiertes JSON behält alle strukturellen Zeichen (geschweifte Klammern, Anführungszeichen, Kommas) bei, was den Token-Verbrauch in LLM-Kontexten erhöht.
- Keine strukturellen Schutzmechanismen: Es fehlen die expliziten Schema-Marker, die TOON bietet, sodass LLMs bei der Rekonstruktion von Daten fehleranfälliger sein können.
[{"id":1,"name":"Alice","age":30},
{"id":2,"name":"Bob","age":25},
{"id":3,"name":"Charlie","age":35}]YAML
- Lesbar: YAML verwendet Einrückungen anstelle von geschweiften Klammern, was verschachtelte Daten menschenfreundlicher machen kann.
- Weniger ausführlich als JSON: Da es viele Klammern und Anführungszeichen vermeidet, kann YAML im Vergleich zu JSON einige Tokens einsparen.
- Mehrdeutigkeit: Ohne explizite Array-Längen oder Feld-Header (es sei denn, sie werden manuell hinzugefügt) könnten LLMs die Struktur falsch interpretieren oder an Präzision verlieren.
- id: 1
name: Alice
age: 30
- id: 2
name: Bob
age: 25
- id: 3
name: Charlie
age: 35TOON
- Token-Einsparungen: TOON bietet erhebliche Token-Reduzierungen, insbesondere für gleichförmige Arrays, aufgrund seiner tabellenartigen Notation und minimalen Zeichensetzung. (Aitoolnet)
- Schema-Leitplanken: Explizite Marker (wie
[N]und{fields}) liefern Validierungssignale an LLMs und verbessern die Strukturtreue. - Menschenlesbar: Die Mischung aus Einrückung und CSV-ähnlichen Zeilen macht es recht lesbar, besonders für Entwickler, die mit YAML oder tabellarischen Daten vertraut sind. (Toonkit | Ultimate TOON Format Toolkit)
- Token-Modell-Kompromisse: Bei ungleichförmigen oder tief verschachtelten Daten könnte JSON tatsächlich effizienter sein; die Vorteile von TOON kommen am besten zur Geltung, wenn Daten tabellarisch und gleichförmig sind.
[3]{id,name,age}:
1,Alice,30
2,Bob,25
3,Charlie,35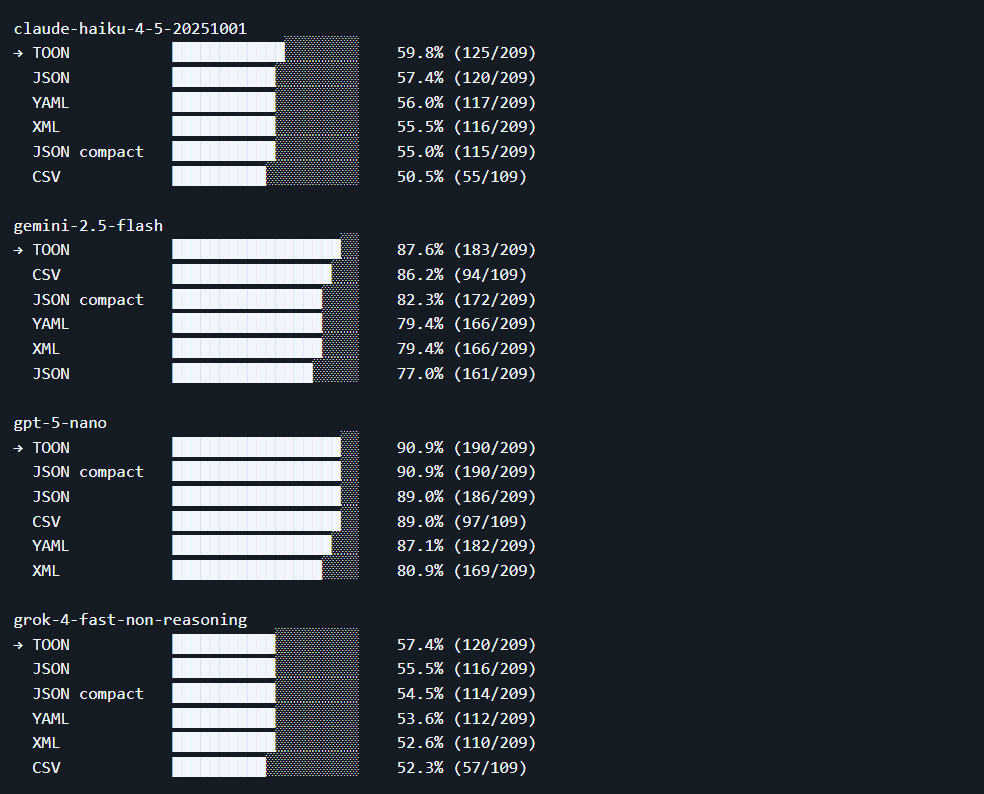
TOON im Kontext von KI-Agenten und LLMs
Warum erforschen Entwickler TOON im Kontext von LLMs und KI-Agenten? Hier sind einige der wichtigsten Motivationen:
- Kosteneffizienz: LLM-APIs berechnen oft pro Token. Durch die Reduzierung des Token-Verbrauchs kann TOON die Eingabekosten erheblich senken.
- Optimierung des Kontextfensters: Kleinere serialisierte Daten bedeuten mehr Platz im Kontextfenster des Modells für andere Inhalte (Anweisungen, Beispiele, Gedankenketten).
- Verbesserte Zuverlässigkeit: Eine explizite Struktur (Array-Länge, Feldnamen) hilft LLMs, das Eingabeformat zu validieren und reduziert Halluzinationen oder falsch platzierte Daten.
- Agenten-Workflows: Für KI-Agenten, die Tool-Aufrufe oder mehrstufige Schlussfolgerungen durchführen, hilft TOON, Konsistenz und Klarheit in strukturierten Daten über die Schritte hinweg zu wahren.
- Nahtlose Konvertierung: Sie können Ihr Backend in JSON beibehalten, es vor dem Senden an das LLM in TOON konvertieren und es später wieder zurückparsen – keine Überarbeitung Ihres Datenmodells.
Einschränkungen und wann TOON möglicherweise nicht ideal ist
Trotz seiner Vorteile ist TOON keine Patentlösung. Es gibt mehrere Szenarien, in denen JSON (oder andere Formate) immer noch überlegen sein könnten:
- Tief verschachtelte oder ungleichförmige Daten: Wenn Ihre Daten viele Ebenen oder inkonsistente Objektformen aufweisen, ist der tabellarische Ansatz von TOON möglicherweise nicht anwendbar, und JSON könnte kompakter oder klarer sein.
- Trainings-Fehlanpassung: Viele LLMs wurden primär mit JSON trainiert, nicht mit TOON. Es besteht das Risiko, dass LLMs TOON-Inhalte falsch interpretieren, wenn sie nicht korrekt aufgefordert werden. Wie einige Benutzer auf Reddit anmerken, könnte das Beibringen eines neuen Formats an das Modell zu Parsing-Fehlern führen.
- Austausch-Erwartungen: Wenn Ihre Daten von traditionellen Systemen, APIs oder Speichern verarbeitet werden müssen, die JSON erwarten, wird TOON möglicherweise nicht direkt akzeptiert.
- Reifegrad der Tools: Obwohl es SDKs in TypeScript, Python und weiteren Sprachen gibt, ist TOON immer noch neuer und weniger universell unterstützt als JSON oder YAML.
Häufig gestellte Fragen (FAQ)
F1. Wofür steht TOON?
Antwort: TOON steht für Token-Oriented Object Notation, ein Format, das entwickelt wurde, um strukturierte Daten in weniger Tokens speziell für die LLM-Eingabe zu kodieren.
F2. Kann TOON alle JSON-Daten darstellen?
Antwort: Ja — Laut ToonParse ist TOON verlustfrei in Bezug auf das JSON-Datenmodell. Es unterstützt dieselben primitiven Typen, Objekte und Arrays wie JSON.
F3. Wie viele Tokens spart TOON ein?
Antwort: Benchmarks auf ToonParse und GitHub legen nahe, dass TOON die Tokens für gleichförmige Arrays um 30–60 % im Vergleich zu schön formatiertem JSON reduzieren kann. Die typische Genauigkeit für die strukturierte Abfrage bleibt dank der expliziten Schema-Marker von TOON hoch.
F4. Werden LLMs das TOON-Format sofort verstehen?
Antwort: Viele LLMs können TOON verstehen, wenn sie korrekt aufgefordert werden (z. B. durch Beispiele mit users[2]{...}:). Das Schemabewusstsein in TOON hilft Modellen, die Struktur zuverlässiger zu validieren. Es kann jedoch eine gewisse Feinabstimmung der Prompts erforderlich sein, wenn man mit Modellen arbeitet, die nicht auf TOON vortrainiert wurden.
F5. Ist TOON ein Ersatz für JSON in APIs und Speichern?
Antwort: Nicht unbedingt. Laut GitHub ist TOON für LLM-Eingaben optimiert. Für APIs, Speicher oder den Datenaustausch, wo JSON der Standard ist, könnten JSON oder andere Formate immer noch geeigneter sein. TOON wird am besten als Übersetzungsschicht in Ihrer LLM-Pipeline verwendet.
Fazit: Wird TOON JSON in LLMs und KI-Agenten ersetzen?
Kurz gesagt: TOON ist eine leistungsstarke und intelligente Ergänzung zu JSON – insbesondere für LLM-gesteuerte Workflows –, aber es ist unwahrscheinlich, dass es JSON vollständig ersetzt.
So sehe ich das:
- Für LLM-Prompts, KI-Agenten und mehrstufige Tool-Orchestrierung bietet TOON echten Mehrwert. Die Token-Einsparungen, Klarheit und Schema-Schutzmechanismen machen es zu einer überzeugenden Wahl, wenn Kosten, Kontextgröße und Zuverlässigkeit eine Rolle spielen.
- Für allgemeine APIs, Datenpersistenz oder Interoperabilität wird traditionelles JSON (oder sogar komprimiertes/minifiziertes JSON) dominant bleiben. JSON ist in nahezu jedem Programmier-Ökosystem tief verwurzelt, und viele Systeme erwarten dieses Format.
- Für Teams, die bereits mit tabellarischen oder gleichförmigen strukturierten Daten arbeiten, könnte TOON eine Win-Win-Situation sein: vor dem Senden an LLMs in TOON konvertieren und dann zur weiteren Verarbeitung wieder in JSON umwandeln.
Letztendlich ist TOON in den meisten Stacks kein vollständiger Ersatz – es ist ein hocheffizientes Werkzeug in Ihrer LLM-Toolbox. Nutzen Sie es dort, wo Sie den größten Nutzen erzielen: in strukturierten Prompts für Agenten, RAG-Pipelines und bei kostenbewusstem LLM-Einsatz.
Fazit
TOON stellt eine durchdachte Entwicklung in der Art und Weise dar, wie wir strukturierte Daten für LLMs und KI-Agenten serialisieren. Durch die Kombination von minimaler Syntax, Schemabewusstsein und menschlicher Lesbarkeit ermöglicht es ein effizienteres, kostengünstigeres und genaueres Prompt-Design. Während JSON der Standard für den Datenaustausch bleibt, scheint der Platz von TOON als spezialisierte Schicht für LLM-Eingaben fest gerechtfertigt.
Wenn Ihr Anwendungsfall das Senden großer, strukturierter Daten an ein LLM beinhaltet – insbesondere wenn diese gleichförmig oder tabellarisch sind –, ist TOON ein Werkzeug, das es wert ist, erkundet zu werden. Achten Sie einfach darauf, wo es möglicherweise nicht glänzt, und verwenden Sie weiterhin JSON oder andere Formate, wenn diese Kontexte auftreten.
Wünschen Sie sich eine integrierte All-in-One-Plattform, damit Ihr Entwicklerteam mit maximaler Produktivität zusammenarbeiten kann?
Apidog erfüllt all Ihre Anforderungen und ersetzt Postman zu einem wesentlich günstigeren Preis!