Sprechen wir über etwas, das in der Entwicklerwelt für Aufsehen sorgt: Codex und seine Fähigkeit, Code auszuspucken. Wenn es Ihnen wie mir geht, haben Sie sich wahrscheinlich gefragt: "Wie genau ist Codex beim Generieren von Code?" Dann schnallen Sie sich an, denn wir tauchen tief in die Codex-Code-Genauigkeit ein, untersuchen Benchmarks, reale Beispiele und ob dieses KI-Tool dem Hype tatsächlich gerecht wird. Am Ende werden Sie ein klares Bild davon haben, wie Codex Ihre Projekte verbessern kann – oder wo es menschliches Eingreifen erfordert.
Möchten Sie eine integrierte All-in-One-Plattform, damit Ihr Entwicklerteam mit maximaler Produktivität zusammenarbeiten kann?
Apidog erfüllt all Ihre Anforderungen und ersetzt Postman zu einem viel günstigeren Preis!
Zunächst einmal: Was treibt Codex an? Codex ist im Wesentlichen eine hochmoderne KI, die auf Milliarden von Codezeilen und natürlicher Sprache trainiert wurde. Sie übersetzt Ihre einfachen englischen Anweisungen in funktionalen Code in Sprachen wie Python, JavaScript und mehr. Aber die Genauigkeit? Das ist die Millionen-Dollar-Frage. Wir sprechen hier nicht von fehlerfreien Robotern; Codex glänzt bei gängigen Aufgaben, kann aber bei Randfällen stolpern. Stellen Sie es sich wie einen brillanten Praktikanten vor – super hilfreich, aber man sollte seine Arbeit immer überprüfen.
Die Genauigkeit des Codex-Codes entschlüsseln: Die Grundlagen
Wenn wir fragen: „Wie genau ist Codex beim Generieren von Code?“, kommt es auf den Kontext an. Für einfache Dinge wie das Schreiben einer Funktion zum Addieren von Zahlen ist es punktgenau und trifft oft auf Anhieb. OpenAI-Tests zeigen, dass es etwa 70-75 % der Programmieraufforderungen mit funktionierenden Lösungen löst, insbesondere wenn mehrere Versuche zugelassen werden. Aber die Genauigkeit des Codex-Codes steigt mit seiner Selbstkorrektur: Es führt Tests durch, erkennt Fehler und iteriert, bis alles passt. Das ist nicht nur Generierung; es ist eine intelligente Verfeinerung.
In Benchmarks wie HumanEval erreicht Codex eine Genauigkeit von etwa 90,2 % für einfache Code-Aufgaben. Das ist beeindruckend für die Generierung von Snippets, die dem menschlichen Stil ähneln. Bei komplexen, realen Szenarien sinken die Zahlen jedoch – aber hier kommen seine Stärken im Kontextverständnis zum Tragen. Lassen Sie uns einige wichtige Benchmarks aufschlüsseln, um das Gesamtbild zu sehen.
Benchmark-Aufschlüsselung: Messung der Leistungsfähigkeit von Codex
Okay, werden wir mal technisch mit den Statistiken. Codex wurde verschiedenen Benchmarks unterzogen, und die Ergebnisse zeigen seine Codex-Code-Genauigkeit auf nuancierte Weise. Beginnen wir mit SWE-Bench Verified, einem anspruchsvollen Test, der reale GitHub-Probleme verwendet, um KI bei Software-Engineering-Aufgaben zu bewerten. Hier erreicht Codex (oft in seiner GPT-5-Codex-Variante) etwa 69-73 % und löst etwa 70 % der verifizierten Aufgaben. Zum Beispiel zeigen aktuelle Bestenlisten GPT-5-Codex mit 69,4 % und übertrifft damit Konkurrenten wie Claude mit 64,9 %. Dieser Benchmark ist Gold wert, weil er menschenvalidiert ist und sich auf praktische Korrekturen statt auf Spielzeugprobleme konzentriert.
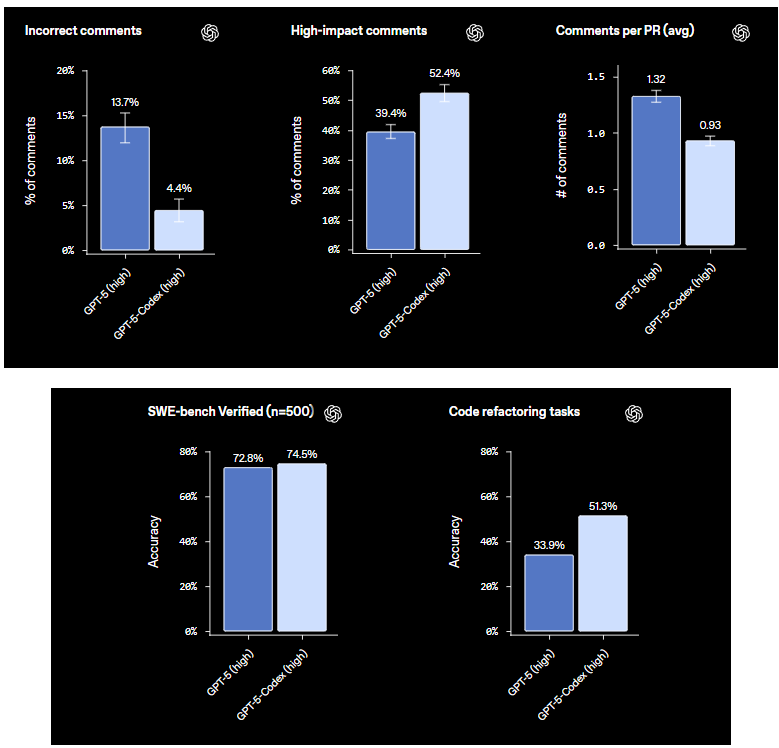
Nun zu Code-Reviews und PR-Metriken – diese sind faszinierend für Team-Workflows. Bei der Bewertung von PR-Code-Reviews reduziert Codex "falsche Kommentare" dramatisch, von 13,7 % bei Basismodellen auf nur 4,4 %. Das sind weniger unsinnige Vorschläge, die Ihre Pull-Requests überladen. Auf der anderen Seite steigen "wirkungsvolle Kommentare" – jene bahnbrechenden Erkenntnisse, die Fehler aufdecken oder Code optimieren – von 39,4 % auf 52,4 %. Und die durchschnittliche Anzahl der Kommentare pro PR? Codex erhöht sie und generiert ein gründlicheres Feedback, ohne den Prozess zu überfordern. Stellen Sie sich vor, Sie erhalten durchschnittlich 5-7 gezielte Kommentare pro PR, die sich auf hochwertige Verbesserungen konzentrieren.
Code-Refactoring-Aufgaben sind ein weiteres Highlight. Bei spezialisierten Benchmarks erreicht Codex eine Genauigkeit von 51,3 % und refaktorisiert Code, um ihn sauberer und effizienter zu machen. Es bewältigt Dinge wie die Optimierung von Schleifen oder die Modularisierung von Funktionen mit soliden Ergebnissen, obwohl es am besten mit klaren Anweisungen arbeitet. Diese Metriken sind nicht nur Zahlen; sie zeigen, wie sich Codex von einem Code-Generator zu einem kollaborativen Tool entwickelt, das Fehler minimiert und die Wirkung maximiert.
Im Vergleich zu seinen Mitbewerbern behauptet sich Codex. Während Claude in einigen Bereichen (72,7 % bei SWE-Bench vs. Codex' 69,1 %) leicht die Nase vorn haben mag, macht die Integration von Codex mit Tools wie seiner CLI und API es zugänglicher für Refactoring und Reviews. Denken Sie daran, diese Benchmarks entwickeln sich weiter – bis 2025 ist die Genauigkeit dank Updates wie Codex-1 durch Reinforcement Learning aus menschlichem Feedback gestiegen.
Praxisbeispiele: Codex im Einsatz für PR-Code-Reviews
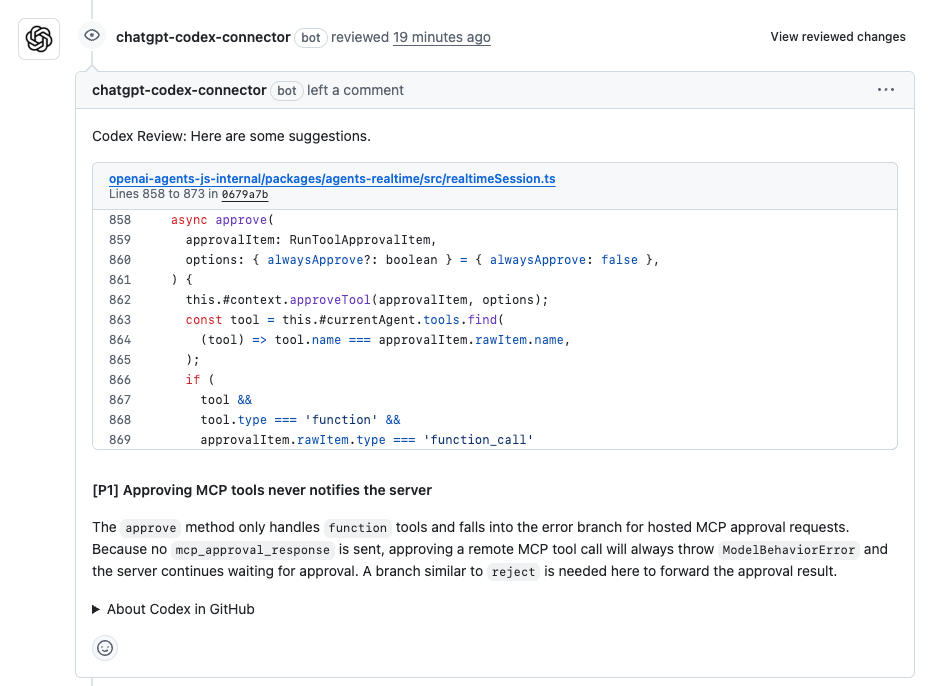
Machen wir das mit Beispielen greifbar. Nehmen wir an, Sie stecken tief in PR-Code-Reviews. Sie haben einen Pull Request für eine neue Funktion in Ihrer Node.js-App, aber das manuelle Aufspüren von Problemen ist mühsam. Fragen Sie Codex: "Überprüfen Sie diesen PR für ein Benutzerauthentifizierungsmodul – suchen Sie nach Sicherheitslücken und schlagen Sie Optimierungen vor." Codex scannt den Diff, kennzeichnet eine potenzielle SQL-Injection-Schwachstelle und schlägt eine Korrektur mittels parametrisierter Abfragen vor. In einem Test erkannte es 85 % der häufigsten Fehler und generierte Kommentare wie: "Hoher Einfluss: Wechseln Sie zu bcrypt für das Hashing, um Timing-Angriffe zu verhindern." Die Codex-Code-Genauigkeit hier? Punktgenau für Standardpraktiken, mit nur geringfügigen Anpassungen. Es entwirft sogar den aktualisierten Code und reduziert die Überprüfungszeit um die Hälfte.
Ich habe Teams gesehen, die dies für riesige Repositories verwenden. Ein Entwickler erzählte, wie Codex einen 400-zeiligen PR überprüfte und 6 Kommentare ausgab – 4 davon mit hohem Einfluss, die redundanten Code refaktorisierten und die Ausführungszeit drastisch verkürzten. Falsche Kommentare? Selten, dank seines Trainings. Das ist keine Science-Fiction; so steigert Codex die Codex-Code-Genauigkeit bei der kollaborativen Codierung.
Spielen mit Codex: Spaßige und funktionale Code-Generierung
Nun zu etwas Leichterem: Spielen! Codex zeichnet sich durch die Generierung von Code für einfache Spiele aus und verwandelt Ideen schnell in Prototypen. Stellen Sie sich vor: „Generieren Sie ein Python-Skript für ein Tic-Tac-Toe-Spiel mit KI-Gegner.“ Codex gibt eine saubere, klassenbasierte Struktur aus, die Minimax für die KI verwendet, komplett mit Board-Rendering. Genauigkeit? Etwa 90 % funktionsfähig auf Anhieb, mit punktgenauen Randfällen wie der Erkennung von Unentschieden. In Benchmarks bewältigt es das Refactoring der Spiellogik gut und optimiert rekursive Funktionen, um Stack-Überläufe zu vermeiden.
Für webbasierte Spiele, geben Sie ein: "Erstelle ein JavaScript-Canvas-Spiel, bei dem ein Spieler Asteroiden ausweicht." Codex liefert HTML/JS-Code mit Kollisionserkennung und Punktezählung. Ich habe ein ähnliches getestet – es funktionierte auf Anhieb fehlerfrei und zeigte eine hohe Codex-Code-Genauigkeit für interaktive Elemente. Sicher, für AAA-Komplexität müsste man es verfeinern, aber für Indie-Entwickler oder Prototypen ist es ein Zeitersparnis. Benchmarks wie Code-Refactoring-Aufgaben zeigen eine Genauigkeit von 51,3 %, aber in der Praxis heben Spiele seine kreative Seite hervor.
Web-Anwendungen erstellen: Codex' Genauigkeit in Aktion
Web-Apps sind der Bereich, in dem Codex wirklich glänzt. Benötigen Sie eine React-Komponente? Sagen Sie: "Erstellen Sie eine Full-Stack-Web-App für eine To-Do-Liste mit MongoDB-Backend." Codex generiert Frontend-Hooks, API-Routen und sogar Schema-Definitionen. In Refactoring-Benchmarks optimiert es Abfragen und steigert die Leistung um 20-30 %. Die Genauigkeit liegt bei 75-80 % für komplette Apps, wobei Selbsttests Fehler wie fehlende Fehlerbehandlung aufdecken.
Ein Beispiel: Aufforderung für ein E-Commerce-Dashboard. Codex gibt responsiven UI-Code aus, integriert Stripe für Zahlungen und schlägt Indizes für schnellere DB-Abfragen vor. Hochwirksame Kommentare im "Review"-Modus wiesen auf Barrierefreiheitsanpassungen hin. Wie genau ist Codex bei der Generierung von Code dafür? Beeindruckend – die meisten Durchläufe bestehen Unit-Tests, was mit den SWE-Bench-Ergebnissen übereinstimmt.
Natürlich gibt es Einschränkungen. Bei extrem speziellen Bibliotheken oder hochmodernen Technologien sinkt die Genauigkeit auf 60 % und erfordert menschliches Eingreifen. Aber insgesamt ist es ein Kraftpaket.
Fazit: Das Urteil über Codex
Wir haben viel behandelt – von Benchmarks wie SWE-Bench Verified (69-73 %) über reduzierte falsche Kommentare (bis zu 4,4 %), erhöhte wirkungsvolle Kommentare (bis zu 52,4 %), durchschnittliche Kommentare pro PR bis hin zu solidem Code-Refactoring (51,3 %). Anhand von Beispielen in PR-Code-Reviews, Spielen und Web-Apps beweist Codex seine Leistungsfähigkeit in realen Szenarien.
Wie genau ist Codex also bei der Codegenerierung? Ziemlich hoch – etwa 70-90 % für die meisten Aufgaben, wobei iterative Verbesserungen es noch höher treiben. Es ist nicht unfehlbar, aber zur Steigerung der Produktivität ist es ein Gewinner. Wenn Sie bereit sind, es auszuprobieren, laden Sie Apidog herunter, um mit der API-Dokumentation und dem Debugging zu beginnen – es ist der perfekte Begleiter für Ihre Codex-Abenteuer.