
ElevenLabs เปลี่ยนข้อความให้เป็นคำพูดที่เป็นธรรมชาติ และรองรับเสียง ภาษา และรูปแบบที่หลากหลาย API ช่วยให้ฝังเสียงลงในแอปพลิเคชัน สร้างระบบบรรยายอัตโนมัติ หรือสร้างประสบการณ์แบบเรียลไทม์ เช่น ตัวแทนเสียง ได้อย่างง่ายดาย หากคุณสามารถส่งคำขอ HTTP ได้ คุณก็จะสามารถสร้างเสียงได้ภายในไม่กี่วินาที
ElevenLabs API คืออะไร?
ElevenLabs API ให้การเข้าถึงโปรแกรมโมเดล AI ที่สร้าง เปลี่ยนแปลง และวิเคราะห์เสียง แพลตฟอร์มนี้เริ่มต้นจากการเป็นบริการแปลงข้อความเป็นคำพูด แต่ได้ขยายไปสู่ชุด AI เสียงเต็มรูปแบบ
ความสามารถหลัก:
- Text-to-Speech (TTS): แปลงข้อความที่เขียนเป็นเสียงพูดพร้อมควบคุมลักษณะเสียง อารมณ์ และจังหวะ
- Speech-to-Speech (STS): แปลงเสียงหนึ่งไปเป็นอีกเสียงหนึ่ง โดยยังคงระดับเสียงและจังหวะเดิมไว้
- Voice Cloning: สร้างสำเนาเสียงดิจิทัลของเสียงใดก็ได้จากไฟล์เสียงที่ชัดเจนเพียง 60 วินาที
- AI Dubbing: แปลและพากย์เนื้อหาเสียง/วิดีโอเป็นภาษาต่างๆ โดยยังคงลักษณะเสียงของผู้พูด
- Sound Effects: สร้างเอฟเฟกต์เสียงจากคำอธิบายที่เป็นข้อความ
- Speech-to-Text: ถอดเสียงจากไฟล์เสียงเป็นข้อความด้วยความแม่นยำสูง
API ทำงานผ่านโปรโตคอล HTTP และ WebSocket มาตรฐาน คุณสามารถเรียกใช้ได้จากทุกภาษา แต่มี SDK อย่างเป็นทางการสำหรับ Python และ JavaScript/TypeScript ที่มาพร้อมกับการป้องกันชนิดข้อมูล (type safety) และการรองรับการสตรีมในตัว
การขอ API Key ของ ElevenLabs
ก่อนที่จะเรียกใช้ API ใดๆ คุณต้องมี API key นี่คือวิธีการขอ:
ขั้นตอนที่ 1: สร้าง บัญชีฟรี แม้แต่แผนฟรีก็ยังมีการเข้าถึง API พร้อมอักขระ 10,000 ตัวต่อเดือน
ขั้นตอนที่ 2: เข้าสู่ระบบและไปที่ส่วน Profile + API Key คุณสามารถหาได้โดยคลิกไอคอนโปรไฟล์ของคุณที่มุมล่างซ้าย หรือไปที่การตั้งค่าสำหรับนักพัฒนาโดยตรง
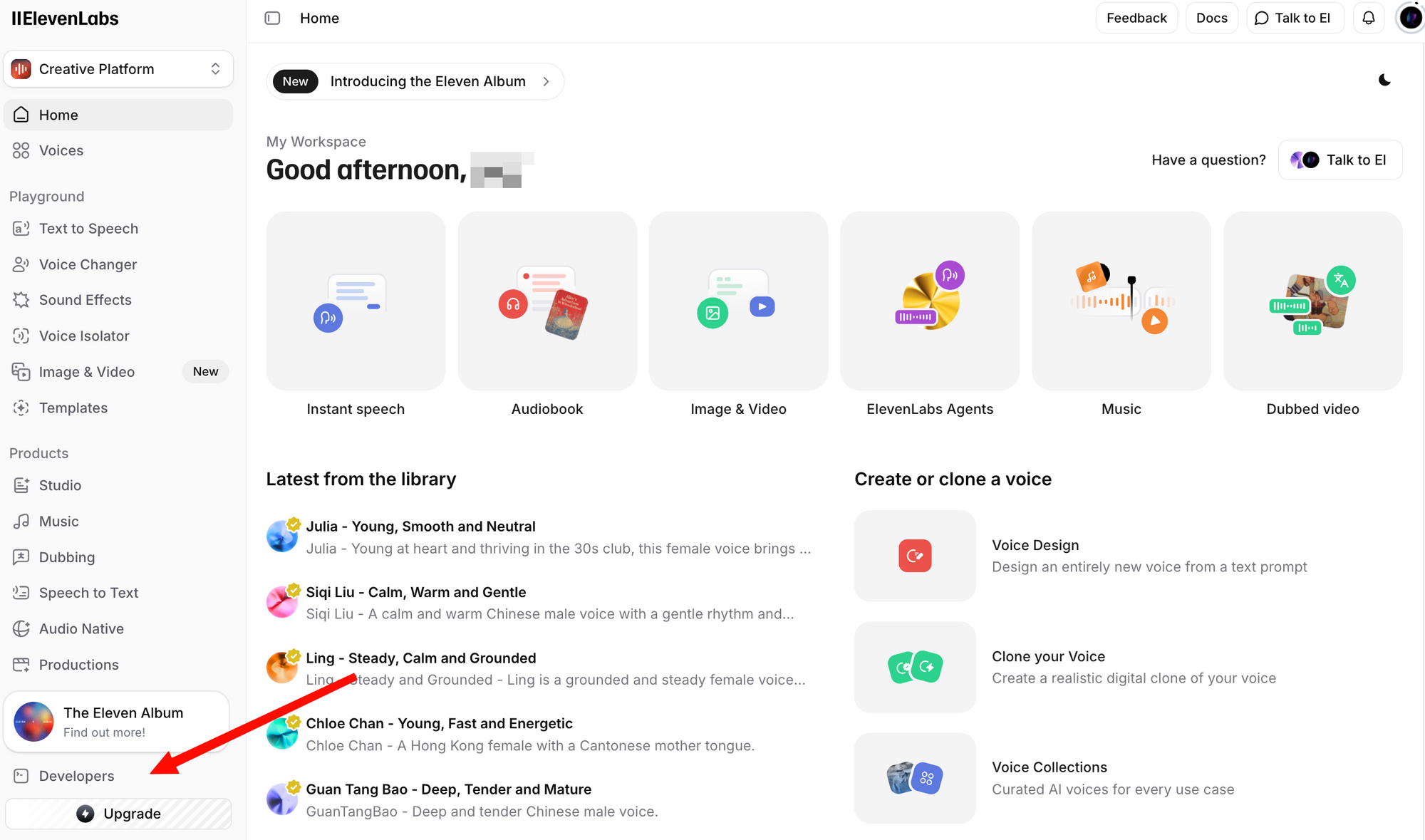
ขั้นตอนที่ 3: คลิก Create API Key คัดลอกคีย์และจัดเก็บไว้ในที่ปลอดภัย คุณจะไม่สามารถเห็นคีย์เต็มได้อีก
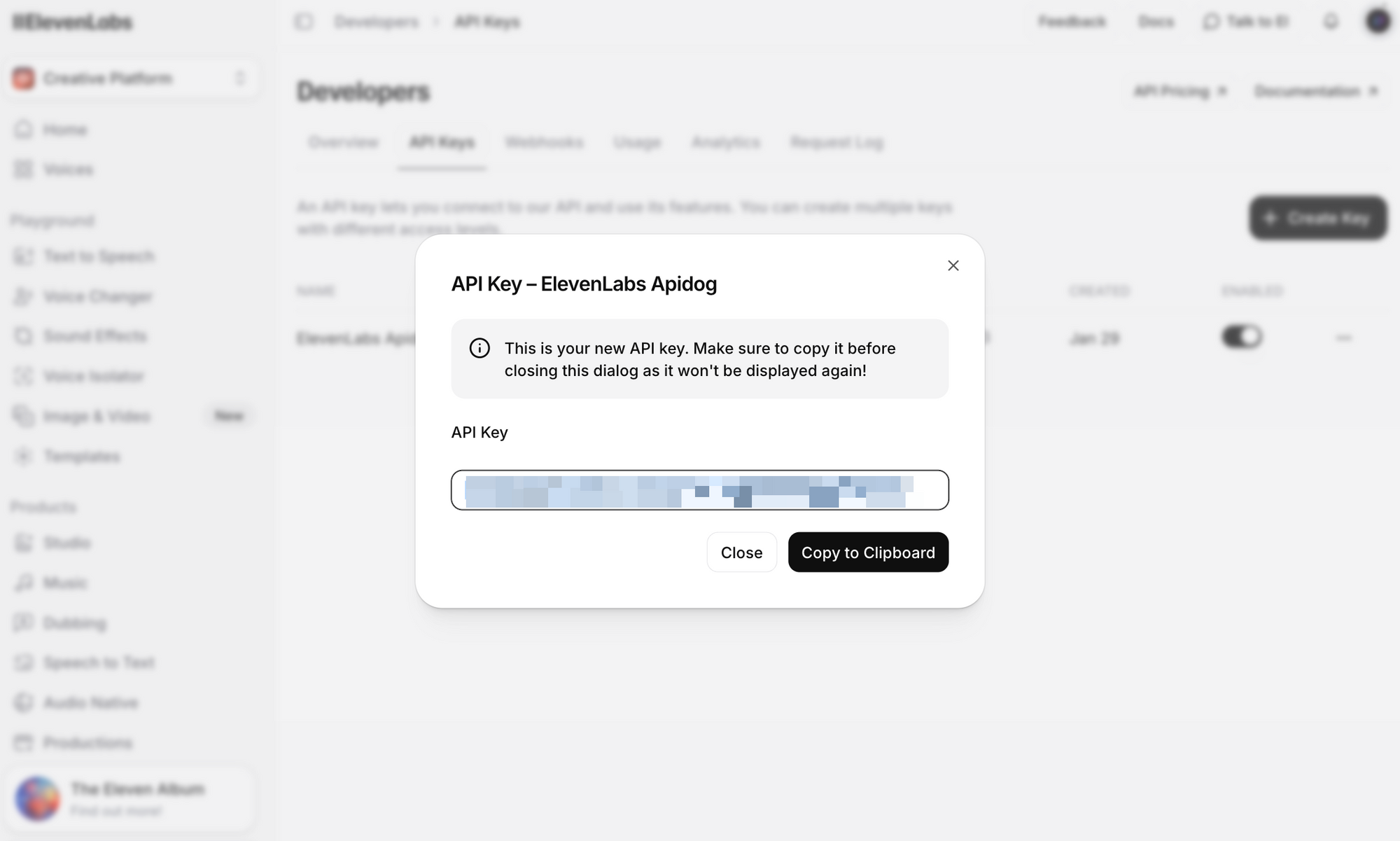
ข้อควรระวังด้านความปลอดภัยที่สำคัญ:
- อย่าผูกมัด API key ของคุณเข้ากับระบบควบคุมเวอร์ชัน
- ใช้ตัวแปรสภาพแวดล้อม (environment variables) หรือตัวจัดการความลับ (secrets manager) ในการใช้งานจริง
- API key สามารถจำกัดขอบเขตไปยังพื้นที่ทำงานเฉพาะสำหรับสภาพแวดล้อมทีม
- หมุนเวียนคีย์อย่างสม่ำเสมอ และเพิกถอนคีย์ที่ถูกบุกรุกทันที
ตั้งค่าเป็นตัวแปรสภาพแวดล้อมสำหรับตัวอย่างในคู่มือนี้:
# Linux/macOS
export ELEVENLABS_API_KEY="your_api_key_here"
# Windows (PowerShell)
$env:ELEVENLABS_API_KEY="your_api_key_here"
ภาพรวม Endpoint ของ ElevenLabs API
API ถูกจัดกลุ่มตามทรัพยากรต่างๆ นี่คือ endpoint ที่ใช้บ่อยที่สุด:
| Endpoint | เมธอด | คำอธิบาย |
|---|---|---|
/v1/text-to-speech/{voice_id} | POST | แปลงข้อความเป็นเสียงพูด |
/v1/text-to-speech/{voice_id}/stream | POST | สตรีมเสียงขณะที่กำลังสร้าง |
/v1/speech-to-speech/{voice_id} | POST | แปลงเสียงจากเสียงหนึ่งไปเป็นอีกเสียงหนึ่ง |
/v1/voices | GET | แสดงรายการเสียงทั้งหมดที่มี |
/v1/voices/{voice_id} | GET | ดูรายละเอียดสำหรับเสียงที่ระบุ |
/v1/models | GET | แสดงรายการโมเดลทั้งหมดที่มี |
/v1/user | GET | ดูข้อมูลบัญชีผู้ใช้และการใช้งาน |
/v1/voice-generation/generate-voice | POST | สร้างเสียงสุ่มใหม่ |
Base URL: https://api.elevenlabs.io
การยืนยันตัวตน: คำขอทั้งหมดต้องมีส่วนหัว xi-api-key:
xi-api-key: your_api_key_here
Text-to-Speech ด้วย cURL
วิธีที่เร็วที่สุดในการทดสอบ API คือการใช้คำสั่ง cURL ตัวอย่างนี้ใช้เสียง Rachel (ID: 21m00Tcm4TlvDq8ikWAM) ซึ่งเป็นหนึ่งในเสียงเริ่มต้นที่มีในทุกแผนบริการ:
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"text": "Welcome to our application. This audio was generated using the ElevenLabs API.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75,
"style": 0.0,
"use_speaker_boost": true
}
}' \
--output speech.mp3
หากสำเร็จ คุณจะได้รับไฟล์ speech.mp3 ที่มีเสียงที่สร้างขึ้นมา เล่นไฟล์ด้วยโปรแกรมเล่นสื่อใดก็ได้
วิเคราะห์คำขอ:
- voice_id (ใน URL): รหัสของเสียงที่จะใช้ เสียงทุกเสียงใน ElevenLabs มีรหัสเฉพาะตัว
- text: เนื้อหาที่จะแปลงเป็นคำพูด โมเดล Flash v2.5 รองรับอักขระสูงสุด 40,000 ตัวต่อคำขอ
- model_id: โมเดล AI ที่จะใช้
eleven_flash_v2_5ให้ความสมดุลที่ดีที่สุดระหว่างความเร็วและคุณภาพ - voice_settings: พารามิเตอร์การปรับแต่งเพิ่มเติม (อธิบายรายละเอียดด้านล่าง)
การตอบสนองจะคืนข้อมูลเสียงดิบ รูปแบบเริ่มต้นคือ MP3 แต่คุณสามารถขอรูปแบบอื่นได้โดยการเพิ่มพารามิเตอร์การสอบถาม output_format:
# Get PCM audio instead of MP3
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM?output_format=pcm_44100" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text": "Hello world", "model_id": "eleven_flash_v2_5"}' \
--output speech.pcm
การใช้ Python SDK
Python SDK อย่างเป็นทางการช่วยลดความซับซ้อนของการรวมระบบด้วย type hints, การเล่นเสียงในตัว และการรองรับการสตรีม
การติดตั้ง
pip install elevenlabs
ในการเล่นเสียงโดยตรงผ่านลำโพงของคุณ คุณอาจต้องใช้ mpv หรือ ffmpeg ด้วย:
# macOS
brew install mpv
# Ubuntu/Debian
sudo apt install mpv
Text-to-Speech พื้นฐาน
import os
from elevenlabs.client import ElevenLabs
from elevenlabs import play
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY")
)
audio = client.text_to_speech.convert(
text="The ElevenLabs API makes it easy to add realistic voice output to any application.",
voice_id="JBFqnCBsd6RMkjVDRZzb", # George voice
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
บันทึกเสียงลงไฟล์
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio = client.text_to_speech.convert(
text="This audio will be saved to a file.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("output.mp3", "wb") as f:
for chunk in audio:
f.write(chunk)
print("Audio saved to output.mp3")
แสดงรายการเสียงที่มี
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
response = client.voices.search()
for voice in response.voices:
print(f"Name: {voice.name}, ID: {voice.voice_id}, Category: {voice.category}")
นี่จะแสดงเสียงทั้งหมดที่มีในบัญชีของคุณ รวมถึงเสียงที่สร้างไว้ล่วงหน้า เสียงที่โคลน และเสียงจากชุมชนที่คุณเพิ่มเข้ามา
การรองรับแบบ Async
สำหรับแอปพลิเคชันที่ใช้ asyncio, SDK มี AsyncElevenLabs:
import asyncio
from elevenlabs.client import AsyncElevenLabs
client = AsyncElevenLabs(api_key="your_api_key")
async def generate_speech():
audio = await client.text_to_speech.convert(
text="This was generated asynchronously.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("async_output.mp3", "wb") as f:
async for chunk in audio:
f.write(chunk)
print("Async audio saved.")
asyncio.run(generate_speech())
การใช้ JavaScript SDK
Node.js SDK อย่างเป็นทางการ (@elevenlabs/elevenlabs-js) ให้การรองรับ TypeScript เต็มรูปแบบและทำงานได้ในสภาพแวดล้อม Node.js
การติดตั้ง
npm install @elevenlabs/elevenlabs-js
Text-to-Speech พื้นฐาน
import { ElevenLabsClient, play } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM", // Rachel voice ID
{
text: "Hello from the ElevenLabs JavaScript SDK!",
modelId: "eleven_multilingual_v2",
}
);
await play(audio);
บันทึกเป็นไฟล์ (Node.js)
import { ElevenLabsClient } from "@elevenlabs/elevenlabs-js";
import { createWriteStream } from "fs";
import { Readable } from "stream";
import { pipeline } from "stream/promises";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "This audio will be written to a file using Node.js streams.",
modelId: "eleven_flash_v2_5",
}
);
const readable = Readable.from(audio);
const writeStream = createWriteStream("output.mp3");
await pipeline(readable, writeStream);
console.log("Audio saved to output.mp3");
การจัดการข้อผิดพลาด
import { ElevenLabsClient, ElevenLabsError } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
try {
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Testing error handling.",
modelId: "eleven_flash_v2_5",
}
);
await play(audio);
} catch (error) {
if (error instanceof ElevenLabsError) {
console.error(`API Error: ${error.message}, Status: ${error.statusCode}`);
} else {
console.error("Unexpected error:", error);
}
}
SDK จะลองส่งคำขอที่ล้มเหลวใหม่สูงสุด 2 ครั้งโดยค่าเริ่มต้น พร้อมกับการหมดเวลา 60 วินาที ทั้งสองค่าสามารถกำหนดค่าได้
การสตรีมเสียงแบบเรียลไทม์
สำหรับแชทบอท ผู้ช่วยเสียง หรือแอปพลิเคชันใดๆ ที่ความล่าช้าเป็นสิ่งสำคัญ การสตรีมช่วยให้คุณสามารถเริ่มเล่นเสียงได้ก่อนที่การตอบสนองทั้งหมดจะถูกสร้างเสร็จสมบูรณ์ สิ่งนี้สำคัญสำหรับ AI สนทนาที่ผู้ใช้คาดหวังการตอบสนองเกือบจะทันที
การสตรีมด้วย Python
from elevenlabs import stream
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio_stream = client.text_to_speech.stream(
text="Streaming allows you to start hearing audio almost instantly, without waiting for the entire generation to complete.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_flash_v2_5",
)
# Play streamed audio through speakers in real time
stream(audio_stream)
การสตรีมด้วย JavaScript
import { ElevenLabsClient, stream } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient();
const audioStream = await elevenlabs.textToSpeech.stream(
"JBFqnCBsd6RMkjVDRZzb",
{
text: "This audio streams in real time with minimal latency.",
modelId: "eleven_flash_v2_5",
}
);
stream(audioStream);
การสตรีมด้วย WebSocket
เพื่อความล่าช้าที่น้อยที่สุด ให้ใช้การเชื่อมต่อ WebSocket นี่เหมาะสำหรับตัวแทนเสียงแบบเรียลไทม์ที่ข้อความมาเป็นส่วนๆ (เช่น จาก LLM):
import asyncio
import websockets
import json
import base64
async def stream_tts_websocket():
voice_id = "21m00Tcm4TlvDq8ikWAM"
model_id = "eleven_flash_v2_5"
uri = f"wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-input?model_id={model_id}"
async with websockets.connect(uri) as ws:
# Send initial config
await ws.send(json.dumps({
"text": " ",
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
"xi_api_key": "your_api_key",
}))
# Send text chunks as they arrive (e.g., from an LLM)
text_chunks = [
"Hello! ",
"This is streaming ",
"via WebSockets. ",
"Each chunk is sent separately."
]
for chunk in text_chunks:
await ws.send(json.dumps({"text": chunk}))
# Signal end of input
await ws.send(json.dumps({"text": ""}))
# Receive audio chunks
audio_data = b""
async for message in ws:
data = json.loads(message)
if data.get("audio"):
audio_data += base64.b64decode(data["audio"])
if data.get("isFinal"):
break
with open("websocket_output.mp3", "wb") as f:
f.write(audio_data)
print("WebSocket audio saved.")
asyncio.run(stream_tts_websocket())
การเลือกและการจัดการเสียง
ElevenLabs มีเสียงให้เลือกหลายร้อยเสียง การเลือกเสียงที่เหมาะสมเป็นสิ่งสำคัญสำหรับประสบการณ์ผู้ใช้ของแอปพลิเคชันของคุณ
เสียงเริ่มต้น
เสียงเหล่านี้มีให้ใช้งานในทุกแผน รวมถึงแผนฟรี:
| ชื่อเสียง | รหัสเสียง | คำอธิบาย |
|---|---|---|
| Rachel | 21m00Tcm4TlvDq8ikWAM | หญิงสาวใจเย็น |
| Drew | 29vD33N1CtxCmqQRPOHJ | ชายหนุ่มเสียงดี |
| Clyde | 2EiwWnXFnvU5JabPnv8n | ตัวละครทหารผ่านศึก |
| Paul | 5Q0t7uMcjvnagumLfvZi | นักข่าวภาคสนาม |
| Domi | AZnzlk1XvdvUeBnXmlld | หญิงสาวแข็งแกร่ง มั่นใจ |
| Dave | CYw3kZ02Hs0563khs1Fj | ชายชาวอังกฤษเสียงสนทนา |
| Fin | D38z5RcWu1voky8WS1ja | ชายชาวไอริช |
| Sarah | EXAVITQu4vr4xnSDxMaL | หญิงสาวอ่อนโยน |
การค้นหารหัสเสียง
ใช้ API เพื่อค้นหาเสียงทั้งหมดที่มี:
curl -X GET "https://api.elevenlabs.io/v1/voices" \
-H "xi-api-key: $ELEVENLABS_API_KEY" | python3 -m json.tool
หรือกรองตามหมวดหมู่ (ที่สร้างไว้ล่วงหน้า, โคลน, สร้างขึ้น):
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# List only premade voices
response = client.voices.search(category="premade")
for voice in response.voices:
print(f"{voice.name}: {voice.voice_id}")
คุณยังสามารถคัดลอกรหัสเสียงได้โดยตรงจากเว็บไซต์ ElevenLabs: เลือกเสียง คลิกเมนูสามจุด แล้วเลือก Copy Voice ID (คัดลอกรหัสเสียง)
การเลือกโมเดลที่เหมาะสม
ElevenLabs มีโมเดลหลายรูปแบบ โดยแต่ละแบบได้รับการปรับให้เหมาะสมกับการใช้งานที่แตกต่างกันไป:

# List all available models with details
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
models = client.models.list()
for model in models:
print(f"Model: {model.name}")
print(f" ID: {model.model_id}")
print(f" Languages: {len(model.languages)}")
print(f" Max chars: {model.max_characters_request_free_user}")
print()
การทดสอบ ElevenLabs API ด้วย Apidog
ก่อนที่จะเขียนโค้ดสำหรับผสานรวม การทดสอบ endpoint ของ API แบบโต้ตอบจะมีประโยชน์ Apidog ทำให้เรื่องนี้ง่ายขึ้น คุณสามารถกำหนดค่าคำขอด้วยภาพ ตรวจสอบการตอบสนอง (รวมถึงเสียง) และสร้างโค้ดไคลเอนต์ได้เมื่อคุณพอใจแล้ว
ขั้นตอนที่ 1: ตั้งค่าโปรเจกต์ใหม่
เปิด Apidog และสร้างโปรเจกต์ใหม่ ตั้งชื่อว่า "ElevenLabs API" หรือเพิ่ม endpoint ลงในโปรเจกต์ที่มีอยู่
ขั้นตอนที่ 2: กำหนดค่าการยืนยันตัวตน
ไปที่ Project Settings > Auth และตั้งค่าส่วนหัวแบบ global:
- ชื่อส่วนหัว:
xi-api-key - ค่าส่วนหัว: API key ของ ElevenLabs ของคุณ
สิ่งนี้จะแนบการยืนยันตัวตนกับทุกคำขอในโปรเจกต์โดยอัตโนมัติ
ขั้นตอนที่ 3: สร้างคำขอ Text-to-Speech
สร้างคำขอ POST ใหม่:
- URL:
https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM - บอดี้ (JSON):
{
"text": "Testing the ElevenLabs API through Apidog. This makes it easy to experiment with different voices and settings.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
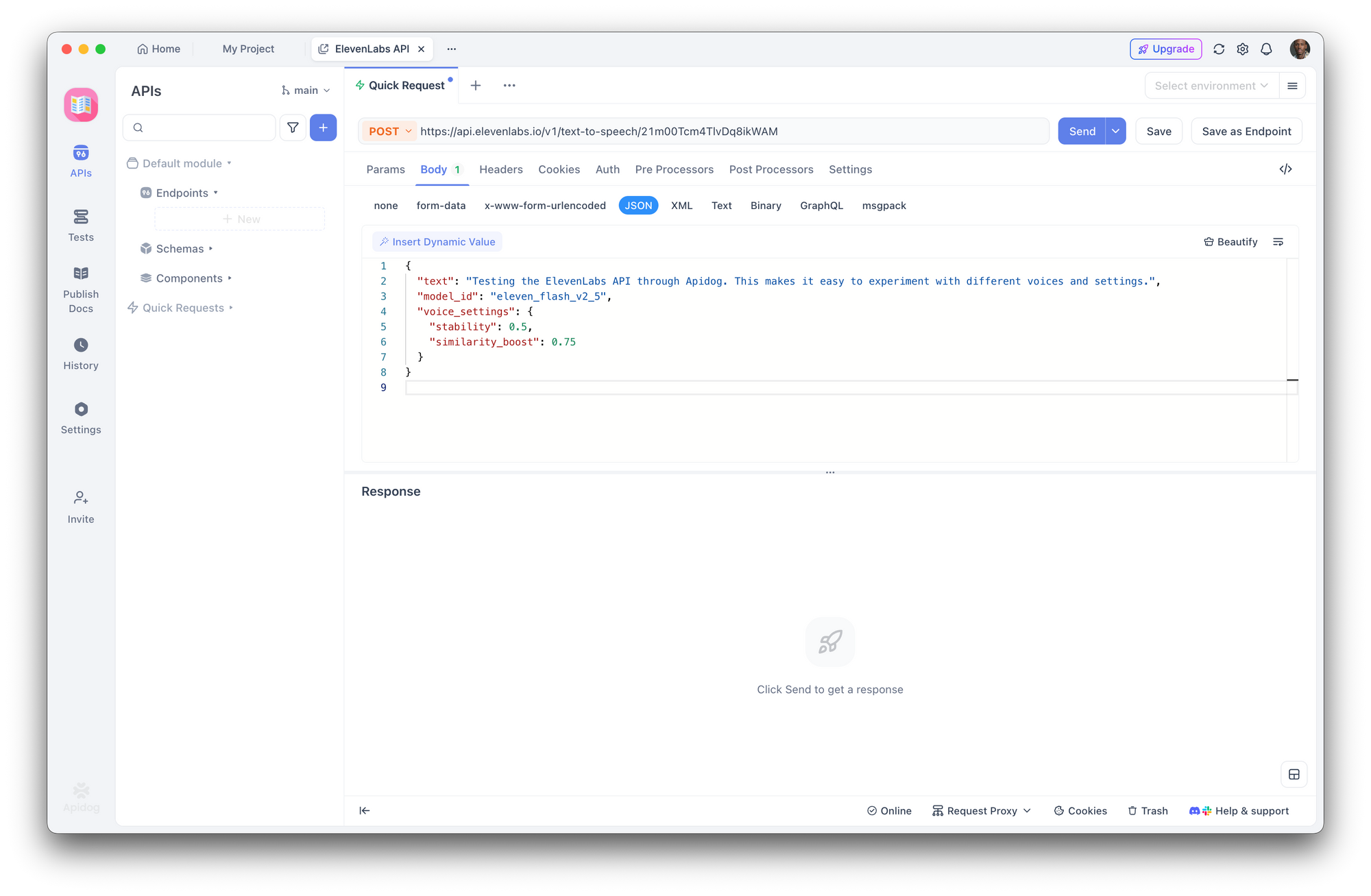
คลิก Send Apidog จะแสดงส่วนหัวการตอบสนองและช่วยให้คุณดาวน์โหลดหรือเล่นเสียงได้โดยตรง
ขั้นตอนที่ 4: ทดลองกับพารามิเตอร์
ใช้ส่วนต่อประสานของ Apidog เพื่อสลับรหัสเสียง เปลี่ยนโมเดล หรือปรับการตั้งค่าเสียงได้อย่างรวดเร็วโดยไม่ต้องแก้ไข JSON ดิบ บันทึกการกำหนดค่าต่างๆ เป็น endpoint แยกกันในคอลเลกชันของคุณเพื่อการเปรียบเทียบที่ง่ายดาย
ขั้นตอนที่ 5: สร้างโค้ดไคลเอนต์
เมื่อคุณยืนยันว่าคำขอทำงานได้แล้ว ให้คลิก Generate Code ใน Apidog เพื่อรับโค้ดไคลเอนต์พร้อมใช้งานใน Python, JavaScript, cURL, Go, Java และอื่นๆ ซึ่งช่วยลดการแปลคู่มือ API เป็นโค้ดที่ใช้งานได้ด้วยตนเอง
ลองเลย:ดาวน์โหลด Apidog ฟรี
การตั้งค่าเสียงและการปรับแต่งอย่างละเอียด
การตั้งค่าเสียงช่วยให้คุณปรับแต่งเสียงได้ พารามิเตอร์เหล่านี้จะถูกส่งในออบเจกต์ voice_settings:
| พารามิเตอร์ | ช่วง | ค่าเริ่มต้น | ผลกระทบ |
|---|---|---|---|
stability | 0.0 - 1.0 | 0.5 | สูงขึ้น = สม่ำเสมอมากขึ้น, แสดงอารมณ์น้อยลง ต่ำลง = ผันแปรมากขึ้น, แสดงอารมณ์มากขึ้น |
similarity_boost | 0.0 - 1.0 | 0.75 | สูงขึ้น = ใกล้เคียงกับเสียงต้นฉบับมากขึ้น ต่ำลง = มีความหลากหลายมากขึ้น |
style | 0.0 - 1.0 | 0.0 | สูงขึ้น = รูปแบบที่เกินจริงมากขึ้น เพิ่มความล่าช้า เฉพาะสำหรับ Multilingual v2 เท่านั้น |
use_speaker_boost | boolean | true | เพิ่มความคล้ายคลึงกับผู้พูดต้นฉบับ เพิ่มความล่าช้าเล็กน้อย |
ตัวอย่างการใช้งานจริง:
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# Narration voice: consistent, stable
narration = client.text_to_speech.convert(
text="Chapter One. It was a bright cold day in April.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.8,
"similarity_boost": 0.8,
"style": 0.2,
"use_speaker_boost": True,
},
)
# Conversational voice: expressive, natural
conversational = client.text_to_speech.convert(
text="Oh wow, that's actually a great idea! Let me think about how we could make it work.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.3,
"similarity_boost": 0.6,
"style": 0.5,
"use_speaker_boost": True,
},
)
แนวทางปฏิบัติ:
- สำหรับหนังสือเสียงและการบรรยาย ให้ใช้ค่า stability ที่สูงขึ้น (0.7-0.9) เพื่อการส่งมอบที่สม่ำเสมอ
- สำหรับแชทบอทและ AI สนทนา ให้ใช้ค่า stability ที่ต่ำลง (0.3-0.5) เพื่อความหลากหลายที่เป็นธรรมชาติ
- สำหรับเสียงตัวละคร ให้ทดลองใช้ค่า similarity_boost ที่ต่ำลง (0.4-0.6) เพื่อสร้างบุคลิกที่แตกต่าง
- พารามิเตอร์
styleใช้งานได้กับ Multilingual v2 เท่านั้นและเพิ่มความล่าช้า—ให้ข้ามไปสำหรับแอปพลิเคชันแบบเรียลไทม์
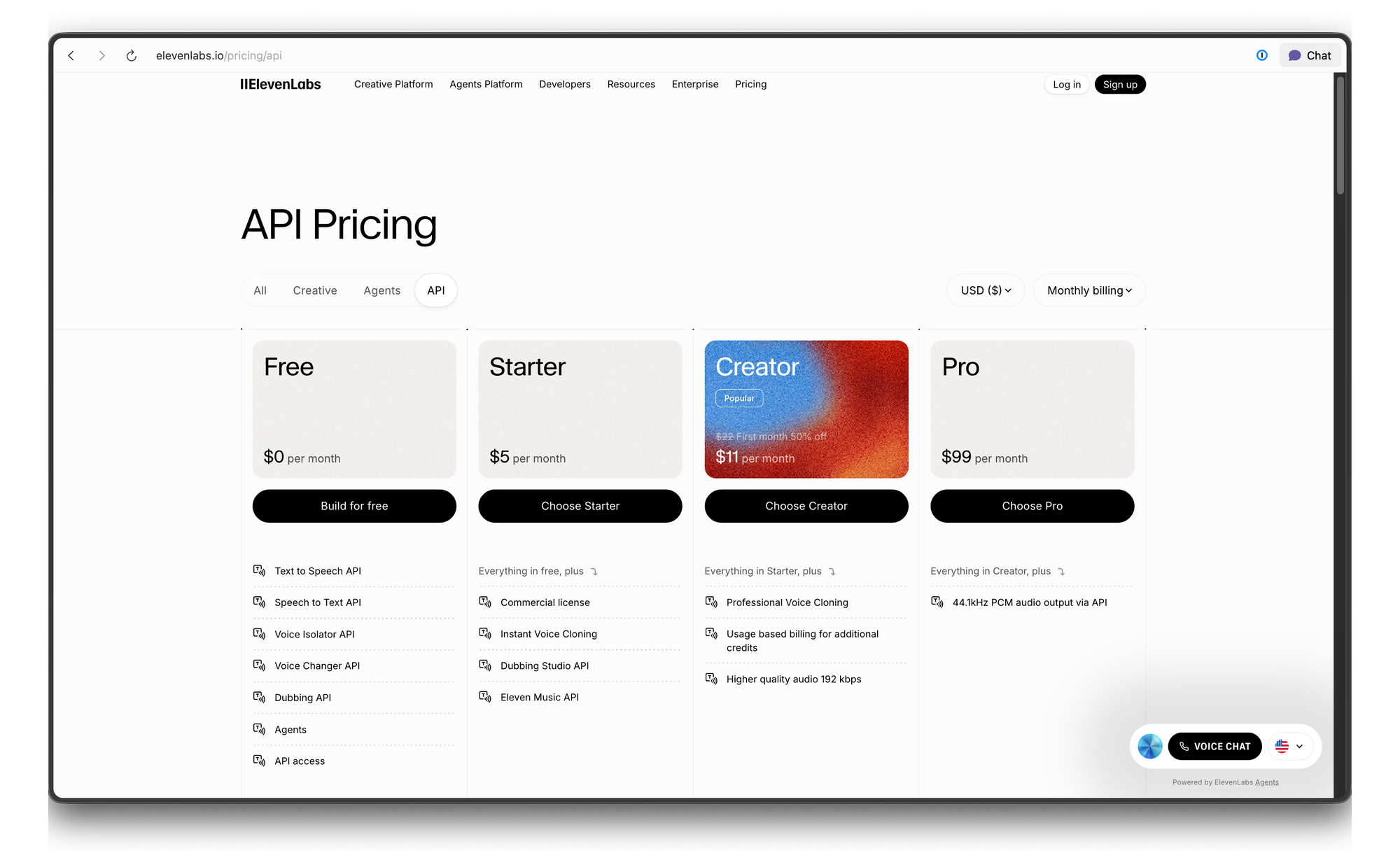
ราคาและข้อจำกัดการเรียกใช้ API ของ ElevenLabs
ElevenLabs ใช้ระบบราคาแบบเครดิต นี่คือรายละเอียด:
การแก้ไขปัญหา
| ข้อผิดพลาด | สาเหตุ | วิธีแก้ไข |
|---|---|---|
| 401 Unauthorized | API key ไม่ถูกต้องหรือหายไป | ตรวจสอบค่าส่วนหัว xi-api-key ของคุณ |
| 422 Unprocessable Entity | บอดี้คำขอไม่ถูกต้อง | ตรวจสอบว่า voice_id มีอยู่จริงและข้อความไม่ว่างเปล่า |
| 429 Too Many Requests | เกินขีดจำกัดการเรียกใช้ | เพิ่ม exponential backoff หรืออัปเกรดแผนของคุณ |
| Audio sounds robotic | โมเดลหรือการตั้งค่าไม่ถูกต้อง | ลองใช้ Multilingual v2 โดยตั้งค่า stability ที่ 0.5 |
| Pronunciation errors | ปัญหาการทำให้ข้อความเป็นมาตรฐาน | สะกดตัวเลข/คำย่อ หรือใช้การจัดรูปแบบที่คล้าย SSML |
บทสรุป
ElevenLabs API ช่วยให้นักพัฒนาสามารถเข้าถึงการสังเคราะห์เสียงที่สมจริงที่สุดในปัจจุบัน ไม่ว่าคุณจะต้องการการบรรยายเพียงไม่กี่บรรทัด หรือไปป์ไลน์เสียงแบบเรียลไทม์เต็มรูปแบบ API ก็สามารถปรับขนาดได้ตั้งแต่การเรียกใช้ cURL แบบง่าย ไปจนถึงการสตรีม WebSocket ในระดับการใช้งานจริง
พร้อมที่จะเพิ่มเสียงที่สมจริงให้กับแอปพลิเคชันของคุณแล้วหรือยัง? ดาวน์โหลด Apidog เพื่อทดสอบ endpoint ของ ElevenLabs API ทดลองกับการตั้งค่าเสียง และสร้างโค้ดไคลเอนต์—ทั้งหมดนี้ฟรี ไม่ต้องใช้บัตรเครดิต