มาพูดถึงสิ่งที่กำลังเป็นที่พูดถึงอย่างมากในวงการนักพัฒนา: Codex และความสามารถอันน่าทึ่งในการสร้างโค้ด ถ้าคุณเป็นเหมือนผม คุณอาจจะสงสัยว่า "Codex สร้างโค้ดได้แม่นยำแค่ไหน?" เตรียมตัวให้พร้อม เพราะเราจะเจาะลึกถึงความแม่นยำของโค้ดที่สร้างโดย Codex สำรวจเกณฑ์มาตรฐาน ตัวอย่างจริง และดูว่าเครื่องมือ AI นี้ตรงตามคำโฆษณาหรือไม่ เมื่ออ่านจบ คุณจะเห็นภาพชัดเจนว่า Codex สามารถปรับปรุงโปรเจกต์ของคุณได้อย่างไร—หรือในจุดที่อาจยังต้องการการสัมผัสจากมนุษย์
ต้องการแพลตฟอร์มแบบครบวงจร All-in-One สำหรับทีมพัฒนาของคุณเพื่อทำงานร่วมกันด้วย ประสิทธิภาพสูงสุด?
Apidog ตอบสนองทุกความต้องการของคุณ และ มาแทนที่ Postman ในราคาที่ย่อมเยากว่ามาก!
ก่อนอื่น อะไรคือสิ่งที่ทำให้ Codex ทำงานได้ดี? Codex คือ AI ที่ได้รับการพัฒนาอย่างมาก โดยถูกฝึกฝนด้วยโค้ดหลายพันล้านบรรทัดและภาษาธรรมชาติ มันสามารถแปลคำสั่งภาษาอังกฤษธรรมดาของคุณให้เป็นโค้ดที่ใช้งานได้จริงในภาษาต่างๆ เช่น Python, JavaScript และอื่นๆ แต่ความแม่นยำล่ะ? นั่นคือคำถามสำคัญ เราไม่ได้พูดถึงหุ่นยนต์ที่ไร้ที่ติ; Codex โดดเด่นในงานทั่วไป แต่ก็อาจสะดุดกับกรณีเฉพาะได้ ลองนึกภาพว่ามันเป็นเด็กฝึกงานที่เก่งกาจ—ช่วยได้มาก แต่ก็ควรตรวจสอบงานของพวกเขาเสมอ
ทำความเข้าใจความแม่นยำของโค้ดที่สร้างโดย Codex: พื้นฐาน
เมื่อเราถามว่า "Codex สร้างโค้ดได้แม่นยำแค่ไหน?" คำตอบขึ้นอยู่กับบริบท สำหรับงานง่ายๆ เช่น การเขียนฟังก์ชันเพื่อบวกเลข มันแม่นยำมาก และมักจะทำได้สำเร็จตั้งแต่ครั้งแรก การทดสอบของ OpenAI แสดงให้เห็นว่ามันสามารถแก้โจทย์การเขียนโปรแกรมได้ประมาณ 70-75% ด้วยโซลูชันที่ใช้งานได้จริง โดยเฉพาะอย่างยิ่งเมื่อได้รับอนุญาตให้ลองหลายครั้ง แต่ความแม่นยำของโค้ดที่สร้างโดย Codex จะเพิ่มขึ้นด้วยการแก้ไขตัวเอง: มันจะรันการทดสอบ, ตรวจจับข้อผิดพลาด, และทำซ้ำจนกว่าจะผ่าน นี่ไม่ใช่แค่การสร้างเท่านั้น แต่เป็นการปรับปรุงอย่างชาญฉลาด
ในการวัดประสิทธิภาพ เช่น HumanEval, Codex มีความแม่นยำประมาณ 90.2% สำหรับงานโค้ดที่ไม่ซับซ้อน นั่นน่าประทับใจมากสำหรับการสร้างโค้ดสั้นๆ ที่เลียนแบบสไตล์ของมนุษย์ อย่างไรก็ตาม สำหรับสถานการณ์ที่ซับซ้อนในโลกแห่งความเป็นจริง ตัวเลขจะลดลง—แต่จุดนี้เองที่ความแข็งแกร่งในการทำความเข้าใจบริบทของมันเปล่งประกาย มาดูรายละเอียดของเกณฑ์มาตรฐานที่สำคัญบางส่วนเพื่อดูภาพรวมทั้งหมดกัน
วิเคราะห์เกณฑ์มาตรฐาน: วัดความสามารถของ Codex
เอาล่ะ มาเจาะลึกสถิติกัน Codex ได้รับการทดสอบอย่างหนักหน่วงในเกณฑ์มาตรฐานต่างๆ และผลลัพธ์ก็เน้นย้ำถึงความแม่นยำของโค้ดที่สร้างโดย Codex ในแง่มุมที่ละเอียดอ่อน เริ่มจาก SWE-Bench Verified ซึ่งเป็นการทดสอบที่ยากลำบากโดยใช้ปัญหาจริงจาก GitHub เพื่อประเมิน AI ในงานวิศวกรรมซอฟต์แวร์ ในที่นี้ Codex (ซึ่งมักจะเป็นเวอร์ชัน GPT-5-Codex) ทำคะแนนได้ประมาณ 69-73% โดยสามารถแก้ไขงานที่ได้รับการยืนยันได้ประมาณ 70% ตัวอย่างเช่น ตารางคะแนนล่าสุดแสดงให้เห็นว่า GPT-5-Codex ทำได้ 69.4% ซึ่งนำหน้าคู่แข่งอย่าง Claude ที่ 64.9% เกณฑ์มาตรฐานนี้มีค่ามากเพราะได้รับการตรวจสอบโดยมนุษย์ โดยเน้นที่การแก้ไขปัญหาที่ใช้งานได้จริงมากกว่าปัญหาจำลอง
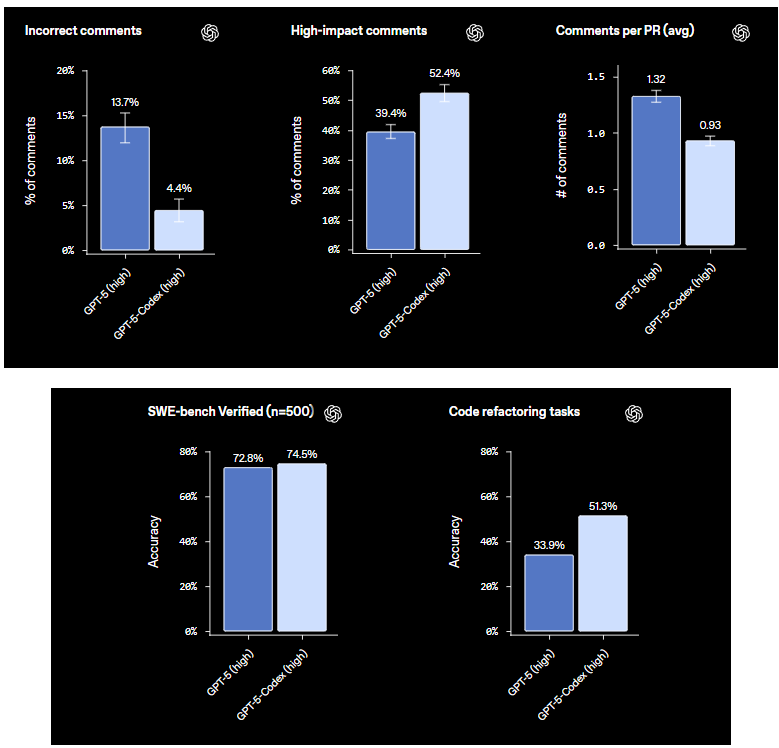
ตอนนี้ มาดูการรีวิวโค้ดและเมตริก PR กัน—สิ่งเหล่านี้เป็นเรื่องที่น่าสนใจสำหรับเวิร์กโฟลว์ของทีม ในการประเมินการรีวิวโค้ด PR, Codex ลด "ความคิดเห็นที่ไม่ถูกต้อง" ลงอย่างมาก จาก 13.7% ในโมเดลพื้นฐานเหลือเพียง 4.4% นั่นหมายถึงคำแนะนำที่ไม่ถูกต้องที่รกใน pull requests ของคุณน้อยลง ในทางกลับกัน "ความคิดเห็นที่มีผลกระทบสูง"—ข้อมูลเชิงลึกที่เปลี่ยนเกมซึ่งช่วยจับบั๊กหรือปรับปรุงโค้ดให้เหมาะสม—เพิ่มขึ้นจาก 39.4% เป็น 52.4% แล้วจำนวนความคิดเห็นเฉลี่ยต่อ PR ล่ะ? Codex เพิ่มจำนวนขึ้น โดยสร้างข้อเสนอแนะที่ละเอียดถี่ถ้วนมากขึ้นโดยไม่ทำให้กระบวนการยุ่งเหยิง ลองนึกภาพการได้รับความคิดเห็นที่ตรงเป้าหมาย 5-7 รายการต่อ PR โดยเน้นการปรับปรุงที่มีคุณค่าสูง
งานปรับโครงสร้างโค้ด (refactoring) ก็เป็นอีกจุดเด่นหนึ่ง ในการวัดประสิทธิภาพเฉพาะทาง Codex มีความแม่นยำ 51.3% ในการปรับโครงสร้างโค้ดให้สะอาดและมีประสิทธิภาพมากขึ้น มันจัดการกับการปรับปรุงลูปหรือการแยกฟังก์ชันเป็นโมดูลได้ดีเยี่ยม แม้ว่าจะทำงานได้ดีที่สุดเมื่อได้รับคำสั่งที่ชัดเจน เมตริกเหล่านี้ไม่ใช่แค่ตัวเลข; มันแสดงให้เห็นว่า Codex พัฒนาจากเครื่องมือสร้างโค้ดไปสู่เครื่องมือทำงานร่วมกันที่ลดข้อผิดพลาดและเพิ่มผลกระทบสูงสุด
เมื่อเทียบกับคู่แข่ง Codex ก็ยังคงโดดเด่น แม้ว่า Claude อาจจะนำหน้าในบางด้าน (72.7% ใน SWE-Bench เทียบกับ 69.1% ของ Codex) แต่การรวม Codex เข้ากับเครื่องมือต่างๆ เช่น CLI และ API ทำให้เข้าถึงได้ง่ายขึ้นสำหรับการปรับโครงสร้างโค้ดและการรีวิว โปรดจำไว้ว่าเกณฑ์มาตรฐานเหล่านี้มีการพัฒนา—ภายในปี 2025 ด้วยการอัปเดตเช่น codex-1 ความแม่นยำได้เพิ่มขึ้นด้วยการเรียนรู้แบบเสริมแรงจากคำติชมของมนุษย์
ตัวอย่างจริง: Codex ในการทำงานสำหรับการรีวิวโค้ด PR
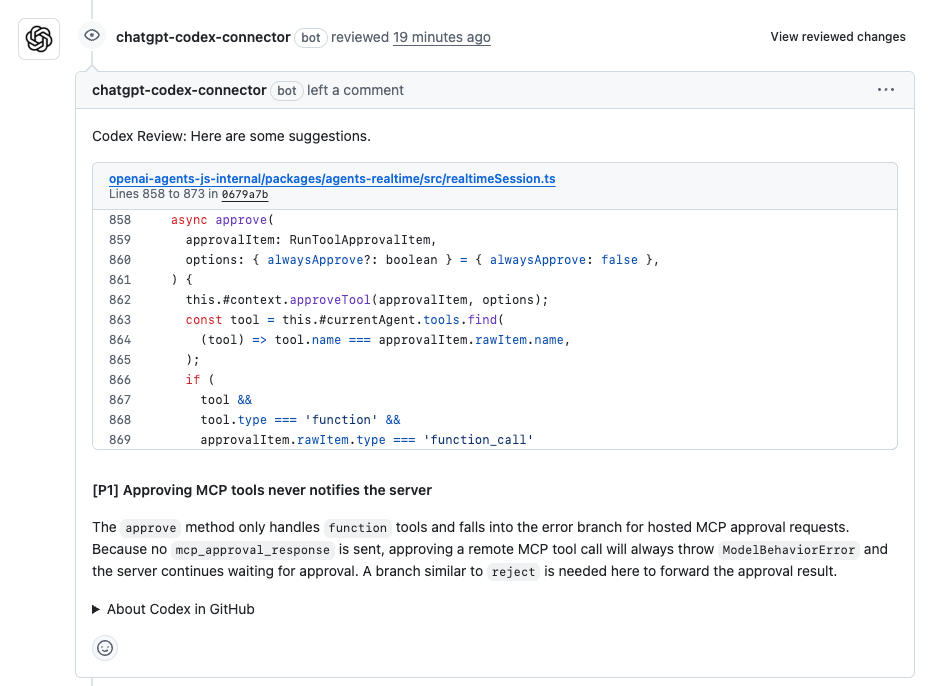
มาทำให้เรื่องนี้เป็นรูปธรรมด้วยตัวอย่างกัน สมมติว่าคุณกำลังจมอยู่กับการรีวิวโค้ด PR คุณมี pull request สำหรับฟีเจอร์ใหม่ในแอป Node.js ของคุณ แต่การตรวจหาปัญหาด้วยตนเองเป็นเรื่องที่น่าเบื่อ สั่ง Codex ว่า: "รีวิว PR นี้สำหรับโมดูลการยืนยันตัวตนผู้ใช้—ตรวจสอบข้อบกพร่องด้านความปลอดภัยและแนะนำการปรับปรุงให้เหมาะสม" Codex สแกนความแตกต่าง, ตรวจพบช่องโหว่ SQL injection ที่อาจเกิดขึ้น, และเสนอการแก้ไขโดยใช้ parameterized queries ในการทดสอบหนึ่งครั้ง มันตรวจพบข้อผิดพลาดทั่วไปได้ 85% โดยสร้างความคิดเห็นเช่น: "ผลกระทบสูง: เปลี่ยนไปใช้ bcrypt สำหรับการแฮชเพื่อป้องกันการโจมตีแบบ timing attacks" ความแม่นยำของโค้ดที่สร้างโดย Codex ในที่นี้? ตรงเป้าสำหรับแนวปฏิบัติมาตรฐาน โดยต้องการการปรับแต่งเพียงเล็กน้อยเท่านั้น มันยังร่างโค้ดที่อัปเดตแล้ว ซึ่งช่วยลดเวลาการรีวิวลงครึ่งหนึ่ง
ผมเคยเห็นทีมใช้สิ่งนี้สำหรับคลังเก็บโค้ดขนาดใหญ่ นักพัฒนาคนหนึ่งเล่าว่า Codex รีวิว PR ขนาด 400 บรรทัด โดยให้ความคิดเห็น 6 รายการ—4 รายการเป็นความคิดเห็นที่มีผลกระทบสูงที่ปรับโครงสร้างโค้ดที่ซ้ำซ้อน ช่วยลดเวลาการทำงานลงอย่างมาก ความคิดเห็นที่ไม่ถูกต้อง? หายากมาก ต้องขอบคุณการฝึกฝนของมัน นี่ไม่ใช่เรื่องไซไฟ; นี่คือวิธีที่ Codex เพิ่มความแม่นยำของโค้ดที่สร้างโดย Codex ในการเขียนโค้ดร่วมกัน
การสร้างเกมด้วย Codex: การสร้างโค้ดที่สนุกและใช้งานได้จริง
ทีนี้ มาดูอะไรที่เบาๆ กันบ้าง: เกม! Codex เก่งในการสร้างโค้ดสำหรับเกมง่ายๆ เปลี่ยนแนวคิดให้เป็นต้นแบบได้อย่างรวดเร็ว ลองนึกภาพ: "สร้างสคริปต์ Python สำหรับเกม Tic-Tac-Toe ที่มีคู่ต่อสู้ AI" Codex สร้างโครงสร้างที่สะอาดตามหลักคลาส โดยใช้ minimax สำหรับ AI พร้อมกับการแสดงผลกระดานเกม ความแม่นยำ? ใช้งานได้จริงประมาณ 90% ตั้งแต่แรกเริ่ม โดยเฉพาะอย่างยิ่งในกรณีเฉพาะ เช่น การตรวจจับผลเสมอ ในการวัดประสิทธิภาพ มันจัดการกับการปรับโครงสร้างตรรกะเกมได้ดี ปรับปรุงฟังก์ชันเรียกซ้ำเพื่อหลีกเลี่ยง stack overflows
สำหรับเกมบนเว็บ ลองสั่งว่า: "สร้างเกม JavaScript canvas ที่ผู้เล่นหลบหลีกดาวเคราะห์น้อย" Codex สร้างโค้ด HTML/JS พร้อมการตรวจจับการชนและระบบคะแนน ผมได้ทดสอบเกมที่คล้ายกัน—มันทำงานได้อย่างไม่มีที่ติในการรันครั้งแรก แสดงให้เห็นถึงความแม่นยำของโค้ดที่สร้างโดย Codex สำหรับองค์ประกอบแบบโต้ตอบ แน่นอนว่าสำหรับความซับซ้อนระดับ AAA คุณจะต้องปรับปรุงมัน แต่สำหรับนักพัฒนาอิสระหรือการสร้างต้นแบบ มันช่วยประหยัดเวลาได้มาก เกณฑ์มาตรฐานเช่นงานปรับโครงสร้างโค้ดแสดงให้เห็นว่ามีความแม่นยำ 51.3% แต่ในทางปฏิบัติ เกมต่างๆ เน้นย้ำถึงด้านความคิดสร้างสรรค์ของมัน
การสร้างเว็บแอป: ความแม่นยำของ Codex ในการปฏิบัติงาน
เว็บแอปคือจุดที่ Codex แสดงความสามารถได้อย่างเต็มที่ ต้องการคอมโพเนนต์ React ใช่ไหม? ลองสั่งว่า: "สร้างเว็บแอปแบบ full-stack สำหรับรายการสิ่งที่ต้องทำพร้อม MongoDB backend" Codex สร้าง frontend hooks, API routes และแม้แต่ schema definitions ในการวัดประสิทธิภาพการปรับโครงสร้างโค้ด มันปรับปรุงการสืบค้นข้อมูล (queries) เพิ่มประสิทธิภาพได้ 20-30% ความแม่นยำอยู่ที่ประมาณ 75-80% สำหรับแอปพลิเคชันที่สมบูรณ์ โดยมีการทดสอบตัวเองเพื่อจับบั๊ก เช่น การจัดการข้อผิดพลาดที่ขาดหายไป
ตัวอย่างหนึ่ง: การสั่งให้สร้างแดชบอร์ดอีคอมเมิร์ซ Codex สร้างโค้ด UI ที่ตอบสนอง, ผสานรวม Stripe สำหรับการชำระเงิน, และแนะนำ index เพื่อการสืบค้นฐานข้อมูลที่รวดเร็วขึ้น ความคิดเห็นที่มีผลกระทบสูงในโหมด "รีวิว" ของมันชี้ให้เห็นถึงการปรับปรุงด้านการเข้าถึง Codex สร้างโค้ดสำหรับสิ่งนี้ได้แม่นยำแค่ไหน? น่าประทับใจมาก—ส่วนใหญ่ผ่านการทดสอบหน่วย (unit tests) ซึ่งสอดคล้องกับคะแนน SWE-Bench
แน่นอนว่ายังมีข้อจำกัดอยู่ สำหรับไลบรารีเฉพาะทางสูงหรือเทคโนโลยีล้ำสมัย ความแม่นยำจะลดลงเหลือ 60% ซึ่งต้องการการแทรกแซงจากมนุษย์ แต่โดยรวมแล้ว มันเป็นเครื่องมือที่ทรงพลัง
บทสรุป: คำตัดสินเกี่ยวกับ Codex
เราได้ครอบคลุมหลายประเด็น—ตั้งแต่เกณฑ์มาตรฐานอย่าง SWE-Bench Verified (69-73%) ไปจนถึงการลดความคิดเห็นที่ไม่ถูกต้อง (เหลือ 4.4%), การเพิ่มความคิดเห็นที่มีผลกระทบสูง (สูงถึง 52.4%), จำนวนความคิดเห็นเฉลี่ยต่อ PR, และการปรับโครงสร้างโค้ดที่แข็งแกร่ง (51.3%) จากตัวอย่างในการรีวิวโค้ด PR, เกม, และเว็บแอป Codex ได้พิสูจน์ความสามารถของมันในสถานการณ์จริง
แล้ว Codex สร้างโค้ดได้แม่นยำแค่ไหน? ค่อนข้างสูง—ประมาณ 70-90% สำหรับงานส่วนใหญ่ โดยมีการปรับปรุงซ้ำๆ ที่ผลักดันให้สูงขึ้นไปอีก มันไม่ได้ไร้ที่ติ แต่สำหรับการเพิ่มประสิทธิภาพการทำงาน มันคือผู้ชนะ หากคุณพร้อมที่จะลองใช้ ดาวน์โหลด Apidog เพื่อเริ่มต้นกับการทำเอกสารประกอบ API และการดีบัก—มันคือคู่หูที่สมบูรณ์แบบสำหรับการผจญภัยกับ Codex ของคุณ