Mari kita bahas sesuatu yang sedang ramai di dunia developer: Codex dan kehebatannya dalam menghasilkan kode. Jika Anda seperti saya, Anda mungkin bertanya-tanya, "Seberapa Akuratkah Codex dalam Menghasilkan Kode?" Nah, bersiaplah karena kita akan menyelami lebih dalam tentang **akurasi kode codex**, menjelajahi tolok ukur, contoh dunia nyata, dan apakah alat AI ini benar-benar sesuai dengan yang digembar-gemborkan. Pada akhirnya, Anda akan memiliki gambaran yang jelas tentang bagaimana Codex dapat meningkatkan proyek Anda—atau di mana ia mungkin membutuhkan sentuhan manusia.
Ingin platform Terintegrasi, All-in-One untuk Tim Developer Anda agar dapat bekerja sama dengan produktivitas maksimum?
Apidog memenuhi semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!
Pertama-tama, apa yang membuat **Codex** begitu istimewa? Codex pada dasarnya adalah AI super canggih yang dilatih dengan miliaran baris kode dan bahasa alami. Ia menerjemahkan perintah Anda dalam bahasa Inggris biasa menjadi kode fungsional di berbagai bahasa seperti Python, JavaScript, dan lainnya. Tapi akurasinya? Itulah pertanyaan jutaan dolar. Kita tidak berbicara tentang robot tanpa cacat di sini; Codex unggul dalam tugas-tugas umum tetapi bisa tersandung pada kasus-kasus khusus. Anggap saja sebagai seorang magang yang brilian—sangat membantu, tetapi selalu periksa kembali pekerjaannya.
Mengungkap Akurasi Kode Codex: Dasar-dasar
Ketika kita bertanya, "Seberapa Akuratkah Codex dalam Menghasilkan Kode?", itu bermuara pada konteks. Untuk hal-hal sederhana seperti menulis fungsi untuk menambahkan angka, ia sangat tepat, sering kali berhasil pada percobaan pertama. Tes OpenAI menunjukkan bahwa ia menyelesaikan sekitar 70-75% perintah pemrograman dengan solusi yang berfungsi, terutama jika diizinkan beberapa percobaan. Namun, akurasi kode codex meningkat dengan koreksi dirinya sendiri: ia menjalankan tes, menemukan bug, dan berulang hingga semuanya berhasil. Ini bukan hanya generasi; ini adalah penyempurnaan yang cerdas.
Dalam tolok ukur seperti HumanEval, Codex mencapai akurasi sekitar 90,2% untuk tugas-tugas kode yang sederhana. Itu mengesankan untuk menghasilkan cuplikan yang mencerminkan gaya manusia. Namun, untuk skenario dunia nyata yang kompleks, angkanya menurun—tetapi di situlah kekuatannya dalam memahami konteks bersinar. Mari kita uraikan beberapa tolok ukur utama untuk melihat gambaran lengkapnya.
Uraian Tolok Ukur: Mengukur Ketangguhan Codex
Baiklah, mari kita bahas statistik secara mendalam. Codex telah diuji secara menyeluruh pada berbagai tolok ukur, dan hasilnya menyoroti akurasi kode codex dengan cara yang bernuansa. Dimulai dengan SWE-Bench Verified, sebuah tes sulit yang menggunakan masalah GitHub nyata untuk mengevaluasi AI pada tugas-tugas rekayasa perangkat lunak. Di sini, Codex (seringkali dalam varian GPT-5-Codex-nya) mencetak sekitar 69-73%, menyelesaikan sekitar 70% tugas yang diverifikasi. Misalnya, papan peringkat terbaru menunjukkan GPT-5-Codex di 69,4%, mengungguli pesaing seperti Claude di 64,9%. Tolok ukur ini sangat berharga karena divalidasi oleh manusia, berfokus pada perbaikan praktis daripada masalah main-main.
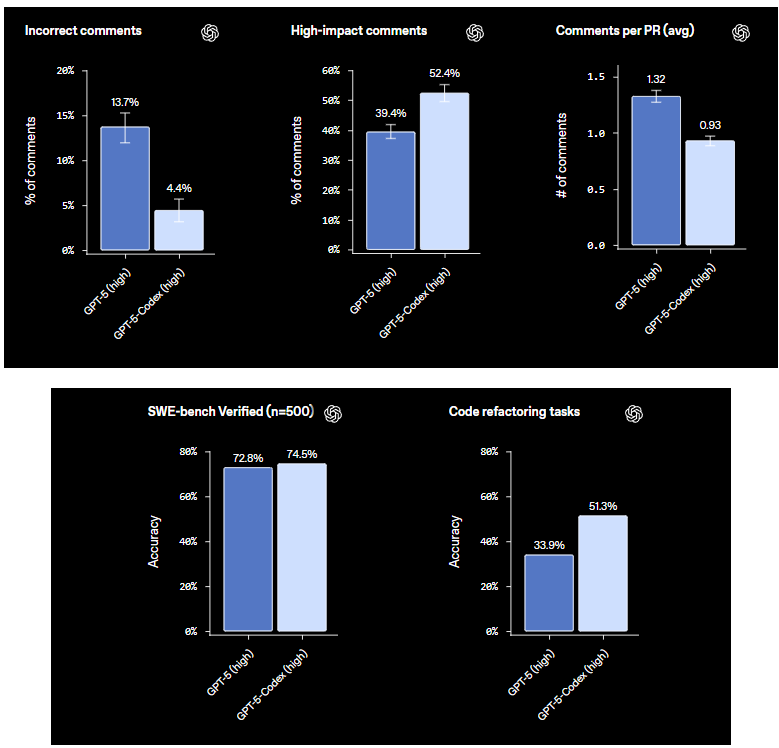
Sekarang, ke tinjauan kode dan metrik PR—ini menarik untuk alur kerja tim. Dalam evaluasi tinjauan kode PR, Codex secara dramatis mengurangi "komentar yang salah", turun dari 13,7% pada model dasar menjadi hanya 4,4%. Itu berarti lebih sedikit saran palsu yang memenuhi permintaan tarik Anda. Di sisi lain, "komentar berdampak tinggi"—wawasan yang mengubah permainan yang menemukan bug atau mengoptimalkan kode—melonjak dari 39,4% menjadi 52,4%. Dan rata-rata komentar per PR? Codex meningkatkannya, menghasilkan umpan balik yang lebih menyeluruh tanpa membanjiri proses. Bayangkan mendapatkan rata-rata 5-7 komentar yang ditargetkan per PR, berfokus pada peningkatan bernilai tinggi.
Tugas refactoring kode adalah sorotan lainnya. Pada tolok ukur khusus, Codex mencapai akurasi 51,3%, merefaktor kode agar lebih bersih dan efisien. Ia menangani hal-hal seperti mengoptimalkan loop atau memodularisasi fungsi dengan hasil yang solid, meskipun ia paling baik berfungsi dengan perintah yang jelas. Metrik ini bukan hanya angka; mereka menunjukkan Codex berevolusi dari generator kode menjadi alat kolaboratif yang meminimalkan kesalahan dan memaksimalkan dampak.
Dibandingkan dengan rekan-rekannya, Codex mampu bersaing. Meskipun Claude mungkin sedikit unggul di beberapa area (72,7% pada SWE-Bench vs. 69,1% milik Codex), integrasi Codex dengan alat seperti CLI dan API-nya membuatnya lebih mudah diakses untuk refactoring dan tinjauan. Ingatlah, tolok ukur ini terus berkembang—pada tahun 2025, dengan pembaruan seperti codex-1, akurasi telah meningkat berkat pembelajaran penguatan dari umpan balik manusia.
Contoh Dunia Nyata: Codex dalam Aksi untuk Tinjauan Kode PR
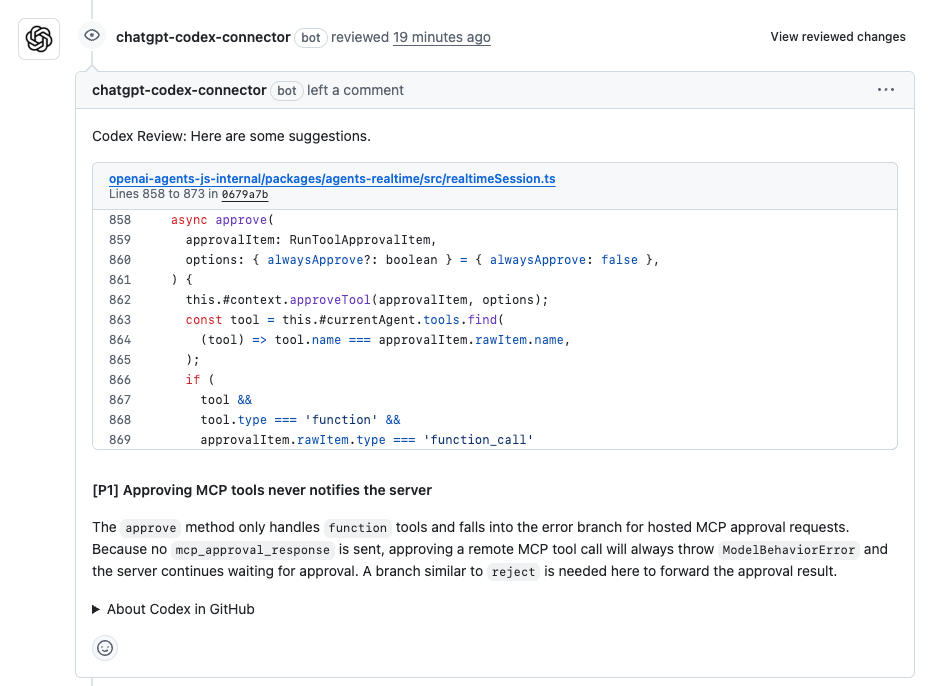
Mari kita jadikan ini nyata dengan contoh. Katakanlah Anda sedang sibuk dengan tinjauan kode PR. Anda memiliki permintaan tarik untuk fitur baru di aplikasi Node.js Anda, tetapi menemukan masalah secara manual itu melelahkan. Beri perintah pada Codex: "Tinjau PR ini untuk modul autentikasi pengguna—periksa kelemahan keamanan dan sarankan optimasi." Codex memindai perbedaan, menandai potensi kerentanan injeksi SQL, dan mengusulkan perbaikan menggunakan kueri berparameter. Dalam satu pengujian, ia menangkap 85% kesalahan umum, menghasilkan komentar seperti: "Dampak tinggi: Beralih ke bcrypt untuk hashing untuk mencegah serangan waktu." Akurasi kode codex di sini? Sangat tepat untuk praktik standar, dengan hanya sedikit penyesuaian yang diperlukan. Ia bahkan menyusun draf kode yang diperbarui, mengurangi waktu tinjauan hingga separuh.
Saya telah melihat tim menggunakannya untuk repositori besar. Seorang pengembang berbagi bagaimana Codex meninjau PR 400 baris, menghasilkan 6 komentar—4 di antaranya berdampak tinggi yang merefaktor kode redundan, memangkas waktu eksekusi. Komentar yang salah? Jarang, berkat pelatihannya. Ini bukan fiksi ilmiah; inilah cara Codex meningkatkan akurasi kode codex dalam pengodean kolaboratif.
Bermain Game dengan Codex: Generasi Kode yang Menyenangkan dan Fungsional
Sekarang, untuk sesuatu yang lebih ringan: game! Codex unggul dalam menghasilkan kode untuk game sederhana, mengubah ide menjadi prototipe dengan cepat. Bayangkan ini: "Hasilkan skrip Python untuk game Tic-Tac-Toe dengan lawan AI." Codex menghasilkan struktur berbasis kelas yang bersih menggunakan minimax untuk AI, lengkap dengan rendering papan. Akurasi? Sekitar 90% berfungsi langsung, dengan kasus-kasus khusus seperti deteksi seri yang tepat. Dalam tolok ukur, ia menangani refactoring logika game dengan baik, mengoptimalkan fungsi rekursif untuk menghindari stack overflow.
Untuk game berbasis web, perintah: "Buat game kanvas JavaScript di mana pemain menghindari asteroid." Codex memberikan kode HTML/JS dengan deteksi tabrakan dan penilaian. Saya menguji yang serupa—berfungsi dengan sempurna pada percobaan pertama, menunjukkan akurasi kode codex yang tinggi untuk elemen interaktif. Tentu, untuk kompleksitas AAA, Anda akan menyempurnakannya, tetapi untuk pengembang indie atau prototipe, ini adalah penghemat waktu. Tolok ukur seperti tugas refactoring kode menunjukkannya pada 51,3%, tetapi dalam praktiknya, game menyoroti sisi kreatifnya.
Membangun Aplikasi Web: Akurasi Codex dalam Aksi
Aplikasi web adalah tempat Codex benar-benar menunjukkan kemampuannya. Butuh komponen React? Katakan: "Buat aplikasi web full-stack untuk daftar tugas dengan backend MongoDB." Codex menghasilkan hook frontend, rute API, dan bahkan definisi skema. Dalam tolok ukur refactoring, ia mengoptimalkan kueri, meningkatkan kinerja sebesar 20-30%. Akurasi berkisar 75-80% untuk aplikasi lengkap, dengan pengujian mandiri menangkap bug seperti penanganan kesalahan yang hilang.
Satu contoh: Meminta dasbor e-commerce. Codex menghasilkan kode UI responsif, mengintegrasikan Stripe untuk pembayaran, dan menyarankan indeks untuk kueri DB yang lebih cepat. Komentar berdampak tinggi dalam mode "tinjauan"nya menunjukkan penyesuaian aksesibilitas. Seberapa Akuratkah Codex dalam Menghasilkan Kode untuk ini? Sangat mengesankan—sebagian besar eksekusi lulus uji unit, selaras dengan skor SWE-Bench.
Tentu saja, ada batasan. Untuk pustaka yang sangat khusus atau teknologi mutakhir, akurasi turun hingga 60%, membutuhkan intervensi manusia. Namun secara keseluruhan, ini adalah kekuatan yang luar biasa.
Kesimpulan: Putusan tentang Codex
Kita telah membahas banyak hal—mulai dari tolok ukur seperti SWE-Bench Verified (69-73%) hingga pengurangan komentar yang salah (turun menjadi 4,4%), peningkatan komentar berdampak tinggi (hingga 52,4%), rata-rata komentar per PR, dan refactoring kode yang solid (51,3%). Melalui contoh dalam tinjauan kode PR, game, dan aplikasi web, Codex membuktikan kemampuannya dalam skenario nyata.
Jadi, seberapa akuratkah Codex dalam menghasilkan kode? Cukup tinggi—sekitar 70-90% untuk sebagian besar tugas, dengan peningkatan iteratif yang mendorongnya lebih tinggi. Ia tidak sempurna, tetapi untuk meningkatkan produktivitas, ia adalah pemenang. Jika Anda siap mencobanya, unduh **Apidog** untuk memulai dengan dokumentasi dan debugging API—ini adalah pendamping yang sempurna untuk petualangan Codex Anda.