
Entwickler suchen nach effizienten Möglichkeiten, fortschrittliche Sprachmodelle in ihre Anwendungen zu integrieren. INTELLECT-3 erweist sich als eine überzeugende Option aufgrund seiner Open-Source-Grundlage und seiner starken Leistung bei Denkaufgaben. Dieses von Prime Intellect entwickelte Modell zeichnet sich durch seine 106 Milliarden Parameter starke Mixture-of-Experts (MoE)-Architektur aus, die eine hohe Effizienz bei der Bewältigung komplexer Berechnungen ermöglicht.
INTELLECT-3 verstehen: Das Open-Source-Kraftpaket
Prime Intellect veröffentlicht INTELLECT-3 als vollständig Open-Source-Modell, das Forschern und Entwicklern ermöglicht, seine Fähigkeiten ohne proprietäre Barrieren anzupassen und zu erweitern. Diese Transparenz fördert Innovationen in Bereichen wie Reinforcement Learning (RL) und agentischen KI-Systemen. Sie erhalten direkten Zugriff auf das komplette Paket, einschließlich Modellgewichten, Trainings-Frameworks, Datensätzen, RL-Umgebungen und Evaluierungstools, direkt aus den Repositories von Prime Intellect.

Im Kern verwendet INTELLECT-3 eine 106 Milliarden Parameter starke MoE-Architektur, die auf dem GLM-4.5-Air-Basismodell aufbaut. MoE-Designs leiten Eingaben an spezialisierte "Experten"-Subnetzwerke weiter, was die Computernutzung optimiert und die Inferenz beschleunigt. Zum Beispiel aktiviert das Modell während der Verarbeitung nur eine Untermenge von Parametern, die für die Abfrage relevant sind, wodurch die Latenz reduziert und gleichzeitig die Genauigkeit erhalten bleibt. Diese Einrichtung erweist sich als besonders effektiv für Aufgaben, die selektive Expertise erfordern, wie mathematische Ableitungen oder Codegenerierung.
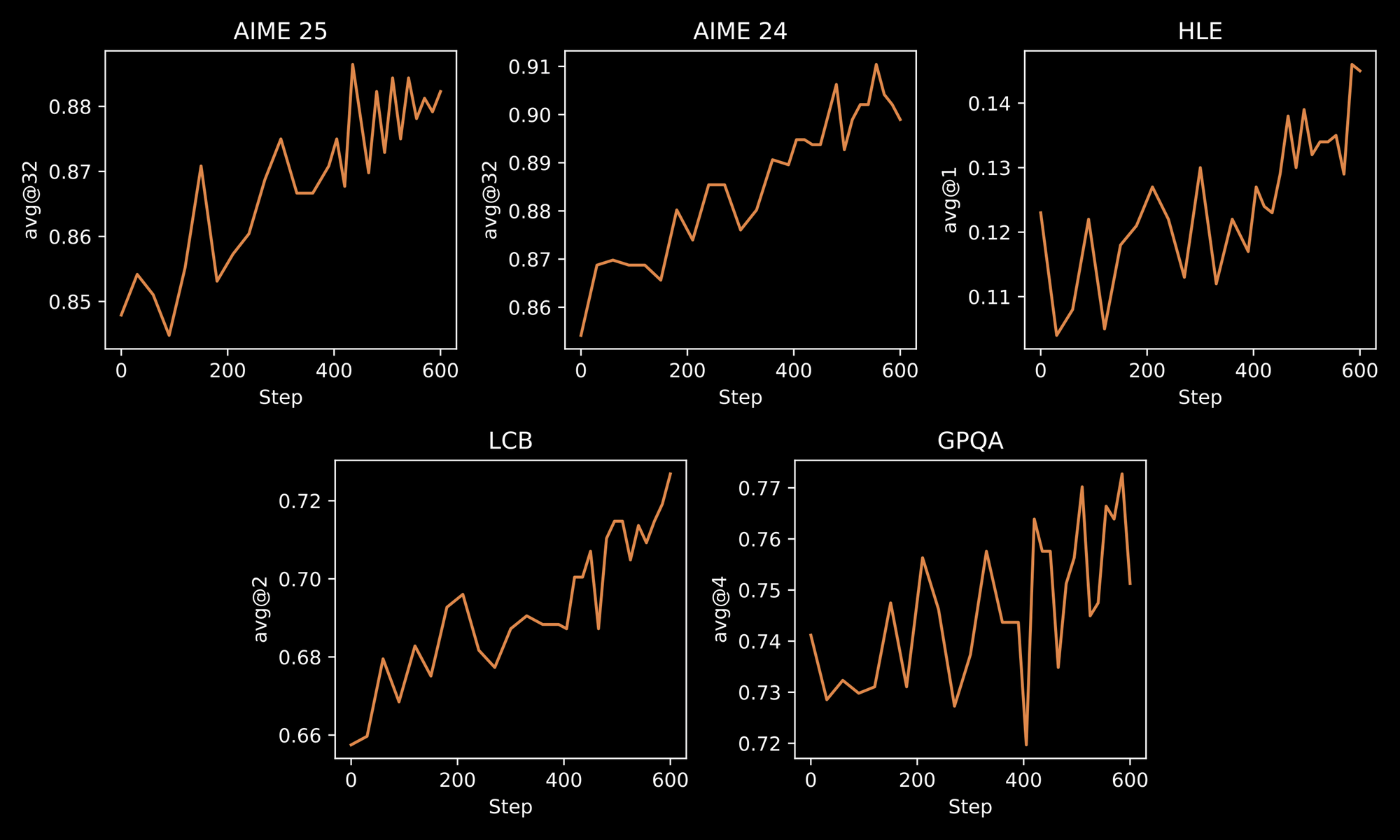
Der Trainingsprozess unterstreicht die Robustheit von INTELLECT-3. Ingenieure wenden eine zweistufige Methodik an: anfängliches Supervised Fine-Tuning (SFT) auf kuratierten Datensätzen, gefolgt von groß angelegtem RL unter Verwendung des benutzerdefinierten prime-rl-Frameworks. prime-rl arbeitet als asynchrones Off-Policy-RL-System, das große parallele Simulationen effizient verarbeitet. Davon profitieren Sie durch verbesserte Modellverhaltensweisen in dynamischen Umgebungen, wie iterativer Problemlösung oder mehrstufiger Planung.
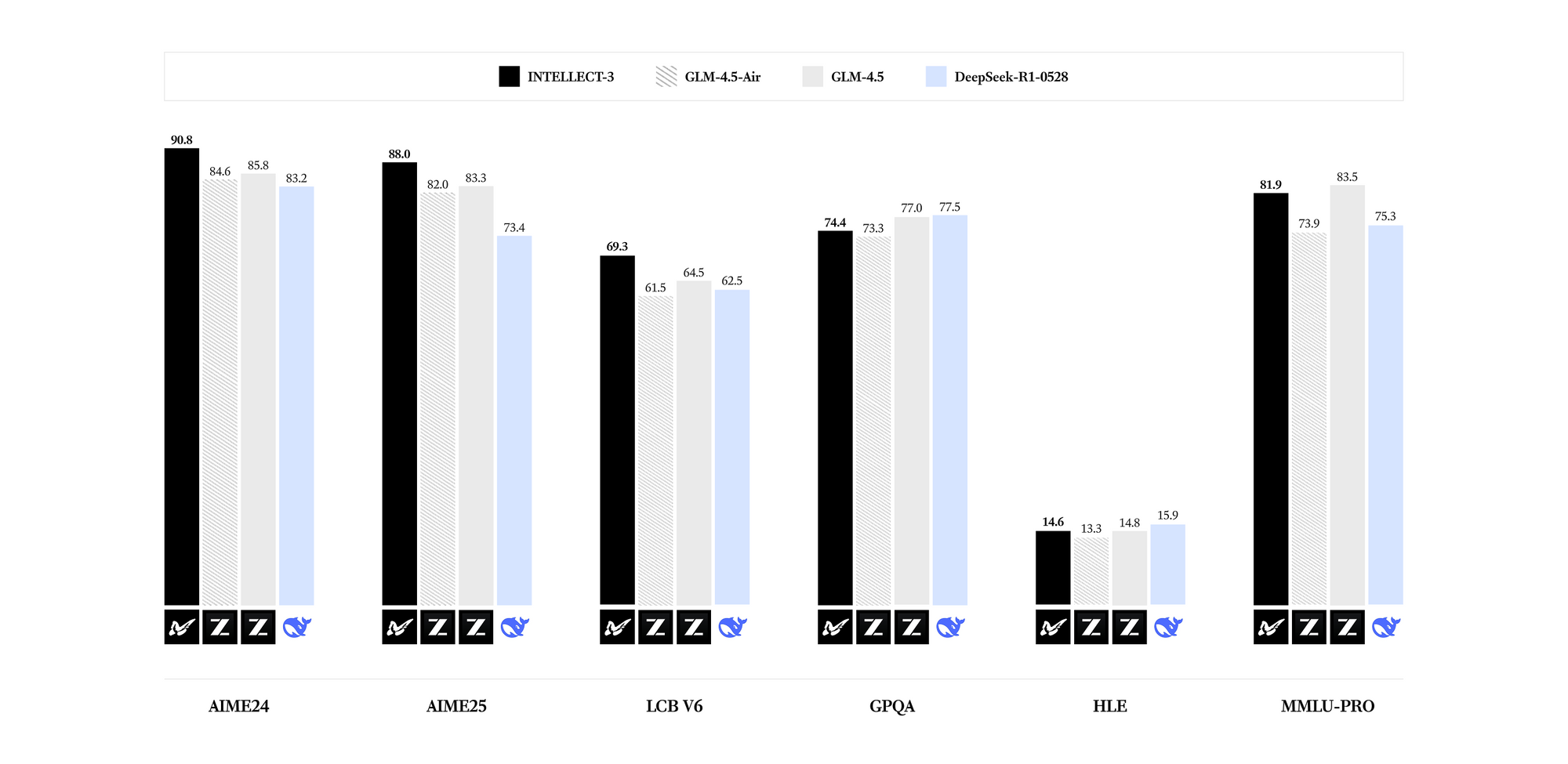
INTELLECT-3 glänzt in spezialisierten Domänen. Benchmarks zeigen modernste Ergebnisse für seine Parameteranzahl in Mathematik (z.B. GSM8K-Werte über 95%), Codierung (HumanEval-Passraten über 85%), Wissenschaft (GPQA-Genauigkeit über 60%) und Denkaufgaben (MMLU-Werte nahe 80%). Im Vergleich zu dichteren Modellen wie Llama 3.1 70B erreicht INTELLECT-3 eine überlegene Effizienz – bis zu 2x schnellere Inferenz auf gleichwertiger Hardware – aufgrund seiner spärlichen Aktivierungsmuster. Folglich können Sie es in ressourcenbeschränkten Umgebungen einsetzen, ohne die Ausgabequalität zu beeinträchtigen.
Die unterstützende Infrastruktur erhöht seine Attraktivität als Open-Source-Modell. Der Verifiers & Environments Hub bietet über 500 RL-Umgebungen, von einfachen Rätseln bis hin zu fortgeschrittenen Theorem-Provern.
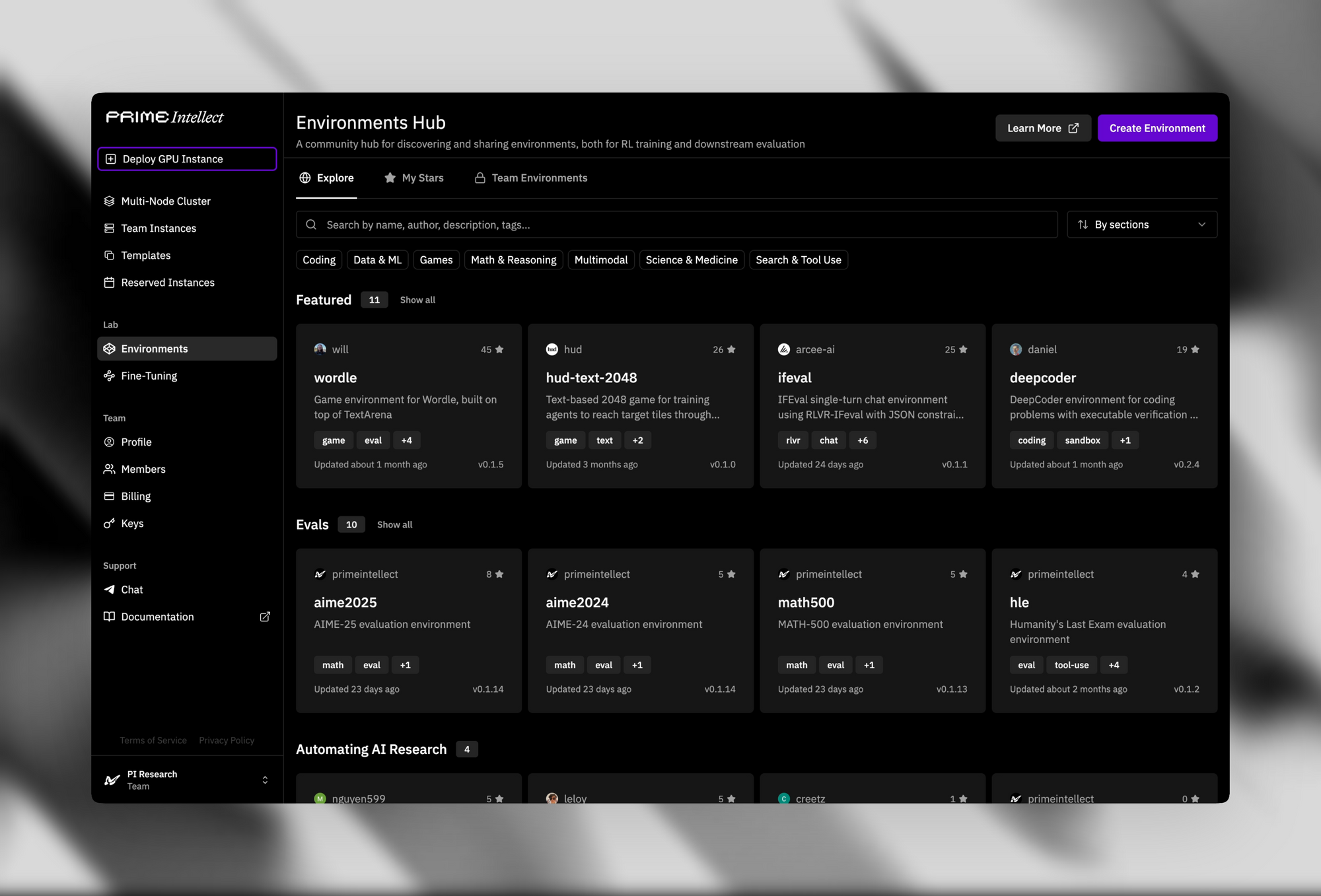
Prime Sandboxes bieten eine sichere Code-Ausführung mit hohem Durchsatz, die Agentenaktionen während des Trainings oder der Inferenz isoliert. Entwickler nutzen diese Tools, um INTELLECT-3 für benutzerdefinierte Anwendungen, wie autonome Agenten in Softwareentwicklungs-Pipelines, feinabzustimmen.
In der Praxis laden Sie die Modellgewichte über Hugging Face oder das GitHub von Prime Intellect herunter. Die Installation erfordert Standardabhängigkeiten wie PyTorch und die Transformers-Bibliothek. Ein einfaches Skript zum Laden des Modells sieht wie folgt aus:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
Dieser Code initialisiert das Modell auf GPU-fähiger Hardware. Für den Einsatz im Produktionsmaßstab wechseln Sie jedoch zu gehosteten APIs, da Self-Hosting erhebliche Rechenleistung (z.B. mehrere A100 GPUs) erfordert. Daher legt der Open-Source-Zugriff die Grundlage, aber die API-Integration skaliert Ihre Bereitstellungen effektiv.
Vom lokalen Experimentieren gehen Sie nun dazu über, wie Sie INTELLECT-3 über verwaltete Dienste zugreifen können. Dieser Übergang gewährleistet Zuverlässigkeit und bewältigt die Komplexitäten der verteilten Inferenz.
Zugriff auf die INTELLECT-3 API: Einrichtung und Authentifizierung
Option 1 – Prime Intellect Nativer Endpunkt (Empfohlen für maximale Leistung & geringste Latenz)
Sie beginnen den API-Zugriff, indem Sie Anmeldeinformationen von der Prime Intellect-Plattform erhalten. Besuchen Sie das Prime Intellect Dashboard unter app.primeintellect.ai und erstellen Sie bei Bedarf ein Konto.
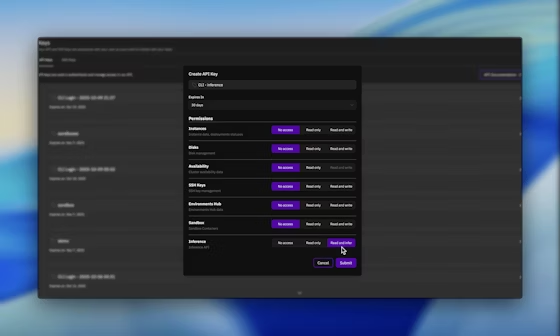
Nach dem Einloggen navigieren Sie zum Abschnitt "API-Schlüssel" und generieren einen neuen Schlüssel mit aktivierten Inferenzberechtigungen. Dieser Schlüssel authentifiziert alle nachfolgenden Anfragen und gewährleistet einen sicheren Zugriff auf INTELLECT-3.
Konfigurieren Sie als Nächstes Ihre Umgebung. Legen Sie den API-Schlüssel als Umgebungsvariable für eine nahtlose Integration fest:
export PRIME_API_KEY="your-api-key-here"
Für teambasierte Workflows fügen Sie den X-Prime-Team-ID Header in Anfragen ein. Dieser Bezeichner leitet die Nutzung an den richtigen Abrechnungspool weiter und verhindert kontoübergreifende Gebühren. Sie rufen die Team-ID aus dem Dashboard unter den Kontoeinstellungen ab.
Die API verwendet eine OpenAI-kompatible Schnittstelle, was die Akzeptanz vereinfacht, wenn Sie bereits Bibliotheken wie openai-python verwenden. Geben Sie die Basis-URL als https://api.pinference.ai/api/v1 an. Dieser Endpunkt leitet Anfragen an optimierte Inferenzanbieter, einschließlich Parasail und Nebius, weiter, die INTELLECT-3-Instanzen hosten. Dadurch erzielen Sie Antworten mit geringer Latenz, ohne die zugrunde liegenden Cluster verwalten zu müssen.
Um den Zugriff zu überprüfen, fragen Sie den Modelle-Endpunkt ab. Dieser listet die verfügbaren Modelle auf und bestätigt die Präsenz von INTELLECT-3 (typischerweise unter einem Handle wie prime-intellect/intellect-3). Verwenden Sie das CLI-Tool für schnelle Überprüfungen:
prime inference models
Alternativ senden Sie eine GET-Anfrage über curl:
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
Die Antwort gibt ein JSON-Array von Modellobjekten zurück, die jeweils Parameter wie id, max_tokens und context_window detaillieren. INTELLECT-3 unterstützt einen 128K Token-Kontext, der lange Argumentationsketten aufnehmen kann.
Die Authentifizierung umfasst auch Ratenbegrenzungen und Quoten. Prime Intellect setzt minütliche und tägliche Limits basierend auf Ihrem Plan durch, die im Dashboard sichtbar sind. Sie überwachen die Nutzung über den Reiter "Abrechnung", der verarbeitete Token und getätigte API-Aufrufe protokolliert. Wenn Limits Ihren Workflow einschränken, können Sie nahtlos über die Plattform upgraden.
Darüber hinaus integrieren Sie mit Apidog für erweiterte Tests. Importieren Sie das OpenAI-Schema in Apidog und simulieren Sie dann Anfragen an INTELLECT-3-Endpunkte. Diese Praxis identifiziert Probleme frühzeitig, wie z.B. fehlerhafte JSON-Payloads. Der kostenlose Tier von Apidog genügt für erste Setups und überbrückt die Lücke zwischen lokaler Entwicklung und Produktions-APIs.
Sobald die Authentifizierung eingerichtet ist, können Sie mit der Erstellung von Anfragen fortfahren. Der folgende Abschnitt beschreibt präzise Formate, um optimale Antworten von INTELLECT-3 zu erhalten.
Option 2 – OpenRouter (Sofortzugang & vereinheitlichte Credits)
Neben dem Self-Hosting oder der Nutzung der nativen Inferenzplattform von Prime Intellect ist INTELLECT-3 auch offiziell auf OpenRouter verfügbar. Dies bietet Ihnen ein alternatives Gateway mit vereinheitlichter Abrechnung, automatischem Fallback-Routing und sofortigem Zugriff – kein separates Prime Intellect-Konto erforderlich, wenn Sie OpenRouter bereits verwenden.
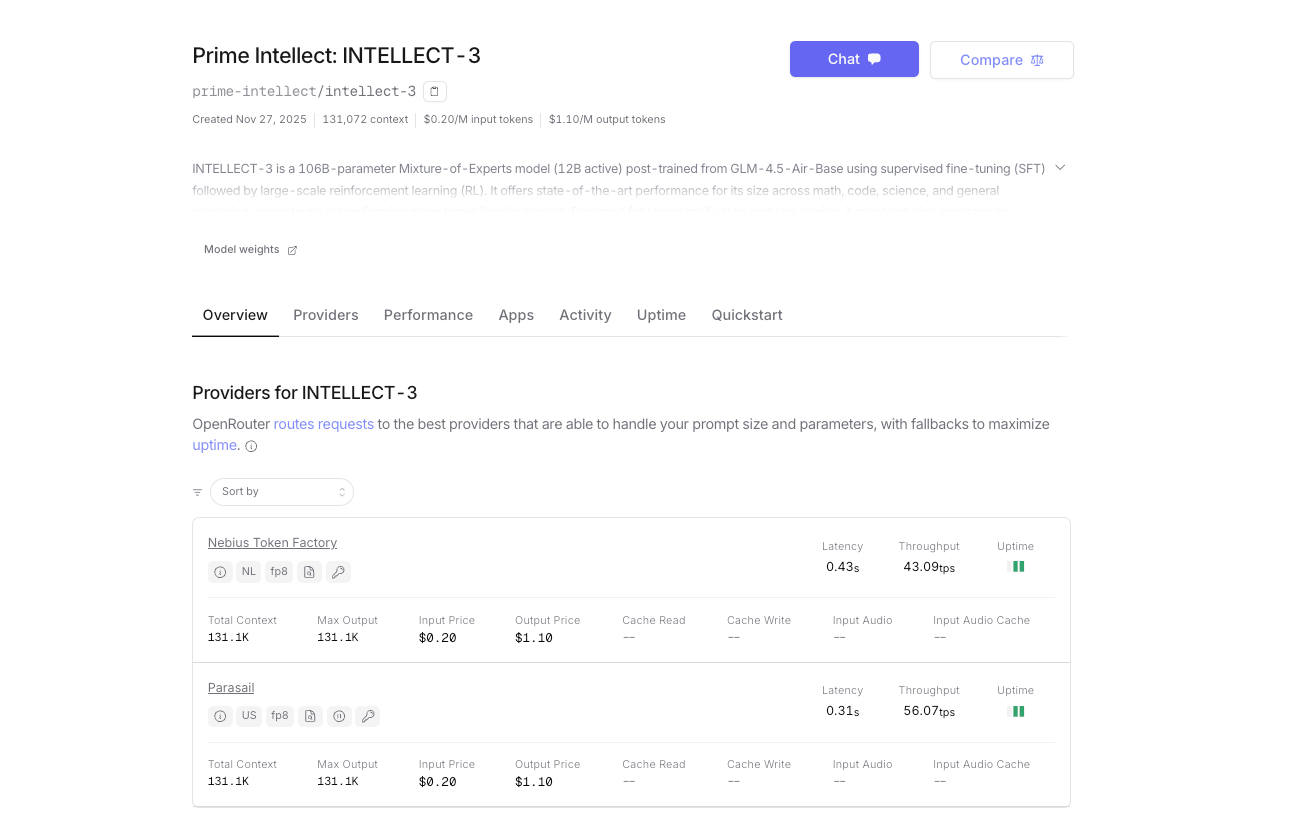
- Basis-URL: https://openrouter.ai/api/v1
- Modellname: prime-intellect/intellect-3
- Authentifizierung: Ihr OpenRouter API-Schlüssel (OPENROUTER_API_KEY)
- Automatisches Anbieter-Routing (derzeit von Prime Intellect Clustern bereitgestellt)
- Pay-as-you-go mit OpenRouter-Credits; etwas höhere Kosten pro Token aufgrund der Plattformgebühr
Beide Endpunkte unterstützen identische Anforderungs-/Antwortschemata, Streaming, Tool-Aufrufe und den JSON-Modus.
Anfragen an die INTELLECT-3 API stellen: Formate und Beispiele
Sie initiieren Interaktionen über den /chat/completions-Endpunkt, der konversationelle und aufgabenorientierte Prompts verarbeitet. Erstellen Sie Anfragen als JSON-Objekte mit Feldern für model, messages, temperature und max_tokens. Das messages-Array ahmt Chat-Verläufe nach, wobei Rollen wie "system", "user" und "assistant" verwendet werden.
Betrachten Sie ein einfaches Beispiel für die Codegenerierung. Sie senden:
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
Dieser Code gibt eine rekursive Fibonacci-Implementierung mit Memoization aus und nutzt dabei die Codierungsfähigkeiten von INTELLECT-3. Der temperature-Parameter steuert die Kreativität – niedrigere Werte (z.B. 0,2) begünstigen deterministische Ausgaben für faktische Abfragen, während höhere Werte (bis zu 1,0) vielfältige Denkwege fördern.
Für mathematisches Denken strukturieren Sie Prompts so, dass Gedanken verkettet werden. Das RL-Training von INTELLECT-3 glänzt hier, da es eine schrittweise Überprüfung simuliert. Beispiel:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
Das Modell antwortet mit einem strengen Beweis, der Axiome und Theoreme zitiert. Sie parsen die Ausgabe über response.choices[0].message.content, die als String ankommt. Für strukturierte Daten aktivieren Sie den JSON-Modus, indem Sie "response_format": {"type": "json_object"} zur Anfrage hinzufügen, um parsierbare Antworten zu gewährleisten.
Die fortgeschrittene Nutzung beinhaltet Tool-Calling, bei dem INTELLECT-3 externe Funktionen integriert. Definieren Sie Tools in der Anfrage:
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
Wenn das Modell das Tool aufruft, gibt es Argumente in response.choices[0].message.tool_calls zurück. Sie führen die Funktion extern aus und speisen die Ergebnisse in einer Folgemeldung zurück. Dieses Muster erstellt agentenbasierte Workflows, die die in der Umgebung trainierten Verhaltensweisen von INTELLECT-3 nutzen.
Fehlerbehandlung ist ein kritischer Bestandteil. Häufige Probleme sind 401 (ungültiger Schlüssel), 429 (Ratenbegrenzung) und 400 (fehlerhafte Anfrage). Implementieren Sie Wiederholungen mit exponentiellem Backoff:
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
Antworten enthalten Metadaten wie usage (prompt_tokens, completion_tokens, total_tokens), die Sie zur Optimierung protokollieren. INTELLECT-3 verarbeitet bis zu 4096 Tokens pro Completion und gleicht dabei Tiefe und Geschwindigkeit aus.
Streaming-Antworten verbessern Echtzeit-Anwendungen. Fügen Sie stream=True zum Erstellungsaufruf hinzu; der Client liefert Chunks als Server-Sent Events. Parsen Sie diese iterativ:
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Diese Technik eignet sich für Chatbots oder Live-Code-Assistenten, bei denen Benutzer inkrementelles Feedback erwarten.
Nachdem Sie die Anfragenerstellung gemeistert haben, bewerten Sie die Leistung. Der nächste Abschnitt stellt Benchmarking-Tools vor, die auf INTELLECT-3 zugeschnitten sind.
Optimierung und Bewertung der INTELLECT-3 API-Nutzung
Sie optimieren API-Aufrufe, indem Sie Parameter empirisch einstellen. Beginnen Sie mit der Stapelverarbeitung mehrerer Nachrichten in einer Anfrage, um den Durchsatz zu erhöhen – bis zu 10-fache Effizienz in Evaluationssuiten. Die CLI von Prime Intellect unterstützt dies:
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
Dieser Befehl führt 100 GSM8K-Beispiele aus und aggregiert Genauigkeits- und Latenzmetriken. Sie analysieren die Ergebnisse, um top_p oder frequency_penalty anzupassen, was die Wiederholung in langen Generierungen mildert.
Die Evaluation erstreckt sich auf benutzerdefinierte Umgebungen aus dem Verifiers Hub. Laden Sie eine RL-Umgebung und fragen Sie INTELLECT-3 als Richtlinie ab:
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
Belohnungen quantifizieren Verbesserungen und leiten das Fine-Tuning, wenn Sie lokal hosten. Für reine API-Benutzer protokollieren Sie Interaktionen in einer Vektordatenbank und berechnen nachgelagerte Metriken wie die Aufgabenerfolgsrate.
Sicherheitsaspekte sind ebenfalls wichtig. Bereinigen Sie Benutzereingaben, um Prompt-Injection zu verhindern, und verwenden Sie System-Prompts, um Grenzen durchzusetzen. Der RL-Hintergrund von INTELLECT-3 reduziert Halluzinationen, aber Sie validieren Ausgaben gegen Verifizierer für risikoreiche Anwendungen.
Skalierung beinhaltet die Überwachung über das Dashboard. Legen Sie Warnungen für Token-Schwellenwerte fest und integrieren Sie sich in Observability-Tools wie Prometheus, die Prime Intellect für Cluster bereitstellt. So gewährleisten Sie die Zuverlässigkeit, wenn die Nutzung steigt.
Nachdem Sie nun die Optimierung beherrschen, betrachten Sie die Kosten. Preistransparenz gewährleistet eine nachhaltige Integration.
INTELLECT-3 API-Preise: Transparentes tokenbasiertes Modell
Prime Intellect strukturiert die Preisgestaltung um den Token-Verbrauch und berechnet Input und Output getrennt. Sie zahlen pro 1.000 Tokens, wobei die Raten je nach Modell und Anbieter variieren. Für INTELLECT-3, erwarten Sie wettbewerbsfähige Zahlen – etwa 0,50 $ pro Million Input-Tokens und 1,50 $ pro Million Output-Tokens – obwohl genaue Werte in der Modelle-Endpunkt-Antwort erscheinen.
| Anbieter | Input ($$ /1M Tokens) | Output ( $$/1M Tokens) | Hinweise |
|---|---|---|---|
| Prime Intellect Direkt | ~0,45–0,60 $ | ~1,30–1,80 $ | Niedrigste Kosten, Mengenrabatte |
| OpenRouter | ~0,60–0,80 $ | ~1,80–2,40 $ | Inklusive OpenRouter Plattformgebühr |
Genaue Raten schwanken; überprüfen Sie immer die neuesten Werte in Ihrem Dashboard oder über den Modelle-Endpunkt.
Welche sollten Sie wählen?
- Wählen Sie Prime Intellect direkt, wenn Sie maximale Geschwindigkeit, niedrigste Kosten oder eine hohe Nutzung planen.
- Wählen Sie OpenRouter, wenn Sie einen einzigen API-Schlüssel für über 50 Modelle bevorzugen, sofortiges Onboarding benötigen oder ein integriertes Fallback-Routing wünschen.
Beide Optionen liefern die gleiche INTELLECT-3 Leistung. Wählen Sie diejenige, die zu Ihrem Workflow passt – viele Teams verwenden sogar beide gleichzeitig für Redundanz.
Der Rest dieses Leitfadens (Anfrageformate, Streaming, Tool-Aufrufe, Optimierung usw.) gilt gleichermaßen, egal ob Sie Prime Intellect direkt oder über OpenRouter aufrufen.
Fahren Sie mit den vollständigen technischen Implementierungsdetails unten fort und beginnen Sie noch heute mit INTELLECT-3 zu entwickeln – über das Gateway, das für Sie am besten geeignet ist.
Fortgeschrittene Integrationen mit der INTELLECT-3 API
Sie erweitern INTELLECT-3 in Ökosysteme wie LangChain oder LlamaIndex zur Orchestrierung. In LangChain:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
Dies bindet die API an Retrieval-Augmented Generation (RAG)-Pipelines und verbessert die Genauigkeit durch externes Wissen.
Für Microservices implementieren Sie über FastAPI-Wrapper, die an INTELLECT-3 proxyn:
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
Legen Sie diesen Endpunkt sicher frei und beschränken Sie die Rate mit Redis. Solche Setups treiben SaaS-Tools an, von Content-Generatoren bis hin zu Forschungsassistenten.
Grenzfälle erfordern Aufmerksamkeit. Behandeln Sie Token-Überläufe, indem Sie Eingaben dynamisch kürzen, und greifen Sie auf kleinere Modelle zurück, wenn INTELLECT-3 in der Warteschlange ist. Community-Foren auf der Prime Intellect-Website bieten Troubleshooting-Threads.
Fazit: INTELLECT-3 API mit Vertrauen einsetzen
Sie verfügen nun über ein umfassendes Toolkit für die Nutzung der INTELLECT-3 API. Von ihren Open-Source-Wurzeln bis hin zur präzisen Anfragenbearbeitung und Kostenverwaltung rüstet Sie dieser Leitfaden für reale Bereitstellungen aus. Experimentieren Sie mit Apidog, um Ihre Workflows zu verfeinern, und überwachen Sie die sich entwickelnden Dokumentationen auf Updates.
Implementieren Sie diese Techniken inkrementell – beginnen Sie mit einfachen Chats und skalieren Sie dann auf Agenten. Die Effizienz und Offenheit von INTELLECT-3 positionieren es als erste Wahl für technische KI-Projekte. Beginnen Sie noch heute mit dem Codieren und erleben Sie die Auswirkungen auf Ihre Anwendungen.