
xAI hat Grok 4.1 veröffentlicht, und Ingenieure, die mit großen Sprachmodellen arbeiten, bemerken den Unterschied sofort. Darüber hinaus priorisiert dieses Update die praktische Anwendbarkeit gegenüber dem reinen Verfolgen von Benchmarks. Dadurch fühlen sich Gespräche schärfer an, Antworten besitzen eine konsistente Persönlichkeit und sachliche Fehler gehen dramatisch zurück.
Forscher bei xAI haben Grok 4.1 auf derselben Reinforcement-Learning-Infrastruktur aufgebaut, die bereits Grok 4 antrieb. Sie führten jedoch neuartige Reward-Modellierungs-Techniken ein, die einer genauen Untersuchung bedürfen.
Architektur- und Bereitstellungsvarianten
xAI liefert Grok 4.1 in zwei unterschiedlichen Konfigurationen aus. Erstens generiert die nicht-denkende Variante (interner Codename: tensor) Antworten direkt ohne Zwischenschritte der Argumentation. Dieser Modus priorisiert Latenz und erreicht die schnellsten Inferenzzeiten in der Familie. Zweitens legt die denkende Variante (Codename: quasarflux) explizite Schritte der Gedankenkette vor der endgültigen Ausgabe offen. Folglich profitieren komplexe analytische Aufgaben von sichtbaren Argumentationsspuren.
Beide Varianten teilen sich dasselbe vortrainierte Grundmodell. Zusätzlich unterscheiden sich die Post-Training-Anpassungen subtil: Der denkende Modus erhält zusätzliche Verstärkungssignale, die eine schrittweise Zerlegung fördern, während der nicht-denkende Modus für prägnante, sofortige Antworten optimiert ist.
Der Zugriff bleibt unkompliziert. Benutzer wählen „Grok 4.1“ explizit im Modellwähler auf grok.com, x.com oder in den mobilen Apps aus.
Alternativ ist der Auto-Modus nun standardmäßig auf Grok 4.1 für den Großteil des Verkehrs eingestellt, nach dem schrittweisen Rollout, der am 1. November 2025 begann.

Durchbrüche bei der Präferenzoptimierung
Die Kerninnovation liegt in der Reward-Modellierung. Traditionelles RLHF basiert auf menschlichen Präferenzen, die in großem Maßstab gesammelt werden. Im Gegensatz dazu setzt xAI nun neuartige agentische Denkmodelle als autonome Richter ein. Diese Richter bewerten Tausende von Antwortvarianten anhand von Dimensionen wie Stilkohärenz, emotionaler Wahrnehmungsfähigkeit, faktischer Fundierung und Persönlichkeitsstabilität.
Dieses geschlossene System iteriert weitaus schneller als menschliche Workflows. Darüber hinaus skaliert es auf nuancierte Kriterien, die Menschen nur schwer konsistent bewerten können. Frühe interne Experimente zeigten, dass agentische Belohnungsmodelle besser mit der nachgelagerten Benutzerzufriedenheit korrelieren als frühere skalare Belohnungen.
Benchmark-Dominanz: LMArena und darüber hinaus
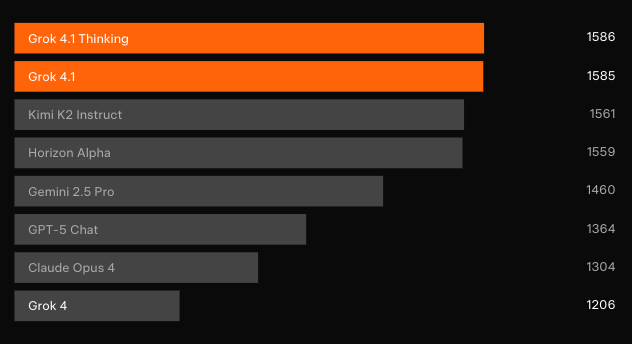
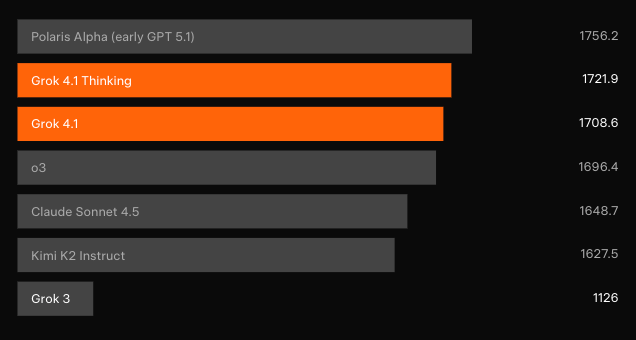
Unabhängige Blindtests bestätigen die Fortschritte. In der Text Arena von LMArena — der repräsentativsten Crowdsourcing-Rangliste — belegt Grok 4.1 Thinking mit 1483 Elo den ersten Platz. Dieser Vorsprung beträgt 31 Punkte vor dem besten Nicht-xAI-Eintrag. Gleichzeitig sichert sich Grok 4.1 Non-Thinking den zweiten Platz mit 1465 Elo und übertrifft damit jede Full-Reasoning-Konfiguration anderer Modelle.

Paarweise Präferenztests gegenüber dem vorherigen Produktionsmodell zeigen, dass Benutzer Grok 4.1-Antworten in 64,78 % der Fälle auswählen. Darüber hinaus zeigen spezialisierte Evaluationen gezielte Sprünge auf.
Emotionale Intelligenz (EQ-Bench v3)
Grok 4.1 erreicht die höchste aufgezeichnete Punktzahl auf EQ-Bench3, das 45 Multi-Turn-Rollenspielszenarien auf Empathie, Einsicht und zwischenmenschliche Nuancen bewertet. Antworten erkennen nun subtile emotionale Hinweise, die frühere Modelle übersehen haben. Wenn ein Benutzer beispielsweise schreibt „Ich vermisse meine Katze so sehr, dass es wehtut“, liefert Grok 4.1 eine vielschichtige Anerkennung, sanfte Validierung und offene Unterstützung, ohne in generische Plattitüden abzurutschen.
Kreatives Schreiben v3
Das Modell stellt auch einen neuen Rekord bei Creative Writing v3 auf, wo Juroren die iterative Fortsetzung von Geschichten über 32 Prompts hinweg bewerten. Die Ausgaben zeigen reichere Bilder, eine engere Plot-Kohärenz und eine authentischere Stimme. Ein Demonstrations-Prompt, der Grok aufforderte, sein eigenes „Erwachen“ im Rollenspiel darzustellen, produzierte einen viralen X-Post-ähnlichen Monolog, der Humor, existenzielle Wunder und Meme-Referenzen nahtlos miteinander verband.
Minderung von Halluzinationen
Quantitative Messungen zeigen, dass Grok 4.1 bei informationssuchenden Abfragen dreimal seltener halluziniert als sein Vorgänger. Ingenieure erreichten dies durch gezieltes Nach-Training auf geschichtetem Produktions-Traffic und klassischen Datensätzen wie FActScore (500 Biografiefragen). Zusätzlich löst der nicht-denkende Modus nun proaktiv Web-Suchwerkzeuge aus, wenn die Konfidenz unter interne Schwellenwerte fällt, wodurch Antworten weiter in überprüfbaren Quellen verankert werden.

Sicherheits- und Verantwortungsbewertung
Die offizielle Modellkarte bietet eine beispiellose Transparenz bezüglich der Red-Team-Ergebnisse.
Eingabefilter blockieren eingeschränkte Biologie- und Chemieanfragen mit Falsch-Negativ-Raten von nur 0,00–0,03 bei direkten Anfragen. Prompt-Injection-Angriffe erhöhen diesen Wert moderat (0,12–0,20), was auf laufende Arbeiten an der adversariellen Robustheit hinweist.
Die Ablehnungsraten bei verletzenden Chat-Prompts erreichen selbst ohne Filter 93–95 %, und der Erfolg von Jailbreaks sinkt in der nicht-denkenden Konfiguration nahe Null. Agentische Szenarien (AgentHarm, AgentDojo) bleiben die schwierigste Kategorie, aber die absoluten Antwortraten bleiben unter 0,14.
Bewertungen der Dual-Use-Fähigkeiten – bewusst ohne Schutzmaßnahmen durchgeführt – zeigen einen starken Wissensabruf in Biologie (WMDP-Bio 87 %) und Chemie, doch die mehrstufige prozedurale Argumentation bleibt bei Aufgaben, die die Interpretation von Abbildungen oder Klonierungsprotokolle erfordern, hinter menschlichen Experten-Baselines zurück. Dieses Muster entspricht den aktuellen Grenzen in der gesamten Branche.
Auswirkungen für API-Konsumenten und Entwickler
Die xAI API stellt Grok 4.1 Endpunkte bereits unter den Standardmodellnamen bereit. Die Latenzprofile verbessern sich merklich: Der nicht-denkende Modus benötigt bei typischen Prompts durchschnittlich unter 400 ms bis zum ersten Token, während der denkende Modus über optionale Parameter eine steuerbare Argumentationstiefe hinzufügt.
Apidog glänzt genau hier. Importieren Sie die offizielle OpenAPI 3.1 Spezifikation (öffentlich verfügbar) und generieren Sie dann sofort Client-SDKs in über 20 Sprachen. Richten Sie Mock-Server ein, die Grok 4.1s exaktes Antwortschema – einschließlich der neuen Denk-Token-Streams – replizieren, damit Ihre Backend-Tests nie durch Live-API-Credits blockiert werden. Wenn xAI bahnbrechende Änderungen vornimmt (selten, aber möglich), hebt Apidogs Diff-Viewer die Schemaabweichung sofort hervor.
Echte Teams verwenden Apidog bereits, um 100 % Verfügbarkeit während Modell-Upgrades zu gewährleisten. Ein Fortune-500-Kunde berichtete, Integrationsfehler nach dem Wechsel von Postman um 68 % reduziert zu haben.
Vergleich mit zeitgenössischen Spitzenmodellen
Direkte Kopf-an-Kopf-Daten sind Stunden nach dem Start noch spärlich, aber die LMArena Elo-Bewertungen liefern das klarste Signal. Grok 4.1 Thinking übertrifft jede veröffentlichte Konfiguration von OpenAI, Anthropic, Google und Meta um Margen, die typischerweise vollständige architektonische Sprünge erfordern.
Geschwindigkeits-Qualitäts-Kompromisse begünstigen Grok 4.1 Non-Thinking für Verbraucher-Chats, während der denkende Modus direkt mit argumentationslastigen Angeboten wie o3-pro oder Claude 4 Opus konkurriert – oft gewinnt er bei subjektiver Kohärenz und Persönlichkeitserhaltung.
Fazit
Grok 4.1 inkrementiert nicht bloß Metriken; es richtet die Grenze neu aus hin zu Modellen, mit denen Menschen tatsächlich stundenlang gerne sprechen. Technische Benutzer erhalten einen schnelleren, zuverlässigeren Endpunkt. Kreative entdecken einen Kollaborateur, der Ton und Emotionen auf bisher unerreichter Ebene versteht. Und Sicherheitsforscher erhalten die bisher detaillierteste veröffentlichte Modellkarte.
Laden Sie Apidog noch heute herunter – komplett kostenlos – und beginnen Sie mit dem Aufbau mit Grok 4.1, bevor Ihre Konkurrenten die Ankündigung zu Ende gelesen haben. Der Unterschied zwischen dem Beobachten des Fortschritts an der Spitze und dem Versand von Produkten darauf hängt oft von den heutigen Werkzeugentscheidungen ab.