
Ingenieure und Entwickler suchen ständig nach effizienten Modellen, die hohe Leistung ohne übermäßige Ressourcenanforderungen liefern. GLM-4.7-Flash erweist sich in dieser Landschaft als überzeugende Option. Dieses 30B-A3B Mixture-of-Experts (MoE)-Modell, entwickelt von Zhipu AI (Z.ai), zeichnet sich durch sein Gleichgewicht aus Stärke und Effizienz aus. Es brilliert bei Codierungs-Benchmarks, Schlussfolgerungsaufgaben und der Werkzeugintegration, wodurch es sich für lokale Bereitstellungsszenarien eignet.
GLM-4.7-Flash lokal auszuführen, ermöglicht es Benutzern, den Datenschutz zu wahren, die Latenz zu reduzieren und Integrationen anzupassen. Tools wie Ollama, LM Studio und Hugging Face vereinfachen diesen Prozess.
Im Verlauf dieses Leitfadens erhalten Sie praktische Einblicke in die Installation und Nutzung. Berücksichtigen Sie zunächst die grundlegenden Systemanforderungen.
Was ist GLM-4.7-Flash und warum sollte man es lokal verwenden?
GLM-4.7-Flash stellt einen Fortschritt bei Open-Source-Sprachmodellen dar. Basierend auf der glm4_moe_lite-Architektur verwendet es BF16- und F32-Tensortypen unter einer MIT-Lizenz. Das Paper des Modells, „GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models“, beschreibt detailliert sein Training für die Werkzeugnutzung und Argumentation, basierend auf arXiv:2508.06471.
Zu den Hauptmerkmalen gehören die Unterstützung für Englisch und Chinesisch, Textgenerierung und Konversationsaufgaben. Es verarbeitet multimodale Eingaben als Text, konzentriert sich jedoch auf reine Textausgaben. Einschränkungen ergeben sich aus seiner Größe – obwohl effizient, kann es in Nischenbereichen ohne Feinabstimmung nicht mit größeren Modellen mithalten. Details zu den Trainingsdaten bleiben unveröffentlicht, aber Evaluationen bestätigen seinen Vorsprung in Codierungs- und Agenten-Szenarien.
Benutzer entscheiden sich für lokale Ausführungen, um API-Kosten zu vermeiden. Z.ai bietet eine kostenlose Stufe für GLM-4.7-Flash über ihre Plattform an, aber die lokale Bereitstellung eliminiert die Abhängigkeit von externen Diensten. Dieser Ansatz eignet sich für Entwickler, die benutzerdefinierte Anwendungen erstellen, Forscher, die Hypothesen testen, oder Unternehmen, die Sicherheit priorisieren. Zum Beispiel können Sie Quantisierungsstufen steuern, um Hardwarebeschränkungen anzupassen und so eine optimale Leistung zu gewährleisten.
Systemanforderungen für den lokalen Betrieb von GLM-4.7-Flash
Hardware spielt eine entscheidende Rolle bei der Modellinferenz. GLM-4.7-Flash benötigt mindestens 16 GB Systemspeicher für grundlegende Operationen, wie in den LM Studio-Richtlinien angegeben. GPU-Beschleunigung erhöht die Geschwindigkeit jedoch erheblich.
Für Ollama-Varianten:
- q4_K_M: 19 GB VRAM
- q8_0: 32 GB VRAM
- bf16: 60 GB VRAM
Hugging Face empfiehlt torch.bfloat16 für Effizienz, was kompatible NVIDIA GPUs (Ampere oder spätere Architekturen) erfordert. CPU-only-Inferenz funktioniert, verlangsamt sich jedoch bei großen Kontexten erheblich.
Zu den Softwarevoraussetzungen gehören Python 3.8+, pip und Git. Frameworks wie Transformers erfordern zusätzliche Installationen. Stellen Sie sicher, dass Ihr Betriebssystem CUDA für die GPU-Nutzung unterstützt – Ubuntu 20.04 oder Windows mit WSL2 funktioniert gut.
Sollten die Ressourcen nicht ausreichen, reduziert die Quantisierung den Speicherbedarf. Tools wie llama.cpp oder Unsloth bieten 4-Bit- oder 2-Bit-Versionen an, die die Anforderungen auf 15-20 GB VRAM senken. Diese Flexibilität ermöglicht die Bereitstellung auf Consumer-Hardware wie der RTX 4090.
Sind die Anforderungen erfüllt, erkunden Sie die Installationsmethoden. Beginnen Sie mit Ollama wegen seiner Einfachheit.
Wie man GLM-4.7-Flash mit Ollama installiert und verwendet
Ollama bietet eine zugängliche Plattform für den lokalen Betrieb großer Modelle. Es verwaltet Quantisierung und API-Bereitstellung automatisch.
Zuerst installieren Sie Ollama. Laden Sie die ausführbare Datei für Ihr Betriebssystem herunter und führen Sie sie aus.

Überprüfen Sie die Installation mit ollama --version, wobei Sie sicherstellen, dass Version 0.14.3 oder höher vorliegt, da GLM-4.7-Flash diese benötigt.

Als Nächstes ziehen Sie das Modell: Führen Sie ollama pull glm-4.7-flash aus.

Wählen Sie Varianten wie glm-4.7-flash:q4_K_M für geringeren Speicherverbrauch. Der Befehl lädt etwa 19 GB für die q4-Version herunter.
Führen Sie das Modell interaktiv aus: Geben Sie ollama run glm-4.7-flash ein. Geben Sie Prompts wie „Generieren Sie Python-Code für eine Fibonacci-Sequenz.“ ein. Das Modell antwortet mit begründeten Ausgaben und nutzt dabei seine Stärken im Coding.
Für den programmatischen Zugriff verwenden Sie die API. Senden Sie eine curl-Anfrage:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
Dies gibt JSON mit der Antwort zurück. In Python integrieren Sie mit der ollama-Bibliothek:
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
JavaScript folgt ähnlich mit dem ollama npm-Paket.
Passen Sie Konfigurationen an, indem Sie die Modelfile bearbeiten. Setzen Sie die Temperatur auf 0.7 für deterministische Ausgaben bei Codierungsaufgaben. Ollamas neuester Modus ruft bei Bedarf aktuelle Beiträge ab, konzentrieren Sie sich hier jedoch auf die lokale Inferenz.
Diese Methode eignet sich für schnelle Setups. Für eine grafische Benutzeroberfläche wenden Sie sich jedoch an LM Studio.
GLM-4.7-Flash in LM Studio einrichten
LM Studio bietet eine benutzerfreundliche GUI für die Modellverwaltung. Laden Sie es herunter und installieren Sie es.
Suchen Sie im Modell-Hub nach „zai-org/glm-4.7-flash“. Wählen Sie eine quantisierte Version – MLX-4bit, 6bit oder 8bit – aus verknüpften Hugging Face Repositories aus. Der Download wird in der App abgeschlossen.
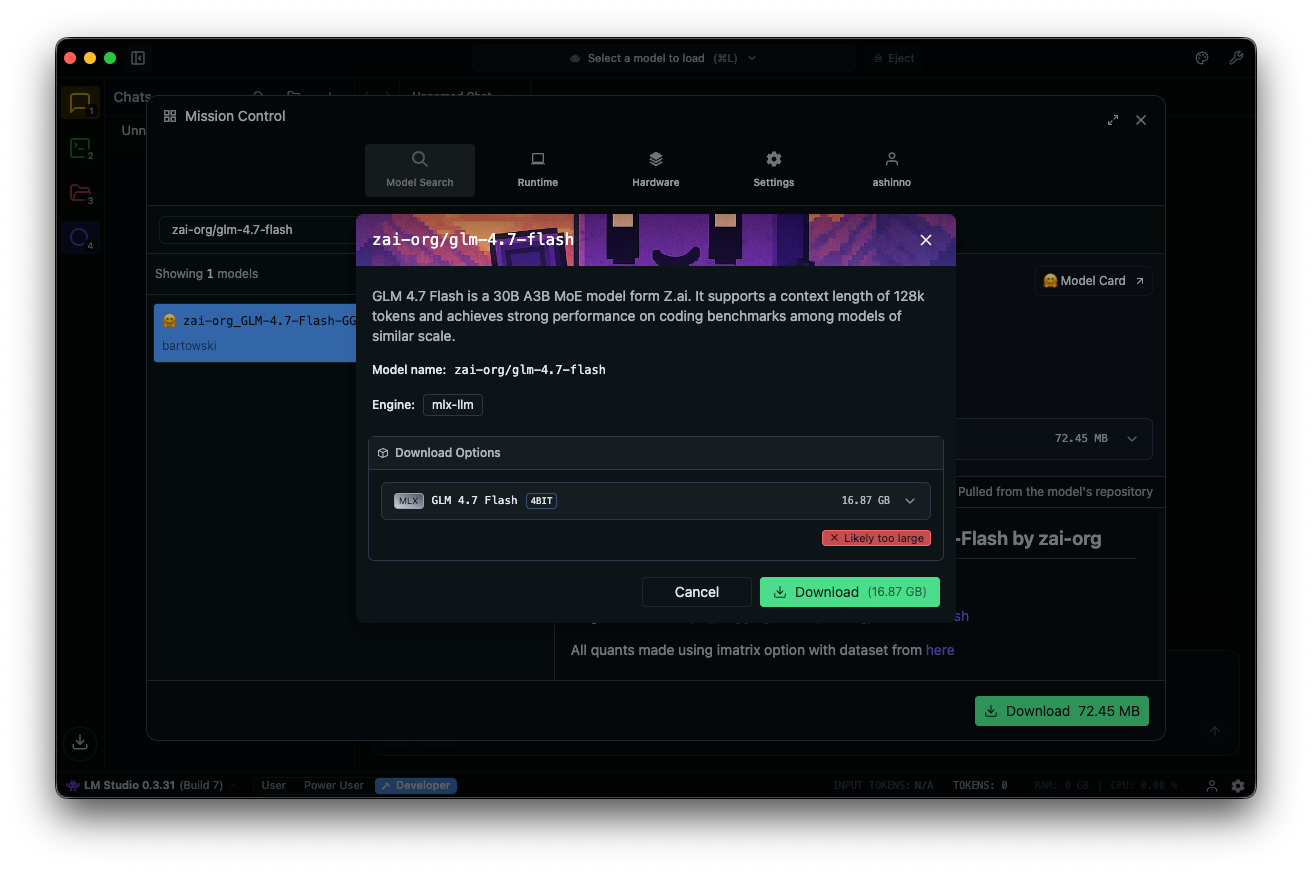
Laden Sie das Modell: Navigieren Sie zur Chat-Oberfläche, wählen Sie GLM-4.7-Flash aus und passen Sie die Parameter an. Aktivieren Sie „Denken“ (Standard: true) für schrittweises Schlussfolgern. Setzen Sie die Temperatur auf 1, top_k auf 50, top_p auf 0.95 und deaktivieren Sie die Wiederholungsstrafe.
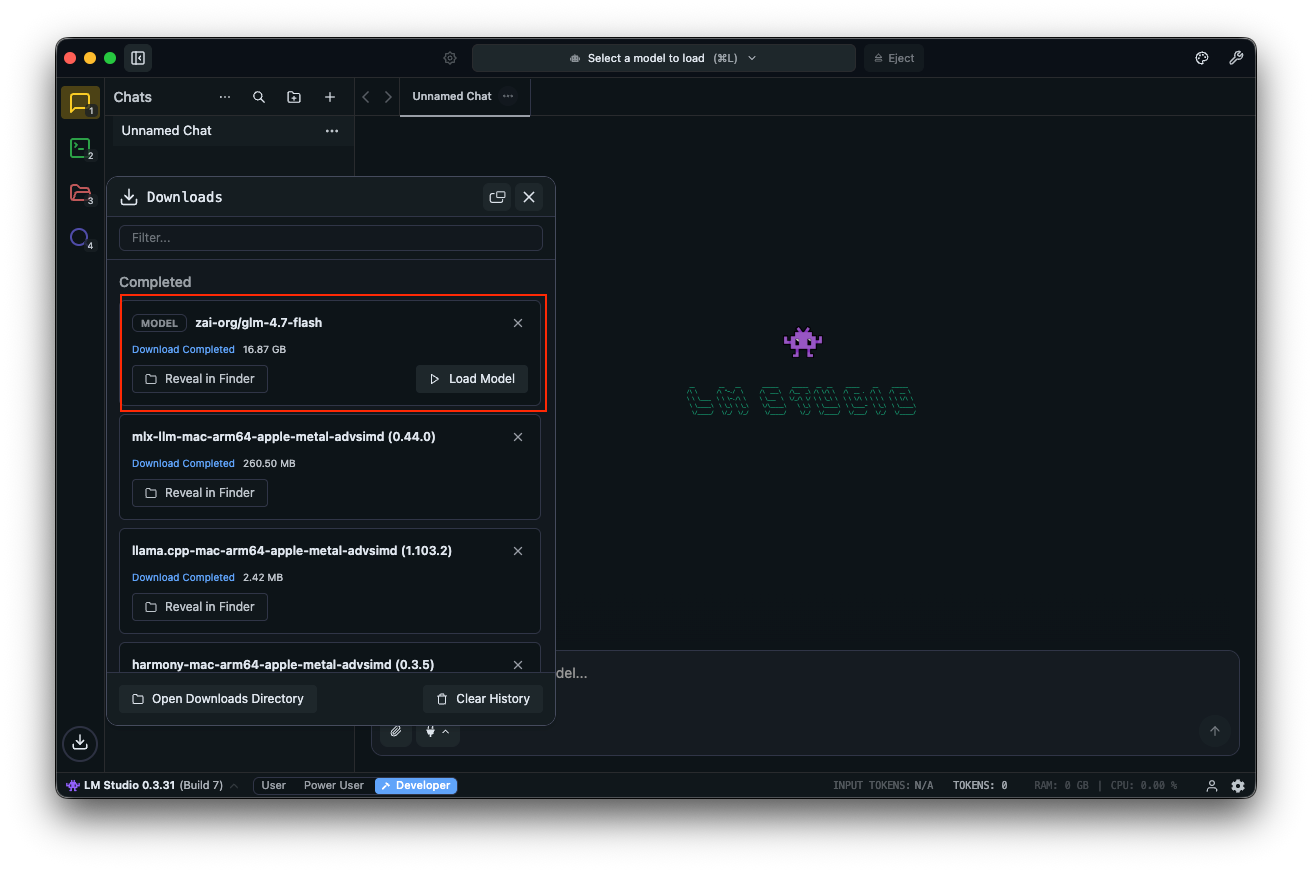
Testen Sie mit Prompts: „Entwerfen Sie eine REST-API für die Benutzerauthentifizierung.“ LM Studio zeigt Ausgaben mit Token-Geschwindigkeiten an, was die Leistungsoptimierung unterstützt.
Benutzerdefinierte Felder wie clear_thinking (Standard: false) verwalten den Verlauf. Bei MoE-Modellen überwachen Sie aktive Experten – A3B bedeutet drei aktive pro Forward Pass, was die Effizienz optimiert.
LM Studio unterstützt Deeplinks für den direkten Modellzugriff. Treten Probleme auf, überprüfen Sie den Systemspeicher – mindestens 16 GB verhindern Abstürze.
Dieses Tool eignet sich hervorragend für Experimente. Für fortgeschrittene Skripting-Aufgaben integrieren Sie es mit Hugging Face.
GLM-4.7-Flash mit Hugging Face Transformers verwenden
Hugging Face bietet robuste Bibliotheken für eine feingranulare Steuerung. Installieren Sie Transformers vom Hauptzweig:
pip install git+https://github.com/huggingface/transformers.git
Laden Sie das Modell:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
Bereiten Sie Eingaben vor:
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
Generieren Sie:
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
Dieses Setup unterstützt die Quantisierung über bitsandbytes für geringeren VRAM. Fügen Sie `load_in_4bit=True` beim Laden des Modells hinzu.
Zum Bereitstellen verwenden Sie vLLM oder SGLang. Installieren Sie vLLM:
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
Starten Sie einen Server:
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
Zugriff über OpenAI-kompatible Endpunkte. SGLang erfordert eine Quellcode-Installation und folgt ähnlichen Schritten.
Diese Frameworks ermöglichen Bereitstellungen auf Produktionsniveau. Betrachten wir nun das API-Testing mit Apidog.
Apidog für API-Tests mit lokalem GLM-4.7-Flash integrieren
Sobald Sie GLM-4.7-Flash über Ollama oder vLLM bereitstellen, testen Sie Endpunkte effizient. Apidog, eine All-in-One-API-Plattform, erleichtert dies.
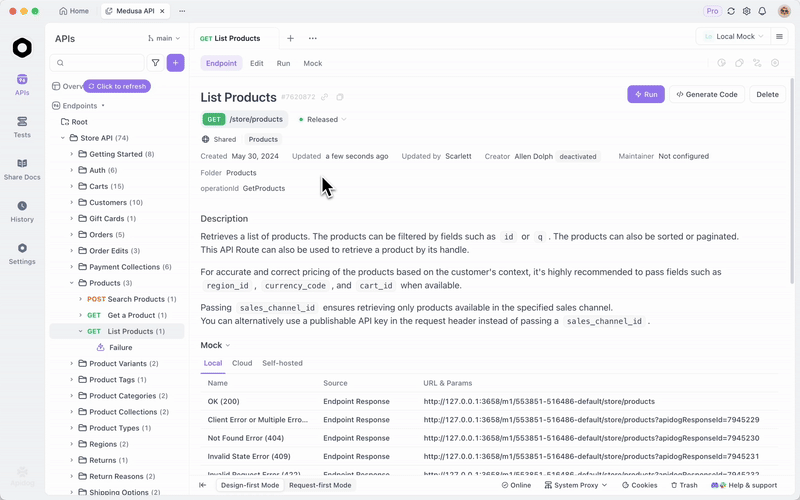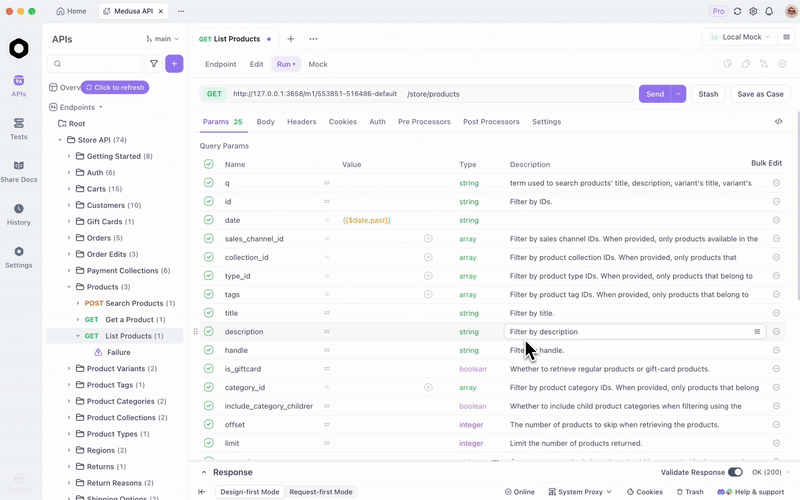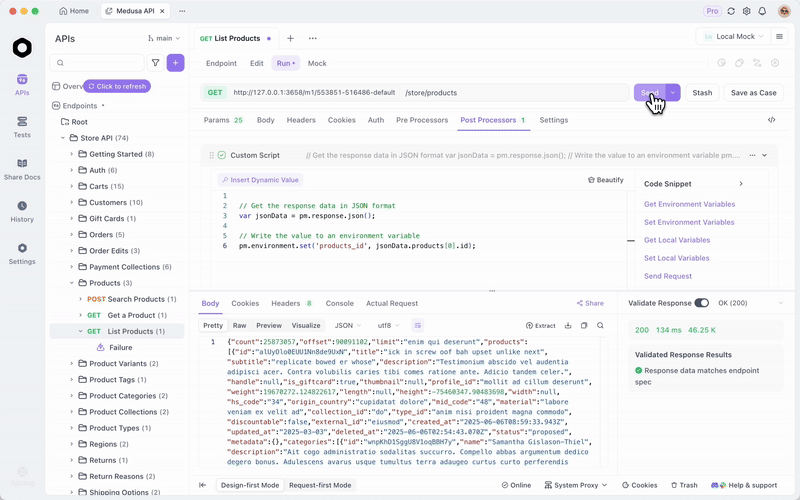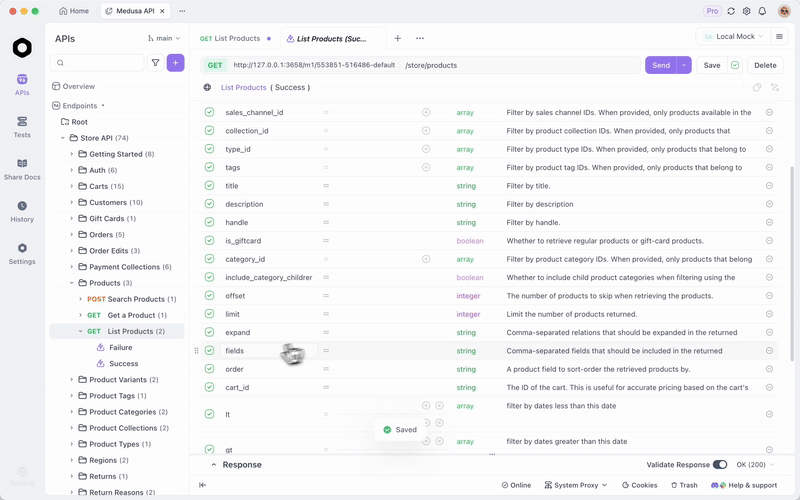
Laden Sie Apidog kostenlos herunter. Es unterstützt KI-Funktionen, indem Sie Ihr lokales Modell als Provider konfigurieren – verwenden Sie API-Schlüssel, falls zutreffend, oder direkte Endpunkte.
Der MCP Server von Apidog integriert sich mit IDEs wie Cursor und nutzt API-Spezifikationen für die Codegenerierung. Dies knüpft an die Codierungsfähigkeiten von GLM-4.7-Flash an – testen Sie agentenbasierte Ausgaben direkt.
Fragen Sie beispielsweise Ihren lokalen Server ab und validieren Sie die Antworten. Dies gewährleistet die Zuverlässigkeit in Anwendungen.
Aufbauend auf den Grundlagen, gehen Sie zur Optimierung über.
Fortgeschrittene Tipps zur Optimierung der GLM-4.7-Flash-Leistung
Feinjustieren Sie Parameter für Aufgaben. Setzen Sie die Temperatur auf 0.7 für Codierung, 1.0 für kreatives Schreiben. Verwenden Sie top_p 0.95, um die Vielfalt auszugleichen.
Quantisieren Sie weiter mit GGUF-Formaten über llama.cpp. Kompilieren Sie llama.cpp mit CUDA und konvertieren Sie dann:
./llama-gguf-split --model GLM-4.7-Flash.gguf
Führen Sie es mit --jinja für Template-Unterstützung aus.
Lange Kontexte handhaben: Teilen Sie Eingaben auf, wenn sie 128K überschreiten. Aktivieren Sie „Denken“ für komplexe Anfragen.
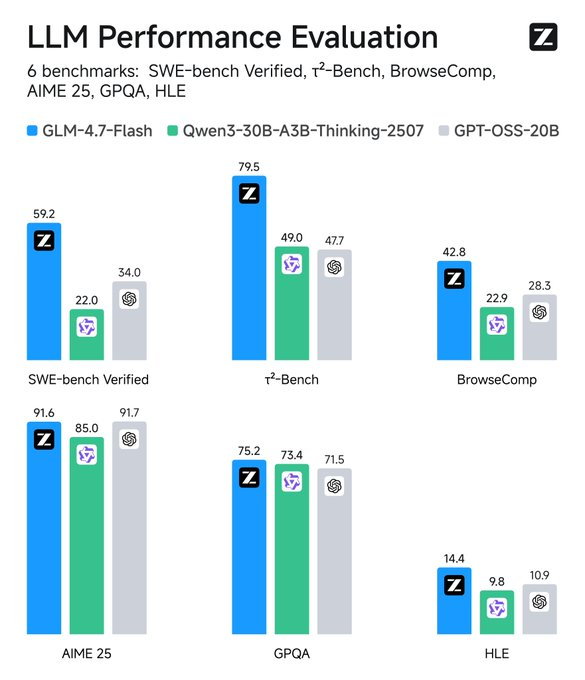
Metriken überwachen: Tools wie TensorBoard verfolgen die Latenz. Vergleichen Sie mit Baselines – GLM-4.7-Flash übertrifft Konkurrenten in SWE-bench um 37.2 Punkte.
Tools integrieren: Fügen Sie Funktionsaufrufe in Prompts für agentisches Verhalten hinzu.
Sicherheit: Führen Sie es in isolierten Umgebungen aus, um Datenlecks zu verhindern.
Diese Strategien maximieren den Nutzen. Denken Sie als Nächstes über Anwendungen nach.
Behebung häufiger Probleme
Speicherengpässe? Reduzieren Sie die Batch-Größe oder quantisieren Sie stärker.
Langsame Inferenz? Rüsten Sie die GPU auf oder verwenden Sie schnellere Frameworks wie vLLM.
Kompatibilitätsprobleme? Aktualisieren Sie Transformers auf den Hauptzweig.
Wenn Ollama fehlschlägt, überprüfen Sie die Verfügbarkeit von Port 11434.
LM Studio stürzt ab? Überprüfen Sie die Modellintegrität.
Gehen Sie diese proaktiv an.
Fazit: Stärken Sie Ihren Workflow mit GLM-4.7-Flash
GLM-4.7-Flash lokal auszuführen, erschließt leistungsstarke KI-Fähigkeiten. Von Ollamas Einfachheit bis zu Hugging Faces Flexibilität gibt es zahlreiche Optionen. Integrieren Sie Apidog für nahtloses API-Management – laden Sie es kostenlos herunter, um Ihr Setup zu optimieren.
Während sich die Technologie weiterentwickelt, überbrücken Modelle wie dieses Leistung und Zugänglichkeit. Implementieren Sie diese Schritte, und Sie erreichen effiziente, private KI-Bereitstellungen. Kleine Anpassungen von Parametern oder Tools führen zu erheblichen Verbesserungen und verwandeln Routineaufgaben in optimierte Prozesse.