Entwickler suchen ständig nach leistungsstarken Sprachmodellen, die eine robuste Leistung in verschiedenen Anwendungen bieten. Zhipu AI stellt GLM-4.6 vor, eine fortschrittliche Iteration der GLM-Serie, die die Grenzen der Fähigkeiten künstlicher Intelligenz erweitert. Dieses Modell baut auf früheren Versionen auf, indem es wesentliche Verbesserungen in der Kontextverarbeitung, Argumentation und praktischen Nützlichkeit integriert. Ingenieure integrieren GLM-4.6 in ihre Arbeitsabläufe, um komplexe Aufgaben, von der Codegenerierung bis zur Inhaltserstellung, mit größerer Effizienz und Genauigkeit zu bewältigen.
Zhipu AI entwickelt GLM-4.6 als Teil des GLM Coding Plan, einem abonnementbasierten Dienst, der zu einem erschwinglichen Preis beginnt. Benutzer greifen über integrierte Tools wie Claude Code, Cline, OpenCode und andere auf dieses Modell zu, was eine nahtlose KI-gestützte Entwicklung ermöglicht. Das Modell zeichnet sich in realen Szenarien aus, in denen es umfangreiche Kontexte verarbeitet und hochwertige Ausgaben generiert. Darüber hinaus zeigt GLM-4.6 eine überragende Leistung in Benchmarks und konkurriert mit internationalen Marktführern wie Claude Sonnet 4. Dies positioniert es als erste Wahl für Entwickler in China und darüber hinaus, die zuverlässige KI-Unterstützung benötigen.
Nachdem wir die Grundlagen des Modells verstanden haben, wollen wir nun seine Kernfunktionen und deren Vorteile für technische Implementierungen untersuchen.
Was ist GLM-4.6?
Zhipu AI entwickelt GLM-4.6 als großes Sprachmodell, das für eine Vielzahl technischer und kreativer Aufgaben optimiert ist. Das Modell verfügt über eine Mixture-of-Experts (MoE)-Architektur mit 355 Milliarden Parametern, die eine effiziente Berechnung bei gleichzeitig hoher Leistung ermöglicht. Benutzer schätzen sein erweitertes Kontextfenster von 200.000 Tokens, eine bemerkenswerte Verbesserung gegenüber dem Limit von 128.000 in früheren Versionen. Diese Erweiterung ermöglicht es dem Modell, komplexe, lange Interaktionen zu verwalten, ohne an Kohärenz zu verlieren.
Darüber hinaus unterstützt GLM-4.6 Text-Ein- und -Ausgabemodalitäten, was es vielseitig für Anwendungen macht, die eine präzise Sprachverarbeitung erfordern. Die maximale Ausgabe-Token-Grenze erreicht 128.000, was ausreichend Platz für detaillierte Antworten bietet. Entwickler nutzen diese Spezifikationen, um Systeme zu erstellen, die umfangreiche Daten verarbeiten, wie z. B. Dokumentenanalyse oder mehrstufige Argumentationsketten.
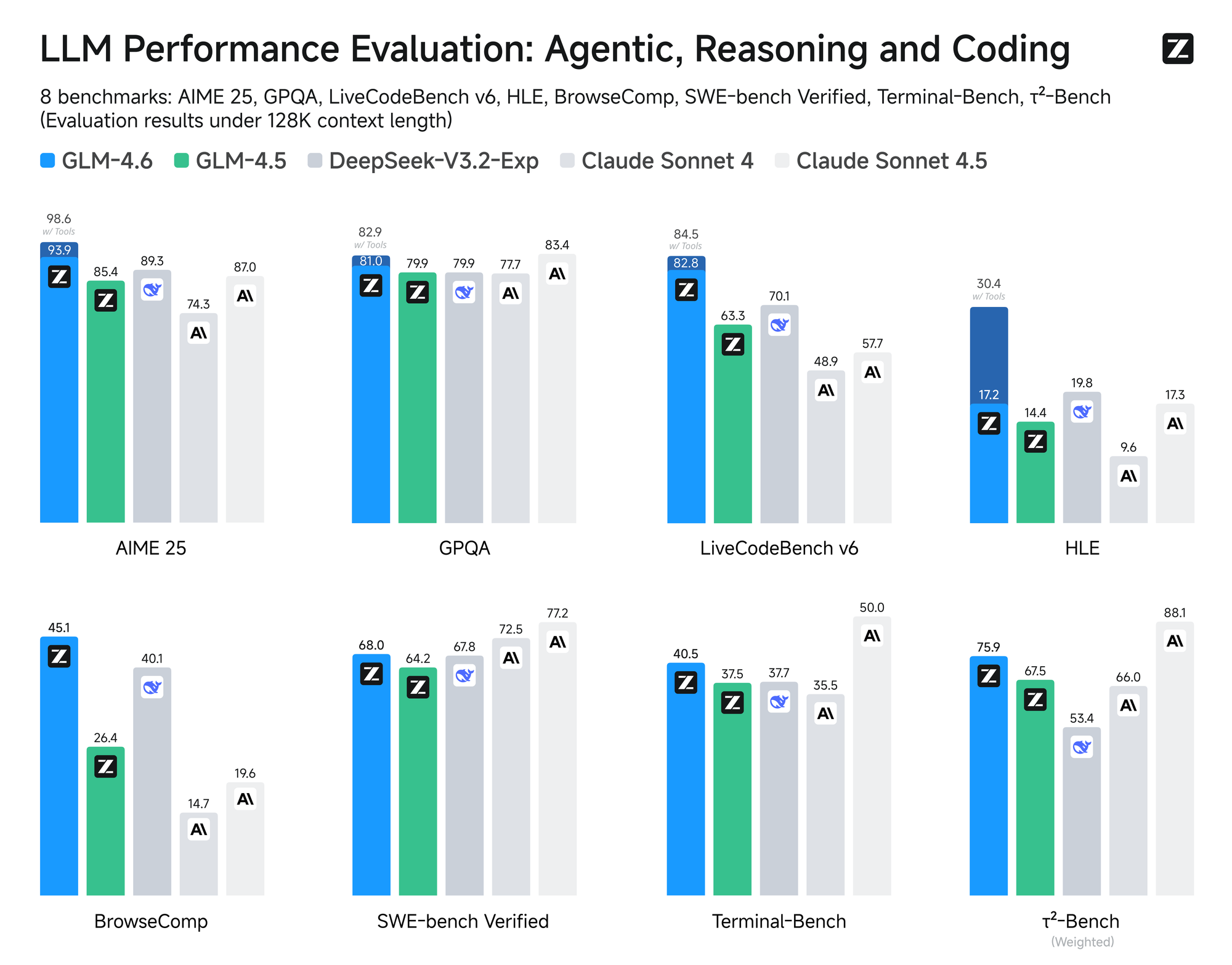
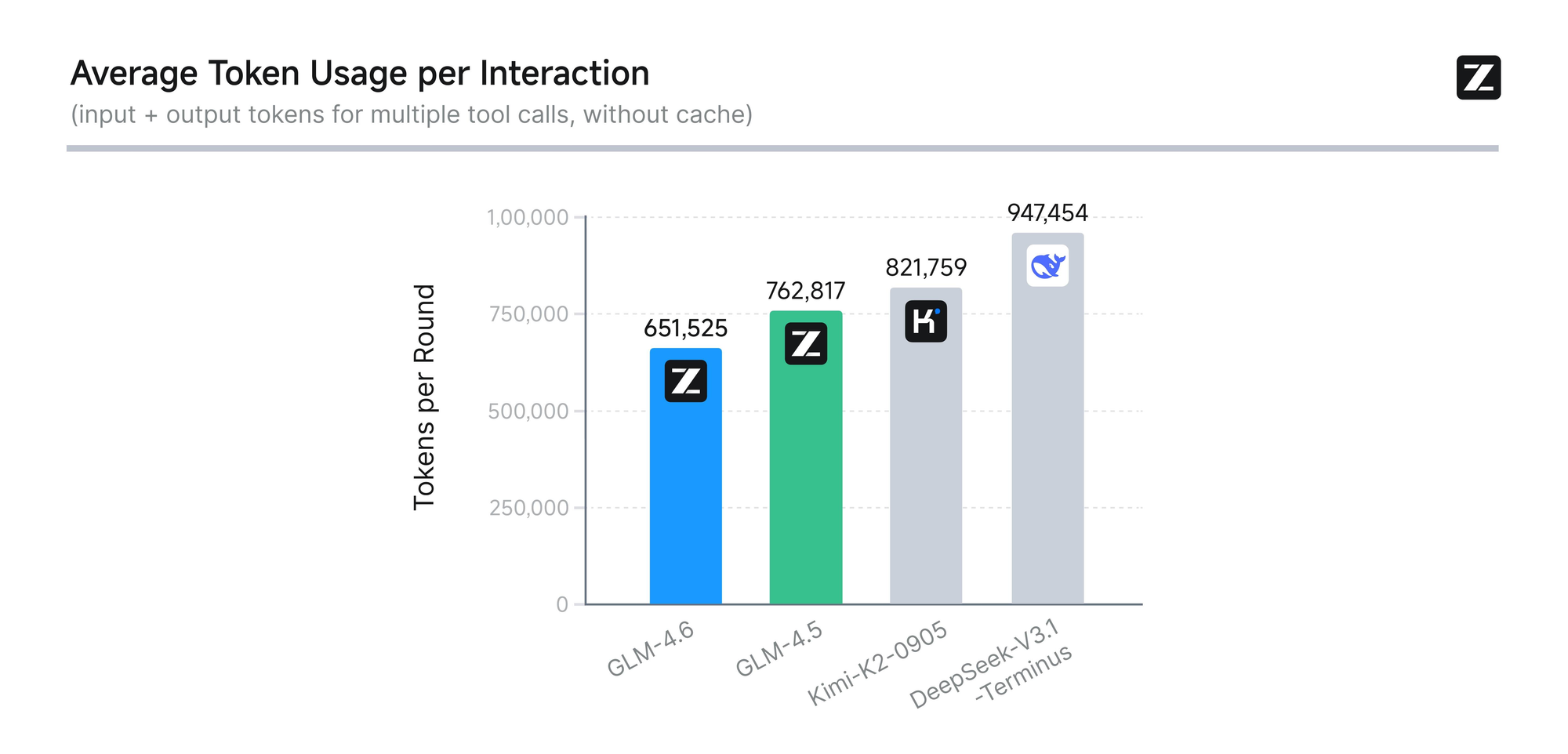
Das Modell wird einer strengen Bewertung anhand von acht maßgeblichen Benchmarks unterzogen, darunter AIME 25, GPQA, LCB v6, HLE und SWE-Bench Verified. Die Ergebnisse zeigen, dass GLM-4.6 gleichauf mit führenden Modellen wie Claude Sonnet 4 und 4.6 abschneidet. Zum Beispiel übertrifft GLM-4.6 in realen Codierungstests, die in der Claude Code-Umgebung durchgeführt wurden, Konkurrenten in 74 praktischen Szenarien. Dies erreicht es mit einer über 30 % höheren Effizienz beim Token-Verbrauch, wodurch die Betriebskosten für Vielnutzer gesenkt werden.
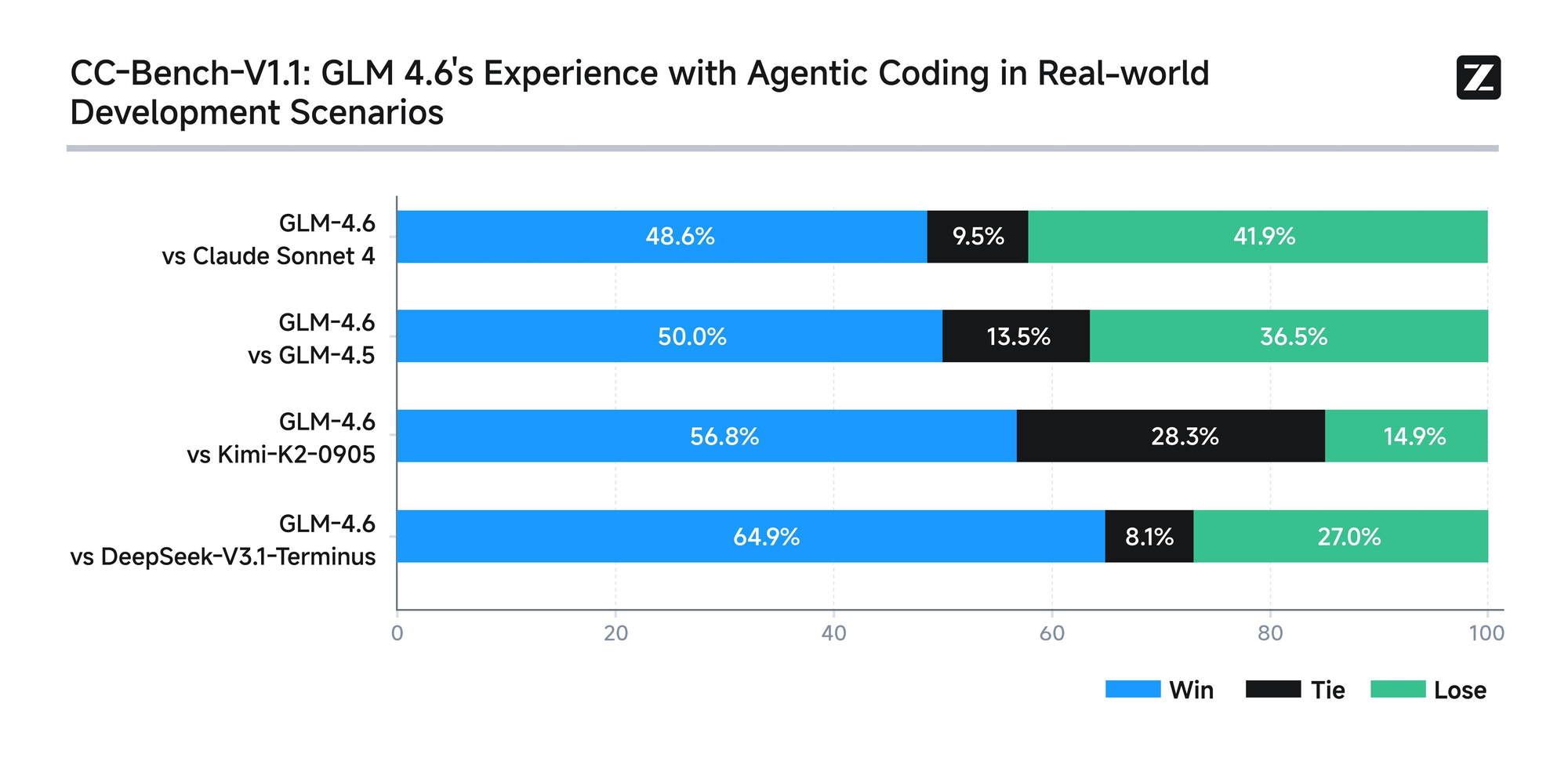
Darüber hinaus verpflichtet sich Zhipu AI zur Transparenz, indem alle Testfragen und Agenten-Trajektorien öffentlich zugänglich gemacht werden. Diese Praxis ermöglicht es Entwicklern, Behauptungen zu überprüfen und Ergebnisse zu reproduzieren, was das Vertrauen in die Technologie fördert. GLM-4.6 integriert auch fortschrittliche Argumentationsfähigkeiten, die die Verwendung von Tools während der Inferenz unterstützen. Diese Funktion erhöht seine Nützlichkeit in agentenbasierten Frameworks, wo das Modell autonom Aufgaben plant und ausführt.
Über die Codierung hinaus glänzt GLM-4.6 in anderen Bereichen. Es verfeinert das Schreiben, um sich eng an menschliche Präferenzen anzupassen, wodurch Stil, Lesbarkeit und Authentizität beim Rollenspiel verbessert werden. Bei Übersetzungsaufgaben optimiert das Modell für kleinere Sprachen wie Französisch, Russisch, Japanisch und Koreanisch, um semantische Kohärenz in informellen Kontexten zu gewährleisten. Inhaltsersteller nutzen es für Romane, Skripte und Copywriting, wobei sie von der kontextuellen Erweiterung und emotionalen Nuance profitieren.
Die Entwicklung virtueller Charaktere stellt eine weitere Stärke dar, da GLM-4.6 in mehrstufigen Gesprächen einen konsistenten Ton beibehält. Dies macht es ideal für soziale KI und Markenpersonifizierung. Bei intelligenter Suche und tiefgehender Forschung verbessert das Modell das Verständnis von Absichten und die Ergebnissynthese und liefert aufschlussreiche Ausgaben.
Insgesamt ermöglicht GLM-4.6 Entwicklern, intelligentere Anwendungen zu erstellen. Seine Kombination aus langer Kontextverarbeitung, effizienter Token-Nutzung und breiter Anwendbarkeit hebt es in der KI-Landschaft hervor. Nachdem wir das Wesen des Modells verstanden haben, wenden wir uns dem Zugriff auf seine API für die praktische Implementierung zu.
Wie man auf die GLM-4.6 API zugreift
Zhipu AI bietet einen unkomplizierten Zugang zur GLM-4.6 API über ihre offene Plattform. Entwickler beginnen, indem sie sich auf der Zhipu AI-Website, speziell unter open.bigmodel.cn oder z.ai, für ein Konto registrieren. Der Prozess erfordert die Verifizierung einer E-Mail-Adresse oder Telefonnummer, um eine sichere Registrierung zu gewährleisten.
Nach der Registrierung abonnieren Benutzer den GLM Coding Plan. Dieser Plan schaltet GLM-4.6 und verwandte Modelle frei. Abonnenten erhalten Zugang zum API-Dashboard, wo sie API-Schlüssel generieren. Diese Schlüssel dienen als Anmeldeinformationen zur Authentifizierung von Anfragen.
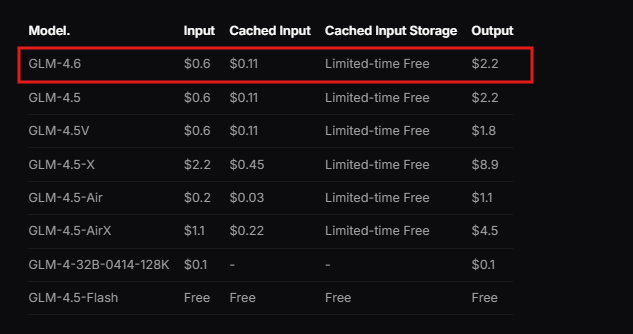
Zusätzlich bietet Zhipu AI eine Dokumentation an, die die Integrationsschritte detailliert beschreibt. Entwickler überprüfen diese Ressource, um Voraussetzungen wie kompatible Programmierumgebungen zu verstehen. Die API folgt einem RESTful-Design, das mit Standard-HTTP-Clients kompatibel ist.
Um zu beginnen, navigieren Benutzer zum Bereich API-Verwaltung in ihrem Konto. Hier erstellen sie einen neuen API-Schlüssel und notieren dessen Wert sicher. Zhipu AI empfiehlt, Schlüssel regelmäßig aus Sicherheitsgründen zu rotieren. Darüber hinaus bietet die Plattform Nutzungskontingente basierend auf Abonnementstufen, um eine Übernutzung zu verhindern.
Sollten Entwickler auf Probleme stoßen, hilft das Support-Team von Zhipu AI per E-Mail oder über Foren. Sie bieten auch Community-Ressourcen zur Fehlerbehebung bei häufigen Zugriffsproblemen an. Nachdem der Zugriff gesichert ist, besteht der nächste Schritt darin, die Authentifizierung einzurichten, um effektiv mit der GLM-4.6 API zu interagieren.
Authentifizierung und Einrichtung für die GLM-4.6 API
Die Authentifizierung bildet das Rückgrat sicherer API-Interaktionen. Zhipu AI verwendet die Bearer-Token-Authentifizierung für die GLM-4.6 API. Entwickler fügen den API-Schlüssel in den Authorization-Header jeder Anfrage ein.
Für die Einrichtung installieren Sie die notwendigen Bibliotheken in Ihrer Entwicklungsumgebung. Python-Benutzer verwenden beispielsweise die `requests`-Bibliothek. Sie importieren sie und konfigurieren die Header wie folgt:
import requests
api_key = "your-api-key"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
Dieser Code bereitet die Umgebung für das Senden von Anfragen vor. Ähnlich verwenden Entwickler in JavaScript mit Node.js die `fetch`-API oder die `axios`-Bibliothek. Sie setzen die Header im `options`-Objekt.
Stellen Sie außerdem sicher, dass Ihr System die Netzwerkanforderungen erfüllt. Der GLM-4.6 API-Endpunkt befindet sich unter https://api.z.ai/api/paas/v4/chat/completions. Testen Sie die Konnektivität, indem Sie die Domain anpingen oder eine einfache Anfrage senden.
Während der Einrichtung konfigurieren Entwickler Umgebungsvariablen, um den API-Schlüssel sicher zu speichern. Diese Praxis vermeidet das Hardcodieren sensibler Informationen in Skripten. Tools wie `dotenv` in Python oder `process.env` in Node.js erleichtern dies.
Wenn Sie einen Proxy oder VPN verwenden, überprüfen Sie, ob dieser den Datenverkehr zu den Servern von Zhipu AI zulässt. Authentifizierungsfehler resultieren oft aus falscher Schlüsselformatierung oder abgelaufenen Abonnements. Zhipu AI protokolliert Fehler in den Antworten, was bei der Diagnose von Problemen hilft.
Nach der Authentifizierung erkunden Entwickler die Endpunkte. Diese Einrichtung gewährleistet einen zuverlässigen, sicheren Zugang zu den Funktionen von GLM-4.6.
Erkundung der GLM-4.6 API-Endpunkte
Die GLM-4.6 API konzentriert sich auf einen primären Endpunkt für Chat-Vervollständigungen. Entwickler senden POST-Anfragen an https://api.z.ai/api/paas/v4/chat/completions, um Antworten zu generieren.
Dieser Endpunkt unterstützt sowohl den Basis- als auch den Streaming-Modus. Im Basismodus verarbeitet der Server die gesamte Anfrage und gibt eine vollständige Antwort zurück. Der Streaming-Modus liefert jedoch die Ausgabe inkrementell, ideal für Echtzeitanwendungen.
Um den Endpunkt aufzurufen, erstellen Sie eine JSON-Nutzlast mit den erforderlichen Parametern. Das Feld "model" gibt "glm-4.6" an. Das "messages"-Array enthält Rollen-Inhalts-Paare, die Konversationen simulieren.
Zum Beispiel sieht eine grundlegende Curl-Anfrage so aus:
curl -X POST "https://api.z.ai/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key" \
-d '{
"model": "glm-4.6",
"messages": [
{"role": "user", "content": "Generate a Python function for sorting a list."}
]
}'
Der Server antwortet mit JSON, das den generierten Inhalt enthält. Entwickler parsen dies, um Assistenten-Nachrichten zu extrahieren.
Zusätzlich unterstützt der Endpunkt erweiterte Funktionen wie Denkprozesse (thinking steps). Setzen Sie das `thinking`-Objekt, um detaillierte Argumentationen in den Ausgaben zu ermöglichen.
Das Verständnis dieses Endpunkts ermöglicht es Entwicklern, interaktive KI-Systeme zu erstellen. Als Nächstes werden wir die Anfrageparameter detailliert aufschlüsseln.
Detaillierte Erklärung der GLM-4.6 API-Anfrageparameter
Anfrageparameter steuern das Verhalten der GLM-4.6 API. Der `model`-Parameter schreibt "glm-4.6" vor, um diese spezifische Version auszuwählen.
Das `messages`-Array steuert die Konversation. Jedes Objekt enthält eine Rolle – "user" für Eingaben, "assistant" für frühere Antworten – und den Inhalt als Textzeichenketten. Entwickler strukturieren mehrstufige Dialoge, indem sie die Rollen abwechseln.
Des Weiteren begrenzt `max_tokens` die Antwortlänge und verhindert übermäßige Ausgaben. Setzen Sie es auf 4096 für ausgewogene Ergebnisse. `Temperature` passt die Zufälligkeit an; niedrigere Werte wie 0,6 führen zu deterministischen Ausgaben, während höhere Werte die Kreativität fördern.
Für Streaming fügen Sie "stream": true hinzu. Dies ändert das Antwortformat in gestückelte Daten.
Der `thinking`-Parameter ermöglicht eine schrittweise Argumentation. Setzen Sie "thinking": {"type": "enabled"}, um Zwischengedanken in die Antworten aufzunehmen.
Weitere optionale Parameter sind `top_p` für Nucleus-Sampling und `presence_penalty`, um Wiederholungen zu vermeiden. Entwickler passen diese je nach Anwendungsfall an.
Ungültige Parameter lösen Fehlermeldungen mit Codes wie 400 für fehlerhafte Anfragen aus. Validieren Sie Nutzlasten immer vor dem Senden.
Durch die Beherrschung dieser Parameter können Entwickler GLM-4.6 API-Aufrufe für optimale Leistung anpassen.
Verarbeitung von Antworten der GLM-4.6 API
Antworten von der GLM-4.6 API kommen im JSON-Format an. Entwickler parsen das `choices`-Array, um auf generierte Inhalte zuzugreifen.
Im Basismodus enthält die Antwort:
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1694123456,
"model": "glm-4.6",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Your generated text here."
},
"finish_reason": "stop"
}
]
}
Extrahieren Sie das `content`-Feld zur Verwendung in Anwendungen.
Im Streaming-Modus werden Antworten als Server-Sent Events (SSE) gestreamt. Jeder Chunk folgt diesem Muster:
data: {"id":"chatcmpl-...","choices":[{"delta":{"content":" partial text"}}]}
Entwickler akkumulieren Deltas, um die vollständige Ausgabe zu erstellen.
Die Fehlerbehandlung umfasst die Überprüfung von Statuscodes. Ein 401 weist auf einen Authentifizierungsfehler hin, während 429 auf Ratenbegrenzungen (Rate Limits) hinweist.
Protokollieren Sie Antworten zum Debuggen. Dieser Ansatz gewährleistet eine robuste Integration mit der GLM-4.6 API.
Codebeispiele zur Integration der GLM-4.6 API
Entwickler implementieren die GLM-4.6 API in verschiedenen Sprachen. In Python verwenden Sie `requests` für einen grundlegenden Aufruf:
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
payload = {
"model": "glm-4.6",
"messages": [{"role": "user", "content": "Explain quantum computing."}],
"max_tokens": 500,
"temperature": 0.7
}
headers = {
"Authorization": "Bearer your-api-key",
"Content-Type": "application/json"
}
response = requests.post(url, data=json.dumps(payload), headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Dieser Code sendet eine Abfrage und gibt die Antwort aus.
In JavaScript mit Node.js:
const fetch = require('node-fetch');
const url = 'https://api.z.ai/api/paas/v4/chat/completions';
const payload = {
model: 'glm-4.6',
messages: [{ role: 'user', content: 'Write a haiku about AI.' }],
max_tokens: 100
};
const headers = {
'Authorization': 'Bearer your-api-key',
'Content-Type': 'application/json'
};
fetch(url, {
method: 'POST',
body: JSON.stringify(payload),
headers
})
.then(res => res.json())
.then(data => console.log(data.choices[0].message.content));
Für Streaming in Python verwenden Sie SSE-Parsing-Bibliotheken wie `sseclient`.
Diese Beispiele demonstrieren die praktische Integration und ermöglichen es Entwicklern, schnell Prototypen zu erstellen.
Apidog für das Testen der GLM-4.6 API verwenden
Apidog dient als hervorragendes Tool zum Testen der GLM-4.6 API. Diese All-in-One-Plattform ermöglicht es Entwicklern, API-Interaktionen zu entwerfen, zu debuggen, zu mocken und zu automatisieren.
Beginnen Sie, indem Sie Apidog von apidog.com herunterladen und ein Projekt erstellen. Importieren Sie den GLM-4.6 API-Endpunkt, indem Sie eine neue API mit der URL https://api.z.ai/api/paas/v4/chat/completions hinzufügen.
Legen Sie die Authentifizierung im Header-Bereich von Apidog fest, indem Sie "Authorization: Bearer your-api-key" hinzufügen. Konfigurieren Sie den Anfragetext mit JSON-Parametern wie `model` und `messages`.
Apidog ermöglicht das Senden von Anfragen und das Anzeigen von Antworten in einer benutzerfreundlichen Oberfläche. Entwickler testen Variationen, indem sie Anfragen duplizieren und Parameter anpassen.
Darüber hinaus können Tests durch das Erstellen von Szenarien in Apidog automatisiert werden. Definieren Sie Assertions, um den Antwortinhalt zu validieren und sicherzustellen, dass die GLM-4.6 API wie erwartet funktioniert.
Mock-Server in Apidog simulieren Antworten für die Offline-Entwicklung. Diese Funktion beschleunigt das Prototyping ohne Live-API-Aufrufe.

Durch die Integration von Apidog optimieren Entwickler die GLM-4.6 API-Workflows, reduzieren Fehler und beschleunigen die Bereitstellung.
Best Practices und Ratenbegrenzungen für die GLM-4.6 API
Die Einhaltung bewährter Verfahren maximiert das Potenzial der GLM-4.6 API. Entwickler überwachen die Nutzung, um innerhalb der Ratenbegrenzungen zu bleiben, die typischerweise durch Tokens pro Minute oder Anfragen pro Tag basierend auf dem Abonnement definiert sind.
Implementieren Sie exponentielles Backoff für Wiederholungsversuche bei Fehlern wie 429. Dies verhindert eine Überlastung des Servers.
Optimieren Sie Prompts für Klarheit, um die Antwortqualität zu verbessern. Verwenden Sie Systemnachrichten, um den Kontext festzulegen und das Modell effektiv zu führen.
Sichern Sie API-Schlüssel in Produktionsumgebungen. Vermeiden Sie es, sie in clientseitigem Code preiszugeben.
Protokollieren Sie Interaktionen für Audits und Leistungsanalysen. Diese Daten dienen als Grundlage für Verbesserungen.
Behandeln Sie Grenzfälle, wie leere Antworten oder Timeouts, mit Fallback-Mechanismen.
Zhipu AI aktualisiert die Ratenbegrenzungen in der Dokumentation; überprüfen Sie diese regelmäßig.
Die Einhaltung dieser Praktiken gewährleistet eine effiziente und zuverlässige Nutzung der GLM-4.6 API.
Erweiterte Nutzung der GLM-4.6 API
Fortgeschrittene Benutzer erkunden Streaming für interaktive Anwendungen. Setzen Sie "stream": true und verarbeiten Sie Chunks in Echtzeit.
Integrieren Sie Tools, indem Sie Funktionsaufrufe in Nachrichten einfügen. GLM-4.6 unterstützt den Aufruf von Tools, wodurch Agenten externe Aktionen ausführen können.
Zum Beispiel definieren Sie Tools in der Nutzlast:
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {...}
}
}
]
Das Modell antwortet bei Bedarf mit Tool-Aufrufen.
Passen Sie die `temperature` für spezifische Aufgaben an; niedrig für faktische Anfragen, hoch für kreative.
Kombinieren Sie mit langen Kontexten für die Dokumentenzusammenfassung. Fügen Sie große Texte in Nachrichten ein.
Integrieren Sie in Agenten-Frameworks wie LangChain für komplexe Workflows.
Diese Techniken erschließen das volle Potenzial von GLM-4.6 in komplexen Systemen.
Fazit
Die GLM-4.6 API bietet Entwicklern ein leistungsstarkes Werkzeug für KI-Innovationen. Indem Sie dieser Anleitung folgen, integrieren Sie sie nahtlos in Projekte. Experimentieren Sie mit Funktionen, testen Sie mit Apidog und wenden Sie Best Practices für den Erfolg an. Zhipu AI entwickelt GLM-4.6 kontinuierlich weiter und verspricht noch größere Fähigkeiten in der Zukunft.