
Sie benötigen effiziente Tools, um in modernen Anwendungen hochwertige Bilder aus Textaufforderungen zu generieren. Die Z-Image API erfüllt diese Anforderung direkt. Entwickler greifen über eine kostenlose Schnittstelle auf ein leistungsstarkes Text-zu-Bild-Modell zu, das schnell fotorealistische Ergebnisse liefert. Diese API nutzt das Open-Source-Modell Z-Image-Turbo vom Tongyi-MAI-Team von Alibaba, das unter der Apache 2.0-Lizenz betrieben wird. Sie profitieren von einer Inferenzzeit unter einer Sekunde auf geeigneter Hardware, was es ideal für Echtzeitfunktionen in Web-Apps, mobilen Tools oder automatisierten Workflows macht.
Als Nächstes erkunden Sie die Open-Source-Grundlagen von Z-Image-Turbo. Anschließend erhalten Sie Einblicke in die API-Zugriffsmethoden und bestätigen die kostenlose Preisstruktur. Abschließend implementieren Sie praktische Integrationen. Diese Schritte befähigen Sie, Bildgenerierungsfunktionen effektiv einzusetzen.
Das Open-Source-Modell Z-Image-Turbo verstehen
Sie beginnen mit der Kerntechnologie der Z-Image API: dem Z-Image-Turbo-Modell. Das Tongyi-MAI-Team von Alibaba veröffentlicht dieses 6-Milliarden-Parameter-Modell vollständig als Open-Source unter Apache 2.0. Diese Lizenz erlaubt die kommerzielle Nutzung, Modifikationen und Distributionen ohne Einschränkungen, was die Akzeptanz in Produktionsumgebungen beschleunigt.
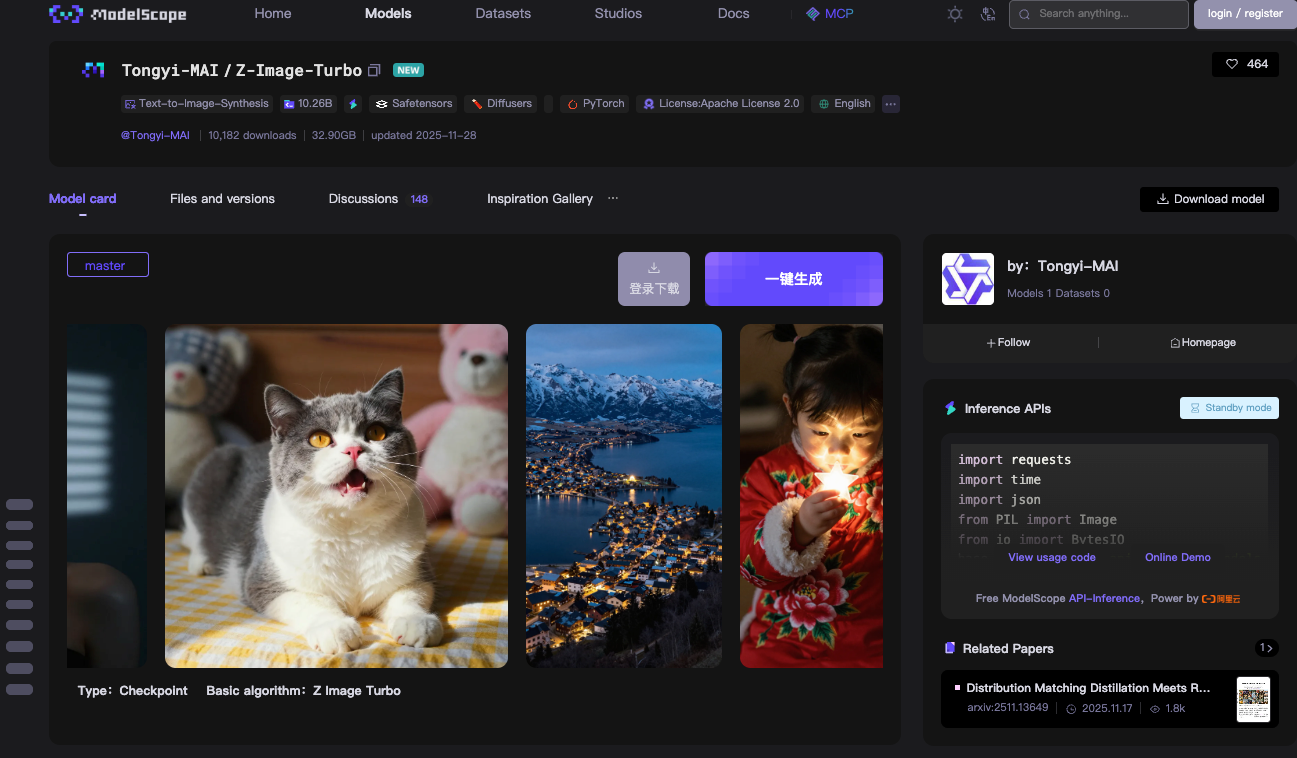
Z-Image-Turbo basiert auf einer Skalierbaren Single-Stream Diffusion Transformer (S3-DiT)-Architektur. Traditionelle Dual-Stream-Modelle trennen die Text- und Bildverarbeitung, was Parameter verschwendet. S3-DiT hingegen verkettet Text-Token, visuelle semantische Token und Bild-VAE-Token zu einem einheitlichen Stream. Dieses Design maximiert die Effizienz. Infolgedessen passt das Modell mit 16 GB VRAM auf Consumer-GPUs wie NVIDIA RTX 40-Serienkarten. Dies erreichen Sie, ohne die Ausgabequalität zu beeinträchtigen.
Das Modell zeichnet sich durch die photorealistische Bildsynthese aus. Es generiert detaillierte Szenen, Porträts und Landschaften aus beschreibenden Prompts. Zum Beispiel erzeugt eine Aufforderung wie „ein ruhiger Bergsee in der Dämmerung mit zweisprachiger Beschilderung auf Englisch und Chinesisch“ gestochen scharfe, kontextbezogene Visualisierungen. Z-Image-Turbo verarbeitet komplexe Anweisungen dank seines integrierten Prompt Enhancers gut. Diese Komponente verfeinert Eingaben für eine bessere Adhärenz und reduziert Artefakte, die bei früheren Diffusionsmodellen häufig auftraten.
Die Inferenzgeschwindigkeit definiert den Vorteil von Z-Image-Turbo. Es benötigt nur 8 Funktionsbewertungen (NFEs), was in der Praxis 9 Inferenzschritten entspricht. Auf Enterprise H800 GPUs sehen Sie eine Latenzzeit von unter einer Sekunde – oft unter 500 ms pro Bild. Consumer-Setups erreichen 2-5 Sekunden, abhängig von der Hardware. Diese Effizienz beruht auf Destillationstechniken wie Decoupled-DMD und DMDR, die das Basis-Z-Image-Modell komprimieren und gleichzeitig die Leistung erhalten.
Sie laden die Modellgewichte von den ModelScope- oder Hugging Face-Repositories herunter. Der Master-Branch enthält Checkpoint-Dateien mit insgesamt etwa 24 GB. Die PyTorch-Kompatibilität gewährleistet eine breite Integration. Für lokale Tests installieren Sie Abhängigkeiten über pip: torch, torchvision und modelscope>=1.18.0. Ein grundlegendes Pipeline-Skript lädt das Modell und generiert ein Bild in weniger als 10 Codezeilen.
Betrachten Sie dieses Beispiel für die lokale Inferenz:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = pipeline(Tasks.text_to_image_synthesis, model="Tongyi-MAI/Z-Image-Turbo", device=device)
output = pipe({
"text": "A photorealistic golden retriever playing in a sunlit park, 1024x1024",
"width": 1024,
"height": 1024,
"num_inference_steps": 9
})
output["output_imgs"][0].save("generated_image.png")
Dieser Code initialisiert die Pipeline, verarbeitet den Prompt und speichert das Ergebnis. Sie bemerken den Parameter num_inference_steps: 9 – er löst die 8-stufige Destillation für optimale Geschwindigkeit aus. Die Guidance-Skala bleibt bei 0,0, da Turbo-Varianten die klassifikatorfreie Guidance überspringen, um die Geschwindigkeit beizubehalten.
Benchmarks bestätigen die Wettbewerbsfähigkeit von Z-Image-Turbo. In Alibabas AI Arena erzielt es hohe Werte bei Elo-basierten menschlichen Präferenzbewertungen und übertrifft viele Open-Source-Konkurrenten in Bezug auf Photorealismus und Texttreue. Im Vergleich zu Modellen wie Stable Diffusion 3 verwendet es weniger Schritte und weniger Speicher, liefert aber vergleichbare Details.
Es gibt jedoch Einschränkungen. Das Modell priorisiert Geschwindigkeit gegenüber extremen Auflösungen; ein Überschreiten von 1536x1536 kann ohne Feinabstimmung zu Unschärfen führen. Es fehlt auch eine native Bild-zu-Bild-Bearbeitung in der Turbo-Variante – dies ist der kommenden Z-Image-Edit-Veröffentlichung vorbehalten. Dennoch bietet Z-Image-Turbo für Text-zu-Bild-Aufgaben eine solide, zugängliche Grundlage.
Sie erweitern dieses Modell über die Z-Image API, die es auf der Infrastruktur von ModelScope hostet. Dieser Wechsel von lokal zu Cloud eliminiert Einrichtungsaufwand. Folglich konzentrieren Sie sich auf die Anwendungslogik statt auf Hardware-Optimierung.
Zugriff auf die kostenlose Z-Image API: Schritt-für-Schritt-Einrichtung
Sie wechseln reibungslos zur API-Integration. Die Z-Image API arbeitet über den Inferenzdienst von ModelScope, der Z-Image-Turbo für Remote-Aufrufe hostet. Diese Einrichtung erfordert minimale Konfiguration und bietet dennoch Zuverlässigkeit auf Unternehmensniveau.
Zuerst registrieren Sie sich auf der ModelScope-Plattform. Erstellen Sie ein Konto mit Ihrer E-Mail-Adresse oder Ihren GitHub-Anmeldeinformationen. Nach dem Einloggen navigieren Sie zum API-Bereich unter Ihrem Profil. Generieren Sie ein ModelScope-Token – dies dient als Ihr Bearer-Authentifizierungsschlüssel. Speichern Sie es sicher, da alle Anfragen es im Authorization-Header vorschreiben.
Der API-Endpunkt konzentriert sich auf asynchrone Verarbeitung, was für Anforderungen mit hohem Durchsatz geeignet ist. Sie übermitteln Generierungsaufgaben per POST an https://api-inference.modelscope.cn/v1/images/generations. Die Antworten geben sofort eine task_id zurück. Anschließend fragen Sie https://api-inference.modelscope.cn/v1/tasks/{task_id} alle 5-10 Sekunden ab, bis die Aufgabe abgeschlossen ist. Dieses Design verhindert Timeouts bei langen Generierungen, obwohl die Geschwindigkeit von Z-Image-Turbo die Wartezeiten kurz hält – typischerweise 5-15 Sekunden End-to-End.
Wichtige Header umfassen:
Authorization: Bearer {your_token}Content-Type: application/jsonX-ModelScope-Async-Mode: true(für die Übermittlung)X-ModelScope-Task-Type: image_generation(für Statusprüfungen)
Der Anforderungsrumpf spezifiziert Parameter wie Modell-ID, Prompt, Dimensionen und Schritte. Sie setzen "model": "Tongyi-MAI/Z-Image-Turbo", um diese Variante anzusprechen. Standarddimensionen sind 1024x1024, aber Sie passen height und width für benutzerdefinierte Seitenverhältnisse an. Behalten Sie guidance_scale: 0.0 und num_inference_steps: 9 für die besten Ergebnisse bei.
Ein vollständiges Curl-Beispiel veranschaulicht den Prozess:
# Schritt 1: Aufgabe übermitteln
curl -X POST "https://api-inference.modelscope.cn/v1/images/generations" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-H "X-ModelScope-Async-Mode: true" \
-d '{
"model": "Tongyi-MAI/Z-Image-Turbo",
"prompt": "A futuristic cityscape at night with neon signs in Chinese and English",
"height": 1024,
"width": 1024,
"num_inference_steps": 9,
"guidance_scale": 0.0
}'
# task_id aus der Antwort extrahieren, z.B. {"task_id": "abc123"}
# Schritt 2: Status abfragen
curl -X GET "https://api-inference.modelscope.cn/v1/tasks/abc123" \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "X-ModelScope-Task-Type: image_generation"
Bei Erfolg enthält die Statusantwort "task_status": "SUCCEED" und ein output_images-Array mit einer herunterladbaren URL. Sie rufen das Bild per GET ab und speichern es als PNG oder JPEG.
Für synchrone Alternativen bietet ModelScope eine Online-Demo unter modelscope.cn/aigc/imageGeneration an. Wählen Sie Z-Image-Turbo als Standardmodell. Der Schnellmodus generiert Bilder ohne Parameter, während der erweiterte Modus volle Kontrolle ermöglicht. Diese Schnittstelle dient dem Prototyping, aber für die Automatisierung bevorzugen Sie die API.
Fehlerbehandlung erweist sich als wesentlich. Gängige Codes sind 401 (ungültiges Token), 429 (Ratenbegrenzungen) und 500 (Serverprobleme). Implementieren Sie Wiederholungsversuche mit exponentiellem Backoff im Produktionscode. Ratenbegrenzungen liegen bei etwa 10-20 Anfragen pro Minute für kostenlose Stufen, obwohl die genauen Quoten je nach Konto variieren.
Sie integrieren diese API in verschiedene Umgebungen. Python-Entwickler verwenden requests für HTTP-Aufrufe, wie zuvor gezeigt. Node.js-Benutzer nutzen axios für promises-basierte Abfragen. Selbst serverlose Funktionen auf AWS Lambda oder Vercel lassen sich angesichts der leichten Payloads einfach bereitstellen.
Apidog verbessert diese Zugriffsphase. Importieren Sie die API-Spezifikation in Apidog, das automatisch Dokumentation und Testfälle generiert. Sie simulieren Antworten, verketten Anfragen zum Polling und exportieren Sammlungen für die Teamfreigabe. Diese Plattform reduziert die Debugging-Zeit und ermöglicht es Ihnen, sich auf Prompt-Engineering zu konzentrieren.
Durch diese Schritte stellen Sie eine zuverlässige Verbindung zur Z-Image API her. Nun untersuchen Sie deren Preisgestaltung, um die Kosteneffizienz zu bestätigen.
Preise und Quoten für die Z-Image API
Als Nächstes bestätigen Sie die Erschwinglichkeit. Die Z-Image API verursacht keine Kosten für die Inferenz. ModelScope bietet unbegrenzte kostenlose Rechenleistung für Z-Image-Turbo-Aufrufe, wie in ihrem offiziellen X-Post angekündigt. Dieses kostenlose Modell umfasst Hosting, Bandbreite und GPU-Ressourcen – eine Seltenheit unter KI-Diensten.
Es gelten jedoch Quoten, um Missbrauch zu verhindern. Kostenlose Konten unterliegen weichen Beschränkungen: etwa 50-100 Generierungen pro Stunde, die regelmäßig zurückgesetzt werden. Sie überwachen die Nutzung über das ModelScope-Dashboard. Das Überschreiten von Limits führt zu temporärer Drosselung, aber Sie können bei Bedarf auf Pro-Tarife für höhere Volumina upgraden. Pro-Pläne beginnen mit niedrigen Gebühren, aber die kostenlose Stufe reicht für die meisten Entwickler und Hobbyisten aus.
Best Practices zur Optimierung der Z-Image API-Leistung
Sie verfeinern Ihre Nutzung mit gezielten Strategien. Wählen Sie zuerst optimale Parameter. Halten Sie sich an 1024x1024 für ein ausgewogenes Verhältnis; skalieren Sie bei Bedarf nach der Generierung hoch. Begrenzen Sie die Schritte auf 9 – höhere Werte verlangsamen die Inferenz ohne Vorteile.
Hardwarebeschleunigung steigert lokale Hybride. Aktivieren Sie Flash Attention in Diffusers: pipe.transformer.set_attention_backend("flash"). Dies reduziert den Speicherverbrauch um 20-30% auf Ampere-GPUs.
Prompt Engineering erhöht die Qualität. Strukturieren Sie Eingaben als „Subjekt + Aktion + Umgebung + Stil“. Testen Sie Variationen im Mock-Modus von Apidog, um schnell zu iterieren.
Sicherheitspraktiken schützen Integrationen. Geben Sie niemals Tokens in clientseitigem Code preis; verwenden Sie Server-Proxys. Validieren Sie Eingaben, um Injection-Angriffe zu verhindern.
Überwachungstools verfolgen Metriken. Protokollieren Sie Generierungszeiten, Erfolgsraten und Token-Nutzung. Tools wie Prometheus lassen sich einfach für Dashboards integrieren.
Fazit
Sie beherrschen nun die Z-Image API vollständig. Vom Verständnis der Open-Source-Architektur von Z-Image-Turbo über die Ausführung von API-Aufrufen bis hin zur Optimierung von Workflows rüstet Sie dieser Leitfaden für den Erfolg. Das kostenlose Preismodell demokratisiert die fortschrittliche Bildgenerierung, während Tools wie Apidog die Entwicklung optimieren.
Implementieren Sie diese Techniken in Ihrem nächsten Projekt. Experimentieren Sie mit Prompts, skalieren Sie Integrationen und tragen Sie zum Ökosystem bei. Während sich die KI weiterentwickelt, positioniert Sie Z-Image-Turbo an der Spitze effizienter, kreativer Tools.