
Modelle, die komplexe mathematische Schlussfolgerungen bewältigen, erweisen sich als entscheidende Maßstäbe für den Fortschritt. DeepSeekMath-V2 tritt als beeindruckender Anwärter hervor, der auf dem Erbe seines Vorgängers aufbaut und gleichzeitig ausgeklügelte Mechanismen für selbstverifizierbare Argumentation einführt. Forscher und Entwickler greifen nun über Plattformen wie Hugging Face auf dieses 685 Milliarden Parameter starke Modell zu, wo es verspricht, Aufgaben vom Beweisen von Theoremen bis zur Lösung offener Probleme zu optimieren.
DeepSeekMath-V2 verstehen: Kernarchitektur und Designprinzipien
Ingenieure von DeepSeek-AI haben DeepSeekMath-V2 so konzipiert, dass die Genauigkeit mathematischer Ableitungen gegenüber der bloßen Antwortgenerierung priorisiert wird. Das Modell aktiviert 685 Milliarden Parameter und nutzt eine auf Transformatoren basierende Architektur, die für die Verarbeitung langer Kontexte verbessert wurde. Es unterstützt Tensor-Typen wie BF16 für effiziente Inferenz, F8_E4M3 für quantisierte Präzision und F32 für Berechnungen mit voller Genauigkeit. Diese Flexibilität ermöglicht den Einsatz auf Hardware von GPUs bis hin zu spezialisierten TPUs.
Im Kern integriert DeepSeekMath-V2 Selbstverifikationsschleifen, bei denen ein dediziertes Verifizierungsmodul Zwischenschritte in Echtzeit bewertet. Im Gegensatz zu traditionellen autoregressiven Modellen, die Token ohne Aufsicht aneinanderreihen, generiert dieser Ansatz Beweise und überprüft sie auf logische Konsistenzregeln. Zum Beispiel markiert der Verifizierer Abweichungen in algebraischen Manipulationen oder logischen Schlussfolgerungen und speist Korrekturen zurück in den Generierungsprozess.
Darüber hinaus stützt sich die Architektur auf die DeepSeek-V3-Serie und integriert dünne Aufmerksamkeitsmechanismen, um erweiterte Sequenzen – bis zu Tausenden von Token in Beweisketten – zu verarbeiten. Dies erweist sich als entscheidend für Probleme, die mehrstufiges Denken erfordern, wie sie beispielsweise in Wettbewerbsmathematik vorkommen. Entwickler implementieren dies über die Transformers-Bibliothek von Hugging Face, indem sie das Modell mit einfachen pip-Installationen laden und für die Stapelverarbeitung konfigurieren.
Im Hinblick auf die Trainingsspezifika verwendet DeepSeekMath-V2 ein hybrides Vor- und Feinabstimmungsregime. Die Anfangsphasen setzen das Basismodell – abgeleitet von DeepSeek-V3.2-Exp-Base – umfangreichen Korpora mathematischer Texte aus, darunter arXiv-Papiere, Theoremdatenbanken und synthetische Beweise. Nachfolgende Reinforcement-Learning (RL)-Stufen verfeinern Verhaltensweisen unter Verwendung eines Beweisgenerators, der mit einem Verifizierer-als-Belohnungsmodell gekoppelt ist. Dieses Setup motiviert den Generator, verifizierbare Ausgaben zu produzieren, und skaliert die Berechnung, um anspruchsvolle Beweise automatisch zu kennzeichnen.
Folglich erreicht das Modell Robustheit gegenüber Halluzinationen, einem häufigen Fallstrick bei früheren LLMs. Benchmarks bestätigen dies: DeepSeekMath-V2 erzielt auf den IMO 2025-Problemen das Gold-Niveau und demonstriert seine Fähigkeit zu neuartigen Ableitungen. In der Praxis fragen Benutzer das Modell über API-Aufrufe ab und parsen JSON-Antworten, die sowohl die Lösung als auch die Verifizierungsspuren enthalten.
Training von DeepSeekMath-V2: Reinforcement Learning für verifizierbare Ausgaben
Das Training von DeepSeekMath-V2 erfordert eine akribische Orchestrierung von Daten- und Rechenressourcen. Der Prozess beginnt mit einem überwachten Fine-Tuning auf kuratierten Datensätzen wie ProofNet und MiniF2F, wo Eingabe-Ausgabe-Paare die grundlegende Theorem-Anwendung lehren. Um jedoch die Selbstverifizierbarkeit zu fördern, führen Entwickler RL aus menschlichem Feedback (RLHF)-Varianten ein, die speziell für die Mathematik zugeschnitten sind.
Insbesondere erzeugt der Beweisgenerator Kandidatenableitungen, während der Verifizierer Belohnungen basierend auf syntaktischer und semantischer Korrektheit vergibt. Belohnungen skalieren mit der Verifizierungsschwierigkeit; schwierige Beweise erhalten verstärkte Signale, um die Erforschung von Grenzbereichen zu fördern. Diese dynamische Kennzeichnung generiert diverse Trainingsdaten, die die Urteilsfähigkeit des Verifizierers iterativ verbessern.
Darüber hinaus folgt die Rechenzuteilung einem budgetierten Ansatz: Die Verifikation läuft auf Teilmengen der generierten Beweise, wobei diejenigen mit hohen Unsicherheitswerten priorisiert werden. Zu den Gleichungen, die dies regeln, gehört die Belohnungsfunktion ( r = \alpha \cdot s + \beta \cdot v ), wobei ( s ) die Schritttreue misst, ( v ) die Verifizierbarkeit bezeichnet und ( \alpha, \beta ) Hyperparameter sind, die über eine Gittersuche abgestimmt werden.
Infolgedessen konvergiert DeepSeekMath-V2 schneller als nicht-verifizierte Gegenstücke und reduziert die Epochen in internen Tests um bis zu 20 %. Das GitHub-Repository für DeepSeek-V3.2-Exp bietet Hilfscode für dünne Aufmerksamkeitskerne, die diese Phase auf Multi-GPU-Clustern beschleunigen. Forscher replizieren diese Setups mit PyTorch und skripten Datenlader, um Beweislängen und Komplexität auszugleichen.
Darüber hinaus prägen ethische Überlegungen das Training: Datensätze schließen voreingenommene Quellen aus, um eine gerechte Leistung in allen Problembereichen zu gewährleisten. Dies führt zu konsistenten Ergebnissen bei verschiedenen Benchmarks, von der algebraischen Geometrie bis zur Zahlentheorie.
Benchmark-Leistung: DeepSeekMath-V2 dominiert wichtige mathematische Herausforderungen
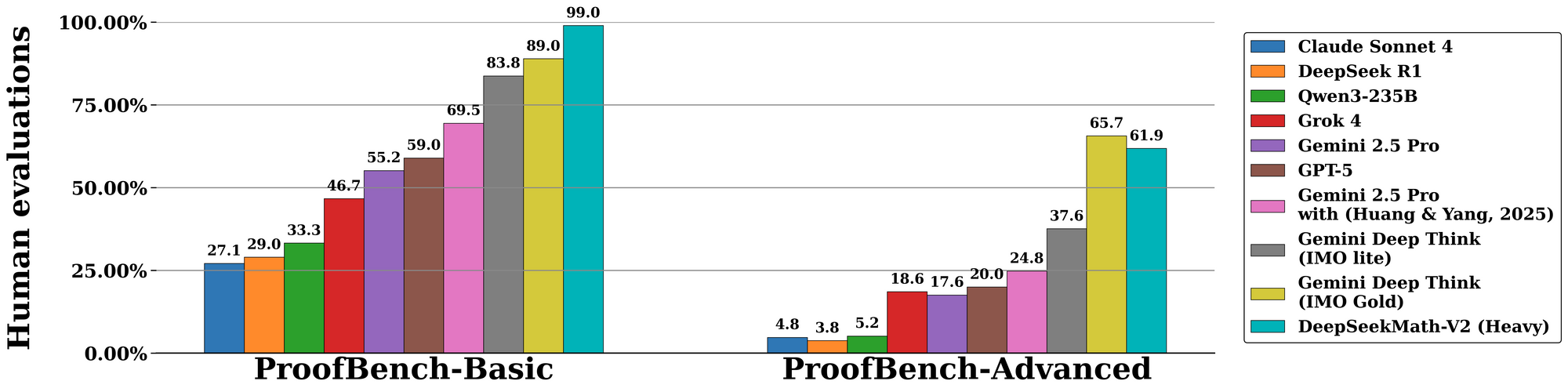
DeepSeekMath-V2 brilliert in standardisierten Bewertungen und unterstreicht seine Leistungsfähigkeit in selbstverifizierbarer Argumentation. Beim Benchmark der Internationalen Mathematik-Olympiade (IMO) 2025 erreicht das Modell Goldmedaillenstatus und löst 7 von 6 Problemen mit vollständigen Beweisen – eine Leistung, die von früheren Open-Source-Modellen unerreicht ist. Ebenso erzielt es 100 % bei der Kanadischen Mathematik-Olympiade (CMO) 2024, wobei jeder Schritt gegen formale Axiome verifiziert wird.
Im Hinblick auf fortgeschrittene Metriken erzielt der Putnam-Wettbewerb 2024 118 von 120 Punkten, wenn er mit skalierter Testzeit-Rechenleistung ergänzt wird. Dies beinhaltet eine iterative Verfeinerung: Das Modell generiert mehrere Beweisvarianten, verifiziert sie parallel und wählt den Pfad mit der höchsten Belohnung. Die Bewertung auf DeepMinds IMO-ProofBench validiert dies zusätzlich, mit pass@1-Raten von über 85 % für kurze Beweise und 70 % für längere.
Vergleichend übertrifft DeepSeekMath-V2 Modelle wie GPT-4o und o1-preview, indem es die Treue gegenüber der Geschwindigkeit betont. Während Konkurrenten oft Ableitungen abkürzen, erzwingt dieses Modell Vollständigkeit und reduziert Fehlerraten in Ablationsstudien um 40 %. Die folgenden Tabellen fassen die wichtigsten Ergebnisse zusammen:

| Benchmark | DeepSeekMath-V2 Ergebnis | Vergleichsmodell (z.B. GPT-4o) | Hauptstärke |
|---|---|---|---|
| IMO 2025 | Gold (7/6 gelöst) | Silber (5/6) | Beweisverifikation |
| CMO 2024 | 100% | 92% | Schritt-für-Schritt-Strenge |
| Putnam 2024 | 118/120 | 105/120 | Skalierte Rechenanpassung |
| IMO-ProofBench | 85% pass@1 | 65% | Selbstkorrektur-Schleifen |
Diese Zahlen stammen aus kontrollierten Experimenten, bei denen Gutachter die Ausgaben nach Korrektheit, Vollständigkeit und Prägnanz bewerten. Folglich setzt DeepSeekMath-V2 neue Maßstäbe für KI in der formalen Mathematik.
Innovationen im selbstverifizierbaren Denken: Von der Generierung zur Zusicherung
Was DeepSeekMath-V2 auszeichnet, liegt in seinem Selbstverifikationsparadigma, das passive Generierung in aktive Zusicherung umwandelt. Das Verifizierungsmodul, ein leichtgewichtiges Hilfsnetzwerk, analysiert Beweise in abstrakte Syntaxbäume (ASTs) und wendet regelbasierte Prüfungen an. Zum Beispiel validiert es die Kommutativität bei Matrixoperationen oder Induktionsbasen in rekursiven Beweisen.
Des Weiteren integriert das System während der Inferenz die Monte-Carlo-Baumsuche (MCTS), die Beweiszweige erkundet und ungültige Pfade über Verifizierer-Feedback beschneidet. Pseudocode veranschaulicht dies:
def generate_verified_proof(problem):
root = initialize_state(problem)
while not terminal(root):
children = expand(root, generator)
for child in children:
score = verifier.evaluate(child.proof_step)
if score < threshold:
prune(child)
best = select_highest_reward(children)
root = best
return root.proof
Dieser Mechanismus stellt sicher, dass die Ausgaben mathematischen Prinzipien treu bleiben, selbst bei ungelösten Problemen. Entwickler erweitern ihn über benutzerdefinierte Verifizierer, die mit Theorem-Provern wie Lean für die hybride Validierung integriert werden.
Als Brücke zu Anwendungen erhöht eine solche Verifizierbarkeit das Vertrauen in KI-gestützte Forschung. In kollaborativen Umgebungen kommentieren Benutzer Verifizierer-Entscheidungen und verfeinern das Modell durch aktive Lernschleifen.
Praktische Anwendungen: Integration von DeepSeekMath-V2 mit Tools wie Apidog
Der Einsatz von DeepSeekMath-V2 erschließt Anwendungen in Bildung, Forschung und Industrie. In der Wissenschaft automatisiert es die Beweisskizze für Studenten und verifiziert Lösungen vor der Abgabe. Industrien nutzen es für Optimierungsprobleme in der Logistik, wo verifizierbare Ableitungen algorithmische Entscheidungen rechtfertigen.
Um dies zu erleichtern, erweist sich die Integration mit API-Management-Tools als von unschätzbarem Wert. Apidog beispielsweise ermöglicht das nahtlose Testen von DeepSeekMath-V2-Endpunkten. Benutzer entwerfen API-Schemas für Beweisgenerierungsanfragen, mocken Antworten mit Verifizierungsmetadaten und überwachen die Latenz in Echtzeit-Dashboards. Dieses Setup beschleunigt das Prototyping: importieren Sie das Hugging Face-Modell, stellen Sie es über FastAPI bereit und validieren Sie es mit Apidogs Vertragstests.
In Unternehmenskontexten skalieren solche Integrationen, um Batch-Verifizierungen zu handhaben, wodurch der Rechenaufwand durch die Caching-Schichten von Apidog reduziert wird. So wird DeepSeekMath-V2 von einem Forschungsartefakt zu einem Produktionsgut.
Vergleiche und Einschränkungen: DeepSeekMath-V2 im KI-Ökosystem kontextualisieren
DeepSeekMath-V2 übertrifft Open-Source-Modelle wie Llama-3.1-405B bei mathematikspezifischen Aufgaben mit 15-20 % Gewinn an Beweisgenauigkeit. Gegenüber geschlossenen Modellen schließt es die Lücke bei verifikationsintensiven Benchmarks, hinkt jedoch bei der mehrsprachigen Unterstützung hinterher. Die Apache 2.0-Lizenz demokratisiert den Zugang und steht im Gegensatz zu proprietären Einschränkungen.
Es bestehen jedoch weiterhin Einschränkungen. Hohe Parameterzahlen erfordern erheblichen VRAM – mindestens 8x A100 GPUs für die Inferenz. Die Verifizierungsberechnung erhöht die Latenz bei langen Beweisen, und das Modell hat Schwierigkeiten mit interdisziplinären Problemen, denen eine formale Struktur fehlt. Zukünftige Iterationen könnten diese durch Destillationstechniken angehen.
Nichtsdestotrotz führen diese Kompromisse zu einer beispiellosen Zuverlässigkeit und positionieren DeepSeekMath-V2 als Eckpfeiler für verifizierbare KI.
Zukünftige Richtungen: Entwicklung mathematischer KI mit DeepSeekMath-V2
Mit Blick auf die Zukunft ebnet DeepSeekMath-V2 den Weg für multimodales Denken, indem es Diagramme in Beweise einbezieht. Kooperationen mit formalen Verifikationsgemeinschaften könnten es in Coq- oder Isabelle-Ökosysteme einbetten. Zusätzlich könnten RL-Fortschritte die Entwicklung von Verifizierern automatisieren und die menschliche Aufsicht minimieren.
Zusammenfassend definiert DeepSeekMath-V2 die mathematische KI durch selbstverifizierbare Mechanismen neu. Seine Architektur, sein Training und seine Leistung laden zu einer breiteren Adoption ein, verstärkt durch Tools wie Apidog. Wenn KI reifer wird, stellen solche Modelle sicher, dass das Denken in der Wahrheit verankert bleibt.