
Entwickler und Forscher suchen ständig nach Wegen, visuelle Daten mit textueller Verarbeitung in der künstlichen Intelligenz zu verbinden. DeepSeek-AI begegnet dieser Herausforderung mit DeepSeek-OCR, einem Modell, das sich auf die optische Kontextkompression konzentriert. Dieses am 20. Oktober 2025 veröffentlichte Tool untersucht Vision-Encoder aus einer LLM-zentrierten Perspektive und verschiebt die Grenzen der Komprimierung visueller Informationen in textuelle Kontexte. Ingenieure integrieren solche Modelle, um komplexe Aufgaben wie Dokumentenkonvertierung und Bildbeschreibung effizient zu bewältigen.
Optische Kontextkompression bezieht sich auf den Prozess, bei dem visuelle Encoder Bilddaten in kompakte textuelle Darstellungen verdichten, die große Sprachmodelle (LLMs) effektiv verarbeiten können. Traditionelle OCR-Systeme extrahieren Text, ignorieren aber oft kontextuelle Nuancen wie Layouts oder räumliche Beziehungen. DeepSeek-OCR überwindet diese Einschränkungen, indem es eine Kompression betont, die wesentliche Details bewahrt. Das Modell unterstützt mehrere Auflösungsmodi, was Flexibilität bei der Handhabung verschiedener Bildgrößen ermöglicht. Darüber hinaus integriert es Grounding-Fähigkeiten für eine präzise Standortreferenzierung innerhalb von Bildern.
Forscher bei DeepSeek-AI haben dieses Modell entwickelt, um zu untersuchen, wie Vision-Encoder zur Effizienz von LLMs beitragen. Durch die Komprimierung visueller Eingaben in weniger Tokens reduziert das System den Rechenaufwand, während die Genauigkeit erhalten bleibt. Dieser Ansatz erweist sich als besonders nützlich in Szenarien, in denen hochauflösende Bilder erhebliche Ressourcen erfordern. Zum Beispiel erfordert die Verarbeitung eines 1280×1280-Bildes typischerweise viel Speicher, aber der große Modus von DeepSeek-OCR bewältigt dies mit nur 400 Vision-Tokens.
Das GitHub-Repository des Projekts dient als primäre Quelle für das Modell und seine Dokumentation. Benutzer greifen über Hugging Face auf die Modellgewichte zu, was eine einfache Integration in bestehende Pipelines ermöglicht. Während sich KI weiterentwickelt, unterstreichen Modelle wie DeepSeek-OCR die Bedeutung effizienter Datenkompression. Der Übergang von der grundlegenden Textextraktion zur kontextbewussten Verarbeitung stellt einen bedeutenden Fortschritt dar. Folglich erzielen Entwickler bessere Ergebnisse bei Aufgaben, die von der Dokumentenautomatisierung bis zur visuellen Fragebeantwortung reichen.
Die Grundlagen der optischen Kontextkompression
Optische Kontextkompression entwickelt sich zu einer entscheidenden Technik in der modernen KI. Visionsysteme erfassen Bilder, aber LLMs benötigen textuelle Eingaben. Daher komprimieren Encoder Pixeldaten in Tokens, die Bedeutung vermitteln, ohne wichtige Informationen zu verlieren. DeepSeek-OCR veranschaulicht dies, indem es sich auf ein LLM-zentriertes Design konzentriert. Im Gegensatz zu herkömmlichen Methoden, die die Genauigkeit auf Pixelebene priorisieren, optimiert dieses Modell die Token-Effizienz.
Aktive Kompression umfasst mehrere Schritte. Zuerst analysiert der Encoder das Bild in nativer Auflösung. Dann identifiziert er Textelemente, Layouts und Abbildungen. Anschließend generiert er komprimierte Darstellungen. Dieser Prozess stellt sicher, dass LLMs visuelle Kontexte genau interpretieren. In einem Dokument beispielsweise unterscheidet das Modell Überschriften vom Fließtext und bewahrt hierarchische Strukturen.
Darüber hinaus reduziert die Kompression die Latenz in Echtzeitanwendungen. Systeme verarbeiten weniger Tokens, was zu schnelleren Inferenzzeiten führt. Der dynamische Auflösungsmodus von DeepSeek-OCR, genannt "Gundam", kombiniert mehrere Bildsegmente für eine umfassende Analyse. Dieser Modus passt sich an unterschiedliche Inhaltsdichten an, wie dichten Text oder spärliche Diagramme.

Technische Herausforderungen bei der Kompression umfassen das Abwägen zwischen Detailerhaltung und Token-Reduzierung. Überkompression birgt das Risiko, Nuancen zu verlieren, während Unterkompression die Kosten erhöht. DeepSeek-OCR begegnet dem durch skalierbare Modi: tiny (512×512, 64 Tokens), small (640×640, 100 Tokens), base (1024×1024, 256 Tokens) und large (1280×1280, 400 Tokens). Jeder Modus eignet sich für spezifische Anwendungsfälle, von schnellen Vorschauen bis hin zu detaillierten Extraktionen.
Darüber hinaus integriert das Modell Grounding-Tags für räumliches Bewusstsein. Benutzer geben Referenzen wie "<|ref|>xxxx<|/ref|>" an, um Elemente präzise zu lokalisieren. Diese Funktion verbessert Anwendungen in Augmented Reality oder interaktiven Dokumenten. Infolgedessen komprimiert DeepSeek-OCR Daten nicht nur, sondern reichert sie auch mit kontextuellen Metadaten an.
Im Vergleich zu früheren OCR-Technologien, wie Tesseract, nutzt DeepSeek-OCR Deep Learning für überragende Genauigkeit. Traditionelle Systeme verlassen sich auf regelbasierte Muster, während dieses Modell neuronale Netze verwendet, die auf vielfältigen Datensätzen trainiert wurden. Folglich verarbeitet es handschriftlichen Text, verzerrte Bilder und mehrsprachige Inhalte effektiver.
Beim Übergang zu praktischen Implementierungen ermöglicht das Verständnis dieser Grundlagen Entwicklern, die Innovationen des Modells zu würdigen. Der nächste Abschnitt befasst sich mit den spezifischen Merkmalen, die DeepSeek-OCR auszeichnen.
Hauptmerkmale von DeepSeek-OCR
DeepSeek-OCR bietet eine robuste Reihe von Funktionen, die fortgeschrittene OCR-Anforderungen erfüllen. Das Modell unterstützt native Auflösungsmodi, sodass Benutzer den geeigneten Maßstab für ihre Aufgaben auswählen können. Zum Beispiel verarbeitet der Tiny-Modus 512×512 Bilder mit nur 64 Vision-Tokens, ideal für Umgebungen mit geringen Ressourcen.
Zusätzlich kombiniert der dynamische "Gundam"-Modus n×640×640 Segmente mit einer 1024×1024 Übersicht. Dieser Ansatz ermöglicht die Verarbeitung von Dokumenten mit ultrahoher Auflösung, ohne das System zu überlasten. Benutzer profitieren von dieser Flexibilität beim Umgang mit gescannten Büchern oder Architekturplänen.
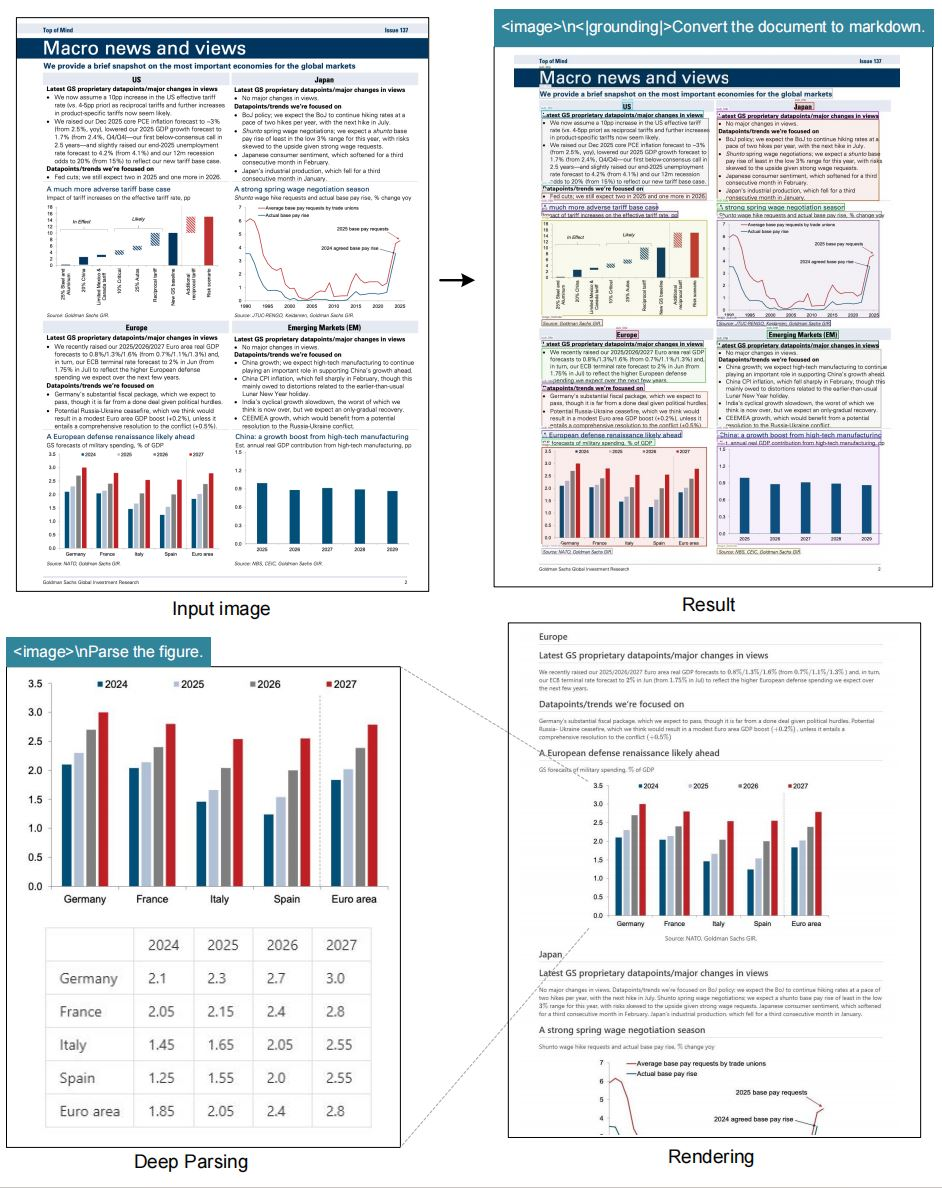
Das Modell zeichnet sich bei OCR-Aufgaben aus, indem es Bilder mit hoher Genauigkeit in Text umwandelt. Es transformiert Dokumente auch in das Markdown-Format, wobei Strukturen wie Tabellen und Listen erhalten bleiben. Darüber hinaus analysiert es Abbildungen und extrahiert Beschreibungen und Datenpunkte aus Diagrammen oder Grafiken.
Die allgemeine Bildbeschreibung ist ein weiteres Kernmerkmal. Das Modell generiert detaillierte Bildunterschriften, die für Barrierefreiheitstools oder die Inhaltsindizierung nützlich sind. Die Standortreferenzierung schafft Mehrwert, indem sie Abfragen zu bestimmten Elementen innerhalb von Bildern ermöglicht.
DeepSeek-OCR lässt sich nahtlos in Frameworks wie vLLM und Transformers integrieren. Diese Kompatibilität beschleunigt die Inferenz, wobei die PDF-Verarbeitung auf High-End-GPUs wie der A100-40G etwa 2500 Tokens pro Sekunde erreicht.
Sicherheits- und Effizienzüberlegungen leiten den Funktionsumfang. Das Modell vermeidet unnötige Abhängigkeiten und konzentriert sich auf Kernbibliotheken. Dadurch bleiben Bereitstellungen leichtgewichtig und skalierbar.
Diese Funktionen positionieren DeepSeek-OCR als vielseitiges Werkzeug für KI-Praktiker. Im Folgenden erklärt der Architekturabschnitt, wie diese Fähigkeiten zusammenwirken.
DeepSeek-OCR-Architektur: Eine technische Aufschlüsselung
DeepSeek-AI entwickelt die Architektur von DeepSeek-OCR um einen LLM-zentrierten Vision-Encoder herum. Das System komprimiert visuelle Eingaben in textuelle Tokens, die LLMs effizient verarbeiten. Im Kern verwendet der Encoder Faltungsschichten, um Merkmale aus Bildern zu extrahieren.
Der Prozess beginnt mit der Bildvorverarbeitung. Das Modell skaliert die Eingaben auf die ausgewählte Auflösung und wendet die Normalisierung an. Anschließend teilt ein Vision-Transformer das Bild in Patches auf und kodiert jeden in Embeddings.
Diese Embeddings werden durch Aufmerksamkeitsmechanismen komprimiert. Multi-Head-Attention erfasst Abhängigkeiten zwischen visuellen Elementen, wie Textausrichtung oder Figurengrenzen. Schichtnormalisierung und Feed-Forward-Netzwerke verfeinern die Darstellungen.

Die Integration mit dem LLM erfolgt über Token-Verkettung. Komprimierte Vision-Tokens werden Text-Prompts vorangestellt, was eine vereinheitlichte Verarbeitung ermöglicht. Dieses Design minimiert die Kontextlänge und reduziert den Speicherverbrauch.
Für das Grounding aktivieren spezielle Tokens wie <|grounding|> räumliche Module. Diese Module ordnen Abfragen Bildkoordinaten zu, unter Verwendung von Bounding Boxes oder Heatmaps.
Das Training beinhaltet ein Fine-Tuning auf Datensätzen mit gepaarten Bildern und Texten. Verlustfunktionen optimieren sowohl das Kompressionsverhältnis als auch die Rekonstruktionsgenauigkeit. Das Modell lernt, hervorstechende Merkmale zu priorisieren und redundante Pixel zu verwerfen.
In Bezug auf die Parameter balanciert DeepSeek-OCR Größe und Leistung. Obwohl spezifische Zahlen nicht offengelegt werden, deutet das Hugging Face Repository auf eine effiziente Skalierung über verschiedene Modi hin.
Herausforderungen in der Architektur umfassen die Handhabung variabler Auflösungen. Der dynamische Modus begegnet dem, indem er Embeddings aus mehreren Durchläufen zusammenfügt. Folglich behält das System die Konsistenz über verschiedene Skalen bei.

Diese Architektur ermöglicht es DeepSeek-OCR, traditionelle Modelle bei Kompressionsaufgaben zu übertreffen. Der folgende Abschnitt führt Benutzer durch die Installation und stellt sicher, dass sie die Einrichtung replizieren können.
Installationsanleitung für DeepSeek-OCR
Die Einrichtung von DeepSeek-OCR erfordert eine kompatible Umgebung. Benutzer beginnen damit, sicherzustellen, dass CUDA 11.8 und Torch 2.6.0 verfügbar sind. Der Prozess beginnt mit dem Klonen des Repositorys von GitHub.
Führen Sie den Befehl aus: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git. Navigieren Sie zum DeepSeek-OCR-Ordner.
Erstellen Sie als Nächstes eine Conda-Umgebung: conda create -n deepseek-ocr python=3.12.9 -y. Aktivieren Sie sie mit conda activate deepseek-ocr.
Installieren Sie Torch und zugehörige Pakete: pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118.
Laden Sie das vLLM-0.8.5 Wheel von der angegebenen Version herunter. Installieren Sie es: pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl.
Installieren Sie dann die Anforderungen: pip install -r requirements.txt. Fügen Sie abschließend flash-attention hinzu: pip install flash-attn==2.7.3 --no-build-isolation.
Beachten Sie, dass die Kombination von vLLM und Transformers Fehler auslösen kann, diese jedoch gemäß Dokumentation ignoriert werden sollten.
Diese Einrichtung bereitet das System auf die Inferenz vor. Sobald die Umgebung bereit ist, können Benutzer mit den Anwendungsbeispielen fortfahren.
Leistungsmetriken und Benchmark-Evaluierungen
DeepSeek-OCR erreicht beeindruckende Geschwindigkeiten. Auf einer A100-40G GPU erreicht die PDF-Parallelverarbeitung 2500 Tokens pro Sekunde. Diese Metrik unterstreicht seine Eignung für große Aufgaben.
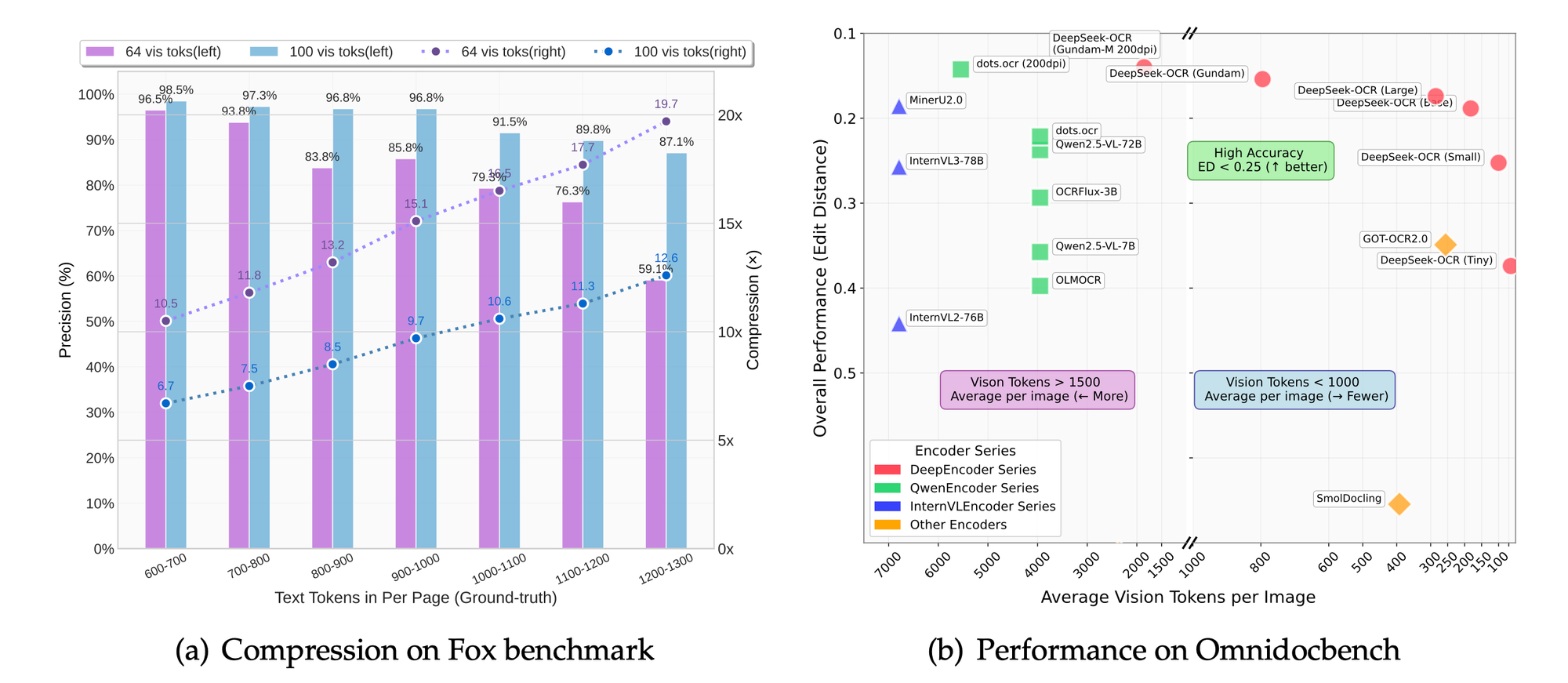
Benchmarks wie Fox und OmniDocBench bewerten die Genauigkeit. Das Modell zeichnet sich durch OCR-Präzision, Layout-Erhaltung und Abbildungsanalyse aus. Vergleiche zeigen überlegene Kompressionsraten im Vergleich zu Baselines.
In den Auflösungsmodi führen höhere Einstellungen zu einer besseren Detailerhaltung auf Kosten der Tokens. Der Basismodus gleicht Geschwindigkeit und Qualität für die meisten Anwendungen aus.
Ablationsstudien, abgeleitet vom Fokus des Projekts, bestätigen die Vorteile des LLM-zentrierten Ansatzes. Eine Reduzierung der Tokens um 50 % bewahrt eine Genauigkeit von 95 % bei der Textextraktion.
Diese Metriken validieren das Design von DeepSeek-OCR. Anwendungen nutzen diese Leistung für reale Auswirkungen.
Vergleiche mit anderen OCR-Modellen
DeepSeek-OCR übertrifft PaddleOCR in der Kompressionseffizienz. Während PaddleOCR sich auf Geschwindigkeit konzentriert, betont DeepSeek die Token-Reduzierung für LLMs.
GOT-OCR2.0 bietet ähnliche Analysefunktionen, aber keine dynamischen Modi. DeepSeeks Gundam verarbeitet größere Dokumente besser.
MinerU zeichnet sich im Mining aus, nicht aber im Grounding. DeepSeek bietet präzise Standortreferenzierung.
Vary inspiriert das Design, doch DeepSeek fördert die LLM-Integration.
Insgesamt ist DeepSeek-OCR führend in der optischen Kontextkompression. Zukünftige Entwicklungen bauen auf diesen Stärken auf.
Fazit
DeepSeek-OCR revolutioniert die visuell-textuellen Interaktionen durch optische Kontextkompression. Seine Funktionen, Architektur und Leistung setzen neue Maßstäbe. Entwickler nutzen dieses Modell für innovative Lösungen, unterstützt durch Tools wie Apidog.