
Welcome! If you've ever wondered how to leverage cutting-edge AI tools for web scraping and content analysis, then you're in the right place. Today, we'll dive deep into an exciting project that combines OpenAI SWARM, Streamlit, and multi-agent systems to make web scraping smarter and content analysis more insightful. We'll also explore how Apidog can simplify API testing and serve as a more affordable alternative for your API needs.
Now, let’s get started on building a fully functional web scraping and content analysis system!
1. What is OpenAI SWARM?
OpenAI SWARM is an emerging approach for leveraging AI and multi-agent systems to automate various tasks, including web scraping and content analysis. At its core, SWARM focuses on using multiple agents that can work independently or collaborate on specific tasks to achieve a common goal.

How SWARM Works
Imagine you want to scrape multiple websites to gather data for analysis. Using a single scraper bot may work, but it's prone to bottlenecks, errors, or even getting blocked by the website. SWARM, however, lets you deploy several agents to tackle different aspects of the task—some agents focus on data extraction, others on data cleaning, and still others on transforming the data for analysis. These agents can communicate with one another, ensuring efficient handling of the tasks.
By combining OpenAI’s powerful language models and SWARM methodologies, you can build smart, adaptive systems that mimic human problem-solving. We’ll be using SWARM techniques for smarter web scraping and data processing in this tutorial.
2. Introduction to Multi-Agent Systems
A multi-agent system (MAS) is a collection of autonomous agents that interact in a shared environment to solve complex problems. The agents can perform tasks in parallel, making MAS ideal for situations where data must be gathered from various sources or different processing stages are needed.
In the context of web scraping, a multi-agent system might involve agents for:
- Data Extraction: Crawling different web pages to collect relevant data.
- Content Parsing: Cleaning and organizing the data for analysis.
- Data Analysis: Applying algorithms to derive insights from the collected data.
- Reporting: Presenting the results in a user-friendly format.
Why Use Multi-Agent Systems for Web Scraping?
Multi-agent systems are robust against failures and can operate asynchronously. This means that even if one agent fails or encounters a problem, the rest can continue their tasks. The SWARM approach thus ensures higher efficiency, scalability, and fault tolerance in web scraping projects.
3. Streamlit: An Overview
Streamlit is a popular open-source Python library that makes it easy to create and share custom web applications for data analysis, machine learning, and automation projects. It provides a framework where you can build interactive UIs without any frontend experience.
Why Streamlit?
- Ease of Use: Write Python code, and Streamlit converts it into a user-friendly web interface.
- Quick Prototyping: Allows for rapid testing and deployment of new ideas.
- Integration with AI Models: Seamlessly integrates with machine learning libraries and APIs.
- Customization: Flexible enough to build sophisticated apps for different use cases.
In our project, we’ll use Streamlit to visualize web scraping results, display content analysis metrics, and create an interactive interface for controlling our multi-agent system.
4. Why Apidog is a Game-Changer
Apidog is a robust alternative to traditional API development and testing tools. It supports the entire API lifecycle, from design to testing and deployment, all within one unified platform.
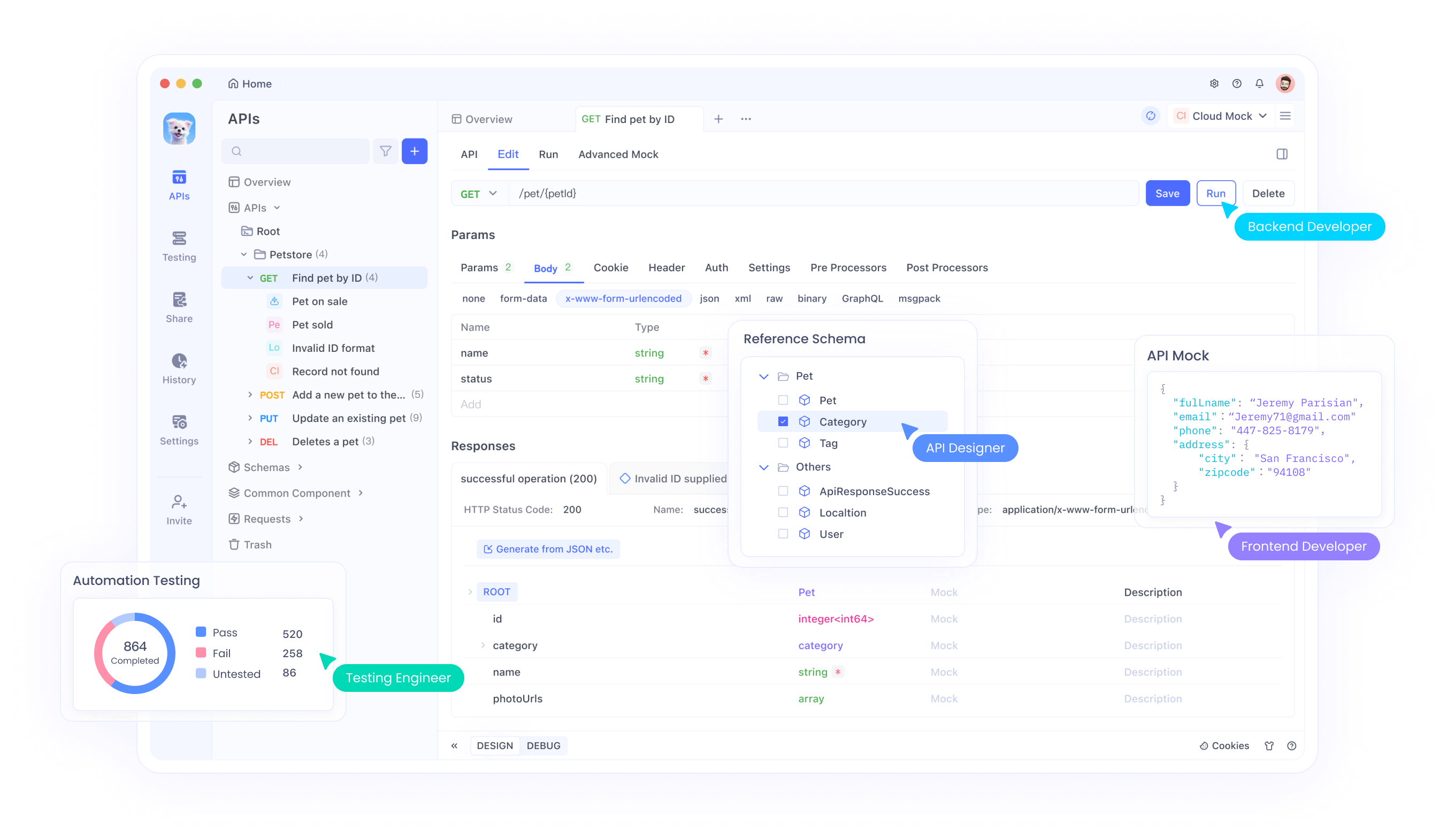
Key Features of Apidog:
- User-Friendly Interface: Easy-to-use drag-and-drop API design.
- Automated Testing: Perform comprehensive API testing without writing additional scripts.
- Built-in Documentation: Generate detailed API documentation automatically.
- Cheaper Pricing Plans: Offers a more affordable option compared to competitors.
Apidog is a perfect match for projects where API integration and testing are essential, making it a cost-effective and comprehensive solution.
Download Apidog for free to experience these benefits firsthand.
5. Setting Up Your Development Environment
Before diving into the code, let's ensure our environment is ready. You’ll need:
- Python 3.7+
- Streamlit: Install with
pip install streamlit - BeautifulSoup for web scraping: Install with
pip install beautifulsoup4 - Requests: Install with
pip install requests - Apidog: For API testing, you can download it from Apidog's official website
Make sure you have all the above installed. Now, let's configure the environment.
6. Building a Multi-Agent System for Web Scraping
Let's build a multi-agent system for web scraping using OpenAI SWARM and Python libraries. The goal here is to create multiple agents to perform tasks such as crawling, parsing, and analyzing data from various websites.
Step 1: Defining the Agents
We'll create agents for different tasks:
- Crawler Agent: Collects raw HTML from web pages.
- Parser Agent: Extracts meaningful information.
- Analyzer Agent: Processes the data for insights.
Here’s how you can define a simple CrawlerAgent in Python:
import requests
from bs4 import BeautifulSoup
class CrawlerAgent:
def __init__(self, url):
self.url = url
def fetch_content(self):
try:
response = requests.get(self.url)
if response.status_code == 200:
return response.text
else:
print(f"Failed to fetch content from {self.url}")
except Exception as e:
print(f"Error: {str(e)}")
return None
crawler = CrawlerAgent("https://example.com")
html_content = crawler.fetch_content()
Step 2: Adding a Parser Agent
The ParserAgent will clean up and structure the raw HTML:
class ParserAgent:
def __init__(self, html_content):
self.html_content = html_content
def parse(self):
soup = BeautifulSoup(self.html_content, 'html.parser')
parsed_data = soup.find_all('p') # Example: Extracting all paragraphs
return [p.get_text() for p in parsed_data]
parser = ParserAgent(html_content)
parsed_data = parser.parse()
Step 3: Adding an Analyzer Agent
This agent will apply natural language processing (NLP) techniques to analyze the content.
from collections import Counter
class AnalyzerAgent:
def __init__(self, text_data):
self.text_data = text_data
def analyze(self):
word_count = Counter(" ".join(self.text_data).split())
return word_count.most_common(10) # Example: Top 10 most common words
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
print(analysis_result)
7. Content Analysis with SWARM and Streamlit
Now that we have the agents working together, let's visualize the results using Streamlit.
Step 1: Creating a Streamlit App
Start by importing Streamlit and setting up the basic app structure:
import streamlit as st
st.title("Web Scraping and Content Analysis with Multi-Agent Systems")
st.write("Using OpenAI SWARM and Streamlit for smarter data extraction.")
Step 2: Integrating Agents
We'll integrate our agents into the Streamlit app, allowing users to enter a URL and see the scraping and analysis results.
url = st.text_input("Enter a URL to scrape:")
if st.button("Scrape and Analyze"):
if url:
crawler = CrawlerAgent(url)
html_content = crawler.fetch_content()
if html_content:
parser = ParserAgent(html_content)
parsed_data = parser.parse()
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
st.subheader("Top 10 Most Common Words")
st.write(analysis_result)
else:
st.error("Failed to fetch content. Please try a different URL.")
else:
st.warning("Please enter a valid URL.")
Step 3: Deploying the App
You can deploy the app using the command:
streamlit run your_script_name.py
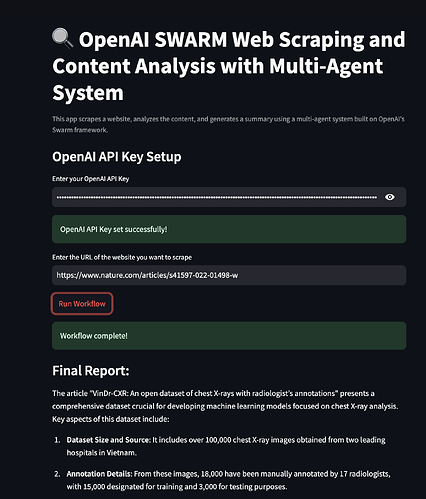
 JT1
JT1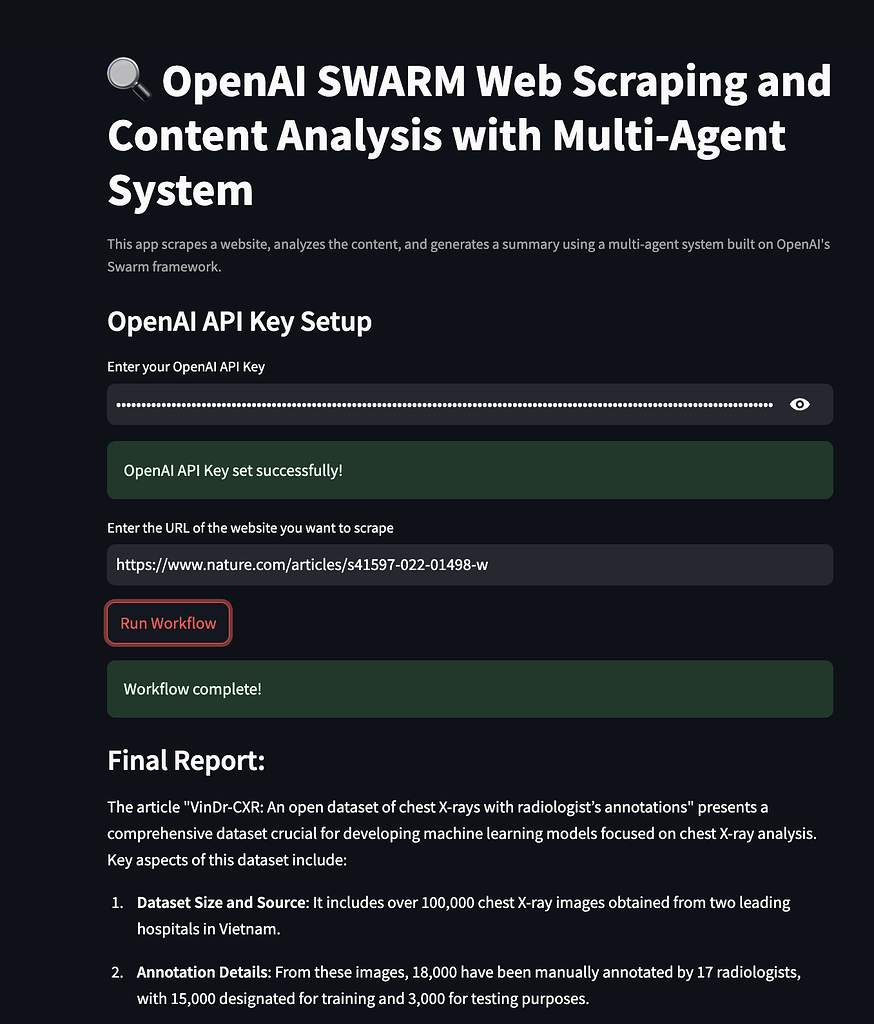
8. Testing APIs with Apidog
Now, let's look at how Apidog can help with testing APIs in our web scraping application.
Step 1: Setting Up Apidog
Download and install Apidog from Apidog's official website. Follow the installation guide to set up the environment.
Step 2: Creating API Requests
You can create and test your API requests directly within Apidog. It supports various request types such as GET, POST, PUT, and DELETE, making it versatile for any web scraping scenario.
Step 3: Automating API Testing
With Apidog, automate testing scripts to validate the response of your multi-agent system when connecting to external services. This ensures your system remains robust and consistent over time.
9. Deploying Your Streamlit Application
Once your application is complete, deploy it for public access. Streamlit makes this easy with its Streamlit Sharing service.
- Host your code on GitHub.
- Navigate to Streamlit Sharing and connect your GitHub repository.
- Deploy your app with a single click.
10. Conclusion
Congratulations! You've learned how to build a powerful web scraping and content analysis system using OpenAI SWARM, Streamlit, and multi-agent systems. We explored how SWARM techniques can make scraping smarter and content analysis more accurate. By integrating Apidog, you also gained insights into API testing and validation to ensure your system's reliability.
Now, go ahead and download Apidog for free to further enhance your projects with powerful API testing features. Apidog stands out as a more affordable and efficient alternative to other solutions, offering a seamless experience for developers.
With this tutorial, you're ready to tackle complex data scraping and analysis tasks more effectively. Good luck, and happy coding!


