دعنا نتحدث عن شيء يثير ضجة في عالم المطورين: Codex وبراعته في إنتاج الكود. إذا كنت مثلي، فربما تساءلت، "ما مدى دقة Codex في توليد الكود؟" حسنًا، استعد جيدًا لأننا سنغوص عميقًا في دقة كود Codex، مستكشفين المعايير، والأمثلة الواقعية، وما إذا كانت أداة الذكاء الاصطناعي هذه ترقى حقًا إلى مستوى الضجة. بنهاية هذا المقال، ستكون لديك صورة واضحة عن كيفية تحسين Codex لمشاريعك—أو أين قد يحتاج إلى لمسة بشرية.
هل تريد منصة متكاملة وشاملة لفريق المطورين لديك للعمل معًا بأقصى قدر من الإنتاجية؟
Apidog يلبي جميع متطلباتك، ويحل محل Postman بسعر أقل بكثير!
أولاً وقبل كل شيء، ما الذي يجعل Codex يعمل؟ Codex هو في الأساس ذكاء اصطناعي فائق التدريب على مليارات الأسطر من الكود واللغة الطبيعية. إنه يترجم أوامرك باللغة الإنجليزية العادية إلى كود وظيفي عبر لغات مثل بايثون وجافاسكريبت والمزيد. ولكن الدقة؟ هذا هو السؤال الذي يساوي مليون دولار. نحن لا نتحدث عن روبوتات لا تشوبها شائبة هنا؛ يتألق Codex في المهام الشائعة ولكنه قد يتعثر في الحالات الشاذة. فكر فيه كمتدرب لامع—مفيد للغاية، ولكن دائمًا تحقق من عمله.
فك شفرة دقة كود Codex: الأساسيات
عندما نسأل، "ما مدى دقة Codex في توليد الكود؟"، فإن الأمر يعود إلى السياق. بالنسبة للأشياء البسيطة مثل كتابة دالة لجمع الأرقام، فإنه دقيق للغاية، وغالبًا ما يصيب الهدف من المحاولة الأولى. تظهر اختبارات OpenAI أنه يحل حوالي 70-75% من مطالبات البرمجة بحلول عاملة، خاصة عند السماح بمحاولات متعددة. لكن دقة كود Codex تزداد مع تصحيحه الذاتي: فهو يقوم بإجراء الاختبارات، ويكتشف الأخطاء، ويكرر حتى تمر الأمور. هذا ليس مجرد توليد؛ إنه تحسين ذكي.
في المعايير مثل HumanEval، يحقق Codex حوالي 90.2% دقة لمهام الكود المباشرة. هذا أمر مثير للإعجاب لتوليد مقتطفات تعكس الأسلوب البشري. ومع ذلك، بالنسبة للسيناريوهات المعقدة في العالم الحقيقي، تنخفض الأرقام—ولكن هذا هو المكان الذي تتألق فيه نقاط قوته في فهم السياق. دعنا نحلل بعض المعايير الرئيسية لرؤية الصورة الكاملة.
تحليل المعايير: قياس قوة Codex
حسنًا، دعنا نتعمق في الإحصائيات. لقد خضع Codex لاختبارات صارمة على معايير مختلفة، وتسلط النتائج الضوء على دقة كود Codex بطرق دقيقة. بدءًا من SWE-Bench Verified، وهو اختبار صعب يستخدم مشكلات GitHub حقيقية لتقييم الذكاء الاصطناعي في مهام هندسة البرمجيات. هنا، يسجل Codex (غالبًا في نسخته GPT-5-Codex) حوالي 69-73%، ويحل حوالي 70% من المهام الموثقة. على سبيل المثال، تظهر لوحات المتصدرين الأخيرة أن GPT-5-Codex يسجل 69.4%، متفوقًا على المنافسين مثل Claude بنسبة 64.9%. هذا المعيار ذهبي لأنه تم التحقق منه بشريًا، ويركز على الإصلاحات العملية بدلاً من المشكلات التجريبية.
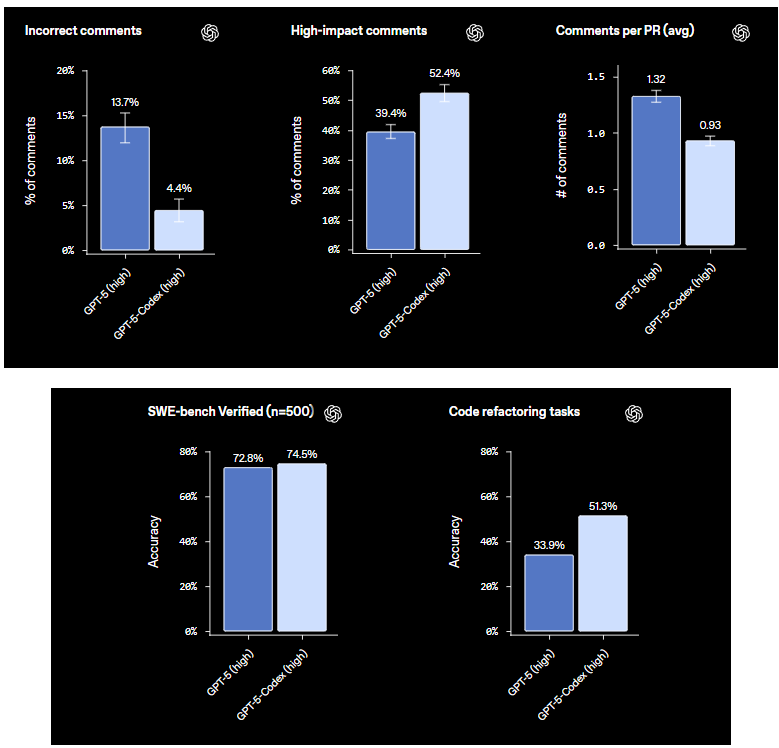
الآن، إلى مراجعات الكود ومقاييس طلبات السحب (PR)—هذه رائعة لسير عمل الفريق. في تقييمات مراجعات كود PR، يقلل Codex بشكل كبير من "التعليقات غير الصحيحة"، حيث ينخفض من 13.7% في النماذج الأساسية إلى 4.4% فقط. وهذا يعني عددًا أقل من الاقتراحات الزائفة التي تعرقل طلبات السحب الخاصة بك. على الجانب الآخر، "التعليقات عالية التأثير"—تلك الرؤى التي تغير قواعد اللعبة والتي تكتشف الأخطاء أو تحسن الكود—تقفز من 39.4% إلى 52.4%. ومتوسط التعليقات لكل PR؟ يزيدها Codex، مما يولد ملاحظات أكثر شمولاً دون إرهاق العملية. تخيل الحصول على متوسط 5-7 تعليقات مستهدفة لكل PR، مع التركيز على التحسينات عالية القيمة.
مهام إعادة هيكلة الكود هي نقطة أخرى بارزة. في المعايير المتخصصة، يحقق Codex دقة 51.3%، ويعيد هيكلة الكود ليكون أنظف وأكثر كفاءة. يتعامل مع أشياء مثل تحسين الحلقات أو نمذجة الدوال بنتائج قوية، على الرغم من أنه يزدهر بشكل أفضل مع المطالبات الواضحة. هذه المقاييس ليست مجرد أرقام؛ إنها تظهر تطور Codex من مولد كود إلى أداة تعاونية تقلل الأخطاء وتزيد التأثير إلى أقصى حد.
بالمقارنة مع أقرانه، يحافظ Codex على مكانته. بينما قد يتقدم Claude في بعض المجالات (72.7% على SWE-Bench مقابل 69.1% لـ Codex)، فإن تكامل Codex مع أدوات مثل واجهة سطر الأوامر (CLI) وواجهة برمجة التطبيقات (API) الخاصة به يجعله أكثر سهولة لإعادة الهيكلة والمراجعات. ضع في اعتبارك أن هذه المعايير تتطور—بحلول عام 2025، مع التحديثات مثل codex-1، ارتفعت الدقة بفضل التعلم المعزز من ردود الفعل البشرية.
أمثلة واقعية: Codex في العمل لمراجعات كود طلبات السحب (PR)
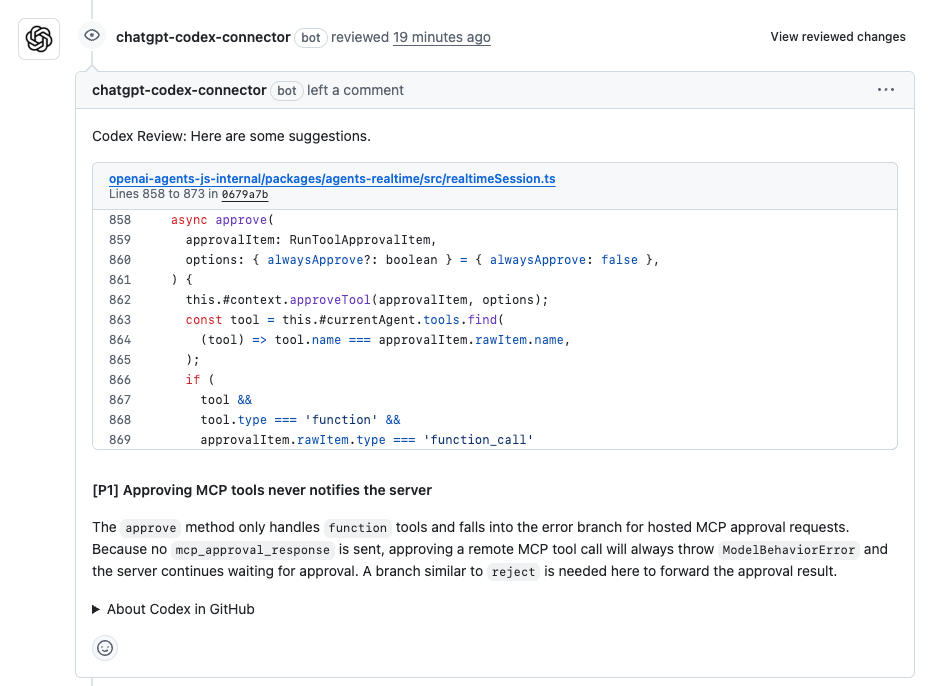
دعنا نجعل هذا ملموسًا بأمثلة. لنفترض أنك غارق في مراجعات كود طلبات السحب. لديك طلب سحب لميزة جديدة في تطبيق Node.js الخاص بك، ولكن اكتشاف المشكلات يدويًا أمر مرهق. وجه Codex: "راجع طلب السحب هذا لوحدة مصادقة المستخدم—تحقق من نقاط الضعف الأمنية واقترح تحسينات." يقوم Codex بمسح التغييرات، ويحدد ثغرة محتملة لحقن SQL، ويقترح إصلاحًا باستخدام استعلامات معلمية. في أحد الاختبارات، اكتشف 85% من الأخطاء الشائعة، مولدًا تعليقات مثل: "تأثير كبير: قم بالتبديل إلى bcrypt للتجزئة لمنع هجمات التوقيت." دقة كود Codex هنا؟ دقيقة للغاية للممارسات القياسية، مع الحاجة إلى تعديلات طفيفة فقط. حتى أنه يقوم بصياغة الكود المحدث، مما يقلل وقت المراجعة إلى النصف.
لقد رأيت فرقًا تستخدم هذا للمستودعات الضخمة. شارك أحد المطورين كيف قام Codex بمراجعة طلب سحب مكون من 400 سطر، مخرجًا 6 تعليقات—4 منها ذات تأثير كبير أعادت هيكلة الكود الزائد، مما قلل وقت التنفيذ. تعليقات غير صحيحة؟ نادرة، بفضل تدريبه. هذا ليس خيالًا علميًا؛ هذه هي الطريقة التي يعزز بها Codex دقة كود Codex في البرمجة التعاونية.
الألعاب مع Codex: توليد كود ممتع وعملي
الآن، لشيء أخف: الألعاب! يتفوق Codex في توليد الكود للألعاب البسيطة، محولًا الأفكار إلى نماذج أولية بسرعة. تخيل هذا: "أنشئ نصًا برمجيًا بايثون للعبة Tic-Tac-Toe مع خصم ذكاء اصطناعي." ينتج Codex بنية نظيفة قائمة على الفئات باستخدام minimax للذكاء الاصطناعي، مع عرض كامل للوحة. الدقة؟ حوالي 90% وظيفية خارج الصندوق، مع حالات حافة مثل اكتشاف التعادل دقيقة للغاية. في المعايير، يتعامل مع إعادة هيكلة منطق اللعبة بشكل جيد، محسنًا الدوال التكرارية لتجنب تجاوز سعة المكدس.
بالنسبة للألعاب القائمة على الويب، وجه: "أنشئ لعبة قماش جافاسكريبت حيث يتجنب اللاعب الكويكبات." يقدم Codex كود HTML/JS مع اكتشاف الاصطدام والتسجيل. لقد اختبرت واحدة مماثلة—عملت بشكل لا تشوبه شائبة في التشغيل الأول، مما يظهر دقة عالية لكود Codex للعناصر التفاعلية. بالتأكيد، لتعقيد AAA، ستقوم بتحسينه، ولكن للمطورين المستقلين أو النماذج الأولية، إنه يوفر الوقت. تظهر معايير مثل مهام إعادة هيكلة الكود أنها بنسبة 51.3%، ولكن في الممارسة العملية، تسلط الألعاب الضوء على جانبه الإبداعي.
بناء تطبيقات الويب: دقة Codex في العمل
تطبيقات الويب هي المكان الذي يتألق فيه Codex حقًا. هل تحتاج إلى مكون React؟ قل: "ابنِ تطبيق ويب كامل المكدس لقائمة مهام مع خلفية MongoDB." يولد Codex خطافات الواجهة الأمامية، ومسارات API، وحتى تعريفات المخطط. في معايير إعادة الهيكلة، يقوم بتحسين الاستعلامات، مما يعزز الأداء بنسبة 20-30%. تتراوح الدقة حوالي 75-80% للتطبيقات الكاملة، مع اكتشاف الاختبار الذاتي للأخطاء مثل عدم وجود معالجة للأخطاء.
مثال واحد: طلب لوحة تحكم للتجارة الإلكترونية. يخرج Codex كود واجهة مستخدم متجاوب، ويدمج Stripe للمدفوعات، ويقترح فهارس لاستعلامات قاعدة بيانات أسرع. أشارت التعليقات عالية التأثير في وضع "المراجعة" الخاص به إلى تعديلات إمكانية الوصول. ما مدى دقة Codex في توليد الكود لهذا؟ بشكل مثير للإعجاب—معظم التشغيلات تجتاز اختبارات الوحدات، بما يتماشى مع درجات SWE-Bench.
بالطبع، توجد قيود. بالنسبة للمكتبات المتخصصة للغاية أو التقنيات المتطورة، تنخفض الدقة إلى 60%، مما يتطلب تدخلًا بشريًا. ولكن بشكل عام، إنه قوة هائلة.
الخلاصة: الحكم على Codex
لقد غطينا الكثير—من المعايير مثل SWE-Bench Verified (69-73%) إلى تقليل التعليقات غير الصحيحة (حتى 4.4%)، وزيادة التعليقات عالية التأثير (حتى 52.4%)، ومتوسط التعليقات لكل PR، وإعادة هيكلة الكود الصلبة (51.3%). من خلال الأمثلة في مراجعات كود PR، والألعاب، وتطبيقات الويب، يثبت Codex جدارته في سيناريوهات حقيقية.
إذن، ما مدى دقة Codex في توليد الكود؟ عالية جدًا—حوالي 70-90% لمعظم المهام، مع تحسينات تكرارية تدفعها إلى أعلى. إنه ليس معصومًا من الخطأ، ولكن لتعزيز الإنتاجية، إنه فائز. إذا كنت مستعدًا لتجربته، قم بتنزيل Apidog للبدء في توثيق واجهة برمجة التطبيقات وتصحيح الأخطاء—إنه الرفيق المثالي لمغامراتك مع Codex.