Trí tuệ nhân tạo tiếp tục phát triển nhanh chóng, và các nhà phát triển hiện nay yêu cầu các công cụ cung cấp khả năng lý luận nâng cao. NVIDIA đáp ứng nhu cầu này với gia đình các mô hình NVIDIA Llama Nemotron. Những mô hình này xuất sắc trong các nhiệm vụ yêu cầu lý luận phức tạp, cung cấp hiệu quả tính toán và đi kèm với giấy phép mở cho việc sử dụng doanh nghiệp. Các nhà phát triển có thể truy cập những mô hình này thông qua API NVIDIA Llama Nemotron, được cung cấp qua các dịch vụ vi mô NIM của NVIDIA, giúp việc tích hợp vào các ứng dụng trở nên liền mạch.
Hiểu về Các Mô Hình NVIDIA Llama Nemotron
Trước khi đi sâu vào API, hãy xem xét các mô hình NVIDIA Llama Nemotron. Gia đình này bao gồm ba biến thể: Nano, Super và Ultra. Mỗi mô hình nhắm vào nhu cầu triển khai cụ thể, cân bằng giữa hiệu suất và yêu cầu về tài nguyên.
- Nano (8B tham số): Các kỹ sư tối ưu hóa mô hình này cho các thiết bị biên và máy tính cá nhân. Nó cung cấp độ chính xác cao với công suất tính toán tối thiểu, khiến nó trở nên lý tưởng cho các ứng dụng nhẹ.
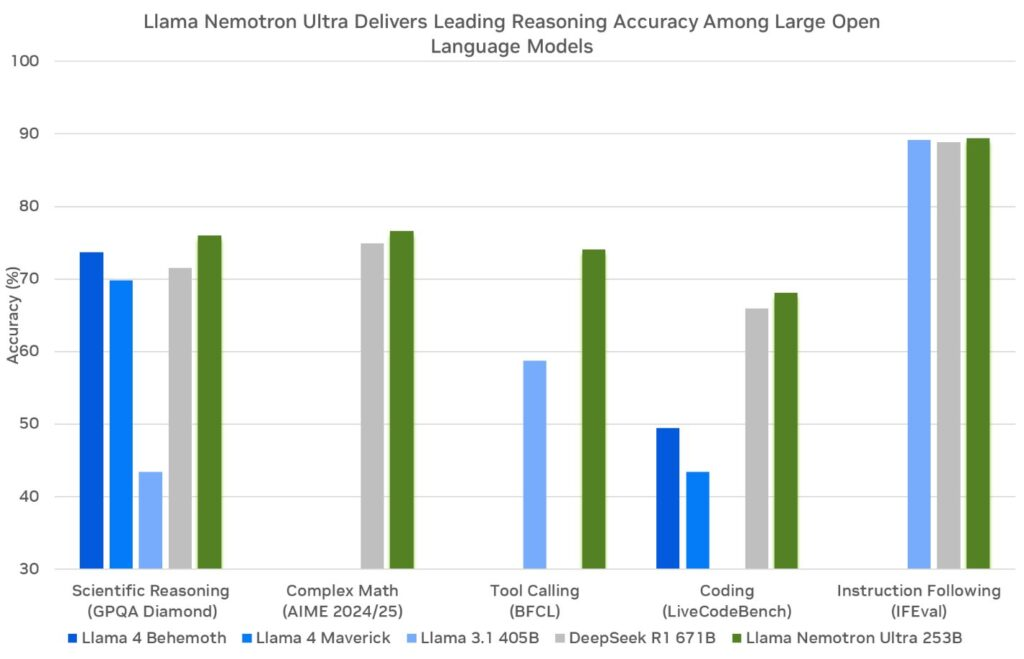
- Super (49B tham số): Các nhà phát triển thiết kế mô hình này cho các thiết lập một GPU. Nó đạt được sự cân bằng giữa thông lượng và độ chính xác, phù hợp cho các nhiệm vụ phức tạp vừa phải.
- Ultra (253B tham số): Các chuyên gia chế tạo mô hình này cho các máy chủ trung tâm dữ liệu đa GPU. Nó cung cấp độ chính xác hàng đầu cho các ứng dụng AI yêu cầu cao nhất.
NVIDIA xây dựng những mô hình này dựa trên khung Llama của Meta, nâng cao chúng với các kỹ thuật sau đào tạo như chưng cất và học tăng cường. Do đó, chúng xuất sắc trong các nhiệm vụ lý luận như phân tích khoa học, toán học nâng cao, lập trình và theo dõi hướng dẫn. Mỗi mô hình hỗ trợ độ dài ngữ cảnh lên tới 128.000 token, cho phép chúng xử lý tài liệu dài hoặc duy trì ngữ cảnh trong các tương tác kéo dài.
Một tính năng nổi bật là khả năng bật hoặc tắt lý luận qua lời nhắc hệ thống. Các nhà phát triển kích hoạt lý luận cho các truy vấn phức tạp, như xử lý sự cố, và tắt nó cho các nhiệm vụ đơn giản, như lấy thông tin tĩnh. Tính linh hoạt này tối ưu hóa việc sử dụng tài nguyên, một lợi thế quan trọng trong các ứng dụng thực tế.
Thiết Lập API NVIDIA Llama Nemotron
Để khai thác API NVIDIA Llama Nemotron, bạn phải thiết lập nó trước. NVIDIA cung cấp API này thông qua các dịch vụ vi mô NIM của nó, hỗ trợ việc triển khai trên đám mây, tại chỗ hoặc môi trường biên. Làm theo các bước sau để bắt đầu:
Tham gia Chương Trình Phát Triển của NVIDIA: Đăng ký để truy cập tài nguyên, tài liệu và công cụ. Bước này mở khóa hệ sinh thái bạn cần.
Nhận Thông Tin Xác Thực API: NVIDIA cung cấp các khóa API. Sử dụng chúng để xác thực yêu cầu của bạn một cách an toàn.
Cài Đặt Thư Viện Cần Thiết: Đối với các nhà phát triển Python, cài đặt thư viện requests để xử lý các cuộc gọi HTTP. Chạy lệnh này trong terminal của bạn:
pip install requests
Với những bước này hoàn tất, bạn chuẩn bị môi trường của mình để tương tác với API NVIDIA Llama Nemotron. Tiếp theo, chúng ta sẽ khám phá cách gửi yêu cầu.
Gửi Yêu Cầu API
API NVIDIA Llama Nemotron tuân theo các tiêu chuẩn RESTful, đơn giản hóa việc tích hợp vào các dự án của bạn. Bạn gửi các yêu cầu POST tới điểm cuối của API, nhúng các tham số trong thân yêu cầu. Hãy phân tích điều này với một ví dụ thực tiễn.
Dưới đây là cách bạn truy vấn API sử dụng Python:
import requests
import json
# Định nghĩa điểm cuối API và xác thực
endpoint = "https://your-nim-endpoint.com/api/v1/generate"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# Tạo tải trọng yêu cầu
payload = {
"model": "llama-nemotron-super",
"prompt": "Có bao nhiêu chữ R trong từ 'strawberry'?",
"max_tokens": 100,
"temperature": 0.7,
"reasoning": "on"
}
# Gửi yêu cầu
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# Xử lý phản hồi
if response.status_code == 200:
result = response.json()
print(result["text"])
else:
print(f"Lỗi: {response.status_code} - {response.text}")
Giải Thích Các Tham Số Chính
model: Xác định biến thể mô hình—Nano, Super hoặc Ultra. Chọn dựa trên việc triển khai của bạn.prompt: Cung cấp văn bản đầu vào cho mô hình để xử lý.max_tokens: Giới hạn độ dài phản hồi trong token. Điều chỉnh điều này để kiểm soát kích thước đầu ra.temperature: Có giá trị từ 0 đến 1. Các giá trị thấp (ví dụ: 0.5) tạo ra đầu ra có thể dự đoán, trong khi các giá trị cao hơn (ví dụ: 0.9) tăng cường tính sáng tạo.reasoning: Bật tắt khả năng lý luận. Đặt thành "on" cho các nhiệm vụ phức tạp, "off" cho các nhiệm vụ đơn giản.
Ví dụ, bật lý luận phù hợp với các nhiệm vụ như giải quyết các bài toán toán học, trong khi tắt nó lại hoạt động cho các tìm kiếm cơ bản. Bạn cũng có thể thêm các tham số như top_p để kiểm soát sự đa dạng hoặc stop_sequences để dừng tạo ra tại các token cụ thể, chẳng hạn như "\n\n".
Dưới đây là một ví dụ mở rộng:
payload = {
"model": "llama-nemotron-super",
"prompt": "Giải thích đệ quy trong lập trình.",
"max_tokens": 200,
"temperature": 0.6,
"top_p": 0.9,
"reasoning": "on",
"stop_sequences": ["\n\n"]
}
Yêu cầu này tạo ra một lời giải thích chi tiết về đệ quy, dừng lại ở một dòng mới gấp đôi. Các công cụ như Apidog giúp bạn kiểm tra và tinh chỉnh những yêu cầu này hiệu quả.
Xử Lý Phản Hồi API
Sau khi gửi yêu cầu, API NVIDIA Llama Nemotron trả về một phản hồi JSON. Điều này bao gồm văn bản đã tạo và siêu dữ liệu. Dưới đây là một phản hồi mẫu:
{
"text": "Có ba chữ R trong từ 'strawberry'.",
"tokens_generated": 10,
"time_taken": 0.5
}
text: Chứa đầu ra của mô hình.tokens_generated: Chỉ ra số lượng token đã được tạo ra.time_taken: Đo thời gian tạo trong giây.
Luôn kiểm tra mã trạng thái. Mã 200 báo hiệu thành công, cho phép bạn phân tích JSON. Các lỗi trả về các mã như 400 hoặc 500, với các chi tiết trong thân phản hồi để gỡ lỗi. Triển khai xử lý lỗi, chẳng hạn như thử lại hoặc dự phòng, để đảm bảo tính ổn định trong sản xuất.
Ví dụ, mở rộng mã trước đó:
if response.status_code == 200:
result = response.json()
print(f"Phản hồi: {result['text']}")
print(f"Số token đã sử dụng: {result['tokens_generated']}")
else:
print(f"Thất bại: {response.text}")
# Thêm logic thử lại nếu cần
Cách tiếp cận này giữ cho ứng dụng của bạn đáng tin cậy dưới các điều kiện khác nhau.
Các Thực Hành Tốt Nhất và Các Trường Hợp Sử Dụng
Để tối đa hóa tiềm năng của API NVIDIA Llama Nemotron, hãy áp dụng các thực hành tốt nhất sau:
- Tối ưu hóa việc sử dụng tài nguyên: Bật lý luận chỉ cho các nhiệm vụ phức tạp. Điều này giảm thiểu chi phí tính toán đáng kể.
- Giám sát hiệu suất: Theo dõi
time_takenđể đảm bảo phản hồi kịp thời, đặc biệt là cho các ứng dụng thời gian thực. - Tinh chỉnh các tham số: Thử nghiệm với
temperaturevàmax_tokensđể cân bằng giữa sự sáng tạo và độ chính xác. - Bảo mật thông tin xác thực: Lưu trữ các khóa API trong các biến môi trường hoặc kho an toàn, không bao giờ trong mã.
- Xử lý yêu cầu hàng loạt: Xử lý nhiều lời nhắc trong một lần gọi để nâng cao hiệu quả.
Các Trường Hợp Sử Dụng Thực Tế
Tính linh hoạt của API hỗ trợ nhiều ứng dụng khác nhau:
- Hỗ trợ khách hàng: Phát triển chatbot giải quyết các truy vấn phức tạp với lý luận, như xử lý sự cố phần cứng.
- Giáo dục: Xây dựng gia sư giải thích các khái niệm, chẳng hạn như giải tích, với logic từng bước.
- Nghiên cứu: Hỗ trợ các nhà khoa học phân tích dữ liệu hoặc phác thảo giả thuyết.
- Phát triển phần mềm: Tạo mã hoặc gỡ lỗi kịch bản dựa trên đầu vào ngôn ngữ tự nhiên.
Đối với một ví dụ lập trình:
payload = {
"model": "llama-nemotron-super",
"prompt": "Viết một hàm Python để tính giai thừa.",
"max_tokens": 200,
"temperature": 0.5,
"reasoning": "on"
}
Mô hình có thể trả về:
def factorial(n):
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)
Điều này chứng tỏ khả năng lý luận qua logic đệ quy của nó. Apidog có thể hỗ trợ trong việc kiểm tra các cuộc gọi API như vậy, đảm bảo độ chính xác.
Kết Luận
API NVIDIA Llama Nemotron trao quyền cho các nhà phát triển tạo ra các tác nhân AI tiên tiến với khả năng lý luận mạnh mẽ. Tính năng lý luận có thể bật tắt nâng cao hiệu suất, trong khi tính linh hoạt của nó giữa các mô hình Nano, Super và Ultra phù hợp với nhiều nhu cầu khác nhau. Dù bạn xây dựng chatbot, công cụ giáo dục hay trợ lý lập trình, API này mang lại tính linh hoạt và sức mạnh.
Hơn nữa, việc tích hợp với các công cụ như Apidog nâng cao quy trình làm việc của bạn. Kiểm tra các điểm cuối, xác thực phản hồi và lặp lại nhanh chóng để tập trung vào đổi mới. Khi AI phát triển, việc thành thạo API NVIDIA Llama Nemotron sẽ đưa bạn vào vị trí hàng đầu trong lĩnh vực chuyển đổi này.