
Các nhà phát triển tìm kiếm những cách hiệu quả để tích hợp các mô hình ngôn ngữ tiên tiến vào ứng dụng của họ. INTELLECT-3 nổi lên như một lựa chọn hấp dẫn nhờ nền tảng mã nguồn mở và hiệu suất mạnh mẽ trong các tác vụ suy luận. Mô hình này, được phát triển bởi Prime Intellect, nổi bật với kiến trúc Mixture-of-Experts (MoE) 106 tỷ tham số, cho phép hiệu quả cao trong việc xử lý các phép tính phức tạp.
Tìm hiểu về INTELLECT-3: Cỗ máy mã nguồn mở mạnh mẽ
Prime Intellect phát hành INTELLECT-3 dưới dạng một mô hình hoàn toàn mã nguồn mở, cho phép các nhà nghiên cứu và nhà phát triển tùy chỉnh và mở rộng khả năng của nó mà không gặp phải rào cản độc quyền. Sự minh bạch này thúc đẩy đổi mới trong các lĩnh vực như học tăng cường (RL) và hệ thống AI dựa trên tác nhân (agentic AI). Bạn có thể truy cập toàn bộ gói, bao gồm trọng số mô hình, framework huấn luyện, tập dữ liệu, môi trường RL và công cụ đánh giá, trực tiếp từ các kho lưu trữ của Prime Intellect.

Về cốt lõi, INTELLECT-3 sử dụng kiến trúc MoE 106 tỷ tham số, được xây dựng trên mô hình cơ sở GLM-4.5-Air. Thiết kế MoE định tuyến đầu vào đến các mạng con "chuyên gia" chuyên biệt, giúp tối ưu hóa việc sử dụng tính toán và tăng tốc suy luận. Chẳng hạn, trong quá trình xử lý, mô hình chỉ kích hoạt một tập hợp con các tham số liên quan đến truy vấn, giảm độ trễ trong khi vẫn duy trì độ chính xác. Cấu hình này đặc biệt hiệu quả cho các tác vụ đòi hỏi chuyên môn chọn lọc, như các phép chứng minh toán học hoặc tạo mã.
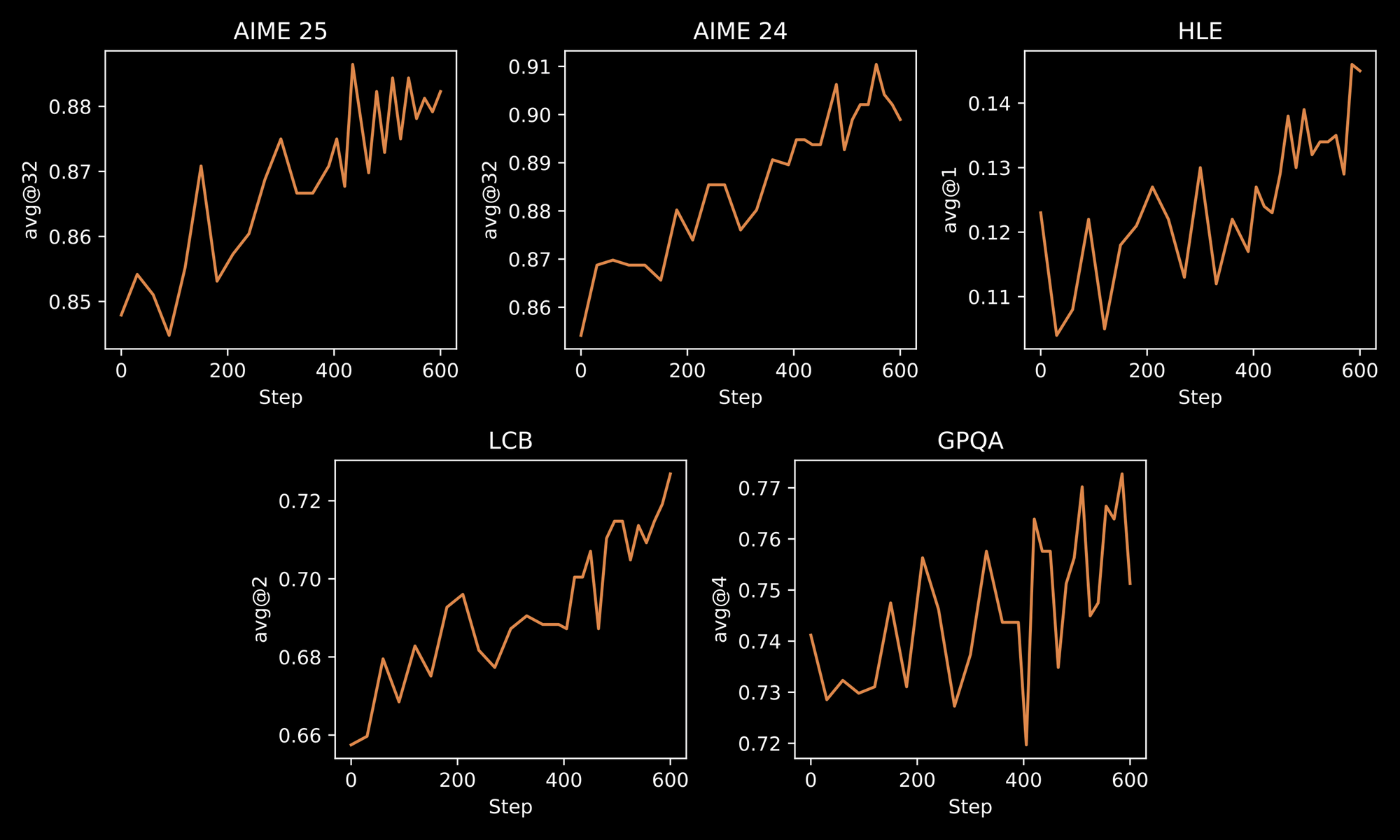
Quá trình huấn luyện nhấn mạnh sự mạnh mẽ của INTELLECT-3. Các kỹ sư áp dụng phương pháp hai giai đoạn: tinh chỉnh có giám sát ban đầu (SFT) trên các tập dữ liệu được tuyển chọn, sau đó là RL quy mô lớn sử dụng framework prime-rl tùy chỉnh. prime-rl hoạt động như một hệ thống RL off-policy bất đồng bộ, xử lý hiệu quả các mô phỏng song song quy mô lớn. Bạn hưởng lợi từ điều này thông qua việc cải thiện hành vi của mô hình trong môi trường động, như giải quyết vấn đề lặp đi lặp lại hoặc lập kế hoạch đa bước.
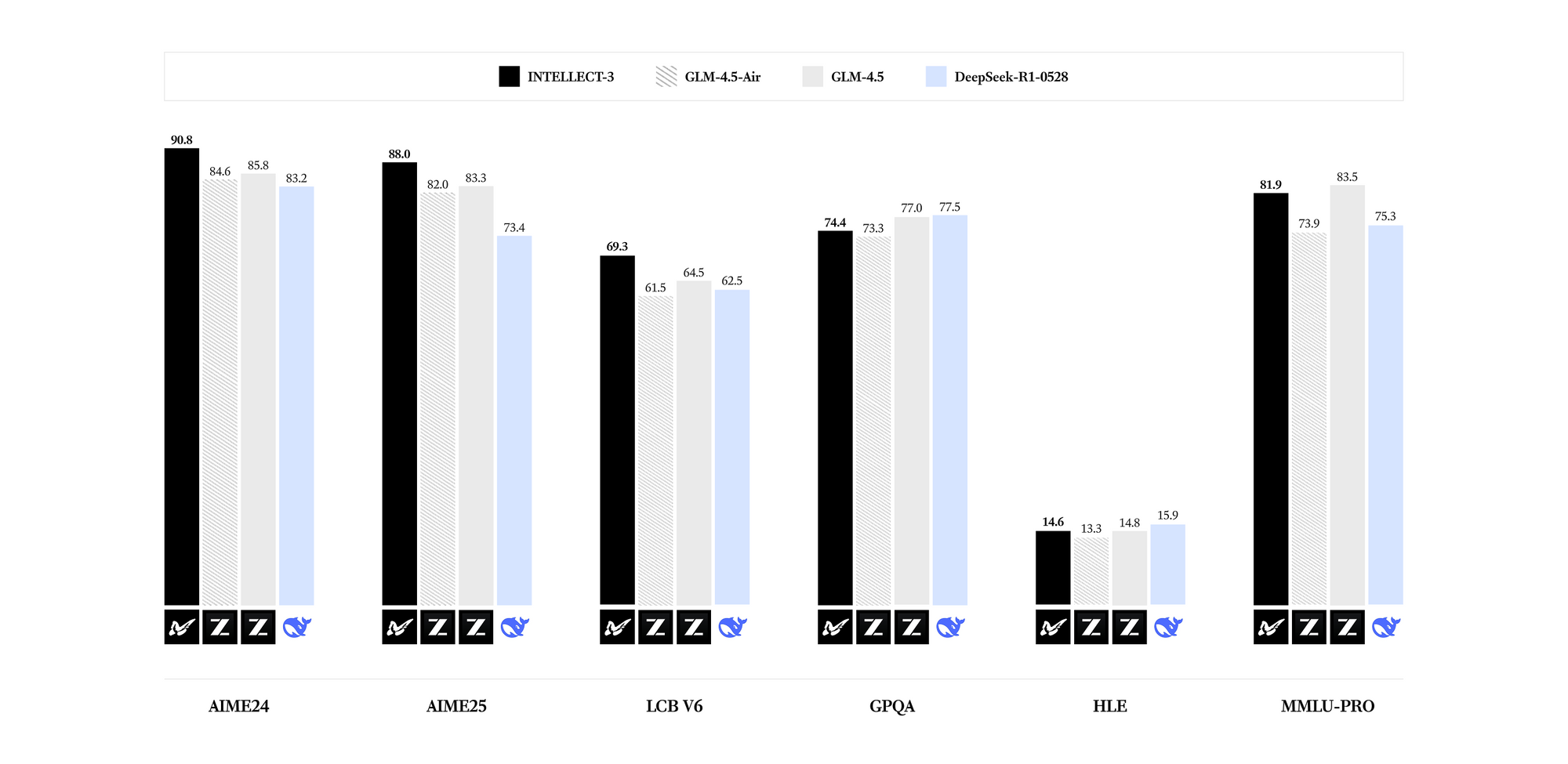
INTELLECT-3 vượt trội trong các lĩnh vực chuyên biệt. Các điểm chuẩn cho thấy kết quả hàng đầu cho số lượng tham số của nó trong toán học (ví dụ: điểm GSM8K vượt quá 95%), mã hóa (tỷ lệ đạt HumanEval trên 85%), khoa học (độ chính xác GPQA trên 60%) và suy luận (điểm MMLU gần 80%). So với các mô hình dày đặc hơn như Llama 3.1 70B, INTELLECT-3 đạt được hiệu quả vượt trội—suy luận nhanh hơn tới 2 lần trên phần cứng tương đương—nhờ các mẫu kích hoạt thưa thớt của nó. Do đó, bạn có thể triển khai nó trong các môi trường hạn chế tài nguyên mà không làm giảm chất lượng đầu ra.
Cơ sở hạ tầng hỗ trợ tăng cường sức hấp dẫn mã nguồn mở của nó. Trung tâm Verifiers & Environments cung cấp hơn 500 môi trường RL, từ các câu đố đơn giản đến các công cụ chứng minh định lý tiên tiến.
Prime Sandboxes cung cấp khả năng thực thi mã an toàn, thông lượng cao, cô lập các hành động của tác nhân trong quá trình huấn luyện hoặc suy luận. Các nhà phát triển tận dụng những công cụ này để tinh chỉnh INTELLECT-3 cho các ứng dụng tùy chỉnh, chẳng hạn như các tác nhân tự trị trong quy trình phát triển phần mềm.
Trong thực tế, bạn tải xuống trọng số mô hình qua Hugging Face hoặc GitHub của Prime Intellect. Cài đặt yêu cầu các phụ thuộc tiêu chuẩn như PyTorch và thư viện Transformers. Một đoạn mã cơ bản để tải mô hình trông như sau:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
Đoạn mã này khởi tạo mô hình trên phần cứng có GPU. Tuy nhiên, đối với việc sử dụng ở quy mô sản xuất, bạn chuyển sang các API được lưu trữ, vì tự lưu trữ đòi hỏi tài nguyên tính toán đáng kể (ví dụ: nhiều GPU A100). Do đó, quyền truy cập mã nguồn mở đặt nền tảng, nhưng tích hợp API sẽ mở rộng quy mô triển khai của bạn một cách hiệu quả.
Chuyển từ thử nghiệm cục bộ, giờ đây bạn sẽ khám phá cách truy cập INTELLECT-3 thông qua các dịch vụ được quản lý. Sự thay đổi này đảm bảo độ tin cậy và xử lý các phức tạp của suy luận phân tán.
Truy cập API INTELLECT-3: Thiết lập và Xác thực
Tùy chọn 1 – Điểm cuối gốc của Prime Intellect (Khuyến nghị cho hiệu suất tối đa & độ trễ thấp nhất)
Bạn bắt đầu truy cập API bằng cách lấy thông tin đăng nhập từ nền tảng của Prime Intellect. Truy cập bảng điều khiển Prime Intellect tại app.primeintellect.ai và tạo tài khoản nếu cần.
Sau khi đăng nhập, điều hướng đến phần khóa API và tạo một khóa mới với quyền suy luận được bật. Khóa này sẽ xác thực tất cả các yêu cầu tiếp theo, đảm bảo quyền truy cập an toàn vào INTELLECT-3.
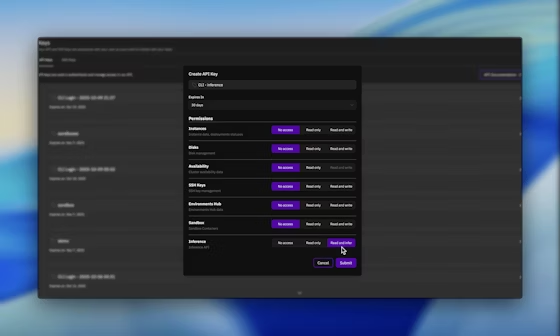
Tiếp theo, cấu hình môi trường của bạn. Đặt khóa API làm biến môi trường để tích hợp liền mạch:
export PRIME_API_KEY="your-api-key-here"
Đối với quy trình làm việc dựa trên nhóm, hãy bao gồm tiêu đề X-Prime-Team-ID trong các yêu cầu. Mã định danh này định tuyến việc sử dụng đến nhóm thanh toán chính xác, ngăn chặn các khoản phí chéo tài khoản. Bạn lấy ID nhóm từ bảng điều khiển trong cài đặt tài khoản.
API áp dụng giao diện tương thích với OpenAI, giúp đơn giản hóa việc triển khai nếu bạn đã sử dụng các thư viện như openai-python. Chỉ định URL cơ sở là https://api.pinference.ai/api/v1. Điểm cuối này chuyển tiếp các yêu cầu đến các nhà cung cấp suy luận được tối ưu hóa, bao gồm Parasail và Nebius, những nơi lưu trữ các phiên bản INTELLECT-3. Kết quả là, bạn đạt được các phản hồi có độ trễ thấp mà không cần quản lý các cụm cơ bản.
Để xác minh quyền truy cập, hãy truy vấn điểm cuối `models`. Điều này liệt kê các mô hình có sẵn, xác nhận sự hiện diện của INTELLECT-3 (thường dưới dạng một định danh như `prime-intellect/intellect-3`). Sử dụng công cụ CLI để kiểm tra nhanh:
prime inference models
Ngoài ra, gửi yêu cầu GET qua curl:
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
Phản hồi trả về một mảng JSON các đối tượng mô hình, mỗi đối tượng chi tiết các tham số như `id`, `max_tokens` và `context_window`. INTELLECT-3 hỗ trợ ngữ cảnh 128K token, đáp ứng các chuỗi suy luận dài.
Xác thực cũng bao gồm giới hạn tỷ lệ (rate limiting) và hạn mức (quotas). Prime Intellect áp dụng giới hạn mỗi phút và hàng ngày dựa trên gói của bạn, có thể xem trong bảng điều khiển. Bạn theo dõi việc sử dụng thông qua tab Thanh toán, nơi ghi lại số token đã xử lý và các cuộc gọi API đã thực hiện. Nếu giới hạn ảnh hưởng đến quy trình làm việc của bạn, hãy nâng cấp gói một cách liền mạch thông qua nền tảng.
Hơn nữa, hãy tích hợp với Apidog để kiểm thử nâng cao. Nhập schema OpenAI vào Apidog, sau đó mô phỏng các yêu cầu đến các điểm cuối của INTELLECT-3. Việc thực hành này giúp xác định sớm các vấn đề, chẳng hạn như tải trọng JSON bị định dạng sai. Gói miễn phí của Apidog đủ cho các thiết lập ban đầu, kết nối phát triển cục bộ với các API sản xuất.
Với xác thực đã được thiết lập, bạn tiếp tục xây dựng các yêu cầu. Phần tiếp theo phác thảo các định dạng chính xác để nhận được phản hồi tối ưu từ INTELLECT-3.
Tùy chọn 2 – OpenRouter (Truy cập tức thì & tín dụng thống nhất)
Ngoài việc tự lưu trữ hoặc sử dụng nền tảng suy luận gốc của Prime Intellect, INTELLECT-3 cũng có sẵn chính thức trên OpenRouter. Điều này mang lại cho bạn một cổng thay thế với thanh toán thống nhất, định tuyến dự phòng tự động và truy cập tức thì—không yêu cầu tài khoản Prime Intellect riêng nếu bạn đã sử dụng OpenRouter.
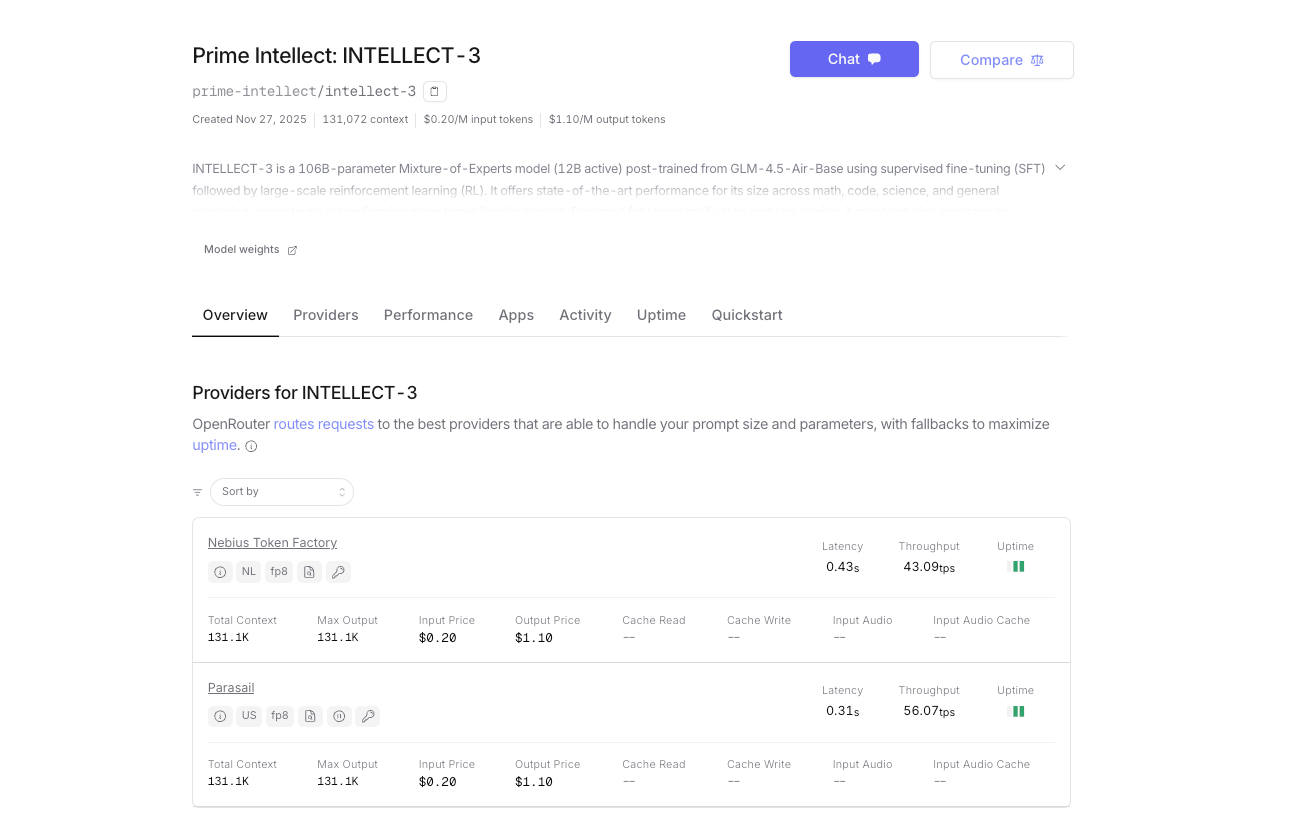
- URL cơ sở: https://openrouter.ai/api/v1
- Tên mô hình: prime-intellect/intellect-3
- Xác thực: Khóa API OpenRouter của bạn (OPENROUTER_API_KEY)
- Định tuyến nhà cung cấp tự động (hiện đang được phục vụ bởi các cụm của Prime Intellect)
- Thanh toán theo mức sử dụng với tín dụng OpenRouter; chi phí mỗi token cao hơn một chút do phí nền tảng
Cả hai điểm cuối đều hỗ trợ các schema yêu cầu/phản hồi, streaming, gọi công cụ và chế độ JSON giống hệt nhau.
Thực hiện các yêu cầu đến API INTELLECT-3: Định dạng và Ví dụ
Bạn khởi tạo tương tác thông qua điểm cuối /chat/completions, nơi xử lý các lời nhắc đàm thoại và theo tác vụ. Xây dựng các yêu cầu dưới dạng đối tượng JSON với các trường cho model, messages, temperature và max_tokens. Mảng messages mô phỏng lịch sử trò chuyện, sử dụng các vai trò như "system", "user" và "assistant".
Hãy xem xét một ví dụ cơ bản về tạo mã. Bạn gửi:
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
Đoạn mã này xuất ra một triển khai Fibonacci đệ quy với ghi nhớ, tận dụng khả năng lập trình của INTELLECT-3. Tham số temperature kiểm soát khả năng sáng tạo—các giá trị thấp hơn (ví dụ: 0.2) ưu tiên các đầu ra xác định cho các truy vấn thực tế, trong khi các giá trị cao hơn (lên đến 1.0) khuyến khích các đường dẫn suy luận đa dạng.
Đối với suy luận toán học, bạn cấu trúc các lời nhắc để xâu chuỗi các suy nghĩ. Khóa huấn luyện RL của INTELLECT-3 tỏa sáng ở đây, vì nó mô phỏng xác minh từng bước. Ví dụ:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
Mô hình phản hồi bằng một chứng minh chặt chẽ, trích dẫn các tiên đề và định lý. Bạn phân tích cú pháp đầu ra thông qua response.choices[0].message.content, được trả về dưới dạng chuỗi. Đối với dữ liệu có cấu trúc, hãy bật chế độ JSON bằng cách thêm "response_format": {"type": "json_object"} vào yêu cầu, đảm bảo các phản hồi có thể phân tích cú pháp.
Sử dụng nâng cao bao gồm gọi công cụ, nơi INTELLECT-3 tích hợp các hàm bên ngoài. Định nghĩa công cụ trong yêu cầu:
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
Nếu mô hình gọi công cụ, nó sẽ trả về các đối số trong response.choices[0].message.tool_calls. Bạn thực thi hàm bên ngoài và đưa kết quả trở lại trong một tin nhắn tiếp theo. Mẫu này xây dựng các quy trình làm việc dựa trên tác nhân, tận dụng các hành vi được huấn luyện trong môi trường của INTELLECT-3.
Xử lý lỗi là một phần quan trọng. Các vấn đề thường gặp bao gồm 401 (khóa không hợp lệ), 429 (giới hạn tỷ lệ) và 400 (yêu cầu không đúng định dạng). Thực hiện thử lại với exponential backoff:
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
Các phản hồi bao gồm siêu dữ liệu như usage (prompt_tokens, completion_tokens, total_tokens), mà bạn ghi lại để tối ưu hóa. INTELLECT-3 xử lý tối đa 4096 token cho mỗi lần hoàn thành, cân bằng độ sâu và tốc độ.
Phản hồi streaming nâng cao các ứng dụng thời gian thực. Thêm stream=True vào lệnh gọi tạo; client sẽ trả về các đoạn dưới dạng Server-Sent Events. Phân tích cú pháp chúng lặp đi lặp lại:
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Kỹ thuật này phù hợp với chatbot hoặc trợ lý mã hóa trực tiếp, nơi người dùng mong đợi phản hồi tăng dần.
Khi đã thành thạo việc tạo yêu cầu, bạn đánh giá hiệu suất. Phần tiếp theo giới thiệu các công cụ chấm điểm được thiết kế riêng cho INTELLECT-3.
Tối ưu hóa và Đánh giá việc sử dụng API INTELLECT-3
Bạn tối ưu hóa các cuộc gọi API bằng cách điều chỉnh các tham số theo kinh nghiệm. Bắt đầu với việc gộp nhiều tin nhắn vào một yêu cầu để tăng thông lượng—hiệu quả lên đến 10 lần trong các bộ đánh giá. CLI của Prime Intellect hỗ trợ điều này:
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
Lệnh này chạy 100 mẫu GSM8K, tổng hợp các chỉ số về độ chính xác và độ trễ. Bạn phân tích kết quả để điều chỉnh top_p hoặc frequency_penalty, giúp giảm sự lặp lại trong các thế hệ dài.
Đánh giá mở rộng sang các môi trường tùy chỉnh từ Verifiers Hub. Tải một môi trường RL và truy vấn INTELLECT-3 như một chính sách:
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
Phần thưởng định lượng những cải tiến, hướng dẫn việc tinh chỉnh nếu bạn lưu trữ cục bộ. Đối với người dùng chỉ API, hãy ghi lại các tương tác vào cơ sở dữ liệu vector và tính toán các chỉ số tiếp theo như tỷ lệ thành công của tác vụ.
Các cân nhắc về bảo mật cũng quan trọng. Làm sạch đầu vào của người dùng để ngăn chặn tấn công prompt injection, và sử dụng các lời nhắc hệ thống để thực thi ranh giới. Nền tảng RL của INTELLECT-3 giảm thiểu các hallucination, nhưng bạn vẫn cần xác thực đầu ra với các bộ xác minh cho các ứng dụng có tính rủi ro cao.
Mở rộng quy mô liên quan đến việc giám sát thông qua bảng điều khiển. Đặt cảnh báo cho các ngưỡng token và tích hợp với các công cụ quan sát như Prometheus, mà Prime Intellect cung cấp cho các cụm. Do đó, bạn duy trì độ tin cậy khi việc sử dụng tăng lên.
Bây giờ bạn đã xử lý tối ưu hóa, hãy xem xét chi phí. Minh bạch về giá cả đảm bảo tích hợp bền vững.
Giá API INTELLECT-3: Mô hình dựa trên token minh bạch
Prime Intellect cấu trúc giá dựa trên mức tiêu thụ token, tính phí riêng cho đầu vào và đầu ra. Bạn trả tiền cho mỗi 1.000 token, với mức giá khác nhau tùy theo mô hình và nhà cung cấp. Đối với INTELLECT-3, hãy mong đợi các con số cạnh tranh—khoảng 0,50 đô la cho mỗi triệu token đầu vào và 1,50 đô la cho mỗi triệu token đầu ra—mặc dù các giá trị chính xác xuất hiện trong phản hồi điểm cuối của mô hình.
| Nhà cung cấp | Đầu vào ($$ /1M token) | Đầu ra ($$ /1M token) | Ghi chú |
|---|---|---|---|
| Prime Intellect Trực tiếp | ~0,45–0,60 đô la | ~1,30–1,80 đô la | Chi phí thấp nhất, chiết khấu theo số lượng |
| OpenRouter | ~0,60–0,80 đô la | ~1,80–2,40 đô la | Bao gồm phí nền tảng OpenRouter |
Tỷ giá chính xác dao động; luôn kiểm tra các giá trị mới nhất trong bảng điều khiển của bạn hoặc qua điểm cuối của mô hình.
Bạn nên chọn cái nào?
- Chọn Prime Intellect trực tiếp nếu bạn muốn tốc độ tối đa, chi phí thấp nhất hoặc có kế hoạch sử dụng khối lượng lớn.
- Chọn OpenRouter nếu bạn ưu tiên một khóa API duy nhất cho hơn 50 mô hình, cần tích hợp ngay lập tức hoặc muốn định tuyến dự phòng tích hợp sẵn.
Cả hai tùy chọn đều mang lại hiệu suất INTELLECT-3 như nhau. Hãy chọn tùy chọn phù hợp với quy trình làm việc của bạn—nhiều nhóm thậm chí còn sử dụng cả hai đồng thời để dự phòng.
Phần còn lại của hướng dẫn này (định dạng yêu cầu, streaming, gọi công cụ, tối ưu hóa, v.v.) áp dụng như nhau cho dù bạn gọi Prime Intellect trực tiếp hay qua OpenRouter.
Tiếp tục với các chi tiết triển khai kỹ thuật đầy đủ bên dưới và bắt đầu xây dựng với INTELLECT-3 ngay hôm nay—thông qua cổng nào phù hợp nhất với bạn.
Tích hợp nâng cao với API INTELLECT-3
Bạn mở rộng INTELLECT-3 vào các hệ sinh thái như LangChain hoặc LlamaIndex để điều phối. Trong LangChain:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
Điều này liên kết API với các pipeline tạo được tăng cường truy xuất (RAG), nâng cao độ chính xác bằng kiến thức bên ngoài.
Đối với các microservice, triển khai qua các trình bao bọc FastAPI đóng vai trò proxy cho INTELLECT-3:
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
Công khai điểm cuối này một cách an toàn, giới hạn tỷ lệ bằng Redis. Các thiết lập như vậy cung cấp năng lượng cho các công cụ SaaS, từ trình tạo nội dung đến trợ lý nghiên cứu.
Các trường hợp đặc biệt cần được chú ý. Xử lý tràn token bằng cách cắt bớt đầu vào động, và quay lại các mô hình nhỏ hơn nếu INTELLECT-3 bị xếp hàng đợi. Các diễn đàn cộng đồng trên trang web của Prime Intellect cung cấp các chủ đề khắc phục sự cố.
Kết luận: Triển khai API INTELLECT-3 với sự tự tin
Giờ đây bạn đã có một bộ công cụ toàn diện để sử dụng API INTELLECT-3. Từ nguồn gốc mã nguồn mở đến việc xử lý yêu cầu chính xác và quản lý chi phí, hướng dẫn này trang bị cho bạn các triển khai thực tế. Thử nghiệm với Apidog để tinh chỉnh quy trình làm việc của bạn và theo dõi các tài liệu đang phát triển để cập nhật.
Thực hiện các kỹ thuật này một cách tăng dần—bắt đầu với các cuộc trò chuyện đơn giản, sau đó mở rộng sang các tác nhân. Hiệu quả và tính mở của INTELLECT-3 định vị nó là lựa chọn hàng đầu cho các dự án AI kỹ thuật. Bắt đầu viết mã ngay hôm nay và chứng kiến tác động lên các ứng dụng của bạn.