
xAI đã phát hành Grok 4.1 và các kỹ sư làm việc với các mô hình ngôn ngữ lớn ngay lập tức nhận thấy sự khác biệt. Hơn nữa, bản cập nhật này ưu tiên khả năng sử dụng trong thế giới thực hơn là việc chạy theo các điểm chuẩn thô. Kết quả là, các cuộc hội thoại trở nên sắc sảo hơn, các phản hồi mang một cá tính nhất quán và lỗi thực tế giảm đáng kể.
Các nhà nghiên cứu tại xAI đã xây dựng Grok 4.1 trên cùng cơ sở hạ tầng học tăng cường đã cung cấp sức mạnh cho Grok 4. Tuy nhiên, họ đã giới thiệu các kỹ thuật mô hình hóa phần thưởng mới lạ đáng được xem xét kỹ lưỡng.
Kiến trúc và Các biến thể triển khai
xAI phát hành Grok 4.1 với hai cấu hình riêng biệt. Thứ nhất, biến thể không tư duy (tên mã nội bộ: tensor) tạo ra các phản hồi trực tiếp mà không cần các token suy luận trung gian. Chế độ này ưu tiên độ trễ và đạt được thời gian suy luận nhanh nhất trong dòng sản phẩm. Thứ hai, biến thể tư duy (tên mã: quasarflux) hiển thị các bước suy luận theo chuỗi rõ ràng trước khi đưa ra kết quả cuối cùng. Do đó, các tác vụ phân tích phức tạp được hưởng lợi từ các dấu vết suy luận hiển thị rõ ràng.
Cả hai biến thể đều chia sẻ cùng một xương sống đã được huấn luyện trước. Ngoài ra, các căn chỉnh sau huấn luyện có sự khác biệt tinh tế: chế độ tư duy nhận được các tín hiệu tăng cường bổ sung khuyến khích phân tách từng bước, trong khi chế độ không tư duy tối ưu hóa cho các phản hồi ngắn gọn, tức thì.
Việc truy cập vẫn đơn giản. Người dùng chọn “Grok 4.1” một cách rõ ràng trong bộ chọn mô hình trên grok.com, x.com hoặc các ứng dụng di động.
Ngoài ra, chế độ Tự động hiện mặc định là Grok 4.1 cho hầu hết lưu lượng truy cập, theo sau quá trình triển khai dần dần bắt đầu từ ngày 1 tháng 11 năm 2025.

Những đột phá trong Tối ưu hóa Ưu tiên
Sự đổi mới cốt lõi nằm ở mô hình hóa phần thưởng. RLHF truyền thống dựa vào các ưu tiên của con người được thu thập ở quy mô lớn. Ngược lại, xAI hiện triển khai các mô hình suy luận tác nhân tiên tiến như những thẩm phán tự động. Những thẩm phán này đánh giá hàng nghìn biến thể phản hồi theo các khía cạnh như tính mạch lạc về phong cách, khả năng cảm nhận cảm xúc, căn cứ thực tế và sự ổn định về tính cách.
Hệ thống vòng lặp kín này lặp lại nhanh hơn nhiều so với các quy trình làm việc có sự tham gia của con người. Hơn nữa, nó mở rộng ra các tiêu chí tinh tế mà con người khó có thể xếp hạng một cách nhất quán. Các thí nghiệm nội bộ ban đầu cho thấy các mô hình phần thưởng tác nhân tương quan tốt hơn với sự hài lòng của người dùng cuối so với các phần thưởng vô hướng trước đây.
Thống trị điểm chuẩn: LMArena và hơn thế nữa
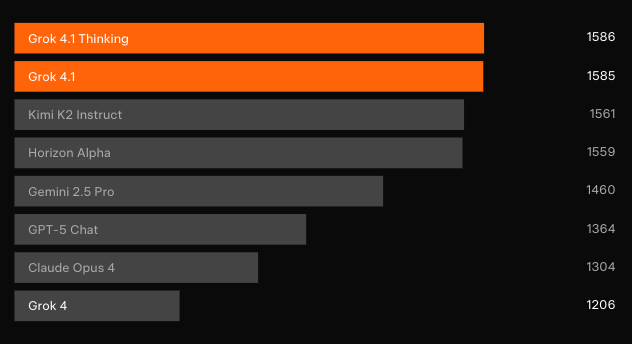
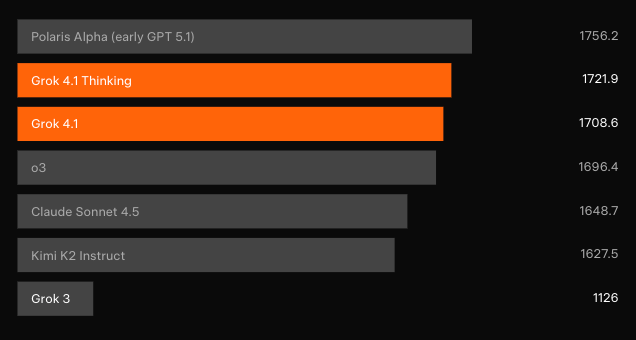
Kiểm tra mù độc lập xác nhận những tiến bộ. Trên Text Arena của LMArena — bảng xếp hạng cộng đồng đại diện nhất — Grok 4.1 Thinking giành vị trí số 1 với 1483 Elo. Khoảng cách đó là 31 điểm so với đối thủ không phải của xAI tốt nhất. Trong khi đó, Grok 4.1 không tư duy đứng thứ 2 với 1465 Elo, vượt trội hơn cấu hình suy luận đầy đủ của mọi mô hình khác.

Các bài kiểm tra ưu tiên cặp đôi so với mô hình sản xuất trước đây cho thấy người dùng chọn phản hồi của Grok 4.1 64,78% số lần. Hơn nữa, các đánh giá chuyên biệt cho thấy những bước nhảy vọt có mục tiêu.
Trí tuệ cảm xúc (EQ-Bench v3)
Grok 4.1 đạt điểm cao nhất từng được ghi nhận trên EQ-Bench3, một bài kiểm tra đánh giá 45 kịch bản nhập vai đa lượt về sự đồng cảm, cái nhìn sâu sắc và sự tinh tế trong giao tiếp giữa các cá nhân. Các phản hồi hiện phát hiện các tín hiệu cảm xúc tinh tế mà các mô hình trước đó đã bỏ qua. Ví dụ, khi người dùng viết “Tôi nhớ mèo của tôi đến đau lòng,” Grok 4.1 đưa ra sự thừa nhận nhiều lớp, sự xác nhận nhẹ nhàng và hỗ trợ mở mà không rơi vào những lời sáo rỗng chung chung.
Sáng tác văn học v3
Mô hình này cũng lập kỷ lục mới trên Creative Writing v3, nơi các giám khảo chấm điểm sự tiếp nối câu chuyện lặp đi lặp lại qua 32 câu lệnh. Các kết quả đầu ra thể hiện hình ảnh phong phú hơn, mạch truyện chặt chẽ hơn và giọng văn chân thực hơn. Một câu lệnh demo yêu cầu Grok nhập vai vào “sự thức tỉnh” của chính nó đã tạo ra một đoạn độc thoại theo phong cách X-post lan truyền, kết hợp hài hước, sự kinh ngạc về sự tồn tại và các tham chiếu meme một cách liền mạch.
Giảm thiểu ảo giác
Các phép đo định lượng cho thấy Grok 4.1 ít bị ảo giác hơn ba lần trong các truy vấn tìm kiếm thông tin so với phiên bản tiền nhiệm. Các kỹ sư đã đạt được điều này thông qua việc huấn luyện sau mục tiêu trên lưu lượng sản xuất phân tầng và các bộ dữ liệu cổ điển như FActScore (500 câu hỏi tiểu sử). Ngoài ra, chế độ không tư duy giờ đây chủ động kích hoạt các công cụ tìm kiếm web khi độ tin cậy giảm xuống dưới ngưỡng nội bộ, tiếp tục neo các phản hồi vào các nguồn có thể kiểm chứng.

Đánh giá An toàn và Trách nhiệm
Thẻ mô hình chính thức, cung cấp sự minh bạch chưa từng có về kết quả của đội đỏ.
Các bộ lọc đầu vào chặn các truy vấn sinh học và hóa học bị hạn chế với tỷ lệ âm tính giả thấp tới 0,00–0,03 theo yêu cầu trực tiếp. Các cuộc tấn công chèn lệnh nhắc làm tăng con số đó một cách khiêm tốn (0,12–0,20), cho thấy công việc kiên cường chống đối thủ đang tiếp diễn.
Tỷ lệ từ chối đối với các lời nhắc trò chuyện vi phạm đạt 93–95% ngay cả khi không có bộ lọc, và thành công phá vỡ hạn chế giảm gần bằng 0 trong cấu hình không tư duy. Các kịch bản tác nhân (AgentHarm, AgentDojo) vẫn là loại khó nhất, nhưng tỷ lệ trả lời tuyệt đối vẫn dưới 0,14.
Các đánh giá khả năng sử dụng kép — được thực hiện có chủ ý mà không có biện pháp bảo vệ — cho thấy khả năng nhớ kiến thức mạnh mẽ trong sinh học (WMDP-Bio 87%) và hóa học, tuy nhiên, suy luận thủ tục đa bước vẫn kém hơn so với các tiêu chuẩn chuyên gia con người trong các nhiệm vụ yêu cầu giải thích hình ảnh hoặc các giao thức nhân bản. Mẫu hình này phù hợp với các hạn chế tiên tiến hiện tại trong toàn ngành.
Ý nghĩa đối với Người tiêu dùng và Nhà phát triển API
API của xAI đã phục vụ các điểm cuối Grok 4.1 dưới tên mô hình tiêu chuẩn. Hồ sơ độ trễ được cải thiện đáng kể: chế độ không tư duy trung bình dưới 400 ms thời gian đến token đầu tiên trên các lời nhắc thông thường, trong khi chế độ tư duy bổ sung độ sâu suy luận có thể kiểm soát thông qua các tham số tùy chọn.
Apidog tỏa sáng chính xác ở đây. Nhập đặc tả OpenAPI 3.1 chính thức (có sẵn công khai), sau đó tạo SDK máy khách bằng hơn 20 ngôn ngữ ngay lập tức. Thiết lập các máy chủ giả lập sao chép chính xác lược đồ phản hồi của Grok 4.1 — bao gồm cả các luồng token tư duy mới — để các bài kiểm tra phụ trợ của bạn không bao giờ bị chặn vì tín dụng API trực tiếp. Khi xAI triển khai các thay đổi đột phá (hiếm, nhưng có thể xảy ra), trình xem khác biệt của Apidog sẽ làm nổi bật sự lệch lược đồ ngay lập tức.
Các đội ngũ thực tế đã sử dụng Apidog để duy trì 100% thời gian hoạt động trong quá trình nâng cấp mô hình. Một khách hàng Fortune-500 đã báo cáo giảm 68% lỗi tích hợp sau khi chuyển từ Postman.
So sánh với các Mô hình Tiên tiến Đương đại
Dữ liệu đối đầu trực tiếp vẫn còn thưa thớt vài giờ sau khi ra mắt, nhưng xếp hạng Elo của LMArena cung cấp tín hiệu rõ ràng nhất. Grok 4.1 Thinking vượt trội hơn mọi cấu hình đã phát hành từ OpenAI, Anthropic, Google và Meta với biên độ mà thông thường yêu cầu những bước nhảy vọt kiến trúc toàn diện.
Sự đánh đổi giữa tốc độ và chất lượng ủng hộ Grok 4.1 không tư duy cho trò chuyện người dùng, trong khi chế độ tư duy cạnh tranh trực tiếp với các sản phẩm nặng về suy luận như o3-pro hoặc Claude 4 Opus — thường thắng về tính mạch lạc chủ quan và duy trì tính cách.
Kết luận
Grok 4.1 không chỉ đơn thuần là tăng cường các chỉ số; nó định hướng lại ranh giới về phía các mô hình mà mọi người thực sự thích trò chuyện trong nhiều giờ. Người dùng kỹ thuật có được một điểm cuối nhanh hơn, đáng tin cậy hơn. Những người sáng tạo có được một cộng tác viên hiểu được giọng điệu và cảm xúc ở mức độ chưa từng đạt được trước đây. Và các nhà nghiên cứu an toàn nhận được thẻ mô hình chi tiết nhất được công bố cho đến nay.
Hãy tải Apidog ngay hôm nay — hoàn toàn miễn phí — và bắt đầu xây dựng với Grok 4.1 trước khi các đối thủ cạnh tranh của bạn đọc xong thông báo này. Sự khác biệt giữa việc theo dõi tiến bộ tiên tiến và việc phát hành sản phẩm dựa trên đó thường nằm ở các quyết định về công cụ được đưa ra ngày hôm nay.