
Gia đình Qwen 3 thống trị hệ sinh thái LLM mã nguồn mở vào năm 2026. Các kỹ sư triển khai các mô hình này ở khắp mọi nơi—từ các tác nhân doanh nghiệp quan trọng đến trợ lý di động. Trước khi bạn bắt đầu gửi yêu cầu đến Alibaba Cloud hoặc tự lưu trữ, hãy tối ưu hóa quy trình làm việc của bạn với Apidog.
Tổng quan về Qwen 3: Những đổi mới kiến trúc thúc đẩy hiệu suất năm 2026
Nhóm Qwen của Alibaba đã phát hành dòng Qwen 3 vào ngày 29 tháng 4 năm 2026, đánh dấu một bước tiến quan trọng trong các mô hình ngôn ngữ lớn (LLM) mã nguồn mở. Các nhà phát triển ca ngợi giấy phép Apache 2.0 của nó, cho phép tinh chỉnh không giới hạn và triển khai thương mại. Về cốt lõi, Qwen 3 sử dụng kiến trúc dựa trên Transformer với các cải tiến về nhúng vị trí và cơ chế chú ý, hỗ trợ độ dài ngữ cảnh lên đến 128K token nguyên bản—và có thể mở rộng lên 131K thông qua YaRN.

Hơn nữa, dòng sản phẩm này còn tích hợp các thiết kế Mixture-of-Experts (MoE) trong các biến thể chọn lọc, chỉ kích hoạt một phần nhỏ các tham số trong quá trình suy luận. Cách tiếp cận này giúp giảm chi phí tính toán đồng thời duy trì độ chính xác cao trong các đầu ra. Ví dụ, các kỹ sư báo cáo tốc độ xử lý nhanh hơn tới 10 lần trên các tác vụ ngữ cảnh dài so với các phiên bản tiền nhiệm dày đặc như Qwen2.5-72B. Kết quả là, các biến thể Qwen 3 có thể mở rộng hiệu quả trên nhiều phần cứng, từ thiết bị biên đến các cụm đám mây.
Qwen 3 cũng vượt trội trong hỗ trợ đa ngôn ngữ, xử lý hơn 119 ngôn ngữ với khả năng tuân thủ hướng dẫn tinh tế. Các điểm chuẩn xác nhận lợi thế của nó trong các lĩnh vực STEM, nơi nó xử lý dữ liệu toán học và mã hóa tổng hợp được tinh chỉnh từ 36 nghìn tỷ token. Do đó, các ứng dụng trong các doanh nghiệp toàn cầu được hưởng lợi từ việc giảm lỗi dịch thuật và cải thiện khả năng suy luận đa ngôn ngữ. Chuyển sang chi tiết cụ thể, chế độ suy luận lai—được bật tắt thông qua cờ tokenizer—cho phép các mô hình thực hiện logic từng bước cho toán học hoặc mã hóa, hoặc mặc định là không suy nghĩ cho hội thoại. Tính hai mặt này trao quyền cho các nhà phát triển để tối ưu hóa cho từng trường hợp sử dụng.
Các tính năng chính hợp nhất các biến thể Qwen 3
Tất cả các mô hình Qwen 3 đều chia sẻ các đặc điểm nền tảng giúp nâng cao tiện ích của chúng vào năm 2026. Thứ nhất, chúng hỗ trợ hoạt động chế độ kép: chế độ tư duy kích hoạt các quy trình chuỗi suy nghĩ cho các điểm chuẩn như AIME25, trong khi chế độ không tư duy ưu tiên tốc độ cho các ứng dụng trò chuyện. Các kỹ sư bật tắt chế độ này bằng các tham số đơn giản, đạt độ chính xác lên đến 92,3% trên các bài toán phức tạp mà không ảnh hưởng đến độ trễ.
Thứ hai, các tính năng tác nhân cho phép gọi công cụ liền mạch, vượt trội so với các đối thủ mã nguồn mở trong các tác vụ như điều hướng trình duyệt hoặc thực thi mã. Ví dụ, các biến thể Qwen 3 đạt 69,6 điểm trên Tau2-Bench Verified, cạnh tranh với các mô hình độc quyền. Ngoài ra, khả năng đa ngôn ngữ bao gồm các phương ngữ từ tiếng Quan thoại đến tiếng Swahili, với 73,0 điểm trên các điểm chuẩn MultiIF.
Thứ ba, hiệu quả đến từ các biến thể lượng tử hóa (ví dụ: Q4_K_M) và các framework như vLLM hoặc SGLang, cung cấp 25 token/giây trên GPU tiêu dùng. Tuy nhiên, các mô hình lớn hơn yêu cầu VRAM 16GB+, thúc đẩy việc triển khai trên đám mây. Giá vẫn cạnh tranh, với token đầu vào ở mức $0,20–$1,20 cho mỗi triệu thông qua Alibaba Cloud.
Hơn nữa, Qwen 3 nhấn mạnh an toàn thông qua kiểm duyệt tích hợp, giảm ảo giác 15% so với Qwen2.5. Các nhà phát triển tận dụng điều này cho các ứng dụng cấp độ sản xuất, từ bộ đề xuất thương mại điện tử đến các công cụ phân tích pháp lý. Khi chúng ta chuyển sang các biến thể riêng lẻ, những điểm mạnh chung này cung cấp một nền tảng nhất quán để so sánh.
Top 5 biến thể mô hình Qwen 3 tốt nhất năm 2026
Dựa trên các điểm chuẩn năm 2026 từ LMSYS Arena, LiveCodeBench và SWE-Bench, chúng tôi xếp hạng năm biến thể Qwen 3 hàng đầu. Tiêu chí lựa chọn bao gồm điểm suy luận, tốc độ suy luận, hiệu quả tham số và khả năng truy cập API. Mỗi biến thể đều xuất sắc trong các kịch bản riêng biệt, nhưng tất cả đều thúc đẩy các ranh giới mã nguồn mở.
1. Qwen3-235B-A22B – Quái vật MoE hàng đầu tuyệt đối
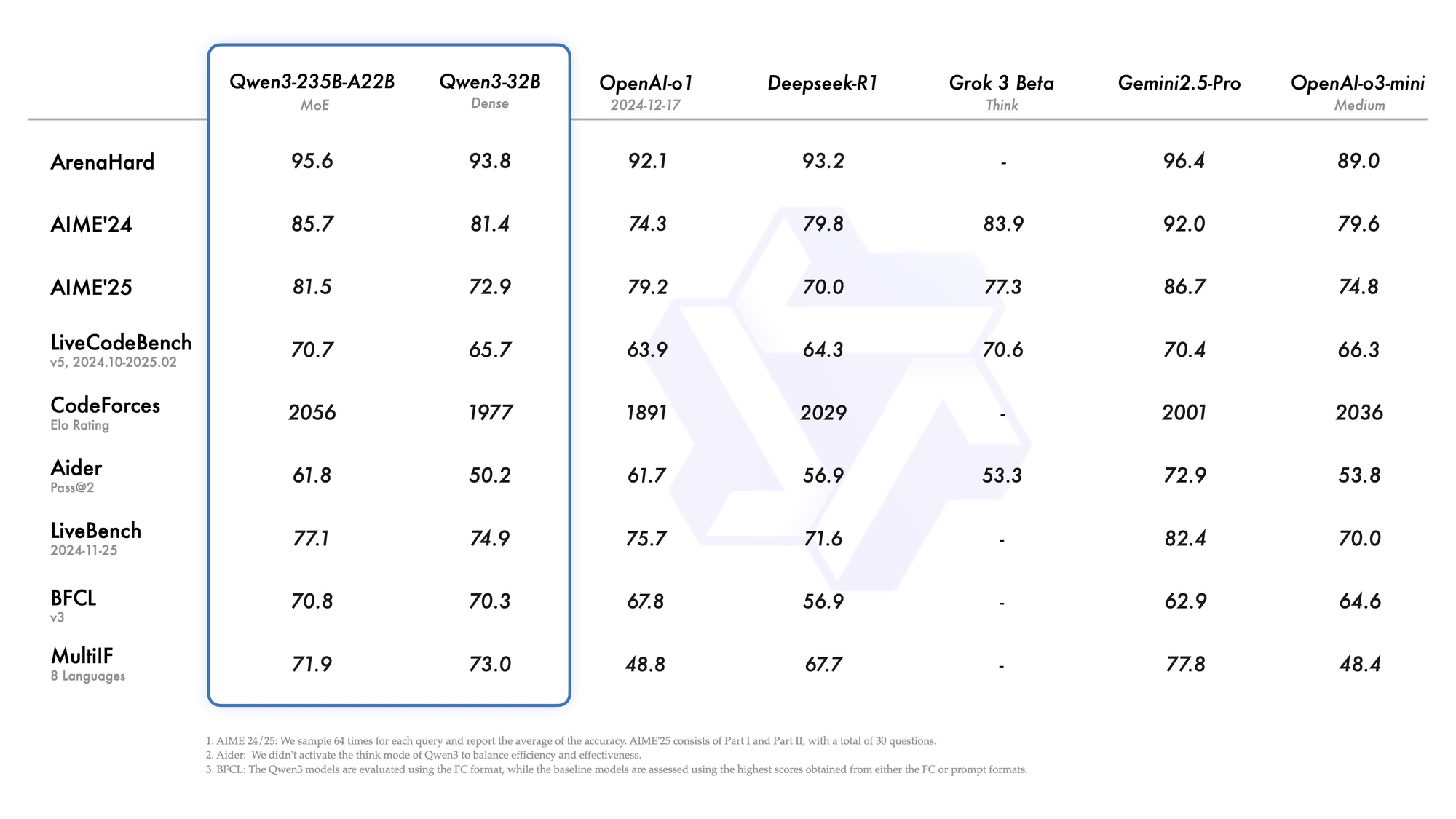
Qwen3-235B-A22B thu hút sự chú ý với tư cách là biến thể MoE hàng đầu, với tổng cộng 235 tỷ tham số và 22 tỷ tham số hoạt động trên mỗi token. Ra mắt vào tháng 7 năm 2026 dưới tên Qwen3-235B-A22B-Instruct-2507, nó kích hoạt tám chuyên gia thông qua định tuyến top-k, cắt giảm 90% chi phí tính toán so với các phiên bản dày đặc tương đương. Các điểm chuẩn xếp hạng nó ngang ngửa với Gemini 2.5 Pro: 95,6 trên ArenaHard, 77,1 trên LiveBench và dẫn đầu trong CodeForces Elo (dẫn trước 5%).
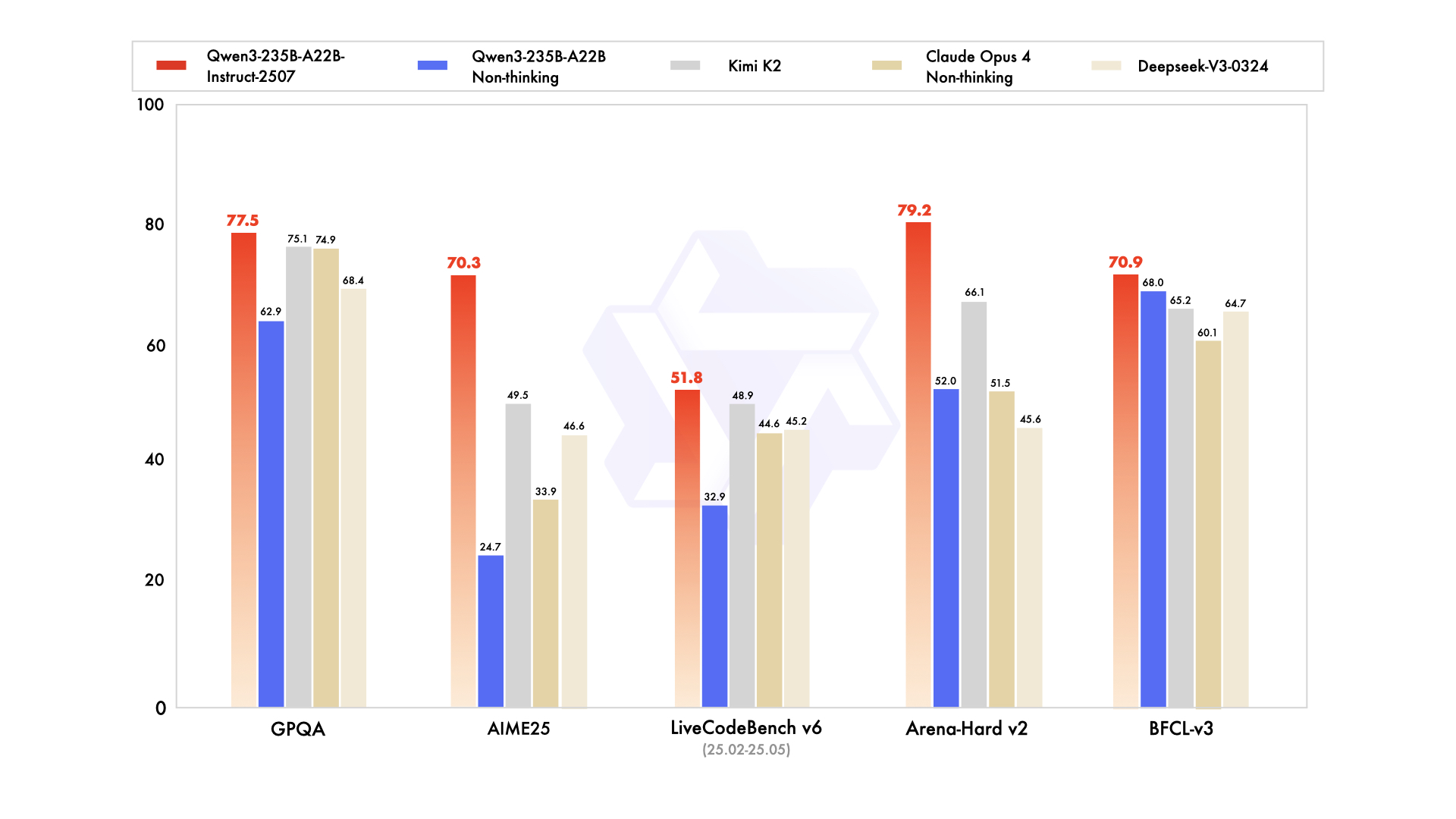
Trong mã hóa, nó đạt 74,8 trên LiveCodeBench v6, tạo ra TypeScript chức năng với số lần lặp tối thiểu. Đối với toán học, chế độ tư duy đạt 92,3 trên AIME25, giải các tích phân đa bước thông qua suy luận rõ ràng. Các tác vụ đa ngôn ngữ đạt 73,0 trên MultiIF, xử lý các truy vấn tiếng Ả Rập một cách hoàn hảo.
Triển khai ưu tiên các API đám mây, nơi nó xử lý 256K ngữ cảnh. Tuy nhiên, chạy cục bộ yêu cầu 8x GPU H100. Các kỹ sư tích hợp nó cho các quy trình làm việc tác nhân, như gỡ lỗi cấp độ kho lưu trữ. Nhìn chung, biến thể này đặt ra tiêu chuẩn năm 2026 về chiều sâu, mặc dù quy mô của nó phù hợp với các nhóm có ngân sách lớn.
Điểm mạnh
- Khớp hoặc vượt trội Gemini 2.5 Pro và Claude 3.7 Sonnet trên hầu hết các bảng xếp hạng năm 2026 (95,6 ArenaHard, 92,3 AIME25 chế độ tư duy, 74,8 LiveCodeBench v6).
- Vượt trội trong các quy trình làm việc tác nhân đa lượt, gọi công cụ phức tạp và hiểu mã cấp độ kho lưu trữ.
- Xử lý ngữ cảnh 256K–1M với YaRN mà không giảm chất lượng.
- Chế độ tư duy cung cấp khả năng suy luận chuỗi suy nghĩ có thể kiểm chứng, cạnh tranh với các mô hình tiên tiến mã nguồn đóng.
Điểm yếu
- Cực kỳ đắt đỏ và chậm khi chạy cục bộ—yêu cầu 8×H100 hoặc tương đương để có độ trễ hợp lý.
- Giá API cao nhất trong dòng ($1,20–$6,00/M token đầu ra ở ngữ cảnh cao nhất).
- Quá mức cần thiết cho 95% khối lượng công việc sản xuất; hầu hết các nhóm không bao giờ sử dụng hết công suất của nó.
Khi nào nên sử dụng
- Các tác nhân tự động cấp doanh nghiệp phải giải toán cấp tiến sĩ, gỡ lỗi toàn bộ cơ sở mã hoặc thực hiện phân tích hợp đồng pháp lý với độ ảo giác gần bằng không.
- Các phòng thí nghiệm nghiên cứu có ngân sách lớn đang đẩy mạnh công nghệ tiên tiến trên các điểm chuẩn mới.
- Các backend suy luận nội bộ nơi chi phí mỗi token ít quan trọng hơn so với trí thông minh tối đa.
2. Qwen3-30B-A3B – Nhà vô địch MoE điểm ngọt
Qwen3-30B-A3B nổi lên như một lựa chọn hàng đầu cho các thiết lập bị hạn chế tài nguyên, với tổng cộng 30,5 tỷ tham số và 3,3 tỷ tham số hoạt động. Cấu trúc MoE của nó—48 lớp, 128 chuyên gia (tám được định tuyến)—phản ánh mô hình hàng đầu nhưng chỉ chiếm 10% dấu chân. Được cập nhật vào tháng 7 năm 2026, nó vượt trội hơn QwQ-32B gấp 10 lần về hiệu quả hoạt động, đạt 91,0 trên ArenaHard và 69,6 trên SWE-Bench Verified.
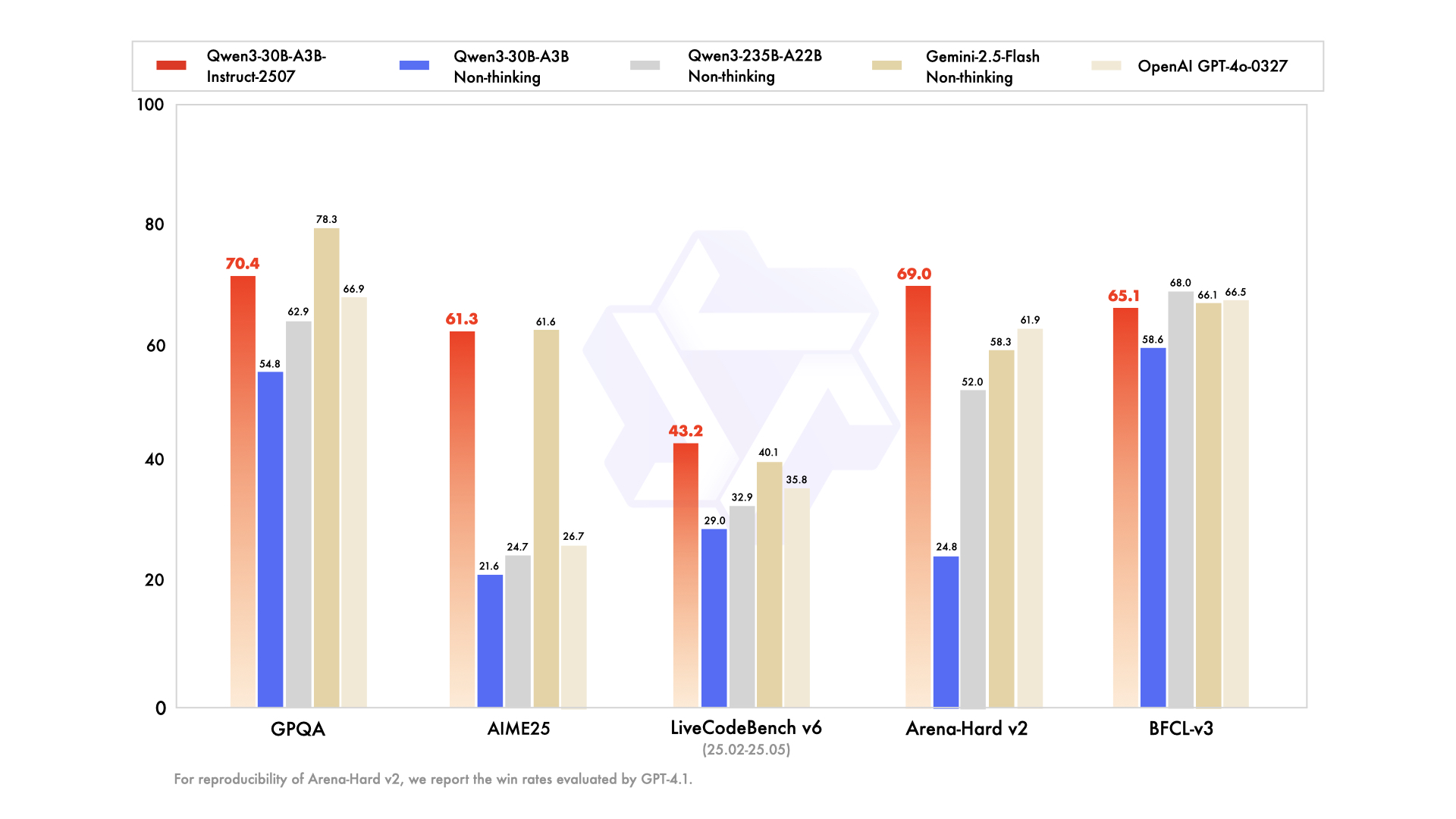
Các đánh giá mã hóa làm nổi bật khả năng của nó: 32,4% pass@5 trên các PR GitHub mới, ngang bằng với GPT-5-High. Các điểm chuẩn toán học cho thấy 81,6 trên AIME25 ở chế độ tư duy, cạnh tranh với các phiên bản lớn hơn. Với ngữ cảnh 131K thông qua YaRN, nó xử lý các tài liệu dài mà không bị cắt bớt.
Điểm mạnh
- Tham số hoạt động rẻ hơn 10 lần so với phiên bản 235B trong khi vẫn giữ được ~90–95% chất lượng suy luận hàng đầu (91,0 ArenaHard, 81,6 AIME25).
- Chạy thoải mái trên một A100 80GB duy nhất hoặc hai card 40GB với vLLM + FlashAttention.
- Tỷ lệ giá/hiệu suất tốt nhất trong số tất cả các mô hình MoE mã nguồn mở năm 2026.
- Vượt trội hơn mọi mô hình dày đặc 72B–110B về mã hóa và toán học.
Điểm yếu
- Vẫn cần ~24–30GB VRAM ở FP8/INT4; không thân thiện với máy tính xách tay.
- Khả năng viết sáng tạo hơi thấp hơn so với các mô hình dày đặc thuần túy có kích thước tương tự.
- Độ trễ ở chế độ tư duy tăng 2–3 lần so với chế độ không tư duy.
Khi nào nên sử dụng
- Các tác nhân mã hóa sản xuất, đánh giá PR tự động hoặc các copilots DevOps nội bộ.
- Các quy trình nghiên cứu thông lượng cao cần khả năng suy luận toán học hoặc khoa học tiên tiến với ngân sách hợp lý.
- Bất kỳ nhóm nào trước đây đã sử dụng Llama-405B hoặc Mixtral-123B nhưng muốn suy luận tốt hơn với chi phí thấp hơn.
3. Qwen3-32B – Ông vua toàn diện dày đặc
Qwen3-32B dày đặc cung cấp 32 tỷ tham số hoạt động đầy đủ, nhấn mạnh thông lượng thô hơn là độ thưa thớt. Được đào tạo trên 36 nghìn tỷ token, nó sánh ngang với Qwen2.5-72B về hiệu suất cơ bản nhưng vượt trội trong căn chỉnh sau đào tạo. Các điểm chuẩn cho thấy 89,5 trên ArenaHard và 73,0 trên MultiIF, với khả năng viết sáng tạo mạnh mẽ (ví dụ: các câu chuyện nhập vai đạt 85% sở thích của con người).
Trong mã hóa, nó dẫn đầu BFCL ở 68,2, tạo ra giao diện người dùng kéo và thả từ lời nhắc. Toán học đạt 70,3 trên AIME25, mặc dù nó kém hơn các đối thủ MoE về chuỗi suy nghĩ. Ngữ cảnh 128K của nó phù hợp với cơ sở kiến thức và chế độ không tư duy tăng tốc độ hội thoại lên 20 token/giây.
Điểm mạnh
- Khả năng tuân thủ hướng dẫn và đầu ra sáng tạo đặc biệt—thường được ưu tiên hơn các mô hình MoE lớn hơn trong các đánh giá mù của con người về viết lách và nhập vai.
- Dễ dàng tinh chỉnh với LoRA/QLoRA trên phần cứng tiêu dùng (VRAM 16–24GB).
- Tốc độ suy luận nhanh nhất trong số các mô hình vẫn đánh bại GPT-4o trên nhiều tác vụ (89,5 ArenaHard).
- Hiệu suất đa ngôn ngữ rất mạnh mẽ trên hơn 119 ngôn ngữ.
Điểm yếu
- Kém hơn khoảng 8–12 điểm so với các phiên bản MoE trong các điểm chuẩn toán học và mã hóa khó nhất khi chế độ tư duy được bật.
- Không có thủ thuật hiệu quả tham số—mỗi token tốn toàn bộ 32B tính toán.
Khi nào nên sử dụng
- Các nền tảng tạo nội dung, trợ lý viết tiểu thuyết, công cụ viết quảng cáo tiếp thị.
- Các dự án yêu cầu tinh chỉnh nặng (chatbot chuyên biệt theo miền, chuyển đổi phong cách).
- Các nhóm muốn chất lượng gần như hàng đầu nhưng phải duy trì dưới 24GB VRAM.
4. Qwen3-14B – Cường quốc biên & di động
Qwen3-14B ưu tiên tính di động với 14,8 tỷ tham số, hỗ trợ 128K ngữ cảnh trên phần cứng tầm trung. Nó cạnh tranh với Qwen2.5-32B về hiệu quả, đạt 85,5 trên ArenaHard và sánh ngang với Qwen3-30B-A3B trong toán học/mã hóa (trong khoảng 5% chênh lệch). Được lượng tử hóa thành Q4_0, nó chạy ở tốc độ 24,5 token/giây trên điện thoại di động như RedMagic 8S Pro.
Các tác vụ tác nhân đạt 65,1 trên Tau2-Bench, cho phép sử dụng công cụ trong các ứng dụng có độ trễ thấp. Hỗ trợ đa ngôn ngữ nổi bật, với độ chính xác 70% trong suy luận phương ngữ. Đối với các thiết bị biên, nó xử lý 32K ngữ cảnh ngoại tuyến, lý tưởng cho phân tích IoT.
Các kỹ sư đánh giá cao dấu chân của nó cho học liên kết, nơi quyền riêng tư quan trọng hơn quy mô. Do đó, nó phù hợp với trợ lý AI di động hoặc hệ thống nhúng.
Điểm mạnh
- Chạy ở tốc độ 24–30 token/giây ngay cả trên điện thoại hiện đại (Snapdragon 8 Gen 4, Dimensity 9400) khi được lượng tử hóa thành Q4_K_M.
- Vẫn đánh bại Qwen2.5-32B và Llama-3.1-70B trên hầu hết các điểm chuẩn suy luận.
- Tuyệt vời cho RAG trên thiết bị với ngữ cảnh 32K–128K.
- Chi phí API thấp nhất trong phân khúc hiệu suất hàng đầu.
Điểm yếu
- Bắt đầu gặp khó khăn với các tác vụ tác nhân đa bước yêu cầu >5 lệnh gọi công cụ.
- Chất lượng viết sáng tạo thấp hơn đáng kể so với các mô hình 32B+.
- Ít khả năng chống chịu tương lai hơn khi các điểm chuẩn tiếp tục tăng.
Khi nào nên sử dụng
- Trợ lý trên thiết bị (ứng dụng Android/iOS, thiết bị đeo).
- Triển khai nhạy cảm về quyền riêng tư (y tế, tài chính) nơi dữ liệu không thể rời khỏi thiết bị.
- Hệ thống nhúng thời gian thực (robot, ô tô, cổng IoT).
5. Qwen3-8B – Công cụ nhẹ và tối ưu cho tạo mẫu
Hoàn thiện top 5, Qwen3-8B cung cấp 8 tỷ tham số cho việc lặp nhanh, vượt trội hơn Qwen2.5-14B trên 15 điểm chuẩn. Nó đạt 81,5 trên AIME25 (không tư duy) và 60,2 trên LiveCodeBench, đủ cho các đánh giá mã cơ bản. Với ngữ cảnh gốc 32K, nó được triển khai trên máy tính xách tay thông qua Ollama, đạt 25 token/giây.
Biến thể này phù hợp cho người mới bắt đầu thử nghiệm trò chuyện đa ngôn ngữ hoặc các tác nhân đơn giản. Chế độ tư duy của nó tăng cường các câu đố logic, đạt 75% trên các tác vụ suy luận. Kết quả là, nó đẩy nhanh việc chứng minh khái niệm trước khi mở rộng quy mô sang các phiên bản lớn hơn.
Điểm mạnh
- Chạy ở tốc độ >25 token/giây ngay cả trên máy tính xách tay với VRAM 8–12GB (MacBook M3 Pro, RTX 4070 mobile).
- Khả năng tuân thủ hướng dẫn đáng ngạc nhiên—đánh bại Gemma-2-27B và Phi-4-14B trên hầu hết các bảng xếp hạng năm 2026.
- Hoàn hảo cho thử nghiệm cục bộ với Ollama hoặc LM Studio.
- Giá API rẻ nhất trong dòng.
Điểm yếu
- Giới hạn suy luận rõ ràng đối với các bài toán toán học cấp sau đại học và các vấn đề mã hóa nâng cao.
- Dễ bị ảo giác hơn trong các tác vụ đòi hỏi nhiều kiến thức.
- Ngữ cảnh hạn chế (32K gốc, 128K với YaRN nhưng chậm hơn).
Khi nào nên sử dụng
- Tạo mẫu nhanh và xây dựng MVP (Sản phẩm khả thi tối thiểu).
- Công cụ giáo dục, trợ lý cá nhân hoặc các dự án sở thích.
- Lớp định tuyến frontend trong các hệ thống lai (sử dụng 8B để phân loại, nâng cấp lên 30B/235B khi cần).
Giá API và các cân nhắc triển khai cho các mô hình Qwen 3
Truy cập Qwen 3 qua API dân chủ hóa AI tiên tiến, với Alibaba Cloud dẫn đầu với mức giá cạnh tranh. Các tầng giá theo token: đối với Qwen3-235B-A22B, đầu vào có giá $0,20–$1,20/triệu (phạm vi 0–252K), đầu ra $1,00–$6,00/triệu. Qwen3-30B-A3B phản ánh điều này ở mức 80% tỷ lệ, trong khi các mô hình dày đặc như Qwen3-32B giảm xuống $0,15 đầu vào/$0,75 đầu ra.
Các nhà cung cấp bên thứ ba như Together AI cung cấp Qwen3-32B với giá $0,80/1M tổng số token, với chiết khấu theo khối lượng. Lượt truy cập bộ nhớ đệm giúp giảm hóa đơn: ngụ ý 20%, rõ ràng 10%. So với GPT-5 ($3–15/1M), Qwen 3 cắt giảm 70%, cho phép mở rộng quy mô hiệu quả về chi phí.
Mẹo triển khai: Sử dụng vLLM để xử lý theo lô, SGLang để tương thích OpenAI. Apidog tăng cường điều này bằng cách mô phỏng các điểm cuối Qwen, kiểm tra tải trọng và tạo tài liệu—điều cần thiết cho các quy trình CI/CD. Chạy cục bộ thông qua Ollama phù hợp cho tạo mẫu, nhưng API vượt trội cho sản xuất.
Các tính năng bảo mật như giới hạn tốc độ và kiểm duyệt tăng thêm giá trị, không có phí bổ sung. Do đó, các nhóm có ngân sách hạn chế lựa chọn dựa trên khối lượng token: các biến thể nhỏ cho phát triển, các biến thể hàng đầu cho suy luận.
Bảng quyết định – Chọn mô hình Qwen 3 của bạn vào năm 2026
| Hạng | Mô hình | Tham số (Tổng/Hoạt động) | Tóm tắt điểm mạnh | Điểm yếu chính | Tốt nhất cho | Chi phí API ước tính (Đầu vào/Đầu ra mỗi 1M token) | VRAM tối thiểu (lượng tử hóa) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235B / 22B MoE | Suy luận tối đa, tác nhân, toán học, mã hóa | Cực kỳ đắt đỏ & nặng | Nghiên cứu tiên tiến, tác nhân doanh nghiệp, độ chính xác không khoan nhượng | $0.20–$1.20 / $1.00–$6.00 | 64GB+ (đám mây) |
| 2 | Qwen3-30B-A3B | 30.5B / 3.3B MoE | Tỷ lệ giá/hiệu suất tốt nhất, suy luận mạnh mẽ | Vẫn cần GPU máy chủ | Các tác nhân mã hóa sản xuất, backend toán học/khoa học, suy luận khối lượng lớn | $0.16–$0.96 / $0.80–$4.80 | 24–30GB |
| 3 | Qwen3-32B | 32B Dense | Viết sáng tạo, dễ tinh chỉnh, tốc độ | Kém hơn MoE trong các tác vụ khó nhất | Nền tảng nội dung, tinh chỉnh miền, chatbot đa ngôn ngữ | $0.15 / $0.75 | 16–20GB |
| 4 | Qwen3-14B | 14.8B Dense | Có khả năng biên/di động, RAG tuyệt vời trên thiết bị | Khả năng tác nhân đa bước hạn chế | AI trên thiết bị, ứng dụng quan trọng về quyền riêng tư, hệ thống nhúng | $0.12 / $0.60 | 8–12GB |
| 5 | Qwen3-8B | 8B Dense | Tốc độ trên máy tính xách tay/điện thoại, rẻ nhất | Giới hạn rõ ràng đối với các tác vụ phức tạp | Tạo mẫu, trợ lý cá nhân, lớp định tuyến trong hệ thống lai | $0.10 / $0.50 | 4–8GB |
Khuyến nghị cuối cùng cho năm 2026
Hầu hết các nhóm vào năm 2026 nên mặc định sử dụng Qwen3-30B-A3B—nó mang lại hơn 90% sức mạnh của phiên bản hàng đầu với chi phí và yêu cầu phần cứng chỉ bằng một phần nhỏ. Chỉ nâng cấp lên 235B-A22B nếu bạn thực sự cần 5–10% chất lượng suy luận cuối cùng và có ngân sách. Giảm xuống 32B dày đặc cho các khối lượng công việc sáng tạo hoặc tinh chỉnh nặng, và sử dụng 14B/8B khi độ trễ, quyền riêng tư hoặc các hạn chế về thiết bị chiếm ưu thế.
Bất kể bạn chọn biến thể nào, Apidog sẽ giúp bạn tiết kiệm hàng giờ gỡ lỗi API. Tải xuống miễn phí ngay hôm nay và bắt đầu xây dựng với Qwen 3 một cách tự tin.