
Mistral 3 gibi büyük dil modellerini yerel makinenizde çalıştırmak, geliştiricilere veri gizliliği, çıkarım hızı ve özelleştirme üzerinde eşsiz bir kontrol sağlar. Yapay zeka iş yükleri daha talepkar hale geldikçe, yerel yürütme, prototipleme, test etme ve uygulamaları çevrimdışı dağıtma için vazgeçilmez hale gelir. Ayrıca, Ollama gibi araçlar bu süreci basitleştirerek Mistral 3'ün yeteneklerini doğrudan masaüstünüzden veya sunucunuzdan kullanmanıza olanak tanır.
Bu kılavuz, Mistral 3 varyantlarını yerel olarak kurmak ve çalıştırmak için size adım adım talimatlar sunar. Kenar dağıtımlarında öne çıkan açık kaynaklı Ministral 3 serisine odaklanıyoruz. Sonunda, gerçek dünya görevleri için performansı optimize ederek düşük gecikmeli yanıtlar ve kaynak verimliliği sağlayacaksınız.
Mistral 3'ü Anlamak: Yapay Zekada Açık Kaynak Güç Merkezi
Mistral AI, en son sürümü olan Mistral 3 ile sınırları zorlamaya devam ediyor. Geliştiriciler ve araştırmacılar, bu model ailesini doğruluk, verimlilik ve erişilebilirlik dengesi nedeniyle övüyor. Tescilli devlerin aksine, Mistral 3 açık kaynak ilkelerini benimseyerek Apache 2.0 lisansı altında yayınlandı. Bu hamle, topluluğu kısıtlama olmaksızın değiştirmeye, dağıtmaya ve yenilik yapmaya yetkilendiriyor.
Özünde Mistral 3, iki ana daldan oluşur: kompakt Ministral 3 serisi ve geniş kapsamlı Mistral Large 3. 3B, 8B ve 14B parametre boyutlarında mevcut olan Ministral 3 modelleri, kaynak kısıtlı ortamları hedefler. Mühendisler bunları, her watt ve çekirdeğin önemli olduğu yerel ve kenar kullanım durumları için tasarladı. Örneğin, 3B varyantı mütevazı GPU'lara sahip dizüstü bilgisayarlara rahatça sığarken, 14B hızdan ödün vermeden çoklu GPU kurulumlarında sınırları zorlar.
Öte yandan Mistral Large 3, 41B aktif parametre ve toplam 675B ile seyrek bir uzman karışımı mimarisi kullanır. Bu tasarım, sorgu başına yalnızca ilgili uzmanları etkinleştirerek hesaplama yükünü azaltır. Geliştiriciler, kodlama yardımı, belge özetleme ve çok dilli çeviri gibi görevler için talimatlarla ayarlanmış sürümlere erişebilirler. Model, 40'tan fazla dili yerel olarak destekler ve İngilizce dışı diyaloglarda emsallerini geride bırakır.
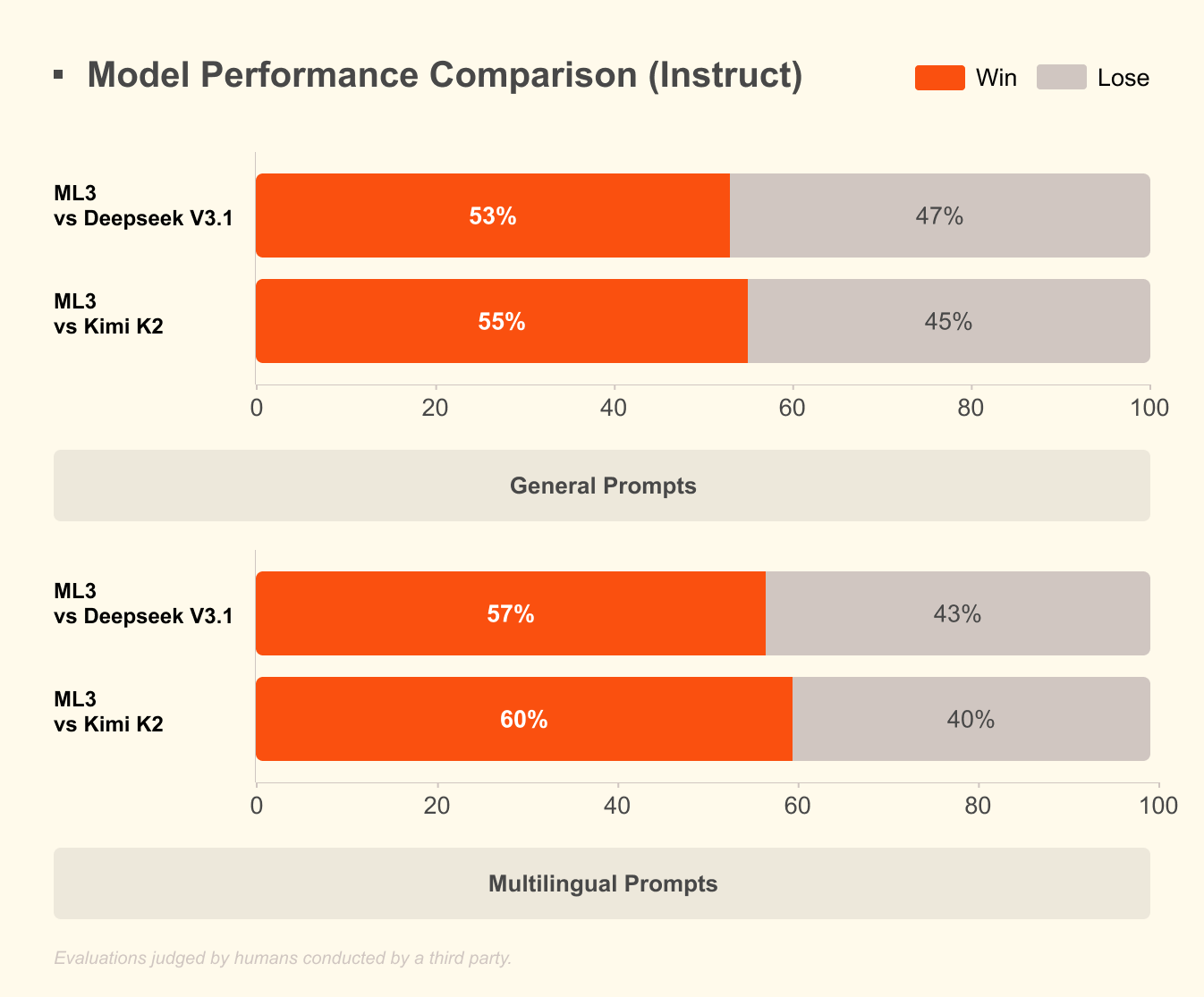
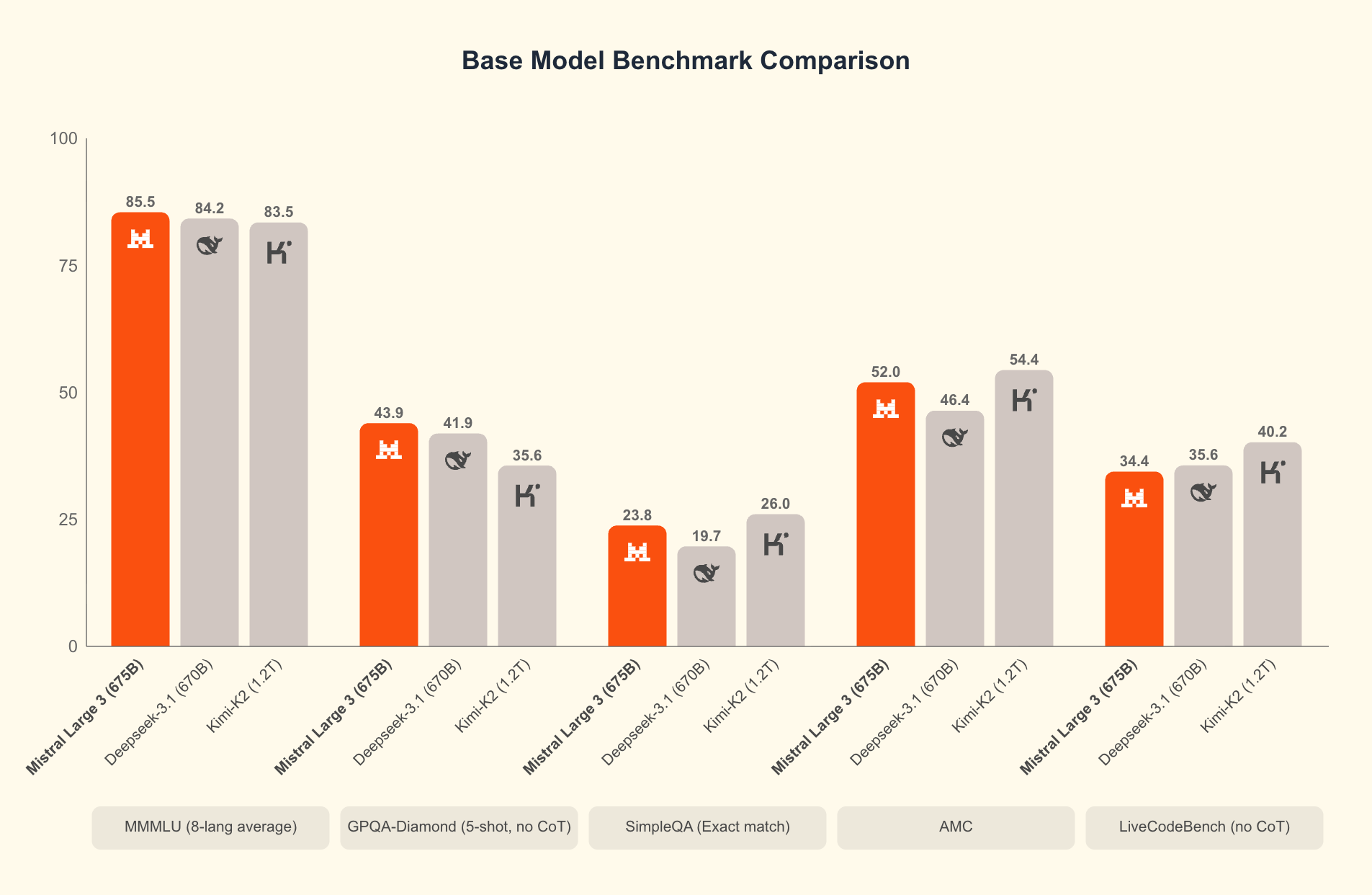
Mistral 3'ü farklı kılan nedir? Karşılaştırmalı testler, gerçek dünya senaryolarında üstünlüğünü ortaya koyuyor. Bilimsel akıl yürütmenin zorlu bir testi olan GPQA Diamond veri setinde, Mistral 3 varyantları çıktı belirteçleri ölçeklendikçe bile yüksek doğruluğu korur. Örneğin, Ministral 3B Instruct modeli, 20.000 belirtece kadar %35-40 civarında bir doğruluk oranını sürdürerek, daha az kaynak kullanırken Gemma 2 9B gibi daha büyük modellerle rekabet eder. Bu verimlilik, NVFP4 sıkıştırması gibi, çıktı kalitesini düşürmeden model boyutunu azaltan gelişmiş niceleme tekniklerinden kaynaklanır.
Ayrıca Mistral 3, görsel soru yanıtlama veya içerik oluşturma uygulamaları için metinle birlikte görüntüleri işleyen multimodal özellikler entegre eder. Bu modelleri açık kaynak haline getirmek hızlı yinelemeyi teşvik eder; topluluklar bunları hukuk analizi veya yaratıcı yazarlık gibi özel alanlar için zaten ince ayar yapıyor. Sonuç olarak, Mistral 3, öncü yapay zekayı demokratikleştirerek start-up'ların ve bireysel geliştiricilerin büyük teknoloji şirketleriyle rekabet etmesini sağlıyor.

Teoriden pratiğe geçiş yapıldığında, bu modelleri yerel olarak çalıştırmak tüm potansiyellerini ortaya çıkarır. Bulut API'ları gecikme ve maliyet getirirken, yerel çıkarım saniyeden daha kısa yanıtlar sunar. Ardından, bunu mümkün kılan donanım ön koşullarını inceleyeceğiz.
Mistral 3'ü Neden Yerel Olarak Çalıştırmalı? Geliştiriciler İçin Faydaları ve Verimlilik Kazançları
Geliştiriciler, yerel yürütmeyi birkaç ikna edici nedenden dolayı tercih eder. Birincisi, gizlilik en üst düzeydedir: hassas veriler makinenizde kalır ve üçüncü taraf sunucularından kaçınır. Sağlık veya finans gibi düzenlenmiş sektörlerde, bu uyumluluk avantajı paha biçilmezdir. İkincisi, maliyet tasarrufları hızla birikir. Mistral 3'ün yüksek verimliliği, yüksek hacimli testler için ideal olan jeton başına ücretlerden kaçınmanız anlamına gelir.
Ayrıca, yerel çalıştırmalar denemeyi hızlandırır. Ağ gecikmeleri olmadan istemler üzerinde yineleme yapın, hiperparametreleri ince ayar yapın veya modelleri zincirleyin. Karşılaştırmalı testler bunu doğruluyor: tüketici donanımında, Ministral 8B saniyede 50-60 jetonluk bir hız elde eder, bu da bulut kurulumlarıyla karşılaştırılabilir ancak sıfır kesinti süresiyle.
Verimlilik, Mistral 3'ün cazibesini tanımlar. Modeller, Ministral varyantlarının Gemma 3 4B ve 12B'yi sürekli doğrulukta geride bıraktığı GPQA Diamond sonuçlarında gösterildiği gibi, düşük maliyetli çıkarım için optimize edilmiştir. Bu, uzun bağlamlı görevler için önemlidir; çıktılar 20.000 jetona uzadıkça, doğruluk minimum düzeyde düşer ve sohbet robotlarında veya kod üreteçlerinde güvenilir performans sağlar.
Ek olarak, Hugging Face gibi platformlar aracılığıyla açık kaynak erişimi, API prototipleme için Apidog gibi araçlarla sorunsuz entegrasyon sağlar. Ölçeklendirmeden önce Mistral 3 uç noktalarını yerel olarak test edin, geliştirme ve üretim arasındaki boşluğu kapatın.
Ancak başarı, doğru kuruluma bağlıdır. Donanım hazır olduğunda kuruluma geçersiniz. Bu hazırlık, sorunsuz çalışmayı sağlar ve verimi en üst düzeye çıkarır.
Yerel Mistral 3 Dağıtımı için Donanım ve Yazılım Gereksinimleri
Mistral 3'ü başlatmadan önce sisteminizin yeteneklerini değerlendirin. Minimum özellikler arasında, 3B model için 16GB RAM'e sahip modern bir CPU (Intel i7 veya AMD Ryzen 7) bulunur. 8B ve 14B varyantları için 32GB RAM ve en az 8GB VRAM'e sahip bir NVIDIA GPU (RTX 3060 veya daha iyisi düşünün) ayırın. Apple Silicon kullanıcıları birleşik bellekten faydalanır; 16GB'lık M1 Pro, 3B'yi zahmetsizce yönetirken, M3 Max 14B'de üstün performans gösterir.
Depolama gereksinimleri değişir: 3B modeli nicelemede yaklaşık 2GB yer kaplarken, 14B için yaklaşık 9GB'a kadar ölçeklenir. Daha hızlı yükleme için SSD kullanın. İşletim sistemleri mi? Linux (Ubuntu 22.04) en iyi performansı sunarken, onu macOS Ventura+ takip eder. Windows 11, WSL2 aracılığıyla çalışır, ancak GPU geçişi ayarlamalar gerektirir.
Yazılım açısından, Python 3.10+ omurgayı oluşturur. GPU hızlandırmasını etkinleştirmek için NVIDIA kartlar için CUDA 12.1'i yükleyin – 100ms altı gecikmeler için hayati öneme sahiptir. Yalnızca CPU çalıştırmaları için ONNX Runtime gibi kütüphaneleri kullanın.
Niceleme burada çok önemli bir rol oynar. Mistral 3, %95 doğruluğu korurken bellek ayak izini %75 azaltan 4-bit ve 8-bit formatları destekler. bitsandbytes gibi araçlar bunu otomatik olarak halleder.
Donanım hazır olduğunda, kurulum basit bir yol izler. Basitliği nedeniyle Ollama'yı öneriyoruz, ancak alternatifler de mevcuttur. Bu seçim süreci kolaylaştırır ve bizi temel kurulum adımlarına götürür.
Ollama Kurulumu: Zahmetsiz Yerel Yapay Zekaya Açılan Kapı
Ollama, Mistral 3 gibi açık kaynaklı modelleri yerel olarak çalıştırmak için önde gelen bir araç olarak öne çıkıyor. Bu hafif platform, karmaşıklıkları soyutlayarak tek bir pakette bir CLI ve API sunucusu sağlar. Geliştiriciler, çapraz platform desteğini ve sıfır yapılandırmalı GPU tespitini takdir ediyor.
Ollama'yı resmi sitesinden (ollama.com) indirerek başlayın. Linux'ta şunu çalıştırın:
curl -fsSL https://ollama.com/install.sh | sh
Bu betik, ikili dosyaları yükler ve hizmetleri ayarlar. ollama --version ile doğrulayın; "ollama version 0.3.0" gibi bir çıktı bekleyin. macOS için DMG yükleyici, ARM'de Intel öykünmesi için Rosetta dahil bağımlılıkları yönetir.
Windows kullanıcıları EXE'yi GitHub sürümlerinden edinebilir. Kurulum sonrası, PowerShell aracılığıyla başlatın: ollama serve. Ollama arka planda daemon olarak çalışır ve 11434 numaralı bağlantı noktasında bir REST API'si sunar.
Neden Ollama? Dahili niceleme ile Ministral 3 dahil olmak üzere modelleri kendi kayıt defterinden çeker. Manuel Hugging Face klonlamasına gerek yoktur. Ek olarak, Mistral 3'ün açık kaynak felsefesiyle uyumlu olarak özel ince ayar için Modelfile'ları destekler.
Ollama hazır olduğunda, bir sonraki adımda modelleri çekip çalıştırırsınız. Bu adım, kurulumunuzu işlevsel bir yapay zeka iş istasyonuna dönüştürür.
Ollama ile Ministral 3 Modellerini Çekme ve Çalıştırma
Ollama'nın kütüphanesi Ministral 3 varyantlarını barındırır.
Mevcut etiketleri listeleyerek başlayın:
ollama list
3B modelini indirmek için:
ollama pull ministral:3b-instruct-q4_0
Bu komut, yaklaşık 2GB veri çeker ve hash'ler aracılığıyla bütünlüğü doğrular. İlerleme çubukları indirmeyi takip eder, genellikle geniş bant bağlantılarda dakikalar içinde tamamlanır.
Etkileşimli bir oturum başlatın:
ollama run ministral-3
Ollama modeli belleğe yükler, sonraki sorgular için önbellekleri ısıtır. İstemleri doğrudan yazın; örneğin:
>> Kuantum dolaşıklığını basit terimlerle açıklayın.

Model, tutarlı çıktılar için talimat ayarını kullanarak gerçek zamanlı olarak yanıt verir. /bye ile çıkın.
Sık karşılaşılan sorunları gidermek mi? GPU'nun yetersiz kullanılması durumunda, OLLAMA_NUM_GPU=999 ortam değişkenini ayarlayın. Bellek yetersizliği (OOM) hataları için, q3_K_M gibi daha düşük bir nicelemeye geçin.
Temellerin ötesinde, Ollama'nın API'si programatik erişim sağlar. Bir tamamlama işlemi için curl kullanın:
curl http://localhost:11434/api/generate -d '{
"model": "ministral:3b-instruct-q4_0",
"prompt": "Write a Python function to sort a list.",
"stream": false
}'
Bu JSON yanıtı, API geliştirme sırasında Apidog ile entegrasyon için mükemmel olan oluşturulmuş metni içerir.
Modelleri çalıştırmak bir başlangıçtır; optimizasyon performansı artırır. Sonuç olarak, donanımınızdan her damla verimliliği sıkıştıran tekniklere yöneliyoruz.
Mistral 3 Çıkarımını Optimize Etme: Hız, Bellek ve Doğruluk Değiş Tokuşları
Verimlilik, yerel yapay zeka başarısını tanımlar. Mistral 3'ün tasarımı burada parlar, ancak ayarlamalar kazançları artırır. Niceleme ile başlayın: Ollama, boyut ve sadakati dengeleyen Q4_0'ı varsayılan olarak kullanır. Ultra düşük kaynaklar için, %10 karmaşıklık maliyetiyle belleği yarıya indiren Q2_K'yi deneyin.
GPU orkestrasyonu önemlidir. Uzun bağlamlarda 2 kat hızlanma için OLLAMA_FLASH_ATTENTION=1 aracılığıyla flash dikkatini etkinleştirin. Mistral 3, 128K belirtece kadar destekler; sürekli doğruluğu doğrulamak için GPQA tarzı istemlerle test edin.
Toplu işleme, verimi artırır. Ollama'nın /api/generate özelliğini birden fazla istemle paralel olarak kullanarak, eşzamansız Python istemcilerinden faydalanın. Örneğin, bir döngü betiği hazırlayın:
import requests
import json
model = "ministral:8b-instruct-q4_0"
url = "http://localhost:11434/api/generate"
prompts = ["Prompt 1", "Prompt 2"]
for p in prompts:
response = requests.post(url, json={"model": model, "prompt": p})
print(json.loads(response.text)["response"])
Bu, çok çekirdekli kurulumlarda saniyede 10'dan fazla sorguyu işler.
Bellek yönetimi takasları önler. nvidia-smi ile izleyin; VRAM dolarsa katmanları CPU'ya boşaltın. vLLM gibi kütüphaneler, sürekli toplu işleme için Ollama ile entegre olur ve A100'lerde saniyede 100 jeton hızını sürdürür.
Doğruluk ayarı mı? Alan verileri üzerinde LoRA adaptörleri ile ince ayar yapın. Hugging Face'in PEFT kütüphanesi bunları Ministral 3'e uygulayarak yaklaşık 1GB ek alan gerektirir. İnce ayar sonrası, ollama create aracılığıyla Ollama formatına dışa aktarın.
Kurulumunuzu GPQA Diamond'a karşı karşılaştırmalı olarak test edin. Doğruluk vs. jetonları çizmek için değerlendirmeleri betik haline getirin, Mistral'ın grafiklerini yansıtın. Ministral 8B gibi yüksek verimli varyantlar %50+ puanları koruyarak Qwen 2.5 VL üzerindeki üstünlüklerini vurgular.
Bu optimizasyonlar sizi gelişmiş uygulamalar için hazırlar. Bu nedenle, Mistral 3'ün erişimini genişleten entegrasyonları inceliyoruz.
Mistral 3'ü Geliştirme Araçlarıyla Entegre Etme: API'lar ve Ötesi
Yerel Mistral 3 ekosistemlerde gelişir. Yapay zeka destekli API'ları taklit etmek için Apidog ile eşleştirin. Ollama'yı sorgulayan uç noktalar tasarlayın, yükleri test edin ve yanıtları doğrulayın – hepsi çevrimdışı.
Örneğin, Apidog'da bir POST /generate rotası oluşturun ve Ollama'nın API'sine yönlendirin. Mistral 3'ün çok dilli istekleri sorunsuz bir şekilde ele almasını sağlayarak istem şablonları için koleksiyonları içe aktarın.
LangChain kullanıcıları Mistral 3'ü araçlarla zincirler:
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
llm = OllamaLLM(model="ministral:3b-instruct-q4_0")
prompt = PromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello world"}))
Bu kurulum, dakikada 50 sorgu işler ve RAG (Retrieval Augmented Generation) işlem hatları için idealdir.
Streamlit panoları çıktıları görselleştirir. Dinamik Soru-Cevap için Mistral 3'ün akıl yürütme yeteneğinden yararlanarak, etkileşimli sohbetler için Ollama çağrılarını uygulamalara gömün.
Güvenlik konuları mı? Ollama'yı NGINX proxy'lerinin arkasında çalıştırın, uç noktaları hız sınırlayın. Üretim için Docker ile kapsayıcılaştırın:
FROM ollama/ollama
COPY Modelfile .
RUN ollama create mistral-local -f Modelfile
Bu, ortamları izole eder ve Kubernetes'e ölçeklendirilebilir.
Uygulamalar geliştikçe izleme anahtar hale gelir. Prometheus gibi araçlar gecikmeyi izler, temel verimlilikten sapmaları uyarır.
Özetle, bu entegrasyonlar Mistral 3'ü bağımsız bir modelden çok yönlü bir motora dönüştürür. Ancak zorluklar ortaya çıkar; bunları ele almak sağlam dağıtımlar sağlar.
Yerel Mistral 3 Çalışmalarında Sık Karşılaşılan Sorun Giderme
Optimize edilmiş kurulumlar bile engellerle karşılaşır. CUDA uyumsuzlukları listenin başında gelir: nvcc --version ile sürümleri doğrulayın. Mistral 3, 11.8+ sürümlerini tolere ettiğinden, çakışmalar ortaya çıkarsa sürümü düşürün.
Model yükleme başarısız mı oluyor? Ollama önbelleğini temizleyin: ollama rm ministral:3b-instruct-q4_0 ardından yeniden çekin. Bozuk indirmeler ağlardan kaynaklanır; --insecure komutunu dikkatli kullanın.
macOS'te Metal hızlandırma CUDA'nın gerisinde kalır. Kararlılık için CPU'yu zorlayın: OLLAMA_METAL=0. Windows WSL kullanıcıları wsl --update aracılığıyla NVIDIA sürücülerini etkinleştirir.
Aşırı ısınma dizüstü bilgisayarları etkiler; gücü sınırlamak için nvidia-smi -pl 100 ile kısın. Doğruluk düşüşleri için istemleri inceleyin – Ministral 3, talimat formatlarında mükemmeldir.
Reddit ve Hugging Face'teki topluluk forumları, kenar durumlarının %90'ını çözer. Tanılamalar için OLLAMA_DEBUG=1 ile hataları günlüğe kaydedin.
Engeller aşıldığında, Mistral 3 tutarlı değer sunar. Son olarak, daha geniş etkisini değerlendiriyoruz.
Sonuç: Yarının Yapay Zeka İnovasyonları İçin Mistral 3'ü Yerel Olarak Kullanın
Mistral 3, gücü ve pratikliği birleştiren yapısıyla açık kaynak yapay zekayı yeniden tanımlıyor. Ollama aracılığıyla yerel olarak çalıştırarak geliştiriciler, başka hiçbir yerde elde edilemeyen hız, gizlilik ve maliyet kontrolü kazanır. Modelleri çekmekten ince ayarlı entegrasyonlara kadar, bu kılavuz size uygulanabilir adımlar sunar.
Cesurca deney yapın: 3B varyantıyla başlayın, 14B'ye ölçeklendirin ve karşılaştırmalı testlere göre ölçün. Mistral AI yineledikçe, yerel çalıştırmalar sizi önde tutar.
Oluşturmaya hazır mısınız? Apidog'u ücretsiz indirin ve Mistral 3 kurulumunuzla desteklenen API'ları prototipleştirin. Verimli yapay zekanın geleceği makinenizde başlar – bunu değerlendirin.