
Geliştiriciler, gelişmiş dil modellerini uygulamalarına entegre etmek için verimli yollar arıyor. INTELLECT-3, açık kaynak temel altyapısı ve muhakeme görevlerindeki güçlü performansı sayesinde cazip bir seçenek olarak öne çıkıyor. Prime Intellect tarafından geliştirilen bu model, karmaşık hesaplamaları yüksek verimlilikle yönetmesini sağlayan 106 milyar parametreli Uzman Karışımı (MoE) mimarisiyle dikkat çekiyor.
INTELLECT-3'ü Anlamak: Açık Kaynak Güç Santrali
Prime Intellect, INTELLECT-3'ü tamamen açık kaynaklı bir model olarak yayınlayarak araştırmacıların ve geliştiricilerin, özel mülkiyet engelleri olmaksızın yeteneklerini özelleştirmelerine ve genişletmelerine olanak tanır. Bu şeffaflık, takviyeli öğrenme (RL) ve ajanssal yapay zeka sistemleri gibi alanlarda inovasyonu teşvik eder. Model ağırlıkları, eğitim çerçeveleri, veri kümeleri, RL ortamları ve değerlendirme araçları dahil olmak üzere tüm pakete doğrudan Prime Intellect'in depolarından erişebilirsiniz.

INTELLECT-3, temelinde GLM-4.5-Air taban modeli üzerine inşa edilmiş 106 milyar parametreli bir MoE mimarisi kullanır. MoE tasarımları, girdileri özel "uzman" alt ağlara yönlendirerek hesaplama kullanımını optimize eder ve çıkarımı hızlandırır. Örneğin, işlem sırasında model yalnızca sorguyla ilgili parametrelerin bir alt kümesini etkinleştirir, bu da doğruluğu korurken gecikmeyi azaltır. Bu kurulum, matematiksel türetmeler veya kod oluşturma gibi seçici uzmanlık gerektiren görevler için özellikle etkili olduğunu kanıtlar.
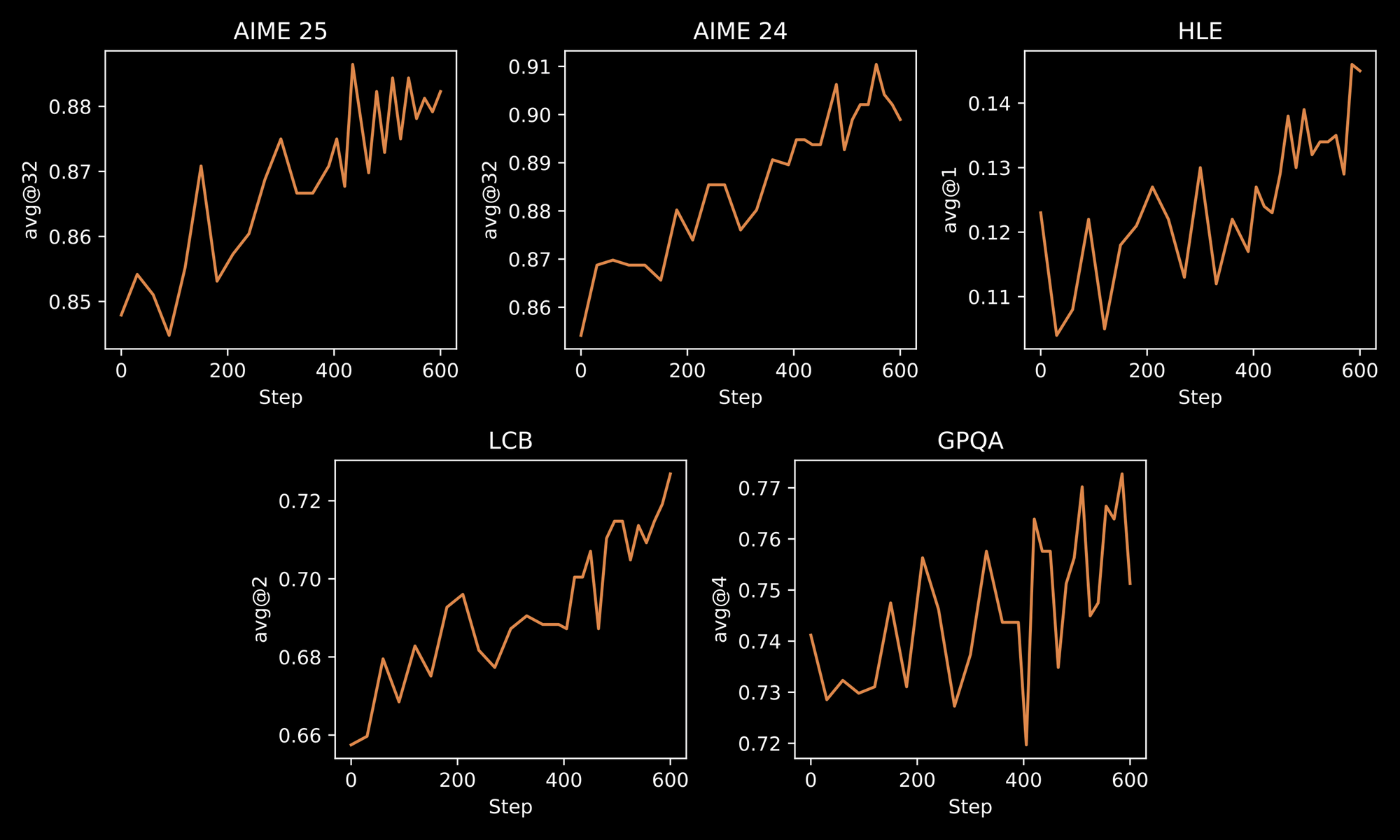
Eğitim süreci, INTELLECT-3'ün sağlamlığını vurgular. Mühendisler iki aşamalı bir metodoloji uygular: özel olarak seçilmiş veri kümeleri üzerinde başlangıç Denetimli İnce Ayar (SFT) ve ardından özel prime-rl çerçevesini kullanarak büyük ölçekli RL. prime-rl, geniş paralel simülasyonları verimli bir şekilde yöneten eşzamansız, politika dışı bir RL sistemi olarak çalışır. Bundan, yinelemeli problem çözme veya çok adımlı planlama gibi dinamik ortamlarda geliştirilmiş model davranışları aracılığıyla faydalanırsınız.
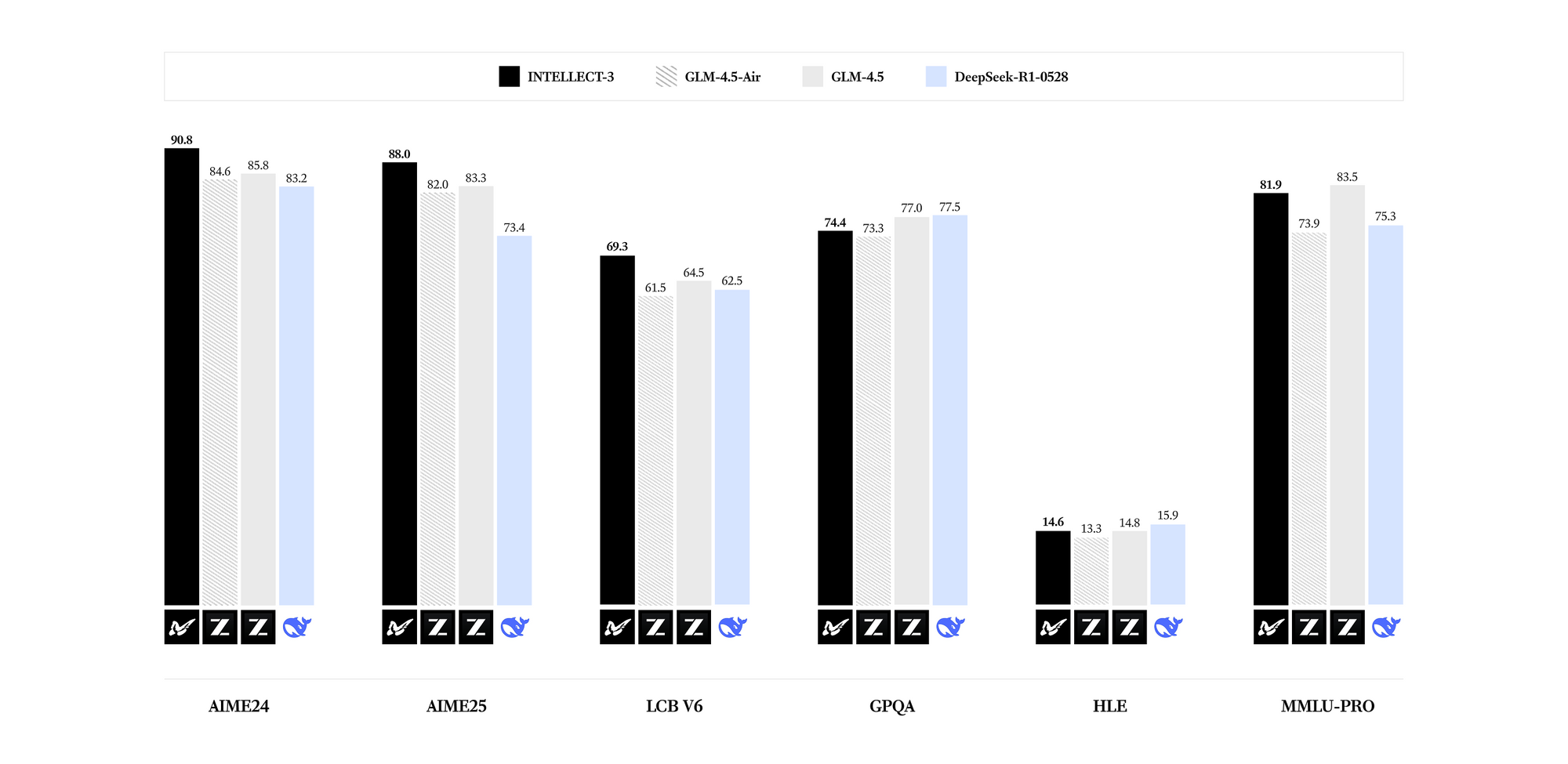
INTELLECT-3 uzmanlaşmış alanlarda öne çıkar. Kıyaslamalar, parametre sayısı için matematik (örn. GSM8K puanları %95'i aşan), kodlama (HumanEval geçiş oranları %85'in üzerinde), bilim (GPQA doğruluğu %60'ın üzerinde) ve muhakeme (MMLU puanları %80'e yakın) genelinde son teknoloji sonuçlar ortaya koyar. Llama 3.1 70B gibi daha yoğun modellerle karşılaştırıldığında, INTELLECT-3 seyrek aktivasyon modelleri sayesinde eşdeğer donanımda 2 kat daha hızlı çıkarım ile üstün verimlilik elde eder. Sonuç olarak, çıktı kalitesinden ödün vermeden kaynak kısıtlı ortamlarda konuşlandırabilirsiniz.
Destekleyici altyapı, açık kaynak çekiciliğini artırır. Verifier'lar ve Ortamlar Merkezi, basit bulmacalardan gelişmiş teorem kanıtlayıcılara kadar 500'den fazla RL ortamı sağlar.
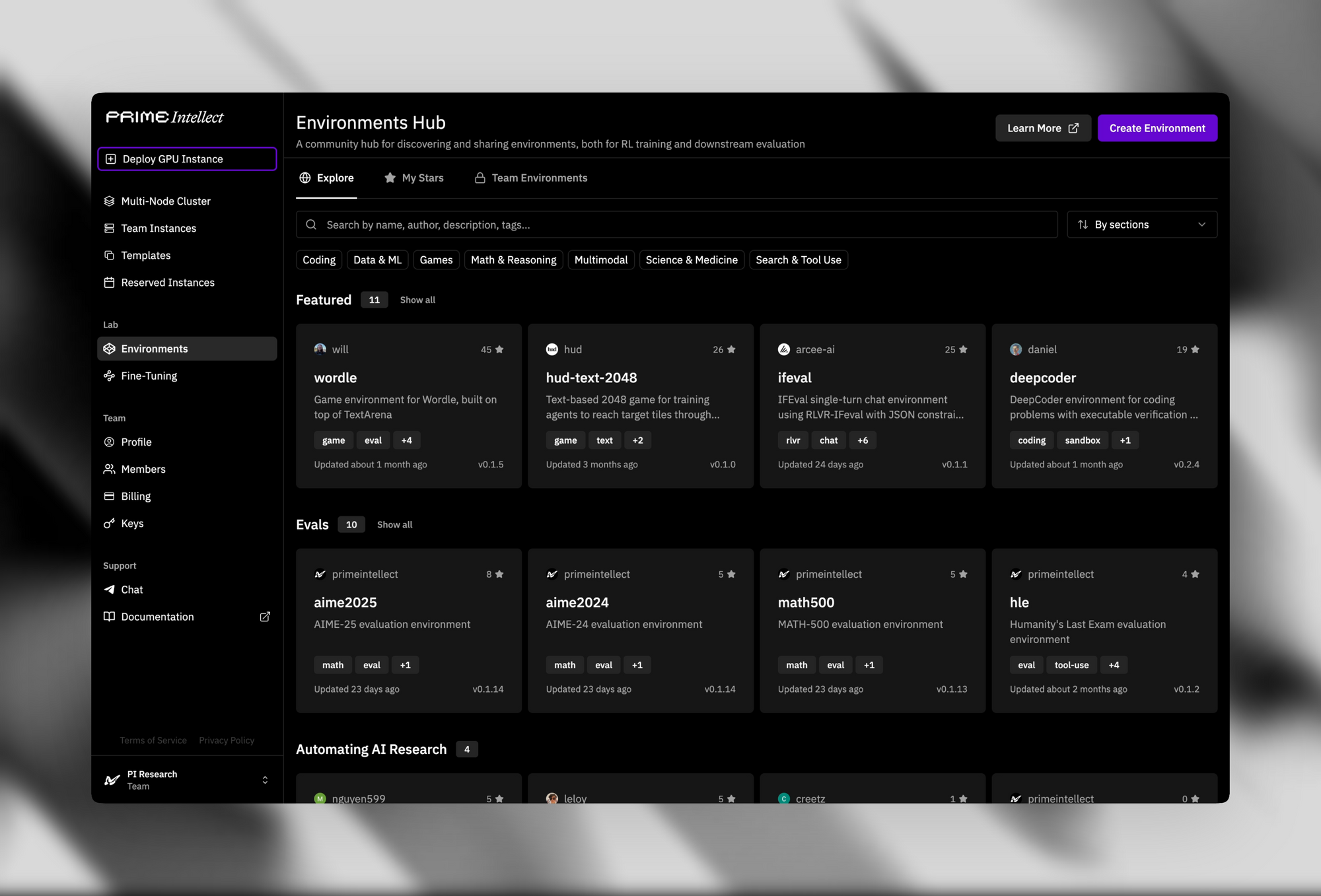
Prime Sandboxları, eğitim veya çıkarım sırasında aracı eylemlerini izole eden güvenli, yüksek verimli kod yürütme sunar. Geliştiriciler, bu araçları INTELLECT-3'ü yazılım geliştirme süreçlerindeki otonom aracılar gibi özel uygulamalar için ince ayarlamak üzere kullanır.
Pratikte, model ağırlıklarını Hugging Face veya Prime Intellect'in GitHub'ı üzerinden indirirsiniz. Kurulum, PyTorch ve Transformers kütüphanesi gibi standart bağımlılıklar gerektirir. Modeli yüklemek için temel bir betik şuna benzer:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
Bu kod, modeli GPU özellikli donanım üzerinde başlatır. Ancak, üretim ölçeğinde kullanım için barındırılan API'lere geçiş yaparsınız, çünkü kendi kendine barındırma önemli hesaplama gücü (örn. birden fazla A100 GPU) gerektirir. Bu nedenle, açık kaynak erişimi temel oluşturur, ancak API entegrasyonu dağıtımlarınızı etkili bir şekilde ölçeklendirir.
Yerel denemelerden geçiş yaparak, şimdi INTELLECT-3'e yönetilen hizmetler aracılığıyla nasıl erişeceğinizi keşfediyorsunuz. Bu geçiş, güvenilirliği sağlar ve dağıtılmış çıkarımın karmaşıklıklarını yönetir.
INTELLECT-3 API'ye Erişim: Kurulum ve Kimlik Doğrulama
Seçenek 1 – Prime Intellect Yerel Uç Noktası (Maksimum performans ve en düşük gecikme için önerilir)
API erişimine Prime Intellect'in platformundan kimlik bilgileri alarak başlarsınız. app.primeintellect.ai adresindeki Prime Intellect panosunu ziyaret edin ve gerekirse bir hesap oluşturun.
Giriş yaptıktan sonra, API anahtarları bölümüne gidin ve Çıkarım (Inference) izinleri etkinleştirilmiş yeni bir anahtar oluşturun. Bu anahtar, INTELLECT-3'e güvenli erişim sağlayarak sonraki tüm istekleri doğrular.
Ardından, ortamınızı yapılandırın. Sorunsuz entegrasyon için API anahtarını bir ortam değişkeni olarak ayarlayın:
export PRIME_API_KEY="your-api-key-here"
Ekip tabanlı iş akışları için, isteklere X-Prime-Team-ID başlığını ekleyin. Bu tanımlayıcı, kullanımı doğru faturalandırma havuzuna yönlendirir ve hesaplar arası ücretlendirmeyi önler. Ekip kimliğini pano üzerinden hesap ayarlarından alabilirsiniz.
API, openai-python gibi kütüphaneleri zaten kullanıyorsanız benimsemeyi basitleştiren OpenAI uyumlu bir arayüz benimser. Temel URL'yi https://api.pinference.ai/api/v1 olarak belirtin. Bu uç nokta, INTELLECT-3 örneklerini barındıran Parasail ve Nebius dahil olmak üzere optimize edilmiş çıkarım sağlayıcılarına istekleri iletir. Sonuç olarak, temel kümeleri yönetmeden düşük gecikmeli yanıtlar elde edersiniz.
Erişimi doğrulamak için modeller uç noktasını sorgulayın. Bu, mevcut modelleri listeler ve INTELLECT-3'ün varlığını onaylar (genellikle prime-intellect/intellect-3 gibi bir ad altında). Hızlı kontroller için CLI aracını kullanın:
prime inference models
Alternatif olarak, curl aracılığıyla bir GET isteği gönderin:
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
Yanıt, id, max_tokens ve context_window gibi parametreleri detaylandıran model nesnelerinin bir JSON dizisini döndürür. INTELLECT-3, uzun biçimli muhakeme zincirlerini barındıran 128K belirteç bağlamını destekler.
Kimlik doğrulama, hız sınırlamasına ve kotalara kadar uzanır. Prime Intellect, planınıza bağlı olarak panoda görünen dakika başına ve günlük limitleri uygular. Kullanımı, işlenen belirteçleri ve yapılan API çağrılarını kaydeden Faturalandırma sekmesi aracılığıyla izlersiniz. Limitler iş akışınızı kısıtlıyorsa, platform aracılığıyla sorunsuz bir şekilde yükseltme yapın.
Ayrıca, gelişmiş testler için Apidog ile entegre olun. OpenAI şemasını Apidog'a aktarın, ardından INTELLECT-3 uç noktalarına istekleri simüle edin. Bu uygulama, yanlış biçimlendirilmiş JSON yükleri gibi sorunları erken tespit eder. Apidog'un ücretsiz katmanı, ilk kurulumlar için yeterlidir ve yerel geliştirmeyi üretim API'lerine bağlar.
Kimlik doğrulama tamamlandığında, istekleri oluşturmaya geçersiniz. Aşağıdaki bölüm, INTELLECT-3'ten optimum yanıtlar almak için kesin formatları özetlemektedir.
Seçenek 2 – OpenRouter (Anında erişim ve birleşik krediler)
Kendi kendine barındırma veya Prime Intellect'in yerel çıkarım platformunu kullanmanın yanı sıra, INTELLECT-3 resmi olarak OpenRouter'da da mevcuttur. Bu size birleşik faturalandırma, otomatik geri dönüş yönlendirmesi ve anında erişim sağlayan alternatif bir geçit sunar; OpenRouter'ı zaten kullanıyorsanız ayrı bir Prime Intellect hesabına gerek yoktur.
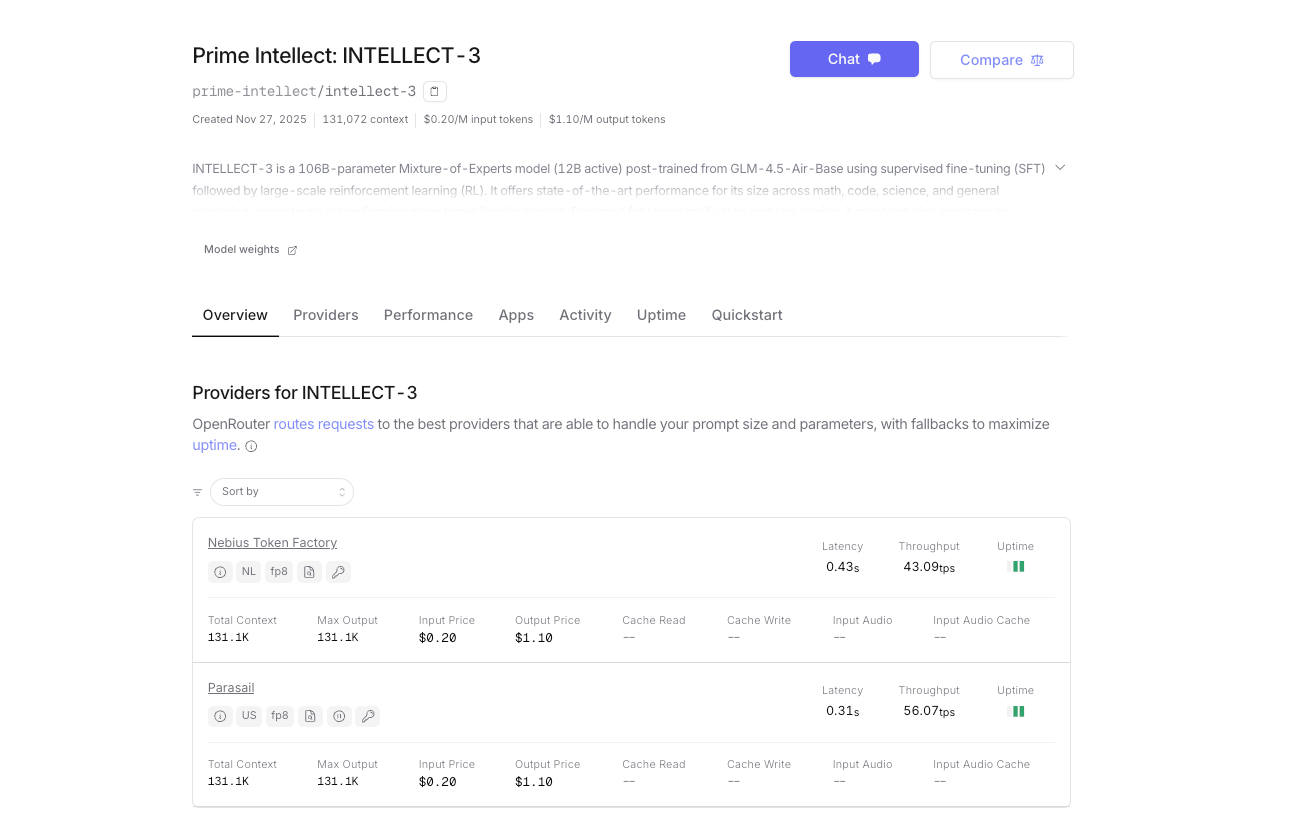
- Temel URL: https://openrouter.ai/api/v1
- Model adı: prime-intellect/intellect-3
- Kimlik doğrulama: OpenRouter API anahtarınız (OPENROUTER_API_KEY)
- Otomatik sağlayıcı yönlendirme (şu anda Prime Intellect kümeleri tarafından sağlanmaktadır)
- OpenRouter kredileriyle kullandıkça öde; platform ücreti nedeniyle belirteç başına biraz daha yüksek maliyet
Her iki uç nokta da aynı istek/yanıt şemalarını, akış özelliğini, araç çağırmayı ve JSON modunu destekler.
INTELLECT-3 API'ye İstek Yapma: Formatlar ve Örnekler
Etkileşimleri, konuşma ve görev odaklı istemleri yöneten /chat/completions uç noktası aracılığıyla başlatırsınız. İstekleri model, messages, temperature ve max_tokens alanlarına sahip JSON nesneleri olarak oluşturursunuz. messages dizisi, "sistem", "kullanıcı" ve "asistan" gibi rolleri kullanarak sohbet geçmişlerini taklit eder.
Kod oluşturma için basit bir örnek düşünün. Şunu gönderirsiniz:
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
Bu kod, INTELLECT-3'ün kodlama yeteneğinden yararlanarak memoizasyonlu özyinelemeli bir Fibonacci uygulaması çıktısı verir. temperature parametresi yaratıcılığı kontrol eder; daha düşük değerler (örn. 0.2) olgusal sorgular için deterministik çıktıları desteklerken, daha yüksek değerler (1.0'a kadar) çeşitli muhakeme yollarını teşvik eder.
Matematiksel muhakeme için, düşünceleri zincirlemek üzere istemleri yapılandırırsınız. INTELLECT-3'ün RL eğitimi burada parlar, çünkü adım adım doğrulamayı simüle eder. Örnek:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
Model, aksiyomlar ve teoremlerden alıntı yaparak titiz bir kanıtla yanıt verir. Çıktıyı, bir dize olarak gelen response.choices[0].message.content aracılığıyla ayrıştırırsınız. Yapılandırılmış veriler için, isteğe "response_format": {"type": "json_object"} ekleyerek JSON modunu etkinleştirin, böylece ayrıştırılabilir yanıtlar sağlanır.
Gelişmiş kullanım, INTELLECT-3'ün harici işlevleri entegre ettiği araç çağırmayı içerir. İstekte araçları tanımlayın:
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
Model aracı çağırırsa, response.choices[0].message.tool_calls içinde argümanları döndürür. İşlevi harici olarak yürütür ve sonuçları bir sonraki mesajda geri beslersiniz. Bu desen, INTELLECT-3'ün çevreye duyarlı eğitimli davranışlarından faydalanarak ajanssal iş akışları oluşturur.
Hata yönetimi kritik bir parçadır. Yaygın sorunlar arasında 401 (geçersiz anahtar), 429 (hız sınırı) ve 400 (hatalı istek) bulunur. Üstel geri çekilme ile yeniden denemeler uygulayın:
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
Yanıtlar, optimizasyon için kaydettiğiniz usage (prompt_tokens, completion_tokens, total_tokens) gibi meta verileri içerir. INTELLECT-3, derinlik ve hızı dengeleyerek tamamlama başına 4096 belirtece kadar işler.
Akışlı yanıtlar gerçek zamanlı uygulamaları geliştirir. Oluşturma çağrısına stream=True ekleyin; istemci, Sunucu Tarafından Gönderilen Olaylar olarak parçaları döndürür. Bunları yinelemeli olarak ayrıştırın:
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Bu teknik, kullanıcıların artımlı geri bildirim beklediği sohbet robotları veya canlı kod asistanları için uygundur.
İstek oluşturmada ustalaştıktan sonra performansı değerlendirirsiniz. Bir sonraki bölüm, INTELLECT-3'e özel kıyaslama araçlarını tanıtır.
INTELLECT-3 API Kullanımını Optimize Etme ve Değerlendirme
API çağrılarını parametreleri deneysel olarak ayarlayarak optimize edersiniz. Verim artışı için birden fazla mesajı tek bir isteğe toplu olarak göndermeyle başlayın—değerlendirme paketlerinde %10'a kadar verimlilik artışı. Prime Intellect'in CLI'si bunu destekler:
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
Bu komut, 100 GSM8K örneğini çalıştırır, doğruluk ve gecikme metriklerini birleştirir. Uzun nesillerdeki tekrarları azaltan top_p veya frequency_penalty değerlerini ayarlamak için sonuçları analiz edersiniz.
Değerlendirme, Doğrulayıcılar Merkezinden özel ortamlara kadar uzanır. Bir RL ortamı yükleyin ve INTELLECT-3'ü politika olarak sorgulayın:
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
Ödüller iyileştirmeleri nicelendirir, yerel olarak barındırıyorsanız ince ayarı yönlendirir. Yalnızca API kullanıcıları için, etkileşimleri bir vektör veritabanına kaydedin ve görev başarı oranı gibi aşağı akış metriklerini hesaplayın.
Güvenlik konuları da önemlidir. İstem enjeksiyonunu önlemek için kullanıcı girişlerini temizleyin ve sınırları zorlamak için sistem istemlerini kullanın. INTELLECT-3'ün RL geçmişi halüsinasyonları azaltır, ancak yüksek riskli uygulamalar için çıktıları doğrulayıcılara karşı doğrularsınız. Ölçeklendirme, pano üzerinden izlemeyi içerir. Belirteç eşikleri için uyarılar ayarlayın ve Prime Intellect'in kümeler için sunduğu Prometheus gibi gözlem araçlarıyla entegre olun. Böylece, kullanım arttıkça güvenilirliği sürdürürsünüz.
Optimizasyonu ele aldığınıza göre, maliyetleri göz önünde bulundurun. Fiyatlandırma şeffaflığı, sürdürülebilir entegrasyonu sağlar.
INTELLECT-3 API Fiyatlandırması: Şeffaf Belirteç Tabanlı Model
Prime Intellect, fiyatlandırmayı belirteç tüketimi etrafında yapılandırır, giriş ve çıkış için ayrı ayrı ücret alır. Model ve sağlayıcıya göre değişen oranlarla her 1.000 belirteç için ödeme yaparsınız. INTELLECT-3 için, milyon giriş belirteci başına yaklaşık 0,50 dolar ve milyon çıktı başına 1,50 dolar civarında rekabetçi rakamlar bekleyebilirsiniz; ancak kesin değerler modeller uç noktası yanıtında görünür.
| Sağlayıcı | Giriş ($$ /1M belirteç) | Çıkış ($$ /1M belirteç) | Notlar |
|---|---|---|---|
| Prime Intellect Doğrudan | ~$0.45–$0.60 | ~$1.30–$1.80 | En düşük maliyet, hacimli indirimler |
| OpenRouter | ~$0.60–$0.80 | ~$1.80–$2.40 | OpenRouter platform ücreti dahildir |
Kesin oranlar dalgalanabilir; her zaman panonuzdaki veya modeller uç noktası aracılığıyla en son değerleri kontrol edin.
Hangisini Seçmelisiniz?
- Maksimum hız, en düşük maliyet istiyorsanız veya yüksek hacimli kullanım planlıyorsanız doğrudan Prime Intellect'i seçin.
- 50'den fazla modelde tek bir API anahtarı tercih ediyorsanız, anında kurulum gerektiğinde veya yerleşik geri dönüş yönlendirmesi istiyorsanız OpenRouter'ı seçin.
Her iki seçenek de aynı INTELLECT-3 performansını sunar. İş akışınıza uyanı seçin; birçok ekip yedeklilik için her ikisini birden aynı anda kullanır.
Bu kılavuzun geri kalanı (istek formatları, akış, araç çağırma, optimizasyon vb.), Prime Intellect'i doğrudan veya OpenRouter aracılığıyla çağırmanız fark etmeksizin eşit şekilde uygulanır.
Aşağıdaki tüm teknik uygulama detaylarıyla devam edin ve sizin için en uygun ağ geçidi aracılığıyla INTELLECT-3 ile bugün inşa etmeye başlayın.
INTELLECT-3 API ile Gelişmiş Entegrasyonlar
Orkestrasyon için INTELLECT-3'ü LangChain veya LlamaIndex gibi ekosistemlere genişletirsiniz. LangChain'de:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
Bu, API'yi geri çağırma artırılmış üretim (RAG) hatlarına bağlayarak harici bilgiyle doğruluğu artırır.
Mikro hizmetler için, INTELLECT-3'e vekil olarak çalışan FastAPI sarmalayıcıları aracılığıyla dağıtım yapın:
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
Bu uç noktayı güvenli bir şekilde açığa çıkarın, Redis ile hız sınırlaması uygulayın. Bu tür kurulumlar, içerik üreticilerden araştırma asistanlarına kadar SaaS araçlarına güç verir.
Uç durumlar dikkat gerektirir. Belirteç taşmalarını girişleri dinamik olarak kırparak ele alın ve INTELLECT-3 kuyrukta bekliyorsa daha küçük modellere geri dönün. Prime Intellect'in sitesindeki topluluk forumları sorun giderme başlıkları sunar.
Sonuç: INTELLECT-3 API'yi Güvenle Dağıtın
Artık INTELLECT-3 API kullanımı için kapsamlı bir araç setine sahipsiniz. Açık kaynak köklerinden hassas istek işlemeye ve maliyet yönetimine kadar bu kılavuz sizi gerçek dünya dağıtımları için donatır. İş akışlarınızı iyileştirmek için Apidog ile deney yapın ve güncellemeler için gelişen belgeleri izleyin.
Bu teknikleri artımlı olarak uygulayın—basit sohbetlerle başlayın, ardından aracılara ölçeklendirin. INTELLECT-3'ün verimliliği ve açıklığı, onu teknik yapay zeka projeleri için vazgeçilmez kılar. Bugün kodlamaya başlayın ve uygulamalarınız üzerindeki etkisine tanık olun.