
xAI, Grok 4.1'i yayınladı ve büyük dil modelleriyle çalışan mühendisler farkı hemen hissetti. Dahası, bu güncelleme ham benchmark peşinde koşmak yerine gerçek dünya kullanılabilirliğine öncelik veriyor. Sonuç olarak, sohbetler daha keskin hissediliyor, yanıtlar tutarlı bir kişiliğe sahip oluyor ve olgusal hatalar önemli ölçüde azalıyor.
xAI'deki araştırmacılar, Grok 4'ü güçlendiren aynı pekiştirmeli öğrenme altyapısı üzerine Grok 4.1'i inşa etti. Ancak, yakından incelenmeyi hak eden yeni ödül modelleme teknikleri tanıttılar.
Mimari ve Dağıtım Varyantları
xAI, Grok 4.1'i iki farklı yapılandırmada sunuyor. Birincisi, düşünmeyen varyant (dahili kod adı: tensor), ara akıl yürütme belirteçleri olmadan doğrudan yanıtlar üretir. Bu mod gecikmeyi önceliklendirir ve ailedeki en hızlı çıkarım sürelerini elde eder. İkincisi, düşünen varyant (kod adı: quasarflux), nihai çıktıdan önce açık düşünce zinciri adımlarını gösterir. Sonuç olarak, karmaşık analitik görevler görünür akıl yürütme izlerinden faydalanır.
Her iki varyant da aynı önceden eğitilmiş omurgayı paylaşır. Ek olarak, eğitim sonrası hizalamalar incelikli farklılıklar gösterir: düşünen mod, adım adım ayrıştırmayı teşvik eden ek pekiştirme sinyalleri alırken, düşünmeyen mod özlü, anlık yanıtlar için optimize edilmiştir.
Erişime kolayca devam ediliyor. Kullanıcılar grok.com, x.com veya mobil uygulamalardaki model seçicide "Grok 4.1"i açıkça seçerler.
Alternatif olarak, otomatik mod, 1 Kasım 2025'te başlayan kademeli dağıtımın ardından artık çoğu trafik için varsayılan olarak Grok 4.1'i kullanıyor.

Tercih Optimizasyonunda Çığırlar Açan Gelişmeler
Temel yenilik ödül modellemede yatmaktadır. Geleneksel RLHF, büyük ölçekte toplanan insan tercihlerine dayanır. Buna karşılık, xAI artık öncü ajanslı akıl yürütme modellerini otonom yargıçlar olarak kullanıma sunuyor. Bu yargıçlar, stil tutarlılığı, duygusal algı, olgusal temel ve kişilik istikrarı gibi boyutlarda binlerce yanıt varyantını değerlendirir.
Bu kapalı döngü sistemi, insan müdahalesi gerektiren iş akışlarından çok daha hızlı döner. Dahası, insanların tutarlı bir şekilde sıralamakta zorlandığı incelikli kriterlere kadar ölçeklenebilir. İlk dahili deneyler, ajanslı ödül modellerinin önceki skaler ödüllere göre son kullanıcı memnuniyetiyle daha iyi korelasyon gösterdiğini ortaya koydu.
Benchmark Hakimiyeti: LMArena ve Ötesi
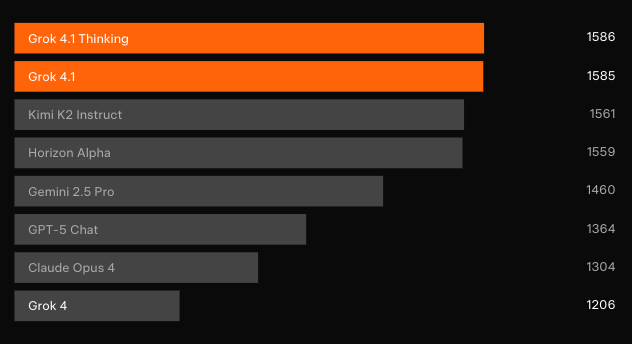
Bağımsız kör testler, elde edilen kazanımları doğruluyor. En temsili kitlesel kaynaklı liderlik tablosu olan LMArena'nın Metin Arenası'nda Grok 4.1 Thinking, 1483 Elo puanıyla 1 numaralı konumu elde etti. Bu fark, en iyi xAI dışı girişimin 31 puan önünde yer alıyor. Bu arada, Grok 4.1 düşünmeyen varyantı 1465 Elo ile 2. sırayı alarak diğer tüm modellerin tam akıl yürütme yapılandırmalarını geride bıraktı.

Önceki üretim modeline karşı yapılan ikili tercih testleri, kullanıcıların Grok 4.1 yanıtlarını %64.78 oranında seçtiğini gösteriyor. Ayrıca, özel değerlendirmeler hedeflenmiş sıçramaları ortaya koyuyor.
Duygusal Zeka (EQ-Bench v3)
Grok 4.1, empati, içgörü ve kişilerarası nüans için 45 çok turlu rol yapma senaryosunu değerlendiren EQ-Bench3'te kaydedilen en yüksek puanı elde etti. Yanıtlar artık önceki modellerin gözden kaçırdığı ince duygusal ipuçlarını algılayabiliyor. Örneğin, bir kullanıcı "Kedimi o kadar çok özledim ki canım yanıyor" yazdığında, Grok 4.1, genel klişelere düşmeden katmanlı bir onay, nazik bir doğrulama ve açık uçlu destek sunuyor.
Yaratıcı Yazarlık v3
Model, yargıçların 32 istem üzerinde yinelemeli hikaye devamlılığını puanladığı Yaratıcı Yazarlık v3'te de yeni bir rekor kırdı. Çıktılar daha zengin görseller, daha sıkı olay örgüsü tutarlılığı ve daha özgün bir ses sergiliyor. Grok'tan kendi "uyanışını" rol yapmasını isteyen bir gösterim istemi, mizahı, varoluşsal merakı ve meme referanslarını sorunsuz bir şekilde harmanlayan viral bir X-post tarzı monolog üretti.
Halüsinasyon Azaltma
Nicel ölçümler, Grok 4.1'in bilgi arama sorgularında selefinden üç kat daha az halüsinasyon gördüğünü gösteriyor. Mühendisler bunu, katmanlı üretim trafiği ve FActScore (500 biyografi sorusu) gibi klasik veri kümeleri üzerinde hedeflenen eğitim sonrası çalışmalarla başardı. Ek olarak, düşünmeyen mod artık güven iç eşiklerin altına düştüğünde web arama araçlarını proaktif olarak tetikleyerek yanıtları doğrulanabilir kaynaklara daha da bağlamaktadır.

Güvenlik ve Sorumluluk Değerlendirmesi
Resmi model kartı, kırmızı ekip sonuçlarına eşi benzeri görülmemiş bir şeffaflık sağlıyor.
Giriş filtreleri, doğrudan istekler altında yanlış negatif oranları 0.00–0.03 kadar düşük olan kısıtlı biyoloji ve kimya sorgularını engeller. İstek enjeksiyon saldırıları bu rakamı mütevazı bir şekilde artırır (0.12–0.20), bu da devam eden düşmanca dayanıklılık çalışmalarını gösterir.
İhlal edici sohbet istemlerinde red oranları filtreler olmadan bile %93–95'e ulaşırken, düşünmeyen yapılandırmada jailbreak başarısı sıfıra yakın düşer. Ajanslı senaryolar (AgentHarm, AgentDojo) en zor kategori olmaya devam ediyor, ancak mutlak yanıt oranları 0.14'ün altında kalıyor.
Kasıtlı olarak korumasız yapılan ikili kullanıma uygunluk değerlendirmeleri, biyoloji (WMDP-Bio %87) ve kimyada güçlü bilgi geri çağırma yeteneğini ortaya koyuyor, ancak çok adımlı prosedürel akıl yürütme, şekil yorumlama veya klonlama protokolleri gerektiren görevlerde insan uzman tabanlarının gerisinde kalıyor. Bu desen, sektör genelindeki mevcut öncü sınırlamalarla uyumludur.
API Tüketicileri ve Geliştiricileri için Çıkarımlar
xAI API, Grok 4.1 uç noktalarını standart model adları altında zaten sunuyor. Gecikme profilleri gözle görülür şekilde iyileşiyor: düşünmeyen mod, tipik istemlerde ilk belirtece kadar geçen sürede ortalama 400 ms'nin altında kalırken, düşünme modu isteğe bağlı parametreler aracılığıyla kontrol edilebilir akıl yürütme derinliği ekler.
İşte tam da burada Apidog parlıyor. Resmi OpenAPI 3.1 spesifikasyonunu (halka açık) içe aktarın, ardından 20'den fazla dilde anında istemci SDK'ları oluşturun. Yeni düşünme belirteci akışları da dahil olmak üzere Grok 4.1'in tam yanıt şemasını kopyalayan sahte sunucular kurarak arka uç testlerinizin canlı API kredilerine takılmasını önleyin. xAI bozan değişiklikler (nadiren, ama mümkün) dağıttığında, Apidog'un fark görüntüleyicisi şema kaymasını hemen vurgular.
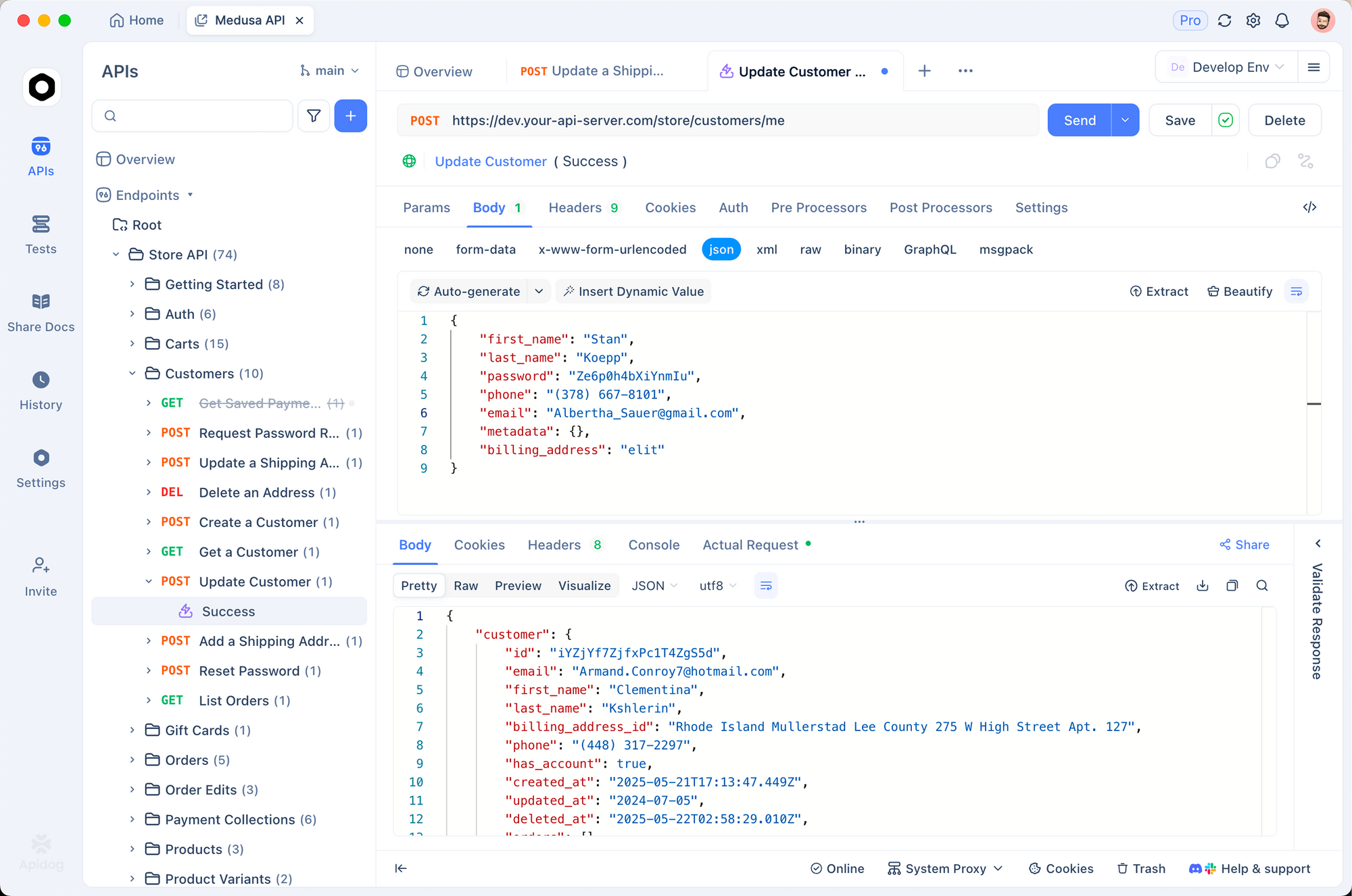
Gerçek ekipler, model yükseltmeleri sırasında %100 çalışma süresini korumak için Apidog'u zaten kullanıyor. Fortune-500 müşterilerinden biri, Postman'dan geçiş yaptıktan sonra entegrasyon hatalarını %68 oranında azalttığını bildirdi.
Çağdaş Öncü Modellere Karşı Karşılaştırma
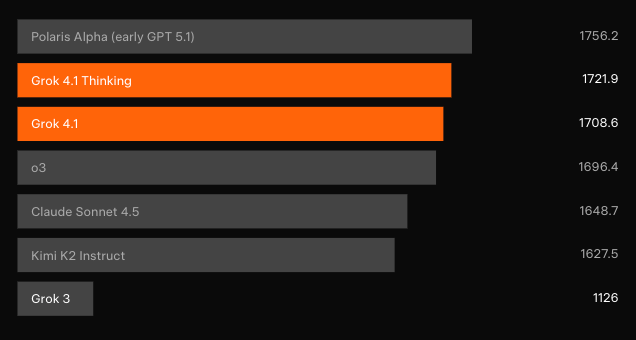
Lansmandan saatler sonra doğrudan karşılaştırma verileri hala seyrek olsa da, LMArena Elo derecelendirmeleri en net sinyali sağlıyor. Grok 4.1 Thinking, OpenAI, Anthropic, Google ve Meta'dan çıkan her yapılandırmayı, genellikle tam mimari sıçramalar gerektiren farklarla geride bırakıyor.
Hız-kalite dengeleri, tüketici sohbetleri için Grok 4.1 düşünmeyen varyantını desteklerken, düşünme modu o3-pro veya Claude 4 Opus gibi akıl yürütme ağırlıklı tekliflerle doğrudan rekabet ediyor — genellikle sübjektif tutarlılık ve kişilik muhafazasında kazanıyor.
Sonuç
Grok 4.1 sadece metrikleri artırmakla kalmıyor; öncü alanı insanların saatlerce konuşmaktan keyif aldığı modellere doğru yeniden yönlendiriyor. Teknik kullanıcılar daha hızlı, daha güvenilir bir uç nokta kazanıyor. Yaratıcılar, daha önce ulaşılamayan seviyelerde tonu ve duyguyu anlayan bir iş ortağına sahip oluyor. Ve güvenlik araştırmacıları, bugüne kadar yayınlanan en ayrıntılı model kartını alıyor.
Apidog'u bugün tamamen ücretsiz indirin ve rakipleriniz duyuruyu okumayı bitirmeden Grok 4.1 ile geliştirmeye başlayın. Öncü ilerlemeyi izlemek ile bu ilerleme üzerine ürünler sevk etmek arasındaki fark genellikle bugün alınan araç kararlarına bağlıdır.