
Mühendisler ve geliştiriciler, aşırı kaynak talepleri olmadan yüksek performans sunan verimli modelleri sürekli olarak ararlar. GLM-4.7-Flash bu ortamda cazip bir seçenek olarak öne çıkıyor. Zhipu AI (Z.ai) tarafından geliştirilen bu 30B-A3B Uzman Karışımı (MoE) modeli, gücü ve verimliliği arasındaki dengeyle dikkat çekiyor. Kodlama kıyaslamalarında, muhakeme görevlerinde ve araç entegrasyonunda üstün başarı göstererek yerel dağıtım senaryoları için uygun hale geliyor.
GLM-4.7-Flash'ı yerel olarak çalıştırmak, kullanıcıların veri gizliliğini korumasına, gecikmeyi azaltmasına ve entegrasyonları özelleştirmesine olanak tanır. Ollama, LM Studio ve Hugging Face gibi araçlar bu süreci basitleştirir.
Bu kılavuzda ilerlerken, kurulum ve kullanıma ilişkin pratik bilgiler edineceksiniz. İlk olarak, sistemin temel gereksinimlerini göz önünde bulundurun.
GLM-4.7-Flash Nedir ve Neden Yerel Olarak Kullanılır?
GLM-4.7-Flash, açık kaynaklı dil modellerinde bir ilerlemeyi temsil eder. glm4_moe_lite mimarisi üzerine inşa edilmiş olup, MIT lisansı altında BF16 ve F32 tensör tiplerini kullanır. Modelin "GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models" adlı makalesi, arXiv:2508.06471'den yararlanarak araç kullanımı ve muhakeme için eğitimini detaylandırmaktadır.
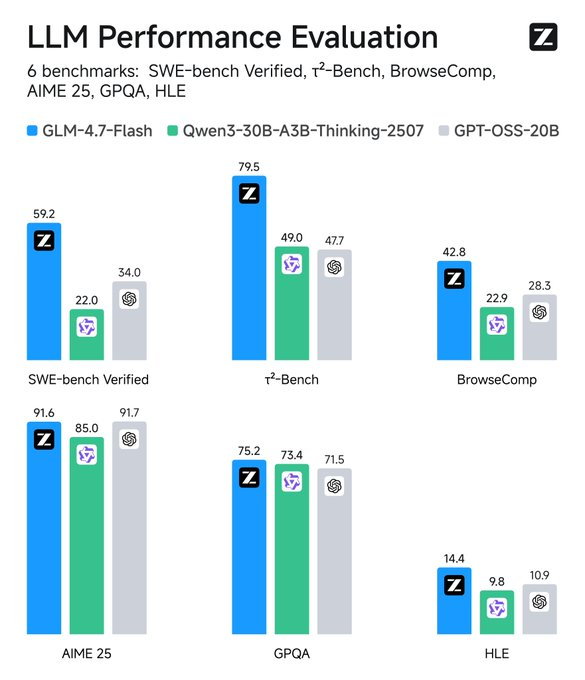
Temel özellikler arasında İngilizce ve Çince desteği, metin üretimi ve sohbet görevleri bulunur. Çok modlu girişleri metin olarak işler ancak yalnızca metin çıkışlarına odaklanır. Sınırlamalar ölçeğinden kaynaklanır—verimli olmasına rağmen, ince ayar yapılmadan niş alanlarda daha büyük modellerle eşleşmeyebilir. Eğitim verisi detayları açıklanmamıştır, ancak değerlendirmeler kodlama ve ajans senaryolarındaki üstünlüğünü doğrulamaktadır.
Kullanıcılar API maliyetlerinden kaçınmak için yerel çalıştırmaları tercih eder. Z.ai, GLM-4.7-Flash için platformları aracılığıyla ücretsiz bir katman sunar, ancak yerel dağıtım harici hizmetlere olan bağımlılığı ortadan kaldırır. Bu yaklaşım, özel uygulamalar geliştiren geliştiriciler, hipotezleri test eden araştırmacılar veya güvenliği önceliklendiren işletmeler için uygundur. Örneğin, donanım kısıtlamalarına uyacak şekilde niceleme seviyelerini kontrol ederek optimum performans sağlarsınız.
GLM-4.7-Flash'ı Yerel Olarak Çalıştırmak İçin Sistem Gereksinimleri
Donanım, model çıkarımında kritik bir rol oynar. LM Studio yönergelerinde belirtildiği gibi, GLM-4.7-Flash temel işlemler için en az 16 GB sistem belleği gerektirir. Ancak, GPU hızlandırma hızı önemli ölçüde artırır.
Ollama varyantları için:
- q4_K_M: 19 GB VRAM
- q8_0: 32 GB VRAM
- bf16: 60 GB VRAM
Hugging Face, verimlilik için torch.bfloat16'yı önerir ve uyumlu NVIDIA GPU'lar (Ampere veya daha yeni mimariler) gerektirir. Yalnızca CPU çıkarımı çalışır ancak büyük bağlamlar için önemli ölçüde yavaşlar.
Yazılım ön koşulları arasında Python 3.8+, pip ve Git bulunur. Transformers gibi çerçeveler ek kurulumlar gerektirir. İşletim sisteminizin GPU kullanımı için CUDA'yı desteklediğinden emin olun—Ubuntu 20.04 veya WSL2 yüklü Windows iyi performans gösterir.
Kaynaklar yetersiz kalırsa, niceleme bellek ayak izini azaltır. llama.cpp veya Unsloth gibi araçlar, gereksinimleri 15-20 GB VRAM'a düşürerek 4-bit veya 2-bit sürümler sunar. Bu esneklik, RTX 4090 gibi tüketici donanımlarında dağıtıma olanak tanır.
Gereksinimler karşılandığında, kurulum yöntemlerini keşfedin. Basitliği için Ollama ile başlayın.
GLM-4.7-Flash'ı Ollama ile Nasıl Kurar ve Kullanırsınız?
Ollama, büyük modelleri yerel olarak çalıştırmak için erişilebilir bir platform sağlar. Niceleme ve API sunumunu otomatik olarak yönetir.
İlk olarak, Ollama'yı yükleyin. İşletim sisteminiz için yürütülebilir dosyayı indirin ve çalıştırın.

Kurulumu ollama --version ile doğrulayın, GLM-4.7-Flash için 0.14.3 veya üzeri bir sürüm olduğundan emin olun.

Ardından, modeli çekin: ollama pull glm-4.7-flash komutunu yürütün.

Daha düşük bellek kullanımı için glm-4.7-flash:q4_K_M gibi varyantları seçin. Bu komut, q4 sürümü için yaklaşık 19 GB indirir.
Modeli etkileşimli olarak çalıştırın: ollama run glm-4.7-flash yazın. "Fibonacci dizisi için Python kodu oluştur." gibi komutlar girin. Model, kodlama güçlerinden yararlanarak gerekçeli çıktılarla yanıt verir.
Programatik erişim için API'yi kullanın. Bir curl isteği gönderin:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
Bu, yanıtla birlikte JSON döndürür. Python'da, ollama kütüphanesiyle entegre edin:
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
JavaScript, ollama npm paketiyle benzer şekilde çalışır.
Modelfile'ı düzenleyerek yapılandırmaları özelleştirin. Kodlama görevlerinde deterministik çıktılar için sıcaklığı 0.7 olarak ayarlayın. Ollama'nın en son modu, gerekirse son gönderileri getirir, ancak burada yerel çıkarıma odaklanın.
Bu yöntem hızlı kurulumlar için uygundur. Ancak, grafik bir arayüz için LM Studio'ya yönelin.
LM Studio'da GLM-4.7-Flash Kurulumu
LM Studio, model yönetimi için kullanıcı dostu bir GUI sunar. İndirin ve kurun.
Model merkezinde "zai-org/glm-4.7-flash" araması yapın. Bağlantılı Hugging Face depolarından niceleme yapılmış bir sürüm—MLX-4bit, 6bit veya 8bit—seçin. İndirme uygulama içinde tamamlanır.
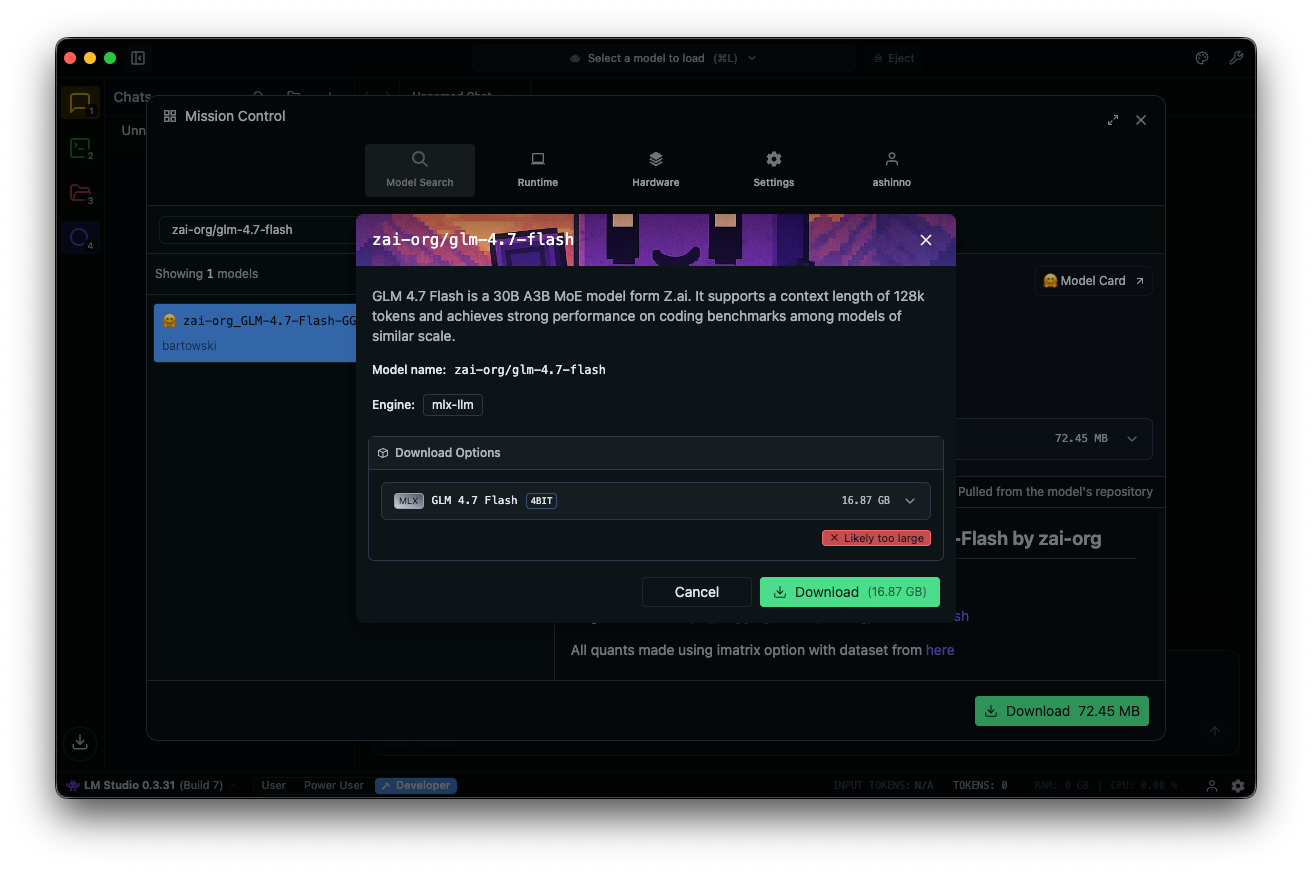
Modeli yükleyin: sohbet arayüzüne gidin, GLM-4.7-Flash'ı seçin ve parametreleri ayarlayın. Adım adım akıl yürütme için düşünmeyi etkinleştirin (varsayılan: true). Sıcaklığı 1, top_k'yi 50, top_p'yi 0.95 olarak ayarlayın ve tekrar cezasını devre dışı bırakın.
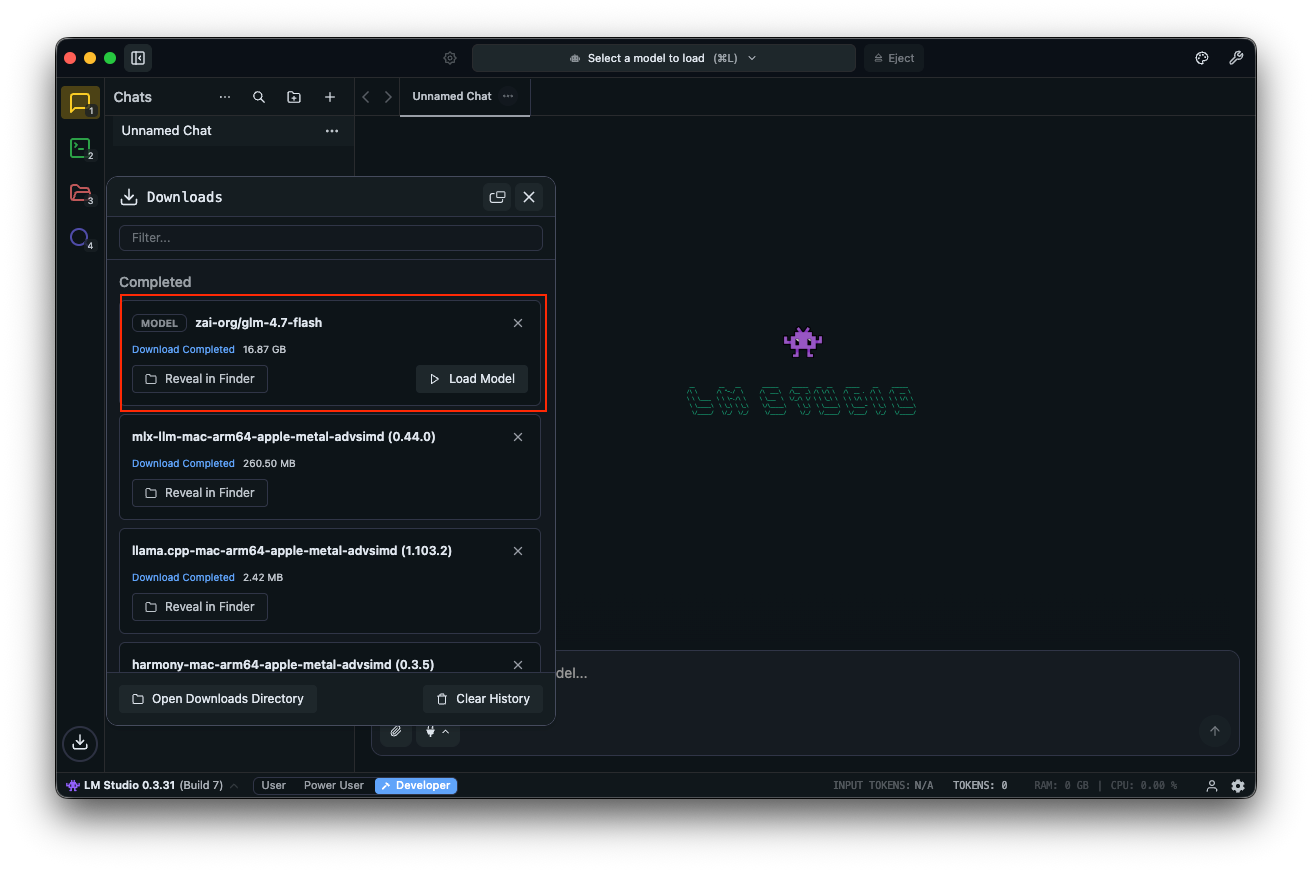
"Kullanıcı kimlik doğrulaması için bir REST API tasarla." gibi komutlarla test edin. LM Studio, performans ayarlamasına yardımcı olan token hızlarıyla çıktıları gösterir.
clear_thinking (varsayılan: false) gibi özel alanlar geçmişi yönetir. MoE modelleri için aktif uzmanları izleyin—A3B, her ileri geçişte üç aktif uzman anlamına gelir ve verimliliği optimize eder.
LM Studio, doğrudan model erişimi için derin bağlantıları destekler. Sorunlar ortaya çıkarsa, sistem belleğini kontrol edin—minimum 16 GB çökmeleri önler.
Bu araç, denemeler için mükemmeldir. Gelişmiş betikleme için Hugging Face ile entegre edin.
GLM-4.7-Flash'ı Hugging Face Transformers ile Kullanma
Hugging Face, hassas kontrol için güçlü kütüphaneler sağlar. Transformers'ı ana daldan yükleyin:
pip install git+https://github.com/huggingface/transformers.git
Modeli yükleyin:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
Girdileri hazırlayın:
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
Oluşturun:
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
Bu kurulum, daha düşük VRAM için bitsandbytes aracılığıyla nicelemeyi destekler. Model yüklemede load_in_4bit=True ekleyin.
Sunum için vLLM veya SGLang kullanın. vLLM'i yükleyin:
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
Bir sunucu çalıştırın:
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
OpenAI uyumlu uç noktalar aracılığıyla erişin. SGLang kaynak kurulumu gerektirir ve benzer adımları izler.
Bu çerçeveler, üretim düzeyinde dağıtımlara olanak tanır. Şimdi, Apidog ile API testini ele alalım.
Yerel GLM-4.7-Flash ile API Testi İçin Apidog'u Entegre Etme
GLM-4.7-Flash'ı Ollama veya vLLM aracılığıyla yayınladığınızda, uç noktaları verimli bir şekilde test edin. Hepsi bir arada bir API platformu olan Apidog, bunu kolaylaştırır.
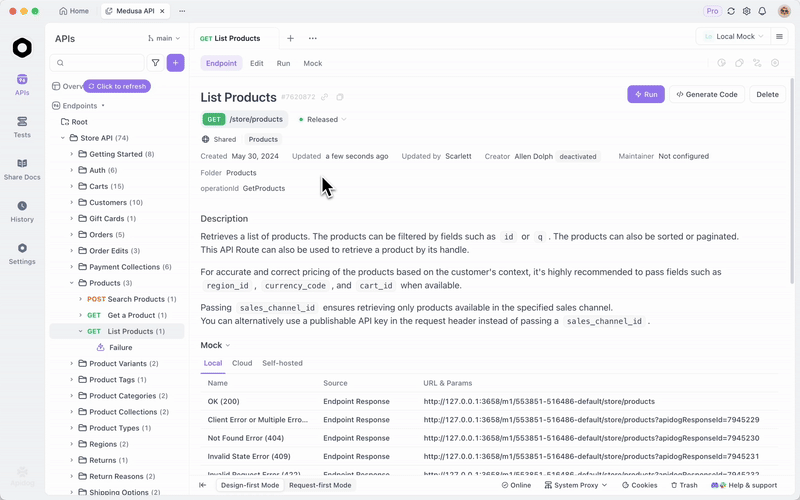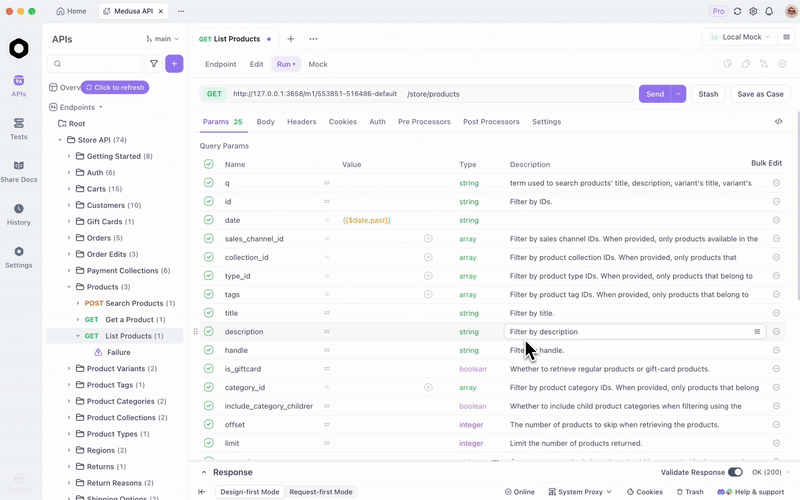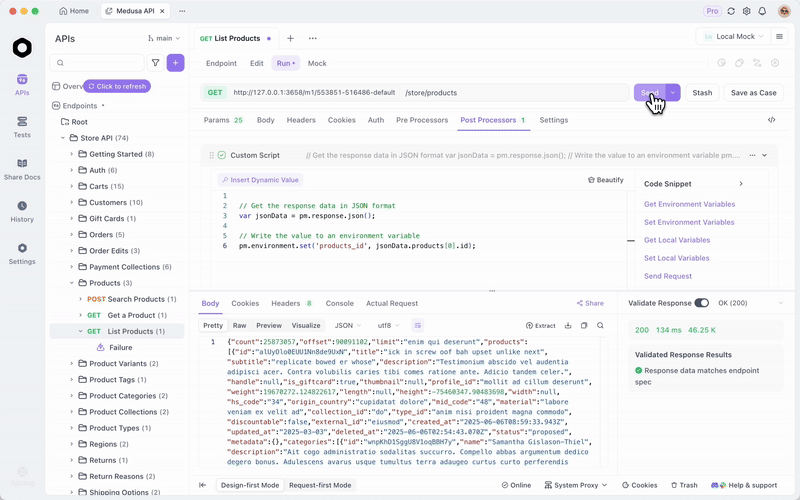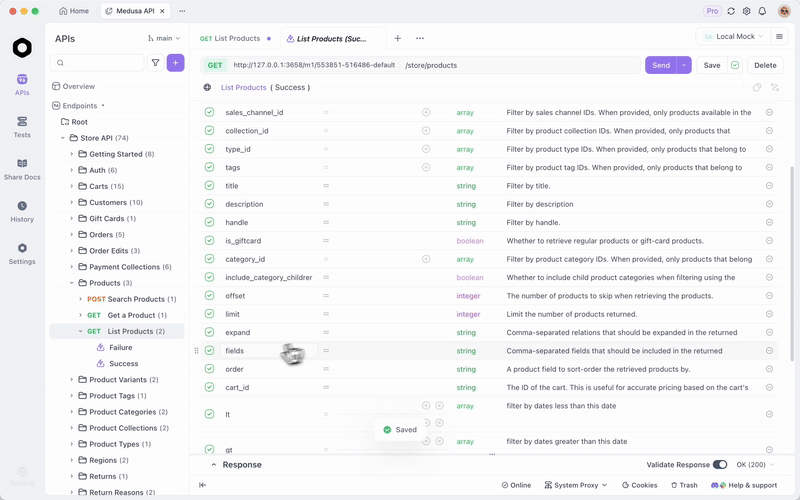
Apidog'u ücretsiz indirin. Yerel modelinizi bir sağlayıcı olarak yapılandırarak AI özelliklerini destekler—uygunsa API anahtarlarını veya doğrudan uç noktaları kullanın.
Apidog'un MCP Sunucusu, kod üretimi için API spesifikasyonlarını kullanarak Cursor gibi IDE'lerle entegre olur. Bu, GLM-4.7-Flash'ın kodlama yeteneklerine geri döner—ajans çıktılarını doğrudan test edin.
Örneğin, yerel sunucunuzu sorgulayın ve yanıtları doğrulayın. Bu, uygulamalarda güvenilirliği sağlar.
Temel bilgiler üzerine inşa ederek optimizasyona geçin.
GLM-4.7-Flash Performansını Optimize Etmek İçin Gelişmiş İpuçları
Görevler için parametreleri ince ayarlayın. Kodlama için sıcaklığı 0.7, yaratıcı yazma için 1.0 olarak ayarlayın. Çeşitliliği dengelemek için top_p 0.95 kullanın.
llama.cpp aracılığıyla GGUF formatlarıyla daha fazla niceleme yapın. llama.cpp'yi CUDA ile derleyin, ardından dönüştürün:
./llama-gguf-split --model GLM-4.7-Flash.gguf
Şablon desteği için --jinja ile çalıştırın.
Uzun bağlamları yönetin: 128K'yi aşarsa girdileri bölün. Karmaşık sorgular için düşünmeyi etkinleştirin.
Metrikleri izleyin: TensorBoard gibi araçlar gecikmeyi takip eder. Temel çizgilerle karşılaştırın—GLM-4.7-Flash, SWE-bench'te rakiplerini 37.2 puan farkla geride bırakır.
Araçları entegre edin: Ajans davranışı için komutlara işlev çağrısı ekleyin.
Güvenlik: Veri sızıntılarını önlemek için izole ortamlarda çalıştırın.
Bu stratejiler faydayı en üst düzeye çıkarır. Ardından uygulamaları değerlendirin.
Yaygın Sorunları Giderme
Bellek yetersizliği hatalarıyla mı karşılaşıyorsunuz? Parti boyutunu azaltın veya daha düşük niceleme yapın.
Yavaş çıkarım mı? GPU'yu yükseltin veya vLLM gibi daha hızlı çerçeveler kullanın.
Uyumluluk sorunları mı? Transformers'ı ana sürüme güncelleyin.
Ollama başarısız olursa, 11434 numaralı bağlantı noktasının kullanılabilirliğini kontrol edin.
LM Studio mu çöküyor? Model bütünlüğünü doğrulayın.
Bunları proaktif olarak ele alın.
Sonuç: GLM-4.7-Flash ile İş Akışınızı Güçlendirin
GLM-4.7-Flash'ı yerel olarak çalıştırmak, güçlü yapay zeka yeteneklerinin kilidini açar. Ollama'nın kolaylığından Hugging Face'in esnekliğine kadar birçok seçenek mevcuttur. Sorunsuz API yönetimi için Apidog'u dahil edin—kurulumunuzu yükseltmek için ücretsiz indirin.
Teknoloji geliştikçe, bunun gibi modeller performans ve erişilebilirliği birleştirir. Bu adımları uygulayarak, verimli, özel AI dağıtımları elde edersiniz. Parametrelerdeki veya araçlardaki küçük ayarlamalar önemli iyileştirmeler sağlayarak rutin görevleri kolaylaştırılmış süreçlere dönüştürür.