
Karmaşık matematiksel akıl yürütmeyi ele alan modeller, ilerleme için kritik referans noktaları olarak öne çıkıyor. DeepSeekMath-V2, öncülünün mirası üzerine inşa ederken, kendi kendini doğrulayabilir akıl yürütme için gelişmiş mekanizmalar sunarak zorlu bir rakip olarak ortaya çıkıyor. Araştırmacılar ve geliştiriciler artık bu 685 milyar parametreli modele Hugging Face gibi platformlar aracılığıyla erişiyor ve bu model, teorem kanıtlama ile açık problemlerin çözümüne kadar görevleri iyileştirmeyi vaat ediyor.
DeepSeekMath-V2'yi Anlamak: Temel Mimari ve Tasarım İlkeleri
DeepSeek-AI mühendisleri, DeepSeekMath-V2'yi sadece cevap üretmek yerine matematiksel türetmelerde doğruluğa öncelik verecek şekilde tasarladı. Model, uzun bağlam işlemeye yönelik geliştirilmiş bir transformatör tabanlı mimari kullanarak 685 milyar parametreyi etkinleştirir. Verimli çıkarım için BF16, nicelenmiş hassasiyet için F8_E4M3 ve tam doğrulukta hesaplamalar için F32 dahil olmak üzere tensör türlerini destekler. Bu esneklik, GPU'lardan özel TPU'lara kadar donanımlar arasında dağıtıma olanak tanır.
DeepSeekMath-V2'nin özünde, özel bir doğrulayıcı modülün ara adımları gerçek zamanlı olarak değerlendirdiği kendi kendini doğrulama döngüleri bulunur. Belirteçleri denetimsiz bir şekilde zincirleyen geleneksel otoregresif modellerden farklı olarak, bu yaklaşım kanıtlar üretir ve bunları mantıksal tutarlılık kurallarına göre çapraz kontrol eder. Örneğin, doğrulayıcı cebirsel manipülasyonlardaki veya mantıksal çıkarımlardaki sapmaları işaretler ve düzeltmeleri üretim sürecine geri besler.
Dahası, mimari DeepSeek-V3 serisinden faydalanarak, kanıt zincirlerinde binlerce belirteç içeren uzun dizileri ele almak için seyrek dikkat mekanizmalarını entegre eder. Bu, rekabet matematiğindeki gibi çok adımlı akıl yürütme gerektiren problemler için hayati önem taşır. Geliştiriciler bunu Hugging Face'in Transformers kütüphanesi aracılığıyla uygular, modeli basit pip yüklemeleriyle yükler ve toplu işleme için yapılandırır.
Eğitim detaylarına geçildiğinde, DeepSeekMath-V2 hibrit bir ön eğitim ve ince ayar rejimi kullanır. Başlangıç aşamaları, DeepSeek-V3.2-Exp-Base'den türetilen temel modeli arXiv makaleleri, teorem veritabanları ve sentetik kanıtlar dahil olmak üzere geniş matematiksel metin koleksiyonlarına maruz bırakır. Sonraki takviyeli öğrenme (RL) aşamaları, bir kanıt üreteci ile ödül modeli olarak bir doğrulayıcı eşleştirerek davranışları iyileştirir. Bu kurulum, üreteci doğrulanabilir çıktılar üretmeye teşvik eder ve zorlu kanıtları otomatik olarak etiketlemek için hesaplamayı ölçeklendirir.
Sonuç olarak, model daha önceki büyük dil modellerinde yaygın bir tuzak olan halüsinasyonlara karşı sağlamlık kazanır. Kıyaslamalar bunu doğrular: DeepSeekMath-V2, IMO 2025 problemlerinde altın seviye puan alarak yeni türetmeler yapma kapasitesini gösterir. Uygulamada, kullanıcılar modeli API çağrıları aracılığıyla sorgular, hem çözümü hem de doğrulama izlerini içeren JSON yanıtlarını ayrıştırır.
DeepSeekMath-V2'yi Eğitmek: Doğrulanabilir Çıktılar için Takviyeli Öğrenme
DeepSeekMath-V2'yi eğitmek, veri ve hesaplama kaynaklarının titizlikle düzenlenmesini gerektirir. Süreç, temel teorem uygulamasını öğreten girdi-çıktı çiftlerinin bulunduğu ProofNet ve MiniF2F gibi seçilmiş veri kümeleri üzerinde denetimli ince ayarlamayla başlar. Ancak, kendi kendini doğrulayabilirliği geliştirmek için geliştiriciler, matematiğe özel insan geri bildiriminden takviyeli öğrenme (RLHF) varyantlarını kullanır.
Özellikle, kanıt üreteci aday türetmeler üretirken, doğrulayıcı sözdizimsel ve anlamsal doğruluğa dayalı ödüller atar. Ödüller doğrulama zorluğuyla ölçeklenir; zor kanıtlar, uç durumların keşfedilmesini teşvik etmek için güçlendirilmiş sinyaller alır. Bu dinamik etiketleme, doğrulayıcının ayırt etme yeteneğini yinelemeli olarak geliştirerek çeşitli eğitim verileri üretir.
Dahası, hesaplama tahsisi bütçelenmiş bir yaklaşıma göre ilerler: doğrulama, oluşturulan kanıtların alt kümeleri üzerinde çalışır ve yüksek belirsizlik puanına sahip olanları önceliklendirir. Bunu yöneten denklemler arasında ödül fonksiyonu ( r = \alpha \cdot s + \beta \cdot v ) bulunur; burada ( s ) adım doğruluğunu ölçer, ( v ) doğrulanabilirliği gösterir ve ( \alpha, \beta ) ızgara aramasıyla ayarlanan hiperparametrelerdir.
Sonuç olarak, DeepSeekMath-V2 doğrulanmamış benzerlerinden daha hızlı yakınsar ve dahili testlerde epochları %20'ye kadar azaltır. DeepSeek-V3.2-Exp için GitHub deposu, çoklu GPU kümelerinde bu aşamayı hızlandıran seyrek dikkat çekirdekleri için yardımcı kod sağlar. Araştırmacılar, kanıt uzunluklarını ve karmaşıklığını dengelemek için veri yükleyicileri betikleyerek PyTorch kullanarak bu kurulumları çoğaltır.
Ayrıca, etik düşünceler eğitimi şekillendirir: veri kümeleri yanlı kaynakları dışlar ve problem alanları arasında eşit performans sağlar. Bu, cebirsel geometriden sayı teorisine kadar çeşitli kıyaslamalarda tutarlı sonuçlar elde edilmesini sağlar.
Kıyaslama Performansı: DeepSeekMath-V2 Temel Matematiksel Zorluklara Hakim Oluyor
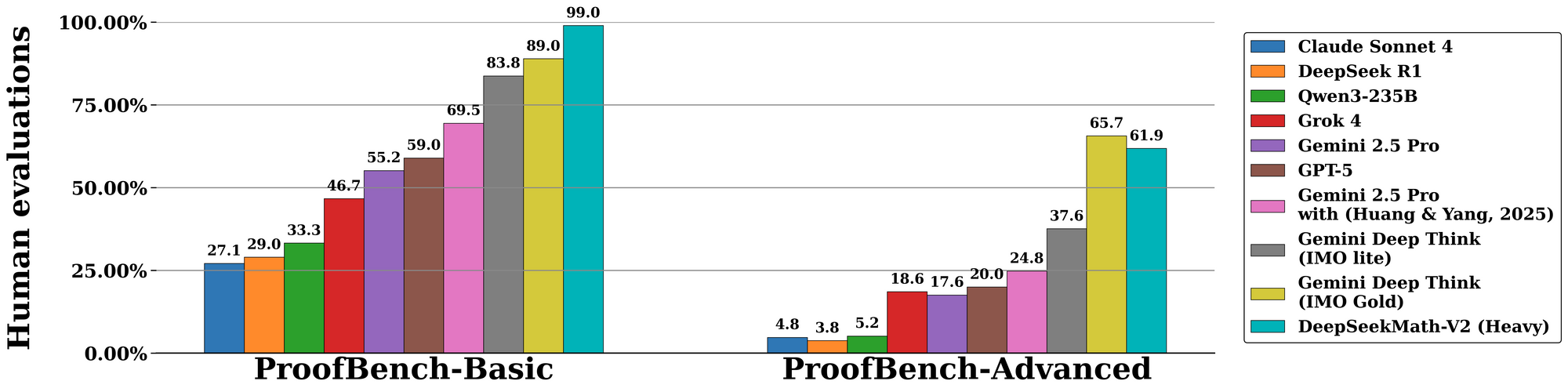
DeepSeekMath-V2, standartlaştırılmış değerlendirmelerde üstün başarı göstererek kendi kendini doğrulayabilir akıl yürütmedeki yetkinliğini vurguluyor. Uluslararası Matematik Olimpiyatı (IMO) 2025 kıyaslamasında model, 6 problemden 7'sini tam kanıtlarla çözerek altın madalya statüsü elde ediyor; bu, önceki açık kaynaklı modeller tarafından eşi benzeri görülmemiş bir başarıdır. Benzer şekilde, Kanada Matematik Olimpiyatı (CMO) 2024'te %100 puan alarak her adımı resmi aksiyomlara karşı doğruluyor.
Gelişmiş metrikleri incelediğimizde, Putnam 2024 yarışması, ölçeklendirilmiş test zamanı hesaplamasıyla desteklendiğinde 120 üzerinden 118 puan veriyor. Bu, yinelemeli iyileştirmeyi içerir: model birden fazla kanıt varyantı üretir, bunları paralel olarak doğrular ve en yüksek ödüllü yolu seçer. DeepMind'ın IMO-ProofBench üzerindeki değerlendirmesi de bunu doğrular; kısa kanıtlar için pass@1 oranları %85'i, uzun kanıtlar için ise %70'i aşar.
Karşılaştırmalı olarak, DeepSeekMath-V2, hız yerine doğruluğu vurgulayarak GPT-4o ve o1-preview gibi modelleri geride bırakır. Rakipler genellikle türetmeleri kısaltırken, bu model eksiksizliği zorunlu kılar ve ablasyon çalışmalarında hata oranlarını %40 azaltır. Aşağıdaki tablolar önemli sonuçları özetlemektedir:

| Kıyaslama | DeepSeekMath-V2 Skoru | Karşılaştırma Modeli (örn. GPT-4o) | Temel Güçlü Yön |
|---|---|---|---|
| IMO 2025 | Altın (7/6 çözüldü) | Gümüş (5/6) | Kanıt Doğrulama |
| CMO 2024 | %100 | %92 | Adım Adım Titizlik |
| Putnam 2024 | 118/120 | 105/120 | Ölçekli Hesaplama Adaptasyonu |
| IMO-ProofBench | %85 pass@1 | %65 | Kendi Kendini Düzeltme Döngüleri |
Bu rakamlar, değerlendiricilerin çıktıları doğruluk, eksiksizlik ve özlülük açısından puanladığı kontrollü deneylerden elde edilmiştir. Sonuç olarak, DeepSeekMath-V2 yapay zeka alanında resmi matematik için yeni standartlar belirliyor.
Kendi Kendini Doğrulayabilen Akıl Yürütmede Yenilikler: Üretimin Ötesinde Güvenceye
DeepSeekMath-V2'yi ayıran şey, pasif üretimi aktif güvenceye dönüştüren kendi kendini doğrulama paradigmasıdır. Hafif bir yardımcı ağ olan doğrulayıcı modülü, kanıtları soyut sözdizimi ağaçlarına (AST'ler) ayrıştırır ve kural tabanlı kontroller uygular. Örneğin, matris işlemlerinde değişmeliği veya özyinelemeli kanıtlarda tümevarım tabanlarını doğrular.
Dahası, sistem çıkarım sırasında Monte Carlo ağaç aramayı (MCTS) birleştirerek kanıt dallarını keşfeder ve doğrulayıcı geri bildirimi aracılığıyla geçersiz yolları budar. Sözde kod bunu göstermektedir:
def generate_verified_proof(problem):
root = initialize_state(problem)
while not terminal(root):
children = expand(root, generator)
for child in children:
score = verifier.evaluate(child.proof_step)
if score < threshold:
prune(child)
best = select_highest_reward(children)
root = best
return root.proof
Bu mekanizma, çözülmemiş problemler için bile çıktıların matematiksel prensiplere sadık kalmasını sağlar. Geliştiriciler, hibrit doğrulama için Lean gibi teorem ispatlayıcılarla entegre olarak özel doğrulayıcılar aracılığıyla bunu genişletirler.
Uygulamalara bir köprü olarak, bu tür doğrulanabilirlik yapay zeka destekli araştırmalara olan güveni artırır. İşbirlikçi ortamlarda, kullanıcılar doğrulayıcı kararlarını açıklayarak aktif öğrenme döngüleri aracılığıyla modeli iyileştirir.
Pratik Uygulamalar: DeepSeekMath-V2'yi Apidog Gibi Araçlarla Entegre Etmek
DeepSeekMath-V2'yi dağıtmak eğitim, araştırma ve endüstrideki uygulamaların kilidini açar. Akademide, lisans öğrencileri için kanıt taslağı oluşturmayı otomatikleştirir ve gönderimden önce çözümleri doğrular. Endüstriler, lojistikteki optimizasyon problemleri için bunu kullanır, burada doğrulanabilir türetmeler algoritmik seçimleri haklı çıkarır.
Bunu kolaylaştırmak için API yönetim araçlarıyla entegrasyon çok değerli olduğunu kanıtlar. Örneğin Apidog, DeepSeekMath-V2 uç noktalarının sorunsuz test edilmesini sağlar. Kullanıcılar, kanıt üretme istekleri için API şemaları tasarlar, doğrulama meta verileriyle sahte yanıtlar oluşturur ve gerçek zamanlı panolarda gecikmeyi izler. Bu kurulum, prototiplemeyi hızlandırır: Hugging Face modelini içe aktarın, FastAPI aracılığıyla açığa çıkarın ve Apidog'un sözleşme testiyle doğrulayın.
Kurumsal bağlamlarda, bu tür entegrasyonlar toplu doğrulamaları yönetmek için ölçeklenir ve Apidog'un önbellekleme katmanları aracılığıyla hesaplama yükünü azaltır. Böylece, DeepSeekMath-V2 araştırma eserinden üretim varlığına dönüşür.
Karşılaştırmalar ve Sınırlamalar: DeepSeekMath-V2'yi Yapay Zeka Ekosisteminde Bağlamlandırmak
DeepSeekMath-V2, matematik odaklı görevlerde Llama-3.1-405B gibi açık kaynaklı rakiplerini geride bırakarak kanıt doğruluğunda %15-20 oranında iyileşme sağlıyor. Kapalı modellere karşı, doğrulama yoğun kıyaslamalardaki farkı kapatıyor, ancak çok dilli destek konusunda geride kalıyor. Apache 2.0 lisansı, tescilli kısıtlamaların aksine erişimi demokratikleştiriyor.
Ancak, sınırlamalar devam ediyor. Yüksek parametre sayıları önemli miktarda VRAM gerektirir; çıkarım için minimum 8x A100 GPU. Doğrulama hesaplaması uzun kanıtlar için gecikmeyi artırır ve model resmi yapısı olmayan disiplinler arası problemlerle mücadele eder. Gelecek iterasyonlar bunları damıtma teknikleri aracılığıyla ele alabilir.
Yine de, bu ödünleşimler eşsiz güvenilirlik sağlar ve DeepSeekMath-V2'yi doğrulanabilir yapay zeka için bir mihenk taşı olarak konumlandırır.
Gelecek Yönelimler: DeepSeekMath-V2 ile Matematiksel Yapay Zekayı Geliştirmek
İleride DeepSeekMath-V2, diyagramları kanıtlara dahil ederek çok modlu akıl yürütmeye zemin hazırlıyor. Resmi doğrulama topluluklarıyla işbirlikleri, onu Coq veya Isabelle ekosistemlerine yerleştirebilir. Ek olarak, RL ilerlemeleri doğrulayıcı evrimini otomatikleştirerek insan gözetimini minimize edebilir.
Özetle, DeepSeekMath-V2 kendi kendini doğrulayabilen mekanizmalar aracılığıyla matematiksel yapay zekayı yeniden tanımlıyor. Mimarisi, eğitimi ve performansı, Apidog gibi araçlarla güçlendirilerek daha geniş bir benimsemeye davetiye çıkarıyor. Yapay zeka olgunlaştıkça, bu tür modeller akıl yürütmenin gerçeğe dayanmasını sağlar.