
Yazılım geliştiricileri ve araştırmacılar, yapay zekada görsel verileri metinsel işlemeyle birleştirmenin yollarını sürekli olarak arıyorlar. DeepSeek-AI, bu zorluğun üstesinden bağlamsal optik sıkıştırmaya odaklanan bir model olan DeepSeek-OCR ile geliyor. 20 Ekim 2025'te piyasaya sürülen bu araç, görme kodlayıcılarını (vision encoders) bir LLM merkezli perspektiften inceliyor ve görsel bilgiyi metinsel bağlamlara sıkıştırma sınırlarını zorluyor. Mühendisler, belge dönüştürme ve görüntü açıklaması gibi karmaşık görevleri verimli bir şekilde ele almak için bu tür modelleri entegre ediyor.
Bağlamsal optik sıkıştırma, görsel kodlayıcıların görüntü verilerini büyük dil modellerinin (LLM'ler) etkili bir şekilde işleyebileceği kompakt metinsel temsiller haline getirdiği süreci ifade eder. Geleneksel OCR sistemleri metin çıkarır ancak genellikle düzenler veya mekansal ilişkiler gibi bağlamsal nüansları göz ardı eder. DeepSeek-OCR, temel ayrıntıları koruyan sıkıştırmaya vurgu yaparak bu sınırlamaların üstesinden gelir. Model, çeşitli görüntü boyutlarını işleme konusunda esneklik sağlayan birden fazla çözünürlük modunu destekler. Ayrıca, görüntüler içinde hassas konum referansı için konumlandırma (grounding) yeteneklerini entegre eder.
DeepSeek-AI'deki araştırmacılar, görme kodlayıcılarının LLM verimliliğine nasıl katkıda bulunduğunu araştırmak için bu modeli tasarladılar. Görsel girdileri daha az jetona (token) sıkıştırarak, sistem doğruluğu korurken hesaplama yükünü azaltır. Bu yaklaşım, yüksek çözünürlüklü görüntülerin önemli kaynaklar gerektirdiği senaryolarda özellikle faydalıdır. Örneğin, 1280×1280'lik bir görüntüyü işlemek genellikle yoğun bellek gerektirir, ancak DeepSeek-OCR'ın büyük modu bunu yalnızca 400 görme jetonuyla halleder.
Projenin GitHub deposu, model ve dokümantasyonu için birincil kaynak olarak hizmet vermektedir. Kullanıcılar, model ağırlıklarına Hugging Face aracılığıyla erişerek mevcut işlem hatlarına kolay entegrasyon sağlarlar. Yapay zeka geliştikçe, DeepSeek-OCR gibi modeller verimli veri sıkıştırmanın önemini vurgulamaktadır. Temel metin çıkarımından bağlamı anlayan işlemeye geçiş, önemli bir ilerlemeyi işaret etmektedir. Sonuç olarak, geliştiriciler belge otomasyonundan görsel soru cevaplamaya kadar çeşitli görevlerde daha iyi sonuçlar elde etmektedir.
Bağlamsal Optik Sıkıştırmanın Temelleri
Bağlamsal optik sıkıştırma, modern yapay zekada kritik bir teknik olarak ortaya çıkmaktadır. Görme sistemleri görüntüleri yakalar, ancak LLM'ler metinsel girdilere ihtiyaç duyar. Bu nedenle, kodlayıcılar piksel verilerini anahtar bilgileri kaybetmeden anlam ileten jetonlara sıkıştırır. DeepSeek-OCR, LLM merkezli tasarıma odaklanarak bunu örneklendirir. Piksel düzeyinde doğruluğa öncelik veren geleneksel yöntemlerin aksine, bu model jeton verimliliğini optimize eder.
Aktif sıkıştırma birkaç adım içerir. İlk olarak, kodlayıcı görüntüyü doğal çözünürlüklerinde analiz eder. Ardından, metinsel öğeleri, düzenleri ve şekilleri tanımlar. Daha sonra, sıkıştırılmış temsiller üretir. Bu süreç, LLM'lerin görsel bağlamları doğru bir şekilde yorumlamasını sağlar. Örneğin, bir belgede model, başlıkları ana metinden ayırır ve hiyerarşik yapıları korur.
Ayrıca, sıkıştırma gerçek zamanlı uygulamalarda gecikmeyi azaltır. Sistemler daha az jeton işler, bu da daha hızlı çıkarım süreleri sağlar. DeepSeek-OCR'ın "Gundam" olarak adlandırılan dinamik çözünürlük modu, kapsamlı analiz için birden fazla görüntü segmentini birleştirir. Bu mod, yoğun metin veya seyrek diyagramlar gibi değişen içerik yoğunluklarına uyum sağlar.

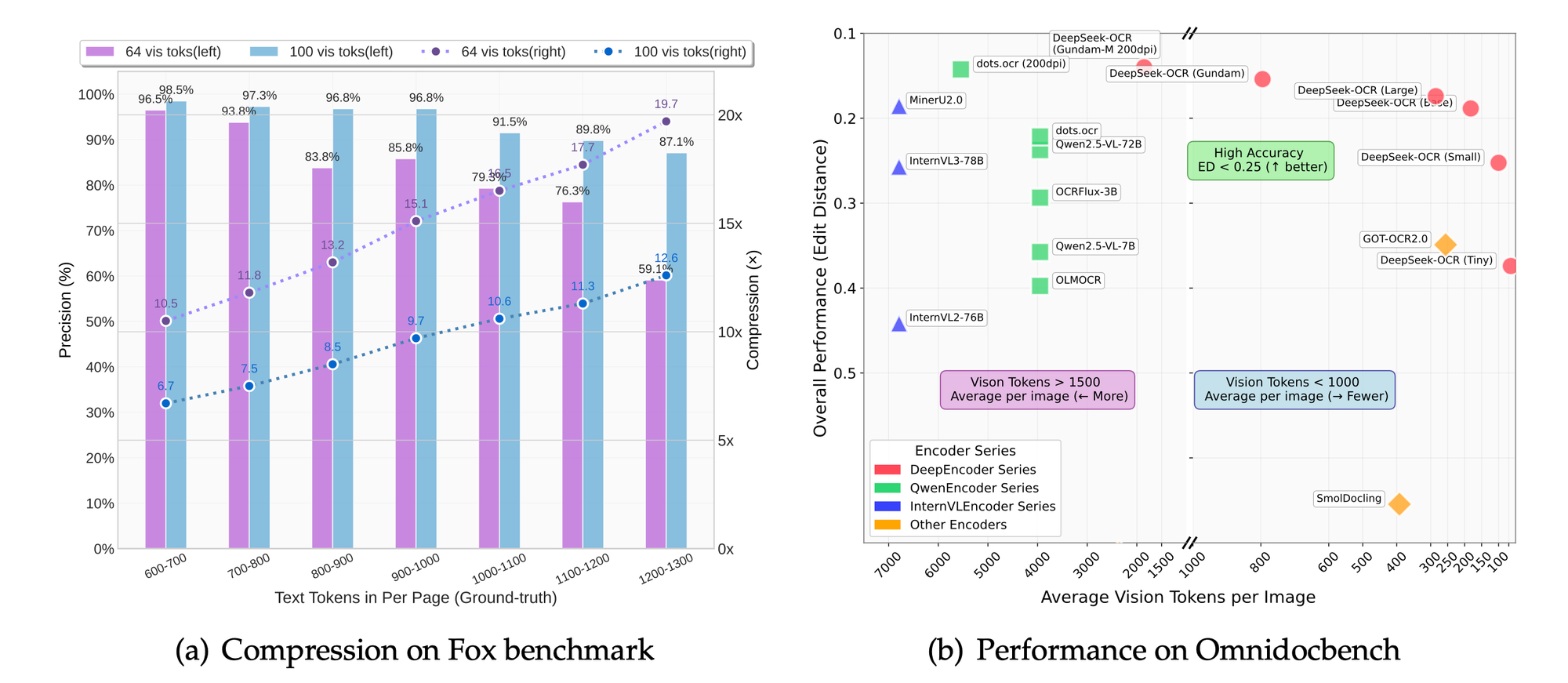
Sıkıştırmadaki teknik zorluklar, ayrıntıların korunması ile jeton azaltma arasındaki dengeyi içerir. Aşırı sıkıştırma nüansların kaybolma riskini taşırken, yetersiz sıkıştırma maliyetleri artırır. DeepSeek-OCR bunu ölçeklenebilir modlarla ele alır: küçük (512×512, 64 jeton), orta (640×640, 100 jeton), temel (1024×1024, 256 jeton) ve büyük (1280×1280, 400 jeton). Her mod, hızlı önizlemelerden ayrıntılı çıkarımlara kadar belirli kullanım durumlarına uygundur.
Ayrıca, model mekansal farkındalık için konumlandırma etiketlerini (grounding tags) içerir. Kullanıcılar, öğeleri hassas bir şekilde konumlandırmak için "<|ref|>xxxx<|/ref|>" gibi referanslar belirtir. Bu özellik, artırılmış gerçeklik veya etkileşimli belgelerdeki uygulamaları geliştirir. Sonuç olarak, DeepSeek-OCR yalnızca verileri sıkıştırmakla kalmaz, aynı zamanda bağlamsal meta verilerle zenginleştirir.
Tesseract gibi önceki OCR teknolojileriyle karşılaştırıldığında, DeepSeek-OCR üstün doğruluk için derin öğrenmeden yararlanır. Geleneksel sistemler kural tabanlı kalıplara dayanırken, bu model çeşitli veri kümeleri üzerinde eğitilmiş sinir ağlarını kullanır. Sonuç olarak, el yazısı metinleri, bozuk görüntüleri ve çok dilli içeriği daha etkili bir şekilde işler.
Pratik uygulamalara geçildiğinde, bu temelleri anlamak geliştiricilerin modelin yeniliklerini takdir etmesini sağlar. Bir sonraki bölüm, DeepSeek-OCR'ı öne çıkaran belirli özelliklere derinlemesine inecektir.
DeepSeek-OCR'ın Temel Özellikleri
DeepSeek-OCR, gelişmiş OCR ihtiyaçlarını karşılayan sağlam bir özellik yelpazesi sunar. Model, kullanıcıların görevleri için uygun ölçeği seçmelerine olanak tanıyan doğal çözünürlük modlarını destekler. Örneğin, küçük mod, düşük kaynaklı ortamlar için ideal olan 512×512 görüntüleri yalnızca 64 görme jetonuyla işler.
Ek olarak, dinamik "Gundam" modu, n×640×640 segmentleri 1024×1024 genel bakışla birleştirir. Bu yaklaşım, sistemi aşırı yüklemeden ultra yüksek çözünürlüklü belgelerin işlenmesini sağlar. Kullanıcılar, taranmış kitaplar veya mimari çizimlerle uğraşırken bu esneklikten faydalanır.
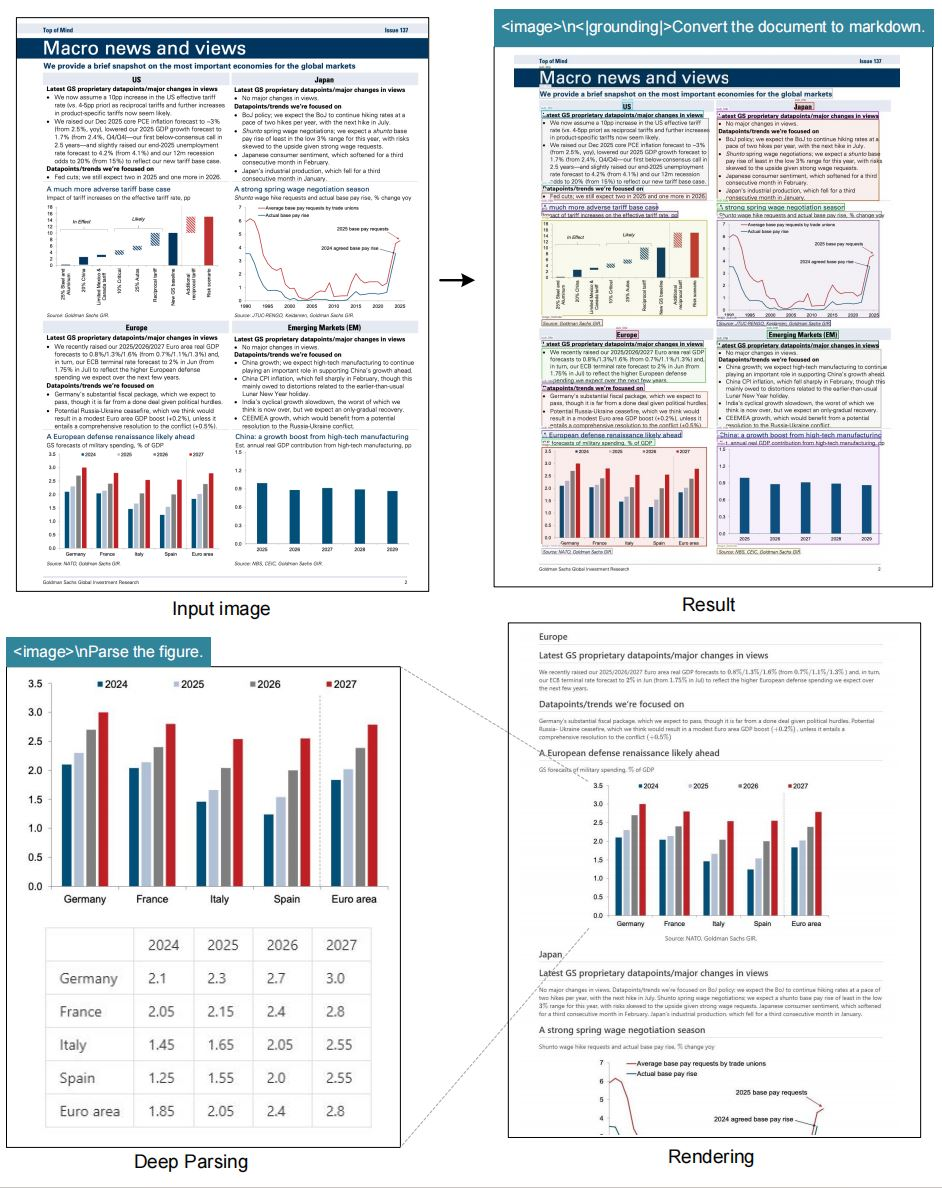
Model, OCR görevlerinde üstün performans gösterir ve görüntüleri yüksek doğrulukla metne dönüştürür. Ayrıca, belgeleri tablo ve listeler gibi yapıları koruyarak markdown formatına dönüştürür. Dahası, şekilleri ayrıştırır, grafiklerden veya çizelgelerden açıklamaları ve veri noktalarını çıkarır.
Genel görüntü açıklaması başka bir temel özelliği oluşturur. Model, erişilebilirlik araçları veya içerik indeksleme için faydalı olan ayrıntılı açıklamalar oluşturur. Konum referansı, görüntülerdeki belirli öğeler hakkında sorgulara izin vererek değer katar.
DeepSeek-OCR, vLLM ve Transformers gibi çerçevelerle sorunsuz bir şekilde entegre olur. Bu uyumluluk, A100-40G gibi üst düzey GPU'larda saniyede yaklaşık 2500 jetona ulaşan PDF işleme ile çıkarımı hızlandırır.
Güvenlik ve verimlilik hususları, özellik setine rehberlik eder. Model, gereksiz bağımlılıklardan kaçınır ve çekirdek kütüphanelere odaklanır. Sonuç olarak, dağıtımlar hafif ve ölçeklenebilir kalır.
Bu özellikler, DeepSeek-OCR'ı yapay zeka uygulayıcıları için çok yönlü bir araç olarak konumlandırır. İlerleyen bölümlerde, mimari bölümü bu yeteneklerin nasıl bir araya geldiğini açıklayacaktır.
DeepSeek-OCR Mimarisi: Teknik Bir Analiz
DeepSeek-AI, DeepSeek-OCR'ın mimarisini LLM merkezli bir görme kodlayıcısı etrafında tasarlar. Sistem, görsel girdileri LLM'lerin verimli bir şekilde sindirebileceği metinsel jetonlara sıkıştırır. Özünde, kodlayıcı görüntülerden özellik çıkarmak için evrişimsel katmanlar kullanır.
Süreç, görüntü ön işleme ile başlar. Model, girdileri seçilen çözünürlüğe göre yeniden boyutlandırır ve normalizasyon uygular. Ardından, bir görme transformatörü görüntüyü yamalara böler ve her birini gömülmelere (embeddings) kodlar.
Bu gömülmeler, dikkat mekanizmaları aracılığıyla sıkıştırmaya tabi tutulur. Çok başlı dikkat, metin hizalaması veya şekil sınırları gibi görsel öğeler arasındaki bağımlılıkları yakalar. Katman normalizasyonu ve ileri beslemeli ağlar, temsilleri iyileştirir.

LLM ile entegrasyon, jeton birleştirme yoluyla gerçekleşir. Sıkıştırılmış görme jetonları, metin istemlerinin önüne eklenerek birleşik işlemeyi sağlar. Bu tasarım, bağlam uzunluğunu en aza indirir ve bellek kullanımını azaltır.
Konumlandırma (grounding) için, <|grounding|> gibi özel jetonlar mekansal modülleri etkinleştirir. Bu modüller, sorguları sınırlayıcı kutular veya ısı haritaları kullanarak görüntü koordinatlarına eşler.
Eğitim, eşleştirilmiş görüntüler ve metinler içeren veri kümeleri üzerinde ince ayar yapmayı içerir. Kayıp fonksiyonları hem sıkıştırma oranını hem de yeniden yapılandırma doğruluğunu optimize eder. Model, gereksiz pikselleri atarak belirgin özelliklere öncelik vermeyi öğrenir.
Parametreler açısından DeepSeek-OCR, boyutu performansla dengeler. Belirli sayılar açıklanmamış olsa da, Hugging Face deposu modlar arasında verimli ölçeklendirmeyi göstermektedir.
Mimarideki zorluklar arasında değişken çözünürlüklerin işlenmesi yer alır. Dinamik mod, birden çok geçişten gelen gömülmeleri birleştirerek bunu ele alır. Sonuç olarak, sistem ölçekler arasında tutarlılığı korur.

Bu mimari, DeepSeek-OCR'ın sıkıştırma görevlerinde geleneksel modellerden daha iyi performans göstermesini sağlar. Bir sonraki bölüm, kullanıcıları kurulum boyunca yönlendirerek kurulumu tekrarlayabilmelerini sağlayacaktır.
DeepSeek-OCR Kurulum Rehberi
DeepSeek-OCR'ı kurmak uyumlu bir ortam gerektirir. Kullanıcılar, CUDA 11.8 ve Torch 2.6.0'ın mevcut olduğundan emin olarak başlar. Süreç, depoyu GitHub'dan klonlamakla başlar.
Komutu çalıştırın: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git. DeepSeek-OCR klasörüne gidin.
Ardından, bir Conda ortamı oluşturun: conda create -n deepseek-ocr python=3.12.9 -y. conda activate deepseek-ocr ile etkinleştirin.
Torch ve ilgili paketleri yükleyin: pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118.
Belirtilen sürümden vLLM-0.8.5 wheel'i indirin. Yükleyin: pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl.
Ardından, gereksinimleri yükleyin: pip install -r requirements.txt. Son olarak, flash-attention'ı ekleyin: pip install flash-attn==2.7.3 --no-build-isolation.
vLLM ve Transformers'ı birleştirmenin hatalara neden olabileceğini unutmayın, ancak kullanıcılar dokümantasyona göre bunları göz ardı eder.
Bu kurulum, sistemi çıkarım için hazırlar. Ortam hazır olduğunda, kullanıcılar kullanım örneklerine geçer.
Performans Metrikleri ve Kıyaslama Değerlendirmeleri
DeepSeek-OCR etkileyici hızlara ulaşır. Bir A100-40G GPU'da, PDF eşzamanlılığı saniyede 2500 jetona ulaşır. Bu metrik, büyük ölçekli görevler için uygunluğunu vurgular.
Fox ve OmniDocBench gibi kıyaslamalar doğruluğu değerlendirir. Model, OCR hassasiyeti, düzen koruma ve şekil ayrıştırmada üstündür. Karşılaştırmalar, temel çizgilere kıyasla üstün sıkıştırma oranları göstermektedir.
Çözünürlük modlarında, daha yüksek ayarlar jeton maliyetiyle daha iyi ayrıntı koruma sağlar. Temel mod, çoğu uygulama için hız ve kaliteyi dengeler.
Projenin odağından çıkarılan ablasyon çalışmaları, LLM merkezli yaklaşımın faydalarını doğrulamaktadır. Jetonları %50 azaltmak, metin çıkarımında %95 doğruluğu korur.
Bu metrikler, DeepSeek-OCR'ın tasarımını doğrular. Uygulamalar, gerçek dünya etkisi için bu performanstan yararlanır.
Diğer OCR Modelleriyle Karşılaştırmalar
DeepSeek-OCR, sıkıştırma verimliliğinde PaddleOCR'dan daha iyi performans gösterir. PaddleOCR hıza odaklanırken, DeepSeek LLM'ler için jeton azaltmayı vurgular.
GOT-OCR2.0 benzer ayrıştırma sunar ancak dinamik modlardan yoksundur. DeepSeek'in Gundam'ı daha büyük belgeleri daha iyi işler.
MinerU madencilikte üstünken, konumlandırmada (grounding) değildir. DeepSeek hassas konum referansı sağlar.
Vary tasarıma ilham verse de, DeepSeek LLM entegrasyonunu ilerletir.
Genel olarak, DeepSeek-OCR bağlamsal optik sıkıştırmada liderdir. Gelecekteki gelişmeler bu güçlü yönler üzerine inşa edilecektir.
Sonuç
DeepSeek-OCR, bağlamsal optik sıkıştırma yoluyla görsel-metin etkileşimlerinde devrim yaratır. Özellikleri, mimarisi ve performansı yeni standartlar belirler. Geliştiriciler, Apidog gibi araçlarla desteklenen yenilikçi çözümler için bu modelden yararlanır.