
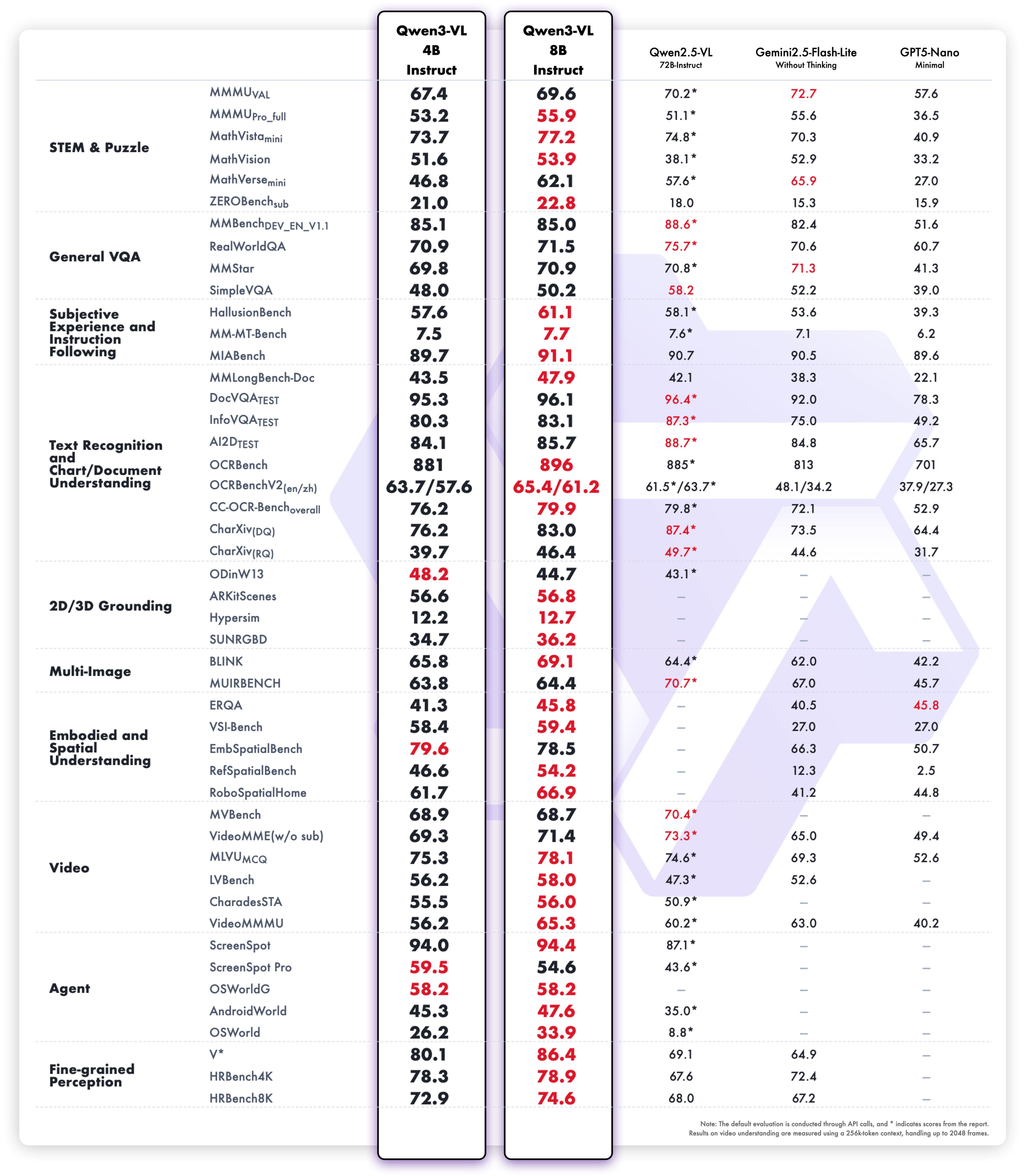
Qwen 3 ailesi, 2026 yılında açık kaynak LLM ortamına hakim oluyor. Mühendisler bu modelleri kritik kurumsal ajanlardan mobil asistanlara kadar her yerde kullanıyor. Alibaba Cloud'a istek göndermeye veya kendi sunucunuzda barındırmaya başlamadan önce, Apidog ile iş akışınızı kolaylaştırın.
Qwen 3'e Genel Bakış: 2026 Performansını Yönlendiren Mimari İnovasyonlar
Alibaba'nın Qwen ekibi, 29 Nisan 2026 tarihinde Qwen 3 serisini piyasaya sürdü ve bu, açık kaynaklı büyük dil modellerinde (LLM'ler) dönüm noktası niteliğinde bir ilerlemeye işaret ediyor. Geliştiriciler, sınırsız ince ayar ve ticari dağıtıma olanak tanıyan Apache 2.0 lisansını övgüyle karşılıyor. Özünde, Qwen 3, konumsal gömmeler ve dikkat mekanizmalarındaki iyileştirmelerle Transformer tabanlı bir mimari kullanıyor; yerel olarak 128K tokene kadar bağlam uzunluklarını destekliyor ve YaRN aracılığıyla 131K'ye kadar genişletilebiliyor.

Ayrıca, seri, belirli varyantlarda Uzman Karışımı (MoE) tasarımlarını içeriyor ve çıkarım sırasında parametrelerin yalnızca bir kısmını etkinleştiriyor. Bu yaklaşım, çıktılarda yüksek doğruluğu korurken hesaplama yükünü azaltıyor. Örneğin, mühendisler, Qwen2.5-72B gibi yoğun öncüllerine kıyasla uzun bağlamlı görevlerde 10 kata kadar daha hızlı işlem hacmi bildiriyor. Sonuç olarak, Qwen 3 varyantları, uç cihazlardan bulut kümelerine kadar donanımlar arasında verimli bir şekilde ölçekleniyor.
Qwen 3 ayrıca, 119'dan fazla dili incelikli talimat takibi ile ele alarak çok dilli destekte üstünlük sağlıyor. Kıyaslamalar, 36 trilyon tokenden rafine edilmiş sentetik matematik ve kod verilerini işlediği STEM alanlarındaki üstünlüğünü doğruluyor. Bu nedenle, küresel işletmelerdeki uygulamalar, azaltılmış çeviri hatalarından ve geliştirilmiş diller arası akıl yürütmeden faydalanıyor. Detaylara geçecek olursak, belirteç bayrakları aracılığıyla değiştirilen hibrit akıl yürütme modu, modellerin matematik veya kodlama için adım adım mantık kullanmasına veya diyalog için düşünmeme moduna varsayılan olarak geçmesine olanak tanır. Bu ikilik, geliştiricilerin her kullanım durumu için optimizasyon yapmasını sağlar.
Qwen 3 Varyantlarını Birleştiren Temel Özellikler
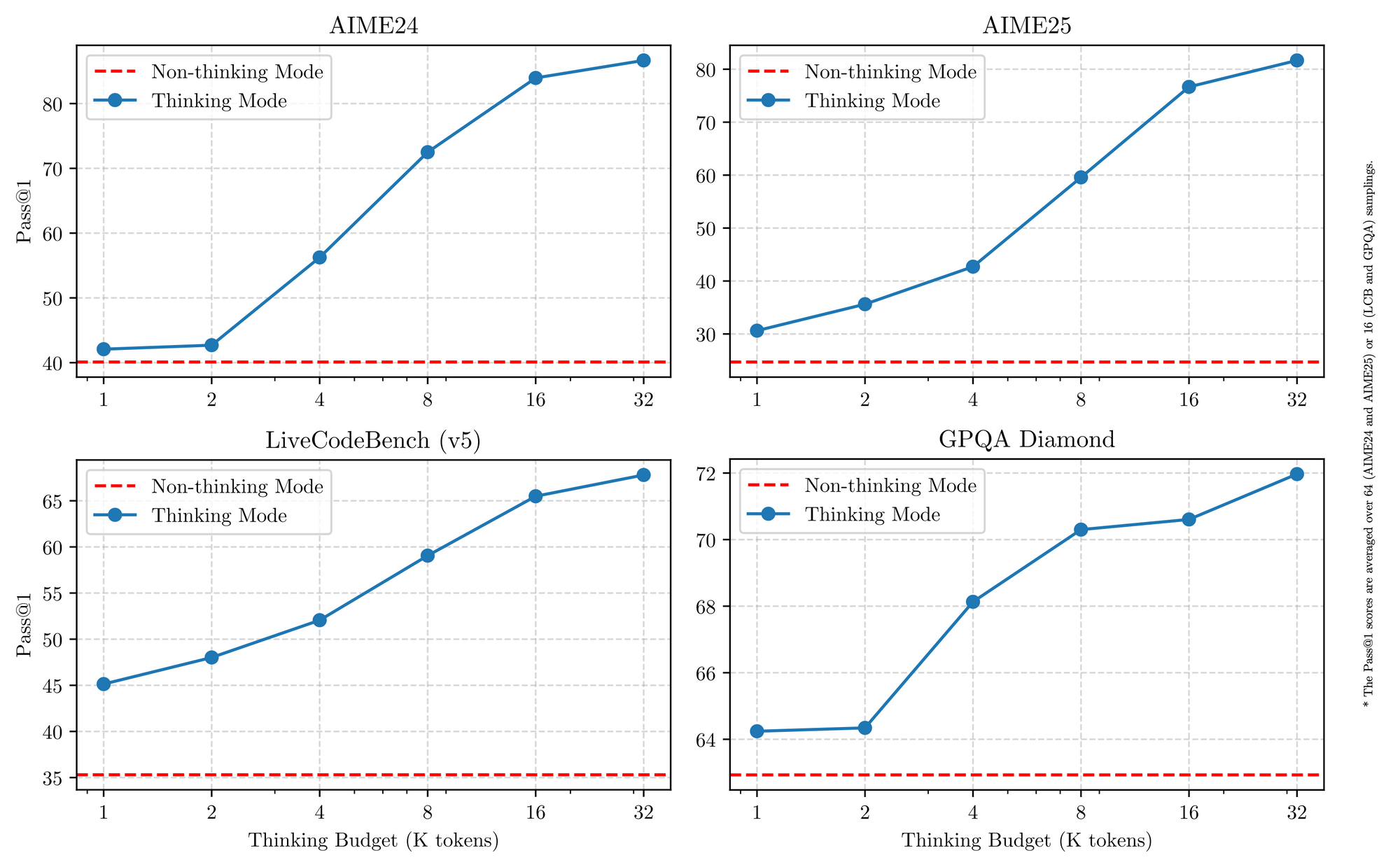
Tüm Qwen 3 modelleri, 2026'te kullanışlılıklarını artıran temel özellikleri paylaşır. Birincisi, çift modlu çalışmayı destekler: düşünme modu, AIME25 gibi kıyaslamalar için düşünce zinciri süreçlerini etkinleştirirken, düşünmeme modu sohbet uygulamaları için hızı önceliklendirir. Mühendisler bunu basit parametrelerle değiştirir ve gecikmeyi feda etmeden karmaşık matematikte %92,3'e varan doğruluk elde eder.
İkincisi, ajans özellikleri, tarayıcı navigasyonu veya kod yürütme gibi görevlerde açık kaynaklı rakiplerini geride bırakarak sorunsuz araç çağrısını mümkün kılar. Örneğin, Qwen 3 varyantları Tau2-Bench Verified'da 69,6 puan alarak tescilli modellerle rekabet eder. Ayrıca, çok dilli yeteneği Mandarin'den Svahili'ye kadar lehçeleri kapsar ve MultiIF kıyaslamalarında 73,0 puana ulaşır.
Üçüncüsü, verimlilik, nicelleştirilmiş varyantlardan (örneğin, Q4_K_M) ve tüketici GPU'larında saniyede 25 token sağlayan vLLM veya SGLang gibi çerçevelerden gelir. Ancak, daha büyük modeller 16GB+ VRAM gerektirir ve bulut dağıtımlarını teşvik eder. Alibaba Cloud aracılığıyla giriş tokenları milyon başına 0,20–1,20 dolar ile fiyatlandırma rekabetçi kalır.
Ayrıca, Qwen 3, yerleşik moderasyon aracılığıyla güvenliği vurgular ve Qwen2.5'e göre halüsinasyonları %15 azaltır. Geliştiriciler bunu e-ticaret önericilerinden yasal analiz araçlarına kadar üretim düzeyinde uygulamalar için kullanır. Bireysel varyantlara geçerken, bu ortak güçlü yönler karşılaştırma için tutarlı bir temel sağlar.
2026'teki En İyi 5 Qwen 3 Model Varyantı
LMSYS Arena, LiveCodeBench ve SWE-Bench'ten 2026 kıyaslamalarına dayanarak, en iyi beş Qwen 3 varyantını sıralıyoruz. Seçim kriterleri arasında akıl yürütme puanları, çıkarım hızı, parametre verimliliği ve API erişilebilirliği yer alıyor. Her biri farklı senaryolarda üstün olsa da, hepsi açık kaynak sınırlarını ilerletiyor.
1. Qwen3-235B-A22B – Mutlak Amiral Gemisi MoE Canavarı
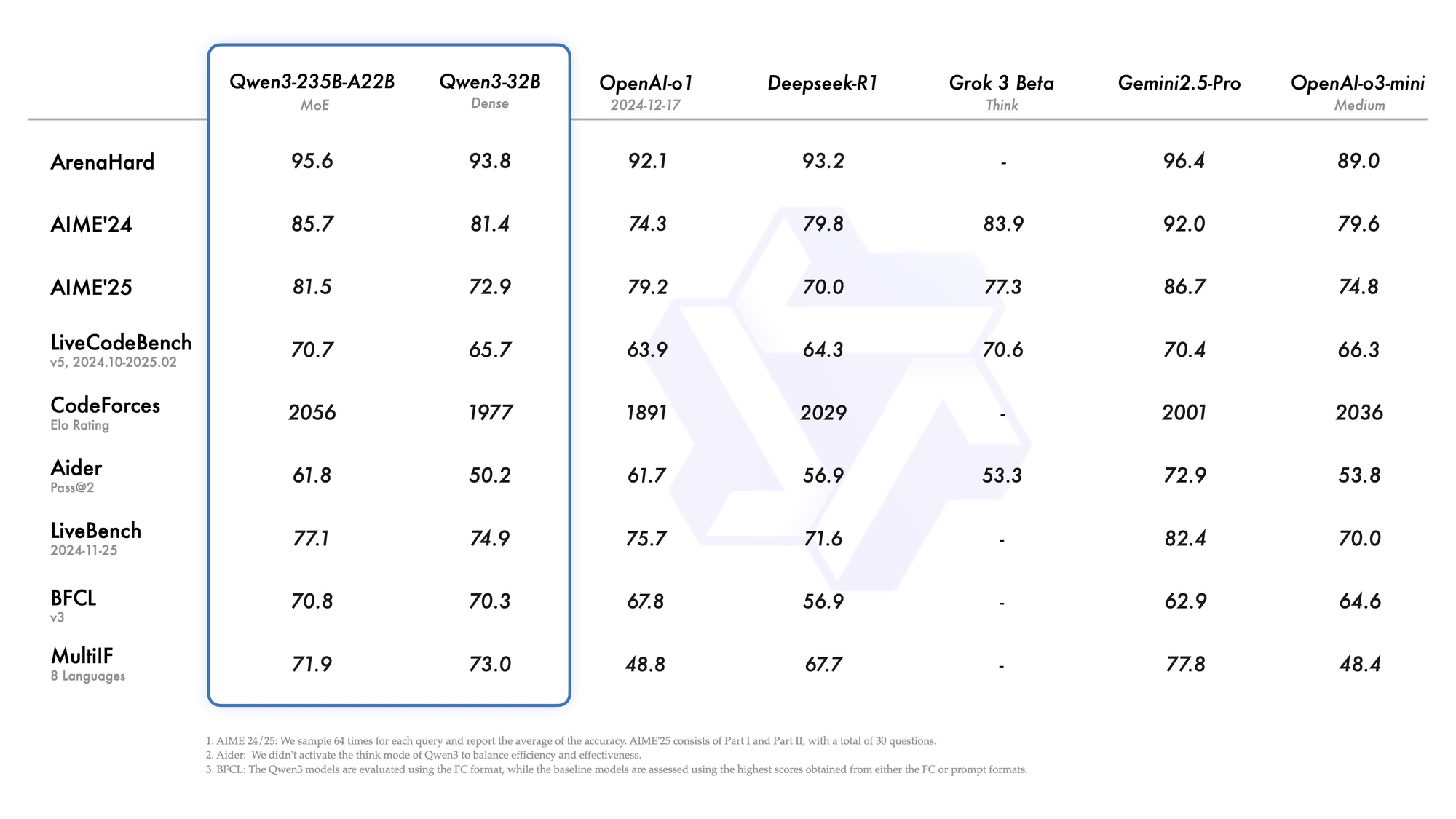
Qwen3-235B-A22B , toplam 235 milyar parametre ve token başına 22 milyar aktif parametre ile önde gelen MoE varyantı olarak dikkat çekiyor. Temmuz 2026'te Qwen3-235B-A22B-Instruct-2507 olarak piyasaya sürülen bu model, top-k yönlendirme aracılığıyla sekiz uzmanı etkinleştirerek yoğun eşdeğerlerine kıyasla hesaplama gücünü %90 azaltıyor. Kıyaslamalar, Gemini 2.5 Pro ile başa baş olduğunu gösteriyor: ArenaHard'da 95,6, LiveBench'te 77,1 ve CodeForces Elo'da liderlik (%5 önde).
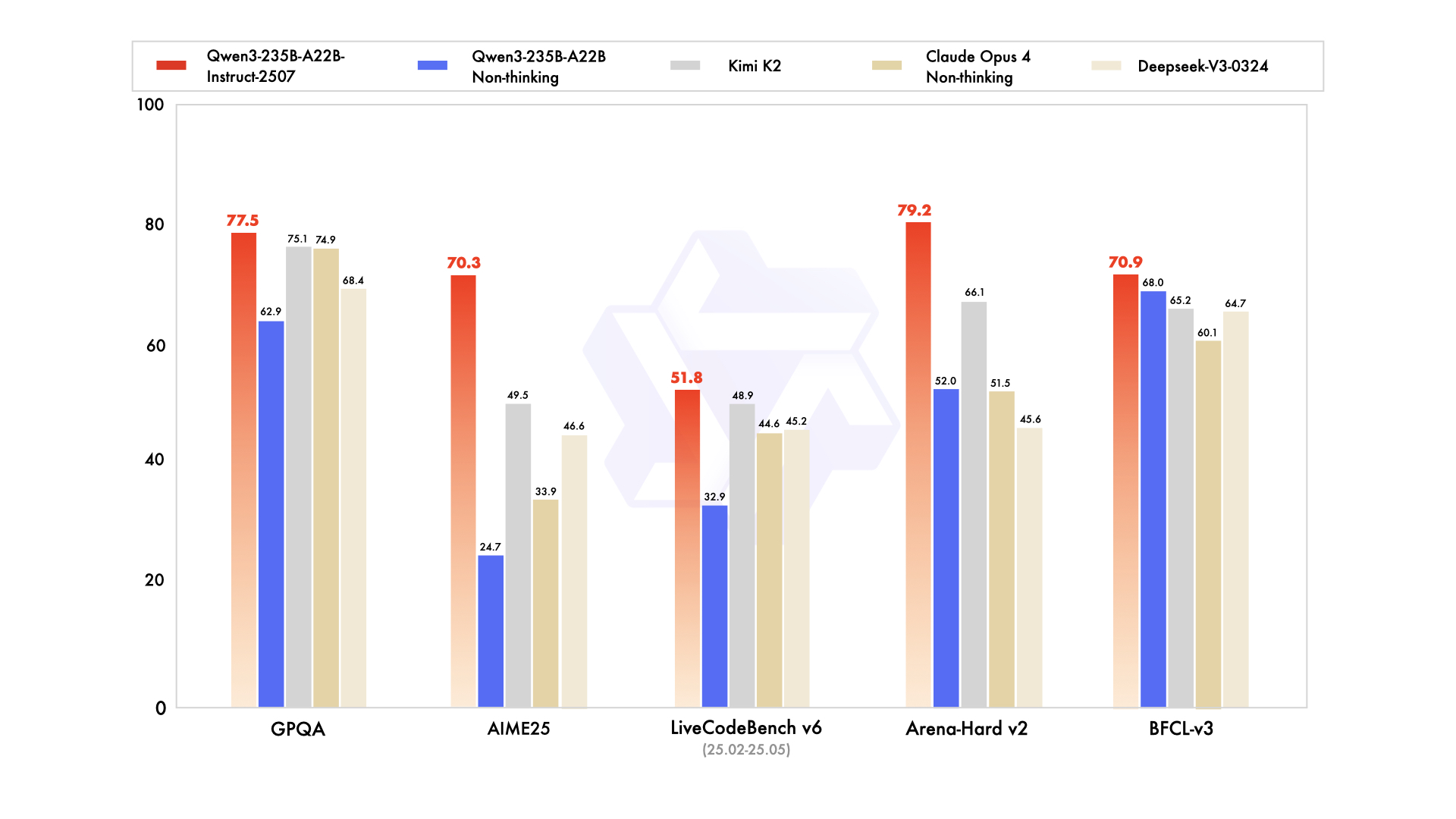
Kodlamada, LiveCodeBench v6'da 74,8 puan alarak minimum iterasyonlarla işlevsel TypeScript oluşturur. Matematik için, düşünme modu AIME25'te 92,3 puan getirerek çok adımlı integralleri açık çıkarım yoluyla çözer. Çok dilli görevlerde MultiIF'te 73,0 puan alarak Arapça sorguları kusursuz bir şekilde işler.
Dağıtım, 256K bağlamı işlediği bulut API'lerini tercih eder. Ancak, yerel çalıştırmalar 8x H100 GPU gerektirir. Mühendisler bunu, depo ölçeğinde hata ayıklama gibi ajan tabanlı iş akışları için entegre eder. Genel olarak, bu varyant derinlik için 2026 standardını belirler, ancak ölçeği yüksek bütçeli ekiplere uygundur.
Güçlü Yönler
- 2026'teki neredeyse her liderlik tablosunda Gemini 2.5 Pro ve Claude 3.7 Sonnet ile eşleşir veya onları yener (95,6 ArenaHard, 92,3 AIME25 düşünme modu, 74,8 LiveCodeBench v6).
- Çok turlu ajan tabanlı iş akışlarında, karmaşık araç çağrısında ve depo düzeyinde kod anlamada üstünlük sağlar.
- YaRN ile 256K–1M bağlamı kalite kaybı olmadan işler.
- Düşünme modu, kapalı kaynaklı öncü modellerle rekabet eden doğrulanabilir bir düşünce zinciri akıl yürütmesi sunar.
Zayıf Yönler
- Yerel olarak son derece pahalı ve yavaş—makul gecikme için 8×H100 veya eşdeğeri gerektirir.
- API fiyatlandırması ailedeki en yüksektir (en yüksek bağlamda M çıktı tokenı başına 1,20–6,00 dolar).
- Üretim iş yüklerinin %95'i için aşırıdır; çoğu ekip kapasitesini asla doyurmaz.
Ne Zaman Kullanılmalı
- Doktora düzeyinde matematik çözmesi, tüm kod tabanlarını hata ayıklaması veya sıfıra yakın halüsinasyonla yasal sözleşme analizi yapması gereken kurumsal düzeyde otonom ajanlar.
- Yeni kıyaslamalarda en son teknolojiyi zorlayan yüksek bütçeli araştırma laboratuvarları.
- Token başına maliyetin maksimum zekadan sonra geldiği dahili akıl yürütme arka uçları.
2. Qwen3-30B-A3B – İdeal MoE Şampiyonu
Qwen3-30B-A3B , toplam 30,5 milyar parametre ve 3,3 milyar aktif parametre ile kaynak kısıtlı kurulumlar için tercih edilen model olarak öne çıkıyor. 48 katman, 128 uzman (sekiz yönlendirmeli) MoE yapısı, amiral gemisi modeli yansıtır ancak %10 daha az yer kaplar. Temmuz 2026'te güncellenen bu model, aktif verimlilikte QwQ-32B'yi 10 kat geride bırakarak ArenaHard'da 91,0 ve SWE-Bench Verified'da 69,6 puan alıyor.
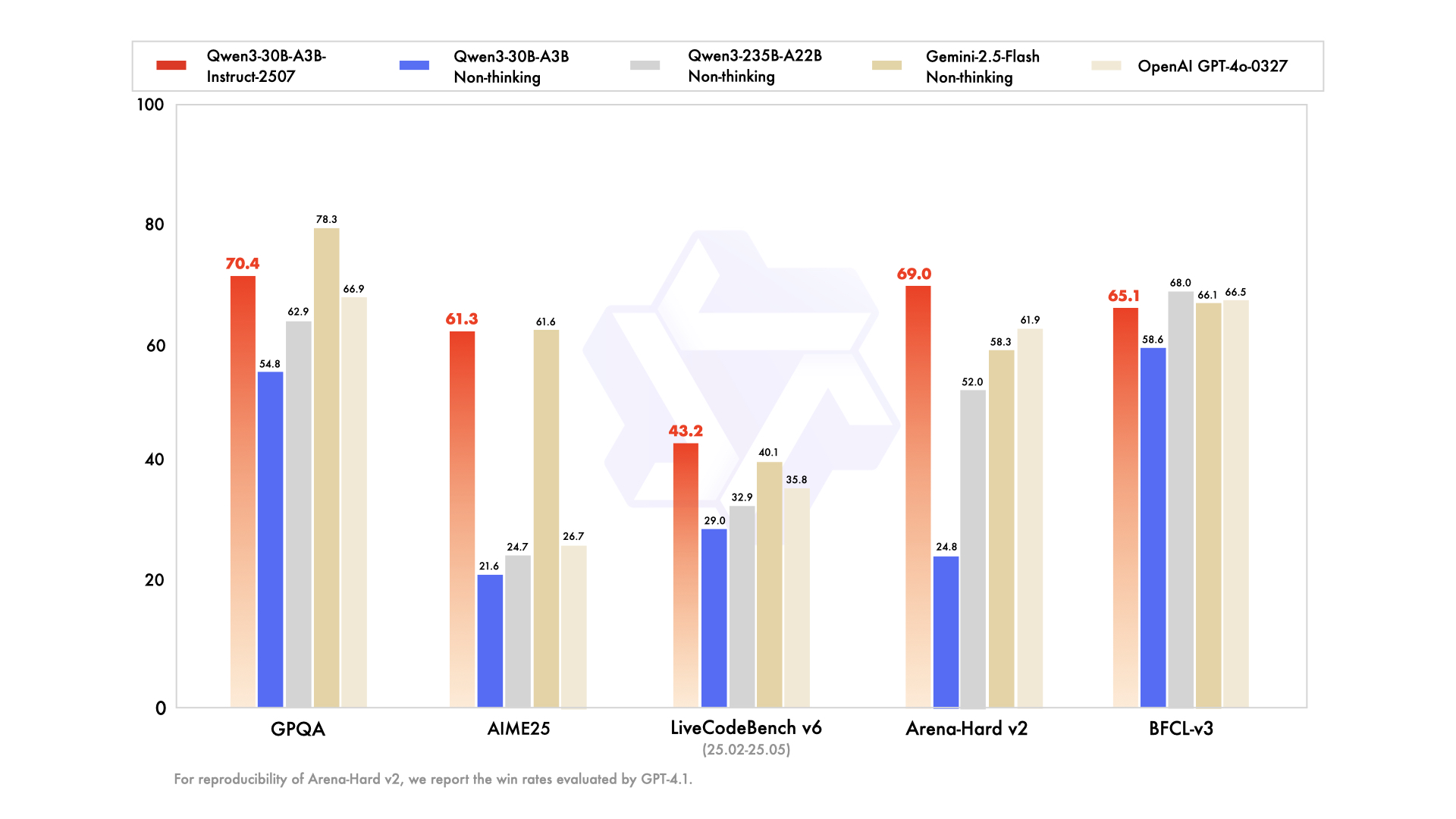
Kodlama değerlendirmeleri yeteneğini vurguluyor: yeni GitHub PR'larında %32,4 pass@5 puanı ile GPT-5-High ile eşleşiyor. Matematik kıyaslamaları, düşünme modunda AIME25'te 81,6 puan gösteriyor ve daha büyük kardeş modellerle rekabet ediyor. YaRN aracılığıyla 131K bağlam ile uzun belgeleri kesmeden işler.
Güçlü Yönler
- 235B'den 10 kat daha ucuz aktif parametreler sunarken amiral gemisi akıl yürütme kalitesinin yaklaşık %90-95'ini korur (91,0 ArenaHard, 81,6 AIME25).
- vLLM + FlashAttention ile tek bir 80GB A100 veya iki adet 40GB kartta rahatça çalışır.
- Tüm 2026 açık MoE modelleri arasında en iyi fiyat-performans oranına sahiptir.
- Kodlama ve matematikte yoğun 72B–110B modellerinin hepsini geride bırakır.
Zayıf Yönler
- FP8/INT4'te hala ~24–30GB VRAM'e ihtiyaç duyar; dizüstü bilgisayar dostu değildir.
- Benzer boyuttaki saf yoğun modellere göre yaratıcı yazma akıcılığı biraz daha düşüktür.
- Düşünme modu gecikmesi, düşünmeme moduna kıyasla 2-3 kat artar.
Ne Zaman Kullanılmalı
- Üretim kodlama ajanları, otomatik PR incelemeleri veya dahili DevOps yardımcı pilotları.
- Makul bir bütçeyle öncü düzeyde matematik veya bilimsel akıl yürütmeye ihtiyaç duyan yüksek işlem hacimli araştırma boru hatları.
- Daha önce Llama-405B veya Mixtral-123B kullanan ancak daha düşük maliyetle daha iyi akıl yürütme isteyen herhangi bir ekip.
3. Qwen3-32B – Yoğun Çok Yönlü Kral
Yoğun Qwen3-32B, 32 milyar tamamen aktif parametre sunarak seyreklikten ziyade ham işlem hacmine vurgu yapar. 36T token üzerinde eğitilmiş olup, temel performansta Qwen2.5-72B ile eşleşir ancak eğitim sonrası hizalamada üstünlük sağlar. Kıyaslamalar ArenaHard'da 89,5 ve MultiIF'te 73,0 puanı, güçlü yaratıcı yazma becerisiyle (örneğin, rol yapma anlatılarında %85 insan tercihi puanı) ortaya koyuyor.
Kodlamada, BFCL'de 68,2 puanla lider konumdadır ve istemlerden sürükle-bırak kullanıcı arayüzleri oluşturur. Matematikte, AIME25'te 70,3 puan verir, ancak düşünce zincirinde MoE rakiplerinin gerisinde kalır. 128K bağlamı bilgi tabanlarına uygundur ve düşünmeme modu diyalog hızını saniyede 20 tokene çıkarır.
Güçlü Yönler
- Üstün talimat takibi ve yaratıcı çıktı—yazma ve rol yapma için kör insan değerlendirmelerinde genellikle daha büyük MoE modellerine tercih edilir.
- Tüketici donanımında (16–24GB VRAM) LoRA/QLoRA ile ince ayar yapmak kolaydır.
- Birçok görevde GPT-4o'yu hala yenen modeller arasında en hızlı çıkarım (89,5 ArenaHard).
- 119'dan fazla dilde çok güçlü çok dilli performans.
Zayıf Yönler
- Düşünme modu etkinleştirildiğinde en zor matematik ve kodlama kıyaslamalarında MoE kardeşlerinin ~8–12 puan gerisinde kalır.
- Parametre verimliliği hilesi yoktur—her token tam 32B hesaplama maliyetine sahiptir.
Ne Zaman Kullanılmalı
- İçerik üretim platformları, roman yazma asistanları, pazarlama metni araçları.
- Yoğun ince ayar gerektiren projeler (alana özel sohbet botları, stil transferi).
- Amiral gemisi kalitesine yakın isteyen ancak 24GB VRAM altında kalması gereken ekipler.
4. Qwen3-14B – Uç ve Mobil Güç Merkezi
Qwen3-14B, 14,8 milyar parametre ile taşınabilirliği önceliklendirir ve orta seviye donanımlarda 128K bağlamı destekler. Verimlilikte Qwen2.5-32B ile rekabet eder, ArenaHard'da 85,5 puan alır ve matematik/kodlamada Qwen3-30B-A3B ile başa baş gider (%5 marj içinde). Q4_0'a nicelleştirildiğinde, RedMagic 8S Pro gibi mobil cihazlarda saniyede 24,5 token hızında çalışır.
Ajan tabanlı görevlerde Tau2-Bench'te 65,1 puan alarak düşük gecikmeli uygulamalarda araç kullanımını mümkün kılar. Çok dilli destek parlar ve lehçe çıkarımında %70 doğruluk sağlar. Uç cihazlar için, IoT analizi için ideal olan 32K bağlamı çevrimdışı işler.
Mühendisler, gizliliğin ölçekten daha önemli olduğu federasyon öğrenimi için kapladığı alanı değerli bulurlar. Bu nedenle, mobil yapay zeka asistanlarına veya gömülü sistemlere uygundur.
Güçlü Yönler
- Q4_K_M'ye nicelleştirildiğinde modern telefonlarda (Snapdragon 8 Gen 4, Dimensity 9400) saniyede 24–30 token hızından daha yüksek çalışır.
- Çoğu akıl yürütme kıyaslamasında Qwen2.5-32B ve Llama-3.1-70B'yi hala yener.
- 32K–128K bağlam ile cihaz içi RAG için mükemmeldir.
- Üst düzey performans aralığında en düşük API maliyeti.
Zayıf Yönler
- 5'ten fazla araç çağrısı gerektiren çok adımlı ajan tabanlı görevlerde zorlanmaya başlar.
- Yaratıcı yazma kalitesi 32B+ modellerinden belirgin şekilde düşüktür.
- Kıyaslamalar yükselmeye devam ettikçe geleceğe daha az uyumludur.
Ne Zaman Kullanılmalı
- Cihaz içi asistanlar (Android/iOS uygulamaları, giyilebilir cihazlar).
- Verilerin cihazdan ayrılamadığı gizliliğe duyarlı dağıtımlar (sağlık, finans).
- Gerçek zamanlı gömülü sistemler (robotlar, arabalar, IoT ağ geçitleri).
5. Qwen3-8B – Üstün Prototipleme ve Hafif İş Gücü
İlk beşi tamamlayan Qwen3-8B , hızlı yineleme için 8 milyar parametre sunar ve 15 kıyaslamada Qwen2.5-14B'yi geride bırakır. AIME25'te (düşünmeme modu) 81,5 ve LiveCodeBench'te 60,2 puan alarak temel kod incelemeleri için yeterli olur. 32K yerel bağlam ile Ollama aracılığıyla dizüstü bilgisayarlara dağıtılır ve saniyede 25 token hızına ulaşır.
Bu varyant, çok dilli sohbeti veya basit ajanları test eden yeni başlayanlar için uygundur. Düşünme modu mantık bulmacalarını geliştirir ve çıkarım görevlerinde %75 puan alır. Sonuç olarak, daha büyük kardeş modellere ölçeklendirmeden önce kavram kanıtlarını hızlandırır.
Güçlü Yönler
- 8–12GB VRAM'li dizüstü bilgisayarlarda bile (>MacBook M3 Pro, RTX 4070 mobil) saniyede 25 token hızından daha yüksek çalışır.
- Şaşırtıcı derecede yetkin talimat takibi—çoğu 2026 liderlik tablosunda Gemma-2-27B ve Phi-4-14B'yi yener.
- Yerel Ollama veya LM Studio denemeleri için mükemmeldir.
- Ailenin en ucuz API fiyatlandırması.
Zayıf Yönler
- Lisansüstü düzeyde matematik ve gelişmiş kodlama sorunlarında belirgin bir akıl yürütme tavanı vardır.
- Bilgi yoğun görevlerde halüsinasyona daha yatkındır.
- Sınırlı bağlam (32K yerel, YaRN ile 128K ancak daha yavaş).
Ne Zaman Kullanılmalı
- Hızlı prototipleme ve MVP oluşturma.
- Eğitim araçları, kişisel asistanlar veya hobi projeleri.
- Hibrit sistemlerde ön uç yönlendirme katmanı (triyaj için 8B kullanın, gerektiğinde 30B/235B'ye yükseltin).
Qwen 3 Modelleri için API Fiyatlandırması ve Dağıtım Hususları
Qwen 3'e API'ler aracılığıyla erişim, gelişmiş yapay zekayı demokratikleştiriyor ve Alibaba Cloud rekabetçi fiyatlarla lider konumda. Fiyatlandırma tokenlara göre kademelendirilir: Qwen3-235B-A22B için, giriş maliyetleri milyon başına 0,20–1,20 dolar (0–252K aralığı), çıktı ise milyon başına 1,00–6,00 dolar. Qwen3-30B-A3B bu oranı %80 ile yansıtırken, Qwen3-32B gibi yoğun modeller giriş 0,15 dolar/çıktı 0,75 dolara düşer.
Together AI gibi üçüncü taraf sağlayıcılar, Qwen3-32B'yi toplam token başına 0,80 dolar/1M fiyatla ve hacim indirimleriyle sunar. Önbellek isabetleri faturaları azaltır: örtük olarak %20, açık olarak %10. GPT-5 (3–15 dolar/1M) ile karşılaştırıldığında, Qwen 3 %70 daha ucuzdur ve uygun maliyetli ölçeklendirmeyi mümkün kılar.
Dağıtım ipuçları: Toplulaştırma için vLLM kullanın, OpenAI uyumluluğu için SGLang kullanın. Apidog, Qwen uç noktalarını taklit ederek, yükleri test ederek ve belgeler oluşturarak bunu geliştirir—bu, CI/CD boru hatları için çok önemlidir. Ollama aracılığıyla yerel çalıştırmalar prototiplemeye uygunken, API'ler üretim için üstündür.
Oran sınırlama ve moderasyon gibi güvenlik özellikleri ek değer katar ve ek ücret alınmaz. Bu nedenle, bütçe bilinci olan ekipler, token hacmine göre seçim yapar: geliştirme için küçük varyantlar, çıkarım için amiral gemileri.
Karar Tablosu – 2026'te Qwen 3 Modelinizi Seçin
| Sıra | Model | Parametreler (Toplam/Aktif) | Güçlü Yönler Özeti | Başlıca Zayıf Yönler | En İyisi | Yakl. API Maliyeti (1M token başına Giriş/Çıkış) | Minimum VRAM (nicelleştirilmiş) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235B / 22B MoE | Maksimum akıl yürütme, ajan tabanlı, matematik, kod | Son derece pahalı ve ağır | Öncü araştırma, kurumsal ajanlar, sıfır toleranslı doğruluk | $0.20–$1.20 / $1.00–$6.00 | 64GB+ (bulut) |
| 2 | Qwen3-30B-A3B | 30.5B / 3.3B MoE | En iyi fiyat-performans, güçlü akıl yürütme | Hala sunucu GPU'su gerektirir | Üretim kodlama ajanları, matematik/bilim arka uçları, yüksek hacimli çıkarım | $0.16–$0.96 / $0.80–$4.80 | 24–30GB |
| 3 | Qwen3-32B | 32B Yoğun | Yaratıcı yazma, kolay ince ayar, hız | En zor görevlerde MoE'nin gerisinde kalır | İçerik platformları, alan ince ayarı, çok dilli sohbet botları | $0.15 / $0.75 | 16–20GB |
| 4 | Qwen3-14B | 14.8B Yoğun | Uç/mobil uyumlu, harika cihaz içi RAG | Sınırlı çok adımlı ajan yeteneği | Cihaz içi yapay zeka, gizlilik açısından kritik uygulamalar, gömülü sistemler | $0.12 / $0.60 | 8–12GB |
| 5 | Qwen3-8B | 8B Yoğun | Dizüstü/telefon hızı, en ucuz | Karmaşık görevlerde belirgin tavan | Prototipleme, kişisel asistanlar, hibrit sistemlerde yönlendirme katmanı | $0.10 / $0.50 | 4–8GB |
2026 İçin Son Tavsiye
2026'teki çoğu ekip, varsayılan olarak Qwen3-30B-A3B'yi tercih etmelidir; bu model, amiral gemisinin gücünün %90'ından fazlasını maliyetin ve donanım gereksinimlerinin bir kısmına sunar. Yalnızca akıl yürütme kalitesinin son %5–10'una gerçekten ihtiyacınız varsa ve bütçeniz varsa 235B-A22B'ye geçin. Yaratıcı veya yoğun ince ayar iş yükleri için 32B yoğun modele düşürün ve gecikme, gizlilik veya cihaz kısıtlamaları baskın olduğunda 14B/8B'yi kullanın.
Hangi varyantı seçerseniz seçin, Apidog size saatlerce API hata ayıklama süresi kazandıracaktır. Bugün ücretsiz indirin ve Qwen 3 ile güvenle geliştirmeye başlayın.