
การรันโมเดลภาษาขนาดใหญ่ เช่น Mistral 3 บนเครื่องของคุณเอง มอบการควบคุมที่เหนือชั้นให้กับนักพัฒนาในด้านความเป็นส่วนตัวของข้อมูล, ความเร็วในการอนุมาน และการปรับแต่ง ในขณะที่ปริมาณงาน AI มีความต้องการมากขึ้น การรันบนเครื่องจึงเป็นสิ่งจำเป็นสำหรับการสร้างต้นแบบ, การทดสอบ และการปรับใช้แอปพลิเคชันแบบออฟไลน์ ยิ่งไปกว่านั้น เครื่องมืออย่าง Ollama ยังช่วยให้กระบวนการนี้ง่ายขึ้น ทำให้คุณสามารถใช้ประโยชน์จากความสามารถของ Mistral 3 ได้โดยตรงจากเดสก์ท็อปหรือเซิร์ฟเวอร์ของคุณ
คู่มือนี้จะให้คำแนะนำทีละขั้นตอนในการติดตั้งและรัน Mistral 3 รุ่นต่างๆ บนเครื่องของคุณ เราจะเน้นไปที่ซีรีส์ Ministral 3 แบบโอเพนซอร์ส ซึ่งมีความโดดเด่นในการใช้งานแบบ edge deployments เมื่ออ่านจบ คุณจะสามารถเพิ่มประสิทธิภาพสำหรับงานจริง เพื่อให้มั่นใจถึงการตอบสนองที่รวดเร็วและใช้ทรัพยากรได้อย่างมีประสิทธิภาพ
ทำความเข้าใจ Mistral 3: ขุมพลังโอเพนซอร์สใน AI
Mistral AI ยังคงก้าวข้ามขีดจำกัดด้วยการเปิดตัวล่าสุด: Mistral 3 นักพัฒนาและนักวิจัยต่างชื่นชมตระกูลโมเดลนี้ที่สามารถรักษาสมดุลระหว่างความแม่นยำ ประสิทธิภาพ และการเข้าถึงได้ แตกต่างจากยักษ์ใหญ่ที่เป็นกรรมสิทธิ์ Mistral 3 ยึดมั่นในหลักการโอเพนซอร์ส โดยเผยแพร่ภายใต้ใบอนุญาต Apache 2.0 การเคลื่อนไหวนี้ช่วยให้ชุมชนสามารถปรับเปลี่ยน แจกจ่าย และสร้างสรรค์นวัตกรรมได้อย่างอิสระ
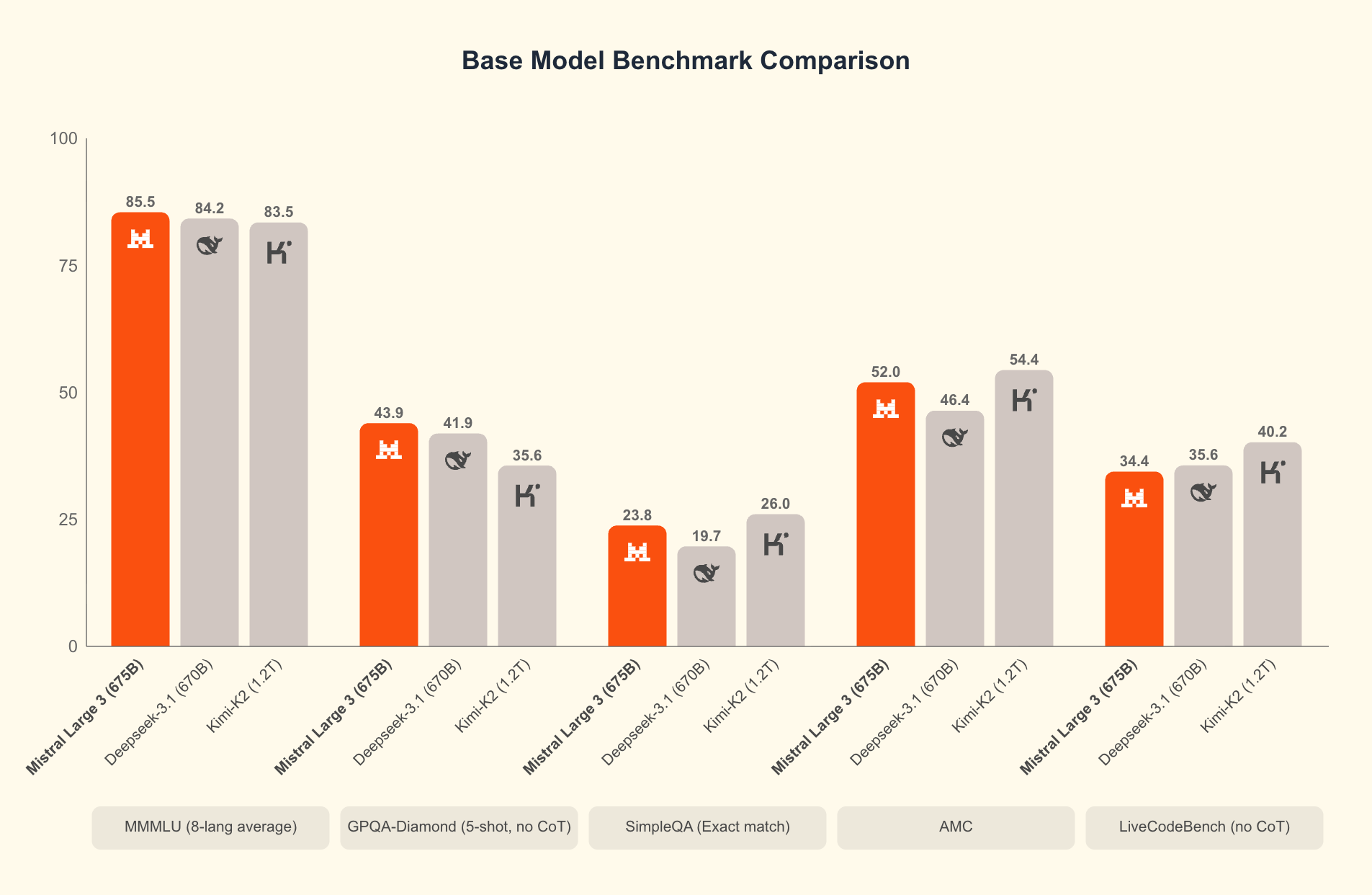
โดยหลักแล้ว Mistral 3 ประกอบด้วยสองสายหลัก ได้แก่ ซีรีส์ Ministral 3 ขนาดกะทัดรัด และ Mistral Large 3 ขนาดใหญ่ โมเดล Ministral 3 ซึ่งมีขนาดพารามิเตอร์ 3B, 8B และ 14B มุ่งเป้าไปที่สภาพแวดล้อมที่มีข้อจำกัดด้านทรัพยากร วิศวกรออกแบบโมเดลเหล่านี้สำหรับการใช้งานในเครื่องและแบบ edge ซึ่งทุกวัตต์และทุกคอร์มีความสำคัญ ตัวอย่างเช่น รุ่น 3B สามารถใช้งานได้สบายบนแล็ปท็อปที่มี GPU ขนาดเล็ก ในขณะที่รุ่น 14B ผลักดันขีดจำกัดในการตั้งค่าหลาย GPU โดยไม่ลดทอนความเร็ว
ในทางกลับกัน Mistral Large 3 ใช้สถาปัตยกรรมแบบ sparse mixture-of-experts ที่มีพารามิเตอร์ที่ใช้งานอยู่ 41 พันล้านตัว และพารามิเตอร์ทั้งหมด 675 พันล้านตัว การออกแบบนี้จะเปิดใช้งานผู้เชี่ยวชาญที่เกี่ยวข้องเท่านั้นต่อหนึ่งคำถาม ซึ่งช่วยลดค่าใช้จ่ายในการคำนวณลงอย่างมาก นักพัฒนาสามารถเข้าถึงเวอร์ชันที่ปรับแต่งตามคำสั่งสำหรับการทำงานต่างๆ เช่น การช่วยเขียนโค้ด การสรุปเอกสาร และการแปลหลายภาษา โมเดลนี้รองรับมากกว่า 40 ภาษาโดยกำเนิด ซึ่งมีประสิทธิภาพเหนือกว่าโมเดลอื่นๆ ในการสนทนาที่ไม่ใช่ภาษาอังกฤษ
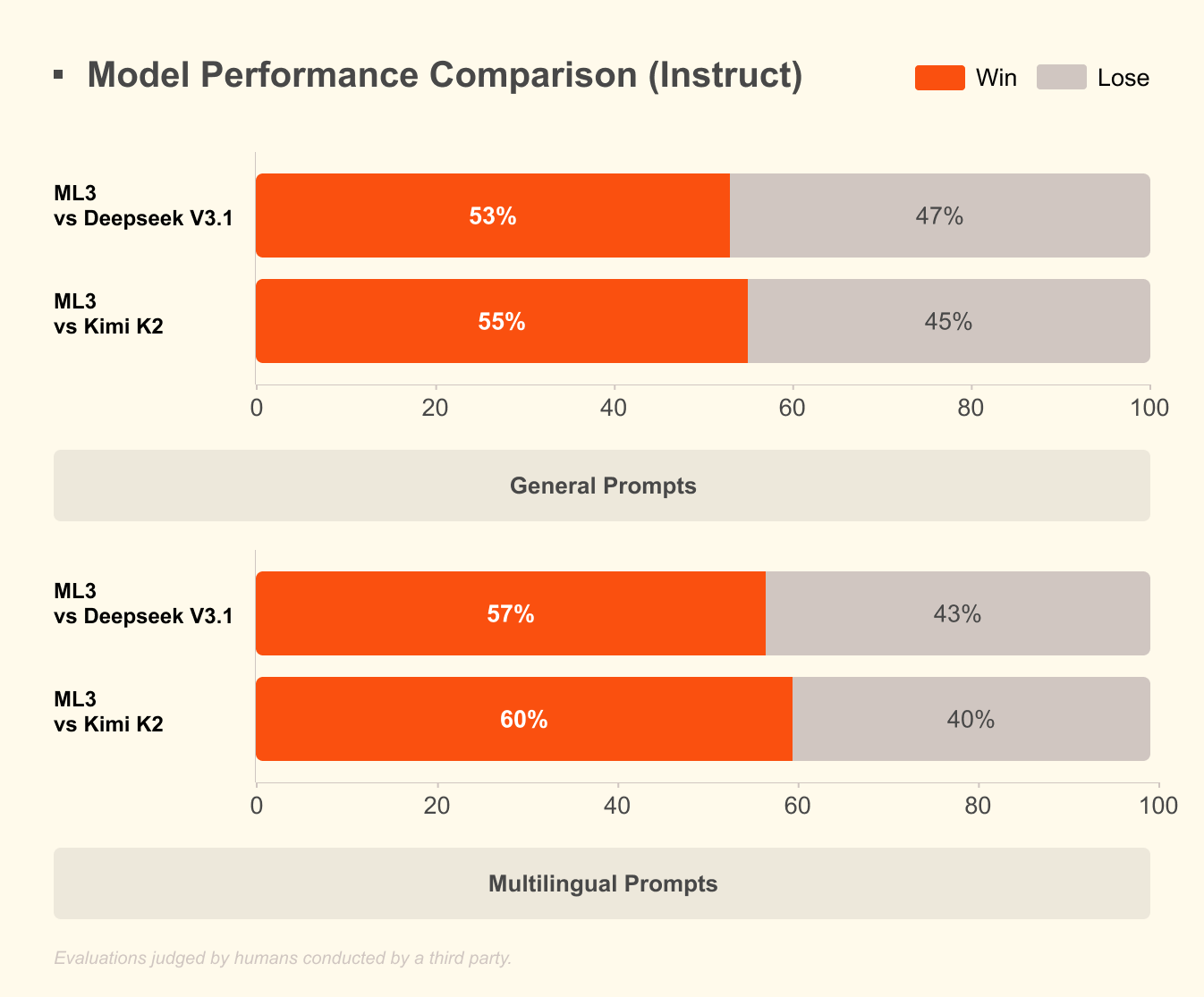
อะไรที่ทำให้ Mistral 3 โดดเด่น? ผลการทดสอบแสดงให้เห็นถึงความได้เปรียบในสถานการณ์จริง บนชุดข้อมูล GPQA Diamond ซึ่งเป็นการทดสอบความสามารถในการให้เหตุผลทางวิทยาศาสตร์อย่างเข้มงวด Mistral 3 รุ่นต่างๆ ยังคงรักษาความแม่นยำสูง แม้ว่าจำนวนโทเค็นที่ส่งออกจะเพิ่มขึ้น ตัวอย่างเช่น โมเดล Ministral 3B Instruct รักษาความแม่นยำประมาณ 35-40% ได้สูงสุดถึง 20,000 โทเค็น แข่งขันกับโมเดลขนาดใหญ่เช่น Gemma 2 9B ในขณะที่ใช้ทรัพยากรน้อยกว่า ประสิทธิภาพนี้เกิดจากเทคนิคการควอนไทซ์ขั้นสูง เช่น การบีบอัดแบบ NVFP4 ซึ่งช่วยลดขนาดโมเดลโดยไม่ลดทอนคุณภาพผลลัพธ์
นอกจากนี้ Mistral 3 ยังผสานรวมคุณสมบัติมัลติโมดอล โดยประมวลผลรูปภาพควบคู่ไปกับข้อความสำหรับการใช้งานในการตอบคำถามจากภาพ หรือการสร้างเนื้อหา การเปิดโมเดลเหล่านี้เป็นโอเพนซอร์สส่งเสริมการพัฒนาอย่างรวดเร็ว ชุมชนต่างๆ ได้ปรับแต่งโมเดลเหล่านี้สำหรับโดเมนเฉพาะทาง เช่น การวิเคราะห์ทางกฎหมาย หรือการเขียนเชิงสร้างสรรค์ ด้วยเหตุนี้ Mistral 3 จึงทำให้ AI ล้ำสมัยเป็นประชาธิปไตย ช่วยให้สตาร์ทอัพและนักพัฒนาแต่ละรายสามารถแข่งขันกับบริษัทยักษ์ใหญ่ด้านเทคโนโลยีได้

จากการเปลี่ยนผ่านจากทฤษฎีสู่การปฏิบัติ การรันโมเดลเหล่านี้บนเครื่องของคุณจะปลดล็อกศักยภาพสูงสุดของพวกมัน Cloud API ทำให้เกิดความหน่วงและค่าใช้จ่าย แต่การอนุมานบนเครื่องให้การตอบสนองที่น้อยกว่าหนึ่งวินาที ถัดไป เราจะตรวจสอบข้อกำหนดเบื้องต้นด้านฮาร์ดแวร์ที่ทำให้สิ่งนี้เป็นไปได้
ทำไมต้องรัน Mistral 3 บนเครื่อง? ประโยชน์สำหรับนักพัฒนาและการเพิ่มประสิทธิภาพ
นักพัฒนาเลือกการรันบนเครื่องด้วยเหตุผลหลายประการที่น่าสนใจ ประการแรก ความเป็นส่วนตัวคือสิ่งสำคัญที่สุด: ข้อมูลที่ละเอียดอ่อนจะยังคงอยู่ในเครื่องของคุณ หลีกเลี่ยงเซิร์ฟเวอร์ของบุคคลที่สาม ในอุตสาหกรรมที่มีการควบคุม เช่น การดูแลสุขภาพหรือการเงิน ความได้เปรียบด้านการปฏิบัติตามข้อกำหนดนี้มีค่าอย่างยิ่ง ประการที่สอง การประหยัดค่าใช้จ่ายสะสมได้อย่างรวดเร็ว ประสิทธิภาพสูงของ Mistral 3 หมายความว่าคุณหลีกเลี่ยงค่าธรรมเนียมต่อโทเค็น ซึ่งเหมาะสำหรับการทดสอบปริมาณมาก
นอกจากนี้ การรันบนเครื่องยังช่วยเร่งการทดลอง คุณสามารถปรับปรุงพร้อมต์, ปรับแต่งไฮเปอร์พารามิเตอร์ หรือเชื่อมโยงโมเดลได้โดยไม่มีความล่าช้าจากเครือข่าย ผลการทดสอบยืนยันสิ่งนี้: บนฮาร์ดแวร์ทั่วไป Ministral 8B สามารถสร้างโทเค็นได้ 50-60 โทเค็นต่อวินาที ซึ่งเทียบได้กับการตั้งค่าบนคลาวด์ แต่ไม่มีการหยุดทำงาน
ประสิทธิภาพคือสิ่งที่ทำให้ Mistral 3 น่าสนใจ โมเดลนี้ได้รับการปรับแต่งสำหรับการอนุมานที่ต้นทุนต่ำ ดังที่แสดงในผลลัพธ์ของ GPQA Diamond ซึ่ง Mistral รุ่นต่างๆ มีประสิทธิภาพเหนือกว่า Gemma 3 4B และ 12B ในด้านความแม่นยำที่ยั่งยืน สิ่งนี้มีความสำคัญสำหรับงานที่มีบริบทขนาดยาว เนื่องจากเมื่อเอาต์พุตขยายไปถึง 20,000 โทเค็น ความแม่นยำจะลดลงน้อยที่สุด ทำให้มั่นใจได้ถึงประสิทธิภาพที่เชื่อถือได้ในแชทบอทหรือเครื่องมือสร้างโค้ด
นอกจากนี้ การเข้าถึงแบบโอเพนซอร์สผ่านแพลตฟอร์มต่างๆ เช่น Hugging Face ช่วยให้สามารถผสานรวมกับเครื่องมืออย่าง Apidog สำหรับการสร้างต้นแบบ API ได้อย่างราบรื่น ทดสอบ Mistral 3 endpoints บนเครื่องของคุณก่อนที่จะขยายขนาด เชื่อมโยงช่องว่างระหว่างการพัฒนาและการใช้งานจริง
อย่างไรก็ตาม ความสำเร็จขึ้นอยู่กับการตั้งค่าที่เหมาะสม เมื่อมีฮาร์ดแวร์พร้อมแล้ว คุณก็สามารถดำเนินการติดตั้งได้ การเตรียมการนี้ช่วยให้การทำงานราบรื่นและเพิ่มปริมาณงานสูงสุด
ข้อกำหนดด้านฮาร์ดแวร์และซอฟต์แวร์สำหรับการใช้งาน Mistral 3 บนเครื่อง
ก่อนที่จะเปิดใช้งาน Mistral 3 ให้ประเมินความสามารถของระบบของคุณ ข้อกำหนดขั้นต่ำ ได้แก่ CPU ที่ทันสมัย (Intel i7 หรือ AMD Ryzen 7) พร้อม RAM 16GB สำหรับโมเดล 3B สำหรับรุ่น 8B และ 14B ให้จัดสรร RAM 32GB และ NVIDIA GPU ที่มี VRAM อย่างน้อย 8GB — เช่น RTX 3060 หรือดีกว่า ผู้ใช้ Apple Silicon ได้รับประโยชน์จากหน่วยความจำรวม (unified memory); M1 Pro ที่มี 16GB สามารถจัดการ 3B ได้อย่างง่ายดาย ในขณะที่ M3 Max ทำงานได้ดีเยี่ยมกับ 14B
ความต้องการพื้นที่เก็บข้อมูลแตกต่างกันไป: โมเดล 3B ที่ถูกควอนไทซ์จะใช้พื้นที่ประมาณ 2GB ซึ่งเพิ่มเป็นประมาณ 9GB สำหรับ 14B ใช้ SSD เพื่อการโหลดที่เร็วขึ้น ระบบปฏิบัติการ? Linux (Ubuntu 22.04) ให้ประสิทธิภาพดีที่สุด ตามด้วย macOS Ventura+ Windows 11 ทำงานได้ผ่าน WSL2 แม้ว่าการส่งผ่าน GPU จะต้องมีการปรับแต่งเล็กน้อย
ในด้านซอฟต์แวร์ Python 3.10+ เป็นหัวใจหลัก ติดตั้ง CUDA 12.1 สำหรับการ์ด NVIDIA เพื่อเปิดใช้งานการเร่งความเร็ว GPU ซึ่งจำเป็นสำหรับการตอบสนองที่น้อยกว่า 100 มิลลิวินาที สำหรับการรันด้วย CPU เท่านั้น ให้ใช้ไลบรารีอย่าง ONNX Runtime
การควอนไทซ์มีบทบาทสำคัญที่นี่ Mistral 3 รองรับรูปแบบ 4 บิตและ 8 บิต ซึ่งช่วยลดการใช้หน่วยความจำลง 75% ในขณะที่ยังคงความแม่นยำไว้ที่ 95% เครื่องมืออย่าง bitsandbytes จะจัดการสิ่งนี้โดยอัตโนมัติ
เมื่ออุปกรณ์พร้อมแล้ว การติดตั้งก็เป็นไปอย่างตรงไปตรงมา เราแนะนำ Ollama เนื่องจากความเรียบง่าย แต่ก็มีทางเลือกอื่นอยู่ การเลือกนี้จะช่วยให้กระบวนการเป็นไปอย่างราบรื่น นำไปสู่ขั้นตอนการตั้งค่าหลักของเรา
การติดตั้ง Ollama: ประตูสู่ AI ในเครื่องที่ง่ายดาย
Ollama โดดเด่นในฐานะเครื่องมือชั้นนำสำหรับการรันโมเดลโอเพนซอร์ส เช่น Mistral 3 บนเครื่องของคุณ แพลตฟอร์มน้ำหนักเบานี้ช่วยลดความซับซ้อน โดยนำเสนอ CLI และ API server ในแพ็คเกจเดียว นักพัฒนาชื่นชอบการรองรับหลายแพลตฟอร์มและการตรวจจับ GPU แบบไม่ต้องตั้งค่า
เริ่มต้นด้วยการดาวน์โหลด Ollama จากเว็บไซต์ทางการ (ollama.com) บน Linux ให้รัน:
curl -fsSL https://ollama.com/install.sh | sh
สคริปต์นี้จะติดตั้งไบนารีและตั้งค่าบริการ ตรวจสอบด้วย ollama --version; คาดว่าจะได้เอาต์พุตเช่น "ollama version 0.3.0" สำหรับ macOS ตัวติดตั้ง DMG จะจัดการการพึ่งพิง รวมถึง Rosetta สำหรับการจำลอง Intel บน ARM
ผู้ใช้ Windows สามารถดาวน์โหลดไฟล์ EXE จาก GitHub releases หลังการติดตั้ง ให้เปิดใช้งานผ่าน PowerShell: ollama serve Ollama จะทำงานเป็น daemon ในพื้นหลัง โดยเปิดเผย REST API บนพอร์ต 11434
ทำไมต้อง Ollama? มันดึงโมเดลจาก registry ของมัน รวมถึง Ministral 3 ด้วยการควอนไทซ์ในตัว ไม่จำเป็นต้องโคลน Hugging Face ด้วยตนเอง นอกจากนี้ยังรองรับ Modelfiles สำหรับการปรับแต่งเพิ่มเติม ซึ่งสอดคล้องกับหลักการโอเพนซอร์สของ Mistral 3
เมื่อ Ollama พร้อม คุณก็จะสามารถดึงและรันโมเดลได้ในขั้นตอนต่อไป ขั้นตอนนี้จะเปลี่ยนการตั้งค่าของคุณให้เป็นเวิร์กสเตชัน AI ที่ใช้งานได้
การดึงและรันโมเดล Ministral 3 ด้วย Ollama
ไลบรารีของ Ollama โฮสต์ Mistral 3 รุ่นต่างๆ
เริ่มต้นด้วยการแสดงรายการแท็กที่มีอยู่:
ollama list
หากต้องการดาวน์โหลดโมเดล 3B:
ollama pull ministral:3b-instruct-q4_0
คำสั่งนี้จะดึงข้อมูลประมาณ 2GB โดยตรวจสอบความสมบูรณ์ผ่านแฮช แถบความคืบหน้าจะติดตามการดาวน์โหลด ซึ่งโดยทั่วไปจะเสร็จสิ้นภายในไม่กี่นาทีบนอินเทอร์เน็ตความเร็วสูง
เปิดเซสชันแบบโต้ตอบ:
ollama run ministral-3
Ollama จะโหลดโมเดลเข้าสู่หน่วยความจำ เตรียมแคชสำหรับการสืบค้นครั้งต่อไป พิมพ์พร้อมต์โดยตรง ตัวอย่างเช่น:
>> Explain quantum entanglement in simple terms.

โมเดลจะตอบสนองแบบเรียลไทม์ โดยใช้ประโยชน์จากการปรับแต่งคำสั่งเพื่อให้ได้ผลลัพธ์ที่สอดคล้องกัน ออกจากระบบด้วย /bye
กำลังแก้ไขปัญหาทั่วไปอยู่ใช่ไหม? หาก GPU ทำงานไม่เต็มประสิทธิภาพ ให้ตั้งค่าตัวแปรสภาพแวดล้อม OLLAMA_NUM_GPU=999 สำหรับข้อผิดพลาด OOM ให้ลดการควอนไทซ์ลง เช่น q3_K_M
นอกเหนือจากพื้นฐานแล้ว API ของ Ollama ยังช่วยให้เข้าถึงแบบโปรแกรมได้ Curl เพื่อดูผลลัพธ์:
curl http://localhost:11434/api/generate -d '{
"model": "ministral:3b-instruct-q4_0",
"prompt": "Write a Python function to sort a list.",
"stream": false
}'
การตอบกลับ JSON นี้มีข้อความที่สร้างขึ้น ซึ่งเหมาะสำหรับการผสานรวมกับ Apidog ในระหว่างการพัฒนา API
การรันโมเดลเป็นเพียงจุดเริ่มต้น การเพิ่มประสิทธิภาพจะช่วยยกระดับการทำงาน ดังนั้น เราจึงหันมาใช้เทคนิคที่รีดเค้นประสิทธิภาพสูงสุดจากฮาร์ดแวร์ของคุณ
การปรับปรุงประสิทธิภาพการอนุมานของ Mistral 3: ความเร็ว, หน่วยความจำ, และความแม่นยำ
ประสิทธิภาพคือตัวกำหนดความสำเร็จของ AI ในเครื่อง การออกแบบของ Mistral 3 โดดเด่นที่นี่ แต่การปรับแต่งเล็กน้อยก็สามารถเพิ่มประสิทธิภาพได้ เริ่มต้นด้วยการควอนไทซ์: Ollama จะตั้งค่าเริ่มต้นเป็น Q4_0 ซึ่งเป็นการรักษาสมดุลระหว่างขนาดและความถูกต้อง สำหรับทรัพยากรที่จำกัดมากๆ ลองใช้ Q2_K ซึ่งลดหน่วยความจำลงครึ่งหนึ่งโดยมีค่าความซับซ้อนเพิ่มขึ้น 10%
การจัดสรร GPU เป็นสิ่งสำคัญ เปิดใช้งาน flash attention ผ่าน OLLAMA_FLASH_ATTENTION=1 เพื่อเพิ่มความเร็วเป็น 2 เท่าสำหรับบริบทที่ยาว Mistral 3 รองรับโทเค็นสูงสุด 128K; ทดสอบด้วยพร้อมต์สไตล์ GPQA เพื่อตรวจสอบความแม่นยำที่ยั่งยืน
การประมวลผลแบบแบตช์ช่วยเพิ่มปริมาณงาน ใช้ /api/generate ของ Ollama กับพร้อมต์หลายรายการแบบขนาน โดยใช้ประโยชน์จากไคลเอ็นต์ Python แบบ asynchronous ตัวอย่างเช่น สคริปต์ลูป:
import requests
import json
model = "ministral:8b-instruct-q4_0"
url = "http://localhost:11434/api/generate"
prompts = ["Prompt 1", "Prompt 2"]
for p in prompts:
response = requests.post(url, json={"model": model, "prompt": p})
print(json.loads(response.text)["response"])
สิ่งนี้สามารถจัดการการสืบค้นได้มากกว่า 10 รายการต่อวินาทีบนระบบหลายคอร์
การจัดการหน่วยความจำช่วยป้องกันการสลับข้อมูล ตรวจสอบด้วย nvidia-smi; ถ่ายโหลดเลเยอร์ไปยัง CPU หาก VRAM เต็ม ไลบรารีอย่าง vLLM ผสานรวมกับ Ollama เพื่อการประมวลผลแบบแบตช์ต่อเนื่อง รักษาอัตรา 100 โทเค็นต่อวินาทีบน A100
การปรับแต่งความแม่นยำ? ปรับแต่งเพิ่มเติมด้วย LoRA adapters บนข้อมูลโดเมน ไลบรารี PEFT ของ Hugging Face ใช้สิ่งเหล่านี้กับ Ministral 3 โดยต้องใช้พื้นที่เพิ่มประมาณ 1GB หลังจากปรับแต่งแล้ว ให้ส่งออกไปยังรูปแบบ Ollama ผ่าน ollama create
วัดประสิทธิภาพการตั้งค่าของคุณเทียบกับ GPQA Diamond สร้างสคริปต์การประเมินเพื่อพล็อตความแม่นยำเทียบกับโทเค็น สะท้อนแผนภูมิของ Mistral รุ่นที่มีประสิทธิภาพสูงอย่าง Ministral 8B ยังคงรักษาคะแนนมากกว่า 50% ซึ่งเน้นย้ำถึงความได้เปรียบเหนือ Qwen 2.5 VL
การเพิ่มประสิทธิภาพเหล่านี้จะเตรียมคุณให้พร้อมสำหรับการใช้งานขั้นสูง ดังนั้น เราจะสำรวจการผสานรวมที่ช่วยขยายขอบเขตของ Mistral 3
การผสานรวม Mistral 3 เข้ากับเครื่องมือพัฒนา: API และอื่นๆ
Mistral 3 ที่รันบนเครื่องสามารถเติบโตได้ดีในระบบนิเวศต่างๆ จับคู่กับ Apidog เพื่อสร้าง API จำลองที่ขับเคลื่อนด้วย AI ออกแบบ endpoints ที่เรียกใช้ Ollama, ทดสอบ payload และตรวจสอบการตอบสนอง ทั้งหมดนี้สามารถทำได้แบบออฟไลน์
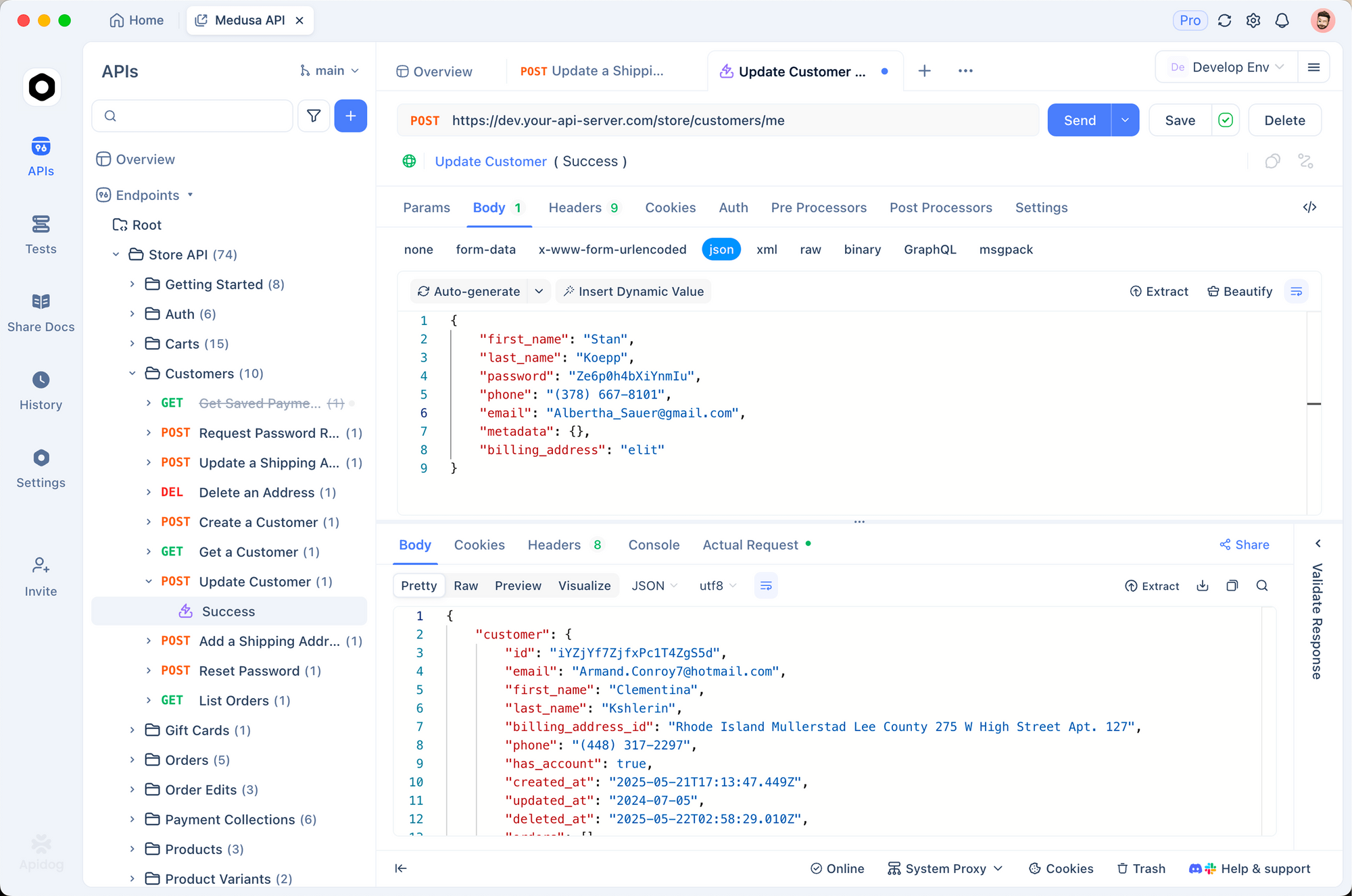
ตัวอย่างเช่น สร้างเส้นทาง POST /generate ใน Apidog ซึ่งจะส่งต่อไปยัง API ของ Ollama นำเข้าคอลเลกชันสำหรับแม่แบบพร้อมต์ เพื่อให้แน่ใจว่า Mistral 3 สามารถจัดการคำขอหลายภาษาได้อย่างไร้ที่ติ
ผู้ใช้ LangChain เชื่อมโยง Mistral 3 กับเครื่องมือ:
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
llm = OllamaLLM(model="ministral:3b-instruct-q4_0")
prompt = PromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello world"}))
การตั้งค่านี้ประมวลผลการสืบค้นได้ 50 รายการต่อนาที ซึ่งเหมาะสำหรับ RAG pipelines
แดชบอร์ด Streamlit แสดงผลลัพธ์ ฝังการเรียกใช้ Ollama ในแอปสำหรับแชทแบบโต้ตอบ โดยใช้ประโยชน์จากการให้เหตุผลของ Mistral 3 สำหรับการถามตอบแบบไดนามิก
ข้อควรพิจารณาด้านความปลอดภัย? รัน Ollama หลัง NGINX proxies โดยจำกัดอัตราการเรียกใช้ endpoints สำหรับการใช้งานจริง ให้บรรจุใน Docker:
FROM ollama/ollama
COPY Modelfile .
RUN ollama create mistral-local -f Modelfile
สิ่งนี้แยกสภาพแวดล้อมออกจากกัน และสามารถปรับขนาดไปสู่ Kubernetes ได้
เมื่อแอปพลิเคชันพัฒนาไป การตรวจสอบจึงกลายเป็นสิ่งสำคัญ เครื่องมืออย่าง Prometheus จะติดตามความหน่วง แจ้งเตือนเมื่อเกิดความคลาดเคลื่อนจากประสิทธิภาพพื้นฐาน
โดยสรุป การผสานรวมเหล่านี้เปลี่ยน Mistral 3 จากโมเดลเดี่ยวให้เป็นเอนจินอเนกประสงค์ อย่างไรก็ตาม ความท้าทายก็เกิดขึ้น การแก้ไขปัญหาเหล่านี้ช่วยให้มั่นใจได้ถึงการติดตั้งใช้งานที่แข็งแกร่ง
การแก้ไขปัญหาทั่วไปในการรัน Mistral 3 บนเครื่อง
แม้แต่การตั้งค่าที่ปรับให้เหมาะสมก็ยังพบกับอุปสรรค ปัญหา CUDA ไม่ตรงกันเป็นอันดับแรก: ตรวจสอบเวอร์ชันด้วย nvcc --version หากเกิดความขัดแย้ง ให้ลดระดับลง เนื่องจาก Mistral 3 รองรับเวอร์ชัน 11.8+
การโหลดโมเดลล้มเหลว? ล้างแคช Ollama: ollama rm ministral:3b-instruct-q4_0 แล้วดึงใหม่ การดาวน์โหลดที่เสียหายเกิดจากเครือข่าย; ใช้ --insecure อย่างระมัดระวัง
บน macOS การเร่งความเร็วด้วย Metal ช้ากว่า CUDA บังคับใช้ CPU เพื่อความเสถียร: OLLAMA_METAL=0 ผู้ใช้ Windows WSL เปิดใช้งานไดรเวอร์ NVIDIA ผ่าน wsl --update
ความร้อนเกินเป็นปัญหาของแล็ปท็อป; ควบคุมด้วย nvidia-smi -pl 100 เพื่อจำกัดพลังงาน สำหรับความแม่นยำที่ลดลง ให้ตรวจสอบพร้อมต์—Ministral 3 เก่งในรูปแบบคำสั่ง
ฟอรัมชุมชนบน Reddit และ Hugging Face สามารถแก้ไขกรณีพิเศษได้ 90% บันทึกข้อผิดพลาดด้วย OLLAMA_DEBUG=1 สำหรับการวินิจฉัย
เมื่อผ่านพ้นอุปสรรคต่างๆ แล้ว Mistral 3 ก็มอบมูลค่าที่สอดคล้องกัน ในที่สุด เราก็มาพิจารณาถึงผลกระทบที่กว้างขึ้นของมัน
สรุป: ใช้ประโยชน์จาก Mistral 3 บนเครื่องของคุณสำหรับนวัตกรรม AI แห่งอนาคต
Mistral 3 นิยามใหม่ของ AI โอเพนซอร์สด้วยการผสมผสานระหว่างพลังและประโยชน์ใช้สอยจริง การรันบนเครื่องผ่าน Ollama ทำให้นักพัฒนาได้รับความเร็ว ความเป็นส่วนตัว และการควบคุมต้นทุนที่ไม่สามารถหาได้จากที่อื่น ตั้งแต่การดึงโมเดลไปจนถึงการปรับแต่งการผสานรวม คู่มือนี้จะให้ขั้นตอนที่สามารถนำไปปฏิบัติได้จริงแก่คุณ
ทดลองอย่างกล้าหาญ: เริ่มต้นด้วยรุ่น 3B ขยายไปถึง 14B และวัดผลเทียบกับเกณฑ์มาตรฐาน ในขณะที่ Mistral AI ทำซ้ำ การรันบนเครื่องจะทำให้คุณก้าวล้ำหน้า
พร้อมที่จะสร้างแล้วหรือยัง? ดาวน์โหลด Apidog ได้ฟรี และสร้างต้นแบบ API ที่ขับเคลื่อนโดยการตั้งค่า Mistral 3 ของคุณ อนาคตของ AI ที่มีประสิทธิภาพเริ่มต้นบนเครื่องของคุณ—จงทำให้มันมีค่า