การรันโมเดลภาษาขนาดใหญ่ (LLMs) บนเครื่องของคุณเอง ช่วยให้ผู้พัฒนาได้รับความเป็นส่วนตัว การควบคุม และประหยัดค่าใช้จ่าย โมเดลแบบ open-weight ของ OpenAI ซึ่งรวมกันเรียกว่า GPT-OSS (gpt-oss-120b และ gpt-oss-20b) นำเสนอความสามารถในการให้เหตุผลอันทรงพลังสำหรับงานต่างๆ เช่น การเขียนโค้ด เวิร์กโฟลว์แบบเอเจนท์ และการวิเคราะห์ข้อมูล ด้วย Ollama ซึ่งเป็นแพลตฟอร์มโอเพนซอร์ส คุณสามารถปรับใช้โมเดลเหล่านี้บนฮาร์ดแวร์ของคุณเองได้โดยไม่ต้องพึ่งพาคลาวด์ คู่มือทางเทคนิคนี้จะแนะนำคุณเกี่ยวกับการติดตั้ง Ollama การกำหนดค่าโมเดล GPT-OSS และการดีบักด้วย Apidog ซึ่งเป็นเครื่องมือที่ช่วยให้การทดสอบ API สำหรับ LLMs ในเครื่องง่ายขึ้น
ทำไมต้องรัน GPT-OSS บนเครื่องด้วย Ollama?
การรัน GPT-OSS บนเครื่องโดยใช้ Ollama มอบข้อได้เปรียบที่แตกต่างกันสำหรับนักพัฒนาและนักวิจัย ประการแรก ช่วยให้มั่นใจได้ถึง ความเป็นส่วนตัวของข้อมูล เนื่องจากข้อมูลอินพุตและเอาต์พุตของคุณยังคงอยู่ในเครื่องของคุณ ประการที่สอง ช่วยลดค่าใช้จ่าย API ของคลาวด์ที่เกิดขึ้นซ้ำๆ ทำให้เหมาะสำหรับการใช้งานที่มีปริมาณมากหรือการทดลอง ประการที่สาม ความเข้ากันได้ของ Ollama กับโครงสร้าง API ของ OpenAI ช่วยให้สามารถรวมเข้ากับเครื่องมือที่มีอยู่ได้อย่างราบรื่น ในขณะที่การสนับสนุนโมเดลแบบ Quantized เช่น gpt-oss-20b (ซึ่งต้องการหน่วยความจำเพียง 16GB) ช่วยให้สามารถเข้าถึงได้บนฮาร์ดแวร์ที่ไม่สูงมาก

นอกจากนี้ Ollama ยังช่วยลดความซับซ้อนของการปรับใช้ LLM อีกด้วย โดยจะจัดการกับน้ำหนักโมเดล (model weights) การพึ่งพา (dependencies) และการกำหนดค่าผ่าน Modelfile เดียวกัน ซึ่งคล้ายกับ Docker container สำหรับ AI เมื่อจับคู่กับ Apidog ซึ่งนำเสนอการแสดงผลแบบเรียลไทม์ของการตอบสนอง AI แบบสตรีมมิ่ง คุณจะได้รับระบบนิเวศที่แข็งแกร่งสำหรับการพัฒนา AI ในเครื่อง ถัดไป เรามาสำรวจข้อกำหนดเบื้องต้นสำหรับการตั้งค่าสภาพแวดล้อมนี้กัน
ข้อกำหนดเบื้องต้นสำหรับการรัน GPT-OSS บนเครื่อง
ก่อนดำเนินการต่อ ตรวจสอบให้แน่ใจว่าระบบของคุณตรงตามข้อกำหนดต่อไปนี้:
- ฮาร์ดแวร์:
- สำหรับ gpt-oss-20b: RAM ขั้นต่ำ 16GB โดยมี GPU (เช่น NVIDIA 1060 4GB) จะดีที่สุด
- สำหรับ gpt-oss-120b: หน่วยความจำ GPU 80GB (เช่น GPU 80GB ตัวเดียว หรือการตั้งค่าศูนย์ข้อมูลระดับสูง)
- พื้นที่เก็บข้อมูลว่าง 20-50GB สำหรับน้ำหนักโมเดลและการพึ่งพา
- ซอฟต์แวร์:
- ระบบปฏิบัติการ: แนะนำ Linux หรือ macOS; รองรับ Windows โดยต้องมีการตั้งค่าเพิ่มเติม
- Ollama: ดาวน์โหลดจาก ollama.com
- ทางเลือก: Docker สำหรับรัน Open WebUI หรือ Apidog สำหรับการทดสอบ API
- อินเทอร์เน็ต: การเชื่อมต่อที่เสถียรสำหรับการดาวน์โหลดโมเดลครั้งแรก
- การพึ่งพา: ไดรเวอร์ NVIDIA/AMD GPU หากใช้การเร่งด้วย GPU; โหมด CPU-only ทำงานได้แต่ช้ากว่า
เมื่อเตรียมสิ่งเหล่านี้พร้อมแล้ว คุณก็พร้อมที่จะติดตั้ง Ollama และปรับใช้ GPT-OSS ไปยังขั้นตอนการติดตั้งกันเลย
ขั้นตอนที่ 1: การติดตั้ง Ollama บนระบบของคุณ
การติดตั้ง Ollama นั้นตรงไปตรงมา รองรับ macOS, Linux และ Windows ทำตามขั้นตอนเหล่านี้เพื่อตั้งค่า:
ดาวน์โหลด Ollama:
- เยี่ยมชม ollama.com และดาวน์โหลดตัวติดตั้งสำหรับ OS ของคุณ
- สำหรับ Linux/macOS ให้ใช้คำสั่งเทอร์มินัล:
curl -fsSL https://ollama.com/install.sh | sh
สคริปต์นี้จะดำเนินการดาวน์โหลดและตั้งค่าโดยอัตโนมัติ
ยืนยันการติดตั้ง:
- รัน
ollama --versionในเทอร์มินัลของคุณ คุณควรเห็นหมายเลขเวอร์ชัน (เช่น 0.1.44) หากไม่เห็น ให้ตรวจสอบ Ollama GitHub สำหรับการแก้ไขปัญหา
เริ่มเซิร์ฟเวอร์ Ollama:
- รัน
ollama serveเพื่อเปิดเซิร์ฟเวอร์ ซึ่งจะฟังที่http://localhost:11434ให้เทอร์มินัลนี้ทำงานอยู่ หรือกำหนดค่า Ollama เป็นบริการเบื้องหลังสำหรับการใช้งานอย่างต่อเนื่อง
เมื่อติดตั้งแล้ว Ollama ก็พร้อมที่จะดาวน์โหลดและรันโมเดล GPT-OSS ไปยังการดาวน์โหลดโมเดลกันเลย
ขั้นตอนที่ 2: การดาวน์โหลดโมเดล GPT-OSS
โมเดล GPT-OSS ของ OpenAI (gpt-oss-120b และ gpt-oss-20b) มีให้ใช้งานบน Hugging Face และได้รับการปรับให้เหมาะสมสำหรับ Ollama ด้วยการ Quantization แบบ MXFP4 ซึ่งช่วยลดความต้องการหน่วยความจำ ทำตามขั้นตอนเหล่านี้เพื่อดาวน์โหลด:
เลือกโมเดล:
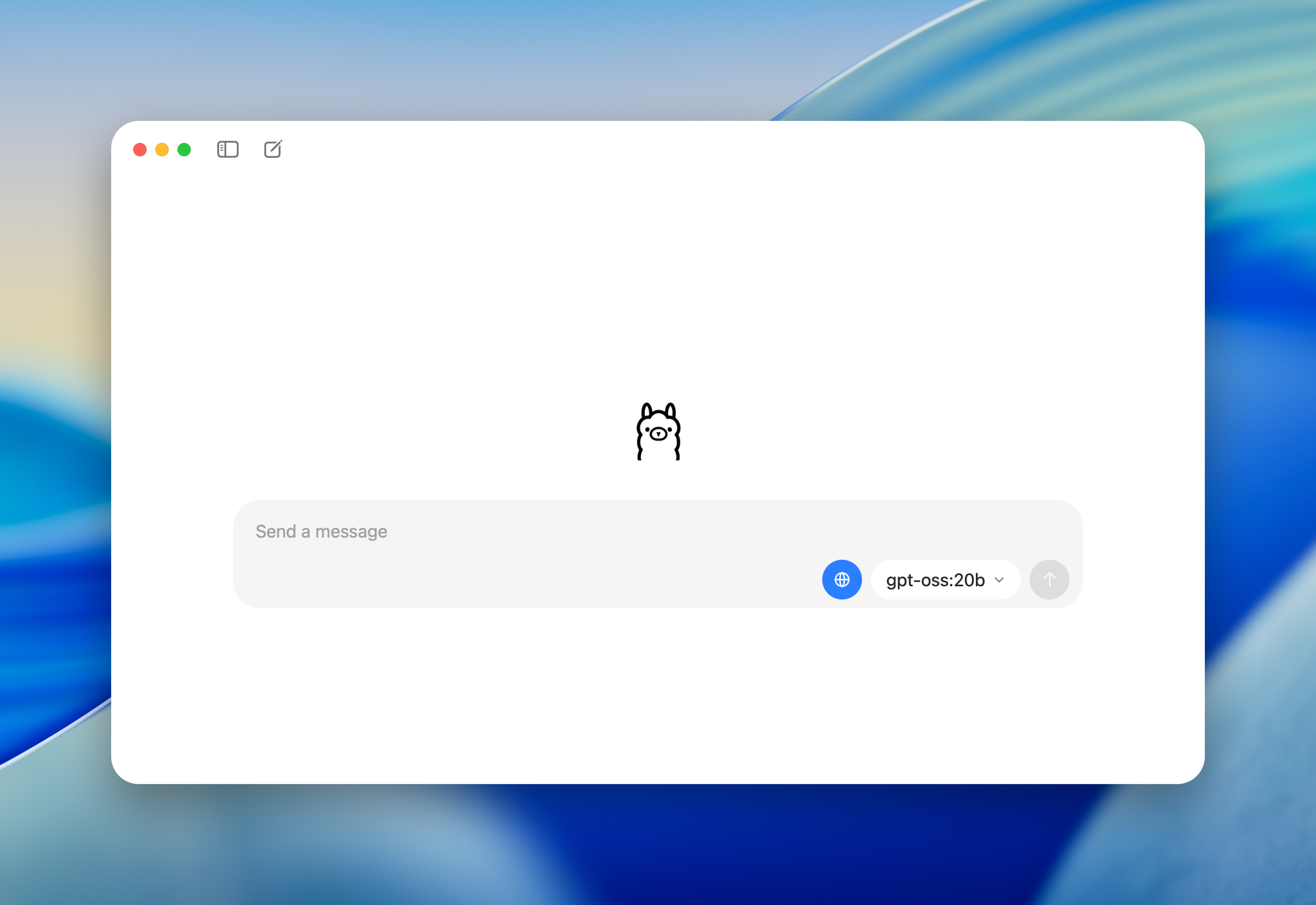
- gpt-oss-20b: เหมาะสำหรับเดสก์ท็อป/แล็ปท็อปที่มี RAM 16GB มันจะเปิดใช้งาน 3.6 พันล้านพารามิเตอร์ต่อโทเค็น เหมาะสำหรับอุปกรณ์ Edge
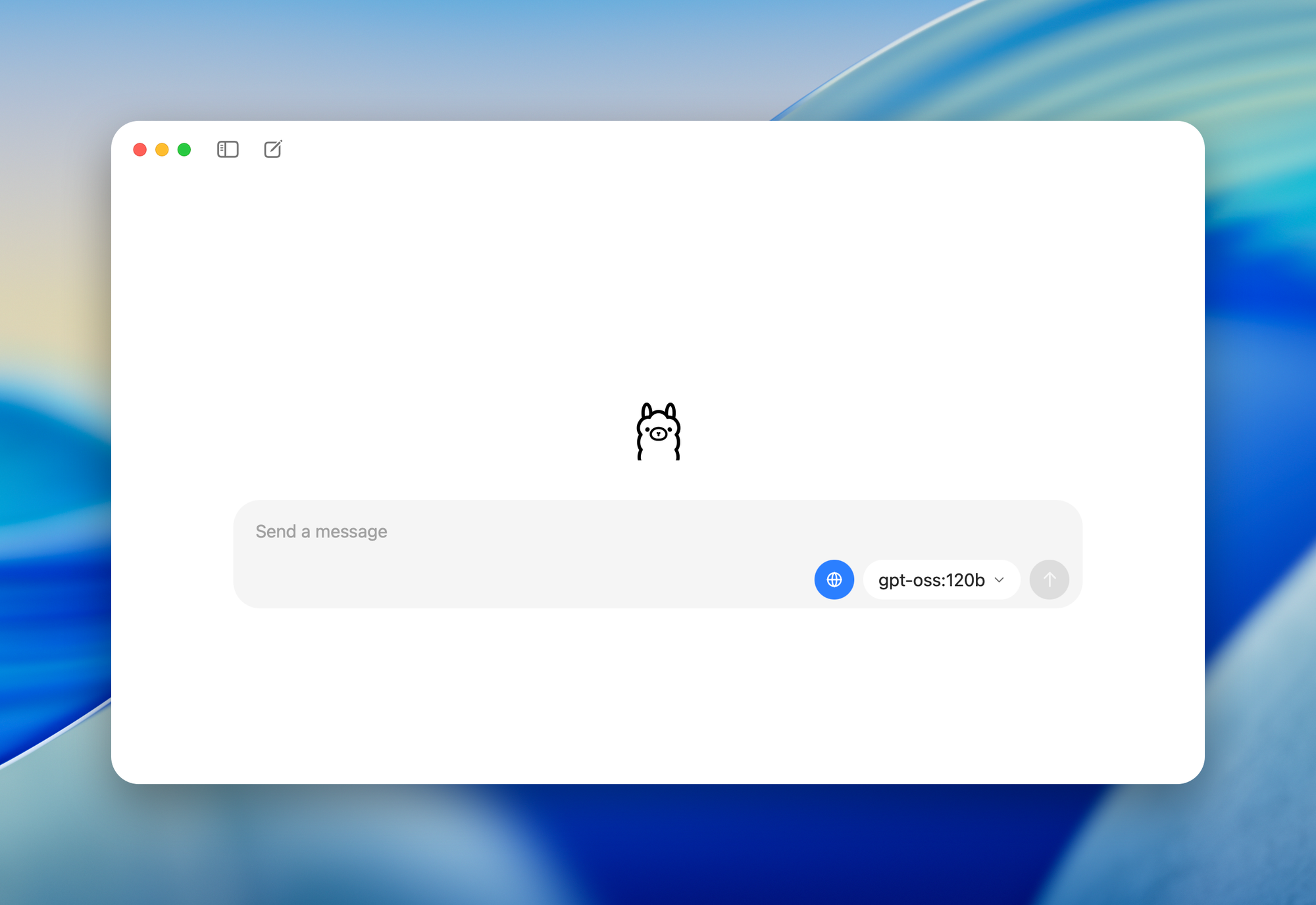
- gpt-oss-120b: ออกแบบมาสำหรับศูนย์ข้อมูลหรือ GPU ระดับสูงที่มีหน่วยความจำ 80GB โดยเปิดใช้งาน 5.1 พันล้านพารามิเตอร์ต่อโทเค็น
ดาวน์โหลดผ่าน Ollama:
- ในเทอร์มินัลของคุณ ให้รัน:
ollama pull gpt-oss-20b
หรือ
ollama pull gpt-oss-120b
ขึ้นอยู่กับฮาร์ดแวร์ของคุณ การดาวน์โหลด (20-50GB) อาจใช้เวลา ตรวจสอบให้แน่ใจว่ามีการเชื่อมต่ออินเทอร์เน็ตที่เสถียร
ยืนยันการดาวน์โหลด:
- แสดงรายการโมเดลที่ติดตั้งด้วย:
ollama list
มองหา gpt-oss-20b:latest หรือ gpt-oss-120b:latest
เมื่อดาวน์โหลดโมเดลแล้ว คุณสามารถรันมันบนเครื่องได้เลย มาสำรวจวิธีการโต้ตอบกับ GPT-OSS กัน
ขั้นตอนที่ 3: การรันโมเดล GPT-OSS ด้วย Ollama
Ollama มีหลายวิธีในการโต้ตอบกับโมเดล GPT-OSS: อินเทอร์เฟซบรรทัดคำสั่ง (CLI), API หรืออินเทอร์เฟซแบบกราฟิก เช่น Open WebUI เรามาเริ่มต้นด้วย CLI เพื่อความเรียบง่าย
เปิดเซสชันแบบโต้ตอบ:
- รัน:
ollama run gpt-oss-20b
สิ่งนี้จะเปิดเซสชันแชทแบบเรียลไทม์ พิมพ์คำถามของคุณ (เช่น “เขียนฟังก์ชัน Python สำหรับการค้นหาแบบไบนารี”) แล้วกด Enter ใช้ /help สำหรับคำสั่งพิเศษ
การค้นหาแบบครั้งเดียว:
- สำหรับการตอบสนองที่รวดเร็วโดยไม่ต้องใช้โหมดโต้ตอบ ให้ใช้:
ollama run gpt-oss-20b "Explain quantum computing in simple terms"
ปรับพารามิเตอร์:
- ปรับเปลี่ยนพฤติกรรมของโมเดลด้วยพารามิเตอร์เช่น temperature (ความคิดสร้างสรรค์) และ top-p (ความหลากหลายของการตอบสนอง) ตัวอย่างเช่น:
ollama run gpt-oss-20b --temperature 0.1 --top-p 1.0 "Write a factual summary of blockchain technology"
ค่า temperature ที่ต่ำกว่า (เช่น 0.1) จะให้ผลลัพธ์ที่เป็นข้อเท็จจริงและกำหนดได้ ซึ่งเหมาะสำหรับงานทางเทคนิค
ถัดไป เรามาปรับแต่งพฤติกรรมของโมเดลโดยใช้ Modelfiles สำหรับกรณีการใช้งานเฉพาะกัน
ขั้นตอนที่ 4: การปรับแต่ง GPT-OSS ด้วย Ollama Modelfiles
Modelfiles ของ Ollama ช่วยให้คุณสามารถปรับแต่งพฤติกรรม GPT-OSS ได้โดยไม่ต้องฝึกซ้ำ คุณสามารถตั้งค่า system prompts ปรับขนาด context หรือ fine-tune พารามิเตอร์ได้ นี่คือวิธีการสร้างโมเดลที่กำหนดเอง:
สร้าง Modelfile:
- สร้างไฟล์ชื่อ
Modelfileด้วย:
FROM gpt-oss-20b
SYSTEM "You are a technical assistant specializing in Python programming. Provide concise, accurate code with comments."
PARAMETER temperature 0.5
PARAMETER num_ctx 4096
สิ่งนี้จะกำหนดค่าโมเดลให้เป็นผู้ช่วยที่เน้น Python โดยมีความคิดสร้างสรรค์ปานกลางและหน้าต่าง context 4k โทเค็น
สร้างโมเดลที่กำหนดเอง:
- ไปยังไดเรกทอรีที่มี Modelfile และรัน:
ollama create python-gpt-oss -f Modelfile
รันโมเดลที่กำหนดเอง:
- เปิดใช้งานด้วย:
ollama run python-gpt-oss
ตอนนี้ โมเดลจะจัดลำดับความสำคัญของการตอบสนองที่เกี่ยวข้องกับ Python ด้วยพฤติกรรมที่ระบุ
การปรับแต่งนี้ช่วยเพิ่มประสิทธิภาพ GPT-OSS สำหรับโดเมนเฉพาะ เช่น การเขียนโค้ดหรือเอกสารทางเทคนิค ตอนนี้ เรามาผสานรวมโมเดลเข้ากับแอปพลิเคชันโดยใช้ Ollama API กัน
ขั้นตอนที่ 5: การผสานรวม GPT-OSS กับ Ollama API
API ของ Ollama ซึ่งทำงานบน http://localhost:11434 ช่วยให้สามารถเข้าถึง GPT-OSS แบบโปรแกรมได้ ซึ่งเหมาะสำหรับนักพัฒนาที่สร้างแอปพลิเคชันที่ขับเคลื่อนด้วย AI นี่คือวิธีการใช้งาน:
API Endpoints:
- POST /api/generate: สร้างข้อความสำหรับพรอมต์เดียว ตัวอย่าง:
curl http://localhost:11434/api/generate -H "Content-Type: application/json" -d '{"model": "gpt-oss-20b", "prompt": "Write a Python script for a REST API"}'
- POST /api/chat: รองรับการโต้ตอบแบบสนทนาพร้อมประวัติข้อความ:
curl http://localhost:11434/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "gpt-oss-20b", "messages": [{"role": "user", "content": "Explain neural networks"}]}'
- POST /api/embeddings: สร้าง vector embeddings สำหรับงานเชิงความหมาย เช่น การค้นหาหรือการจัดประเภท
ความเข้ากันได้กับ OpenAI:
- Ollama รองรับรูปแบบ OpenAI Chat Completions API ใช้ Python กับไลบรารี OpenAI:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama")
response = client.chat.completions.create(
model="gpt-oss-20b",
messages=[{"role": "user", "content": "What is machine learning?"}]
)
print(response.choices[0].message.content)
การผสานรวม API นี้ช่วยให้ GPT-OSS สามารถขับเคลื่อนแชทบอท ตัวสร้างโค้ด หรือเครื่องมือวิเคราะห์ข้อมูลได้ อย่างไรก็ตาม การดีบักการตอบสนองแบบสตรีมมิ่งอาจเป็นเรื่องที่ท้าทาย มาดูกันว่า Apidog ทำให้สิ่งนี้ง่ายขึ้นได้อย่างไร
ขั้นตอนที่ 6: การดีบัก GPT-OSS ด้วย Apidog
Apidog เป็นเครื่องมือทดสอบ API อันทรงพลังที่แสดงภาพการตอบสนองแบบสตรีมมิ่งจาก Ollama endpoints ทำให้ง่ายต่อการดีบักเอาต์พุต GPT-OSS นี่คือวิธีการใช้งาน:
ติดตั้ง Apidog:
- ดาวน์โหลด Apidog จาก apidog.com และติดตั้งบนระบบของคุณ
กำหนดค่า Ollama API ใน Apidog:
- สร้างคำขอ API ใหม่ใน Apidog
- ตั้งค่า URL เป็น
http://localhost:11434/api/generate - ใช้ JSON body เช่น:
{
"model": "gpt-oss-20b",
"prompt": "Generate a Python function for sorting",
"stream": true
}
แสดงภาพการตอบสนอง:
- Apidog จะรวมโทเค็นที่สตรีมเข้ามาเป็นรูปแบบที่อ่านง่าย ซึ่งแตกต่างจากเอาต์พุต JSON ดิบ สิ่งนี้ช่วยระบุปัญหาการจัดรูปแบบหรือข้อผิดพลาดทางตรรกะในการให้เหตุผลของโมเดล
- ใช้การวิเคราะห์เหตุผลของ Apidog เพื่อตรวจสอบกระบวนการคิดทีละขั้นตอนของ GPT-OSS โดยเฉพาะสำหรับงานที่ซับซ้อน เช่น การเขียนโค้ดหรือการแก้ปัญหา
การทดสอบเปรียบเทียบ:
- สร้างคอลเลกชันพรอมต์ใน Apidog เพื่อทดสอบว่าพารามิเตอร์ต่างๆ (เช่น temperature, top-p) ส่งผลต่อเอาต์พุต GPT-OSS อย่างไร สิ่งนี้ช่วยให้มั่นใจได้ถึงประสิทธิภาพของโมเดลที่เหมาะสมที่สุดสำหรับกรณีการใช้งานของคุณ
การแสดงภาพของ Apidog เปลี่ยนการดีบักจากงานที่น่าเบื่อให้เป็นกระบวนการที่ชัดเจนและนำไปปฏิบัติได้ ซึ่งช่วยเพิ่มประสิทธิภาพเวิร์กโฟลว์การพัฒนาของคุณ ตอนนี้ เรามาแก้ไขปัญหาทั่วไปที่คุณอาจพบกัน
ขั้นตอนที่ 7: การแก้ไขปัญหาทั่วไป
การรัน GPT-OSS บนเครื่องอาจนำเสนอความท้าทาย นี่คือวิธีแก้ไขปัญหาที่พบบ่อย:
ข้อผิดพลาดหน่วยความจำ GPU:
- ปัญหา: gpt-oss-120b ล้มเหลวเนื่องจากหน่วยความจำ GPU ไม่เพียงพอ
- วิธีแก้ไข: เปลี่ยนไปใช้ gpt-oss-20b หรือตรวจสอบให้แน่ใจว่าระบบของคุณมี GPU 80GB ตรวจสอบการใช้หน่วยความจำด้วย
nvidia-smi
โมเดลไม่เริ่มทำงาน:
- ปัญหา:
ollama runล้มเหลวพร้อมข้อผิดพลาด - วิธีแก้ไข: ตรวจสอบว่าดาวน์โหลดโมเดลแล้ว (
ollama list) และเซิร์ฟเวอร์ Ollama กำลังทำงานอยู่ (ollama serve) ตรวจสอบบันทึกใน~/.ollama/logs
API ไม่ตอบสนอง:
- ปัญหา: คำขอ API ไปยัง
localhost:11434ล้มเหลว - วิธีแก้ไข: ตรวจสอบให้แน่ใจว่า
ollama serveทำงานอยู่และพอร์ต 11434 เปิดอยู่ ใช้netstat -tuln | grep 11434เพื่อยืนยัน
ประสิทธิภาพช้า:
- ปัญหา: การอนุมานบน CPU ช้า
- วิธีแก้ไข: เปิดใช้งานการเร่งด้วย GPU ด้วยไดรเวอร์ที่เหมาะสม หรือใช้โมเดลที่เล็กลงเช่น gpt-oss-20b
สำหรับปัญหาที่ยังคงอยู่ โปรดปรึกษา Ollama GitHub หรือชุมชน Hugging Face สำหรับการสนับสนุน GPT-OSS
ขั้นตอนที่ 8: การเพิ่มประสิทธิภาพ GPT-OSS ด้วย Open WebUI
สำหรับอินเทอร์เฟซที่ใช้งานง่าย ให้จับคู่ Ollama กับ Open WebUI ซึ่งเป็นแดชบอร์ดบนเบราว์เซอร์สำหรับ GPT-OSS:
ติดตั้ง Open WebUI:
- ใช้ Docker:
docker run -d -p 3000:8080 --name open-webui ghcr.io/open-webui/open-webui:main
เข้าถึงอินเทอร์เฟซ:
- เปิด
http://localhost:3000ในเบราว์เซอร์ของคุณ - เลือก
gpt-oss-20bหรือgpt-oss-120bแล้วเริ่มแชท คุณสมบัติรวมถึงประวัติการแชท การจัดเก็บพรอมต์ และการสลับโมเดล
การอัปโหลดเอกสาร:
- อัปโหลดไฟล์สำหรับคำตอบที่คำนึงถึงบริบท (เช่น การตรวจสอบโค้ดหรือการวิเคราะห์ข้อมูล) โดยใช้ Retrieval-Augmented Generation (RAG)
Open WebUI ทำให้การโต้ตอบง่ายขึ้นสำหรับผู้ใช้ที่ไม่ใช่ด้านเทคนิค ซึ่งช่วยเสริมความสามารถในการดีบักทางเทคนิคของ Apidog
สรุป: ปลดปล่อย GPT-OSS ด้วย Ollama และ Apidog
การรัน GPT-OSS บนเครื่องด้วย Ollama ช่วยให้คุณสามารถควบคุมโมเดล open-weight ของ OpenAI ได้ฟรี พร้อมการควบคุมความเป็นส่วนตัวและการปรับแต่งอย่างเต็มที่ ด้วยการทำตามคู่มือนี้ คุณได้เรียนรู้วิธีติดตั้ง Ollama ดาวน์โหลดโมเดล GPT-OSS ปรับแต่งพฤติกรรม ผสานรวมผ่าน API และดีบักด้วย Apidog ไม่ว่าคุณจะกำลังสร้างแอปพลิเคชันที่ขับเคลื่อนด้วย AI หรือทดลองกับงานให้เหตุผล การตั้งค่านี้ให้ความยืดหยุ่นที่ไม่มีใครเทียบได้ การปรับเปลี่ยนเล็กน้อย เช่น การปรับพารามิเตอร์หรือการใช้การแสดงภาพของ Apidog สามารถเพิ่มประสิทธิภาพเวิร์กโฟลว์ของคุณได้อย่างมาก เริ่มสำรวจ AI ในเครื่องวันนี้และปลดล็อกศักยภาพของ GPT-OSS!