
นักพัฒนาซอฟต์แวร์ต่างมองหาวิธีที่มีประสิทธิภาพในการผสานรวมโมเดลภาษาขั้นสูงเข้ากับแอปพลิเคชันของตน INTELLECT-3 ถือเป็นตัวเลือกที่น่าสนใจเนื่องจากเป็นโอเพ่นซอร์สและมีประสิทธิภาพที่แข็งแกร่งในงานการให้เหตุผล โมเดลนี้พัฒนาโดย Prime Intellect โดดเด่นด้วยสถาปัตยกรรม Mixture-of-Experts (MoE) ที่มีพารามิเตอร์ 106 พันล้านตัว ซึ่งช่วยให้สามารถจัดการการคำนวณที่ซับซ้อนได้อย่างมีประสิทธิภาพสูง
ทำความเข้าใจ INTELLECT-3: ขุมพลังโอเพ่นซอร์ส
Prime Intellect เปิดตัว INTELLECT-3 เป็นโมเดลโอเพ่นซอร์สเต็มรูปแบบ ซึ่งช่วยให้นักวิจัยและนักพัฒนาสามารถปรับแต่งและขยายขีดความสามารถโดยไม่มีข้อจำกัดด้านกรรมสิทธิ์ ความโปร่งใสนี้ส่งเสริมนวัตกรรมในด้านต่างๆ เช่น การเรียนรู้แบบเสริมกำลัง (RL) และระบบ AI ที่ทำงานเป็นตัวแทน คุณสามารถเข้าถึงแพ็คเกจที่สมบูรณ์ ซึ่งรวมถึง น้ำหนักโมเดล เฟรมเวิร์กการฝึกอบรม ชุดข้อมูล สภาพแวดล้อม RL และเครื่องมือประเมินผลได้โดยตรงจาก พื้นที่เก็บข้อมูลของ Prime Intellect

ที่แกนกลาง INTELLECT-3 ใช้สถาปัตยกรรม MoE 106 พันล้านพารามิเตอร์ ซึ่งสร้างขึ้นบนโมเดลพื้นฐาน GLM-4.5-Air การออกแบบ MoE จะส่งอินพุตไปยัง "ผู้เชี่ยวชาญ" เครือข่ายย่อยที่เชี่ยวชาญ ซึ่งช่วยเพิ่มประสิทธิภาพการใช้งานคอมพิวเตอร์และเร่งการอนุมาน ตัวอย่างเช่น ในระหว่างการประมวลผล โมเดลจะเปิดใช้งานเฉพาะพารามิเตอร์บางส่วนที่เกี่ยวข้องกับคำค้นหา ลดความล่าช้าในขณะที่รักษาความแม่นยำ การตั้งค่านี้พิสูจน์แล้วว่ามีประสิทธิภาพเป็นพิเศษสำหรับงานที่ต้องการความเชี่ยวชาญเฉพาะทาง เช่น การอนุพันธ์ทางคณิตศาสตร์หรือการสร้างโค้ด
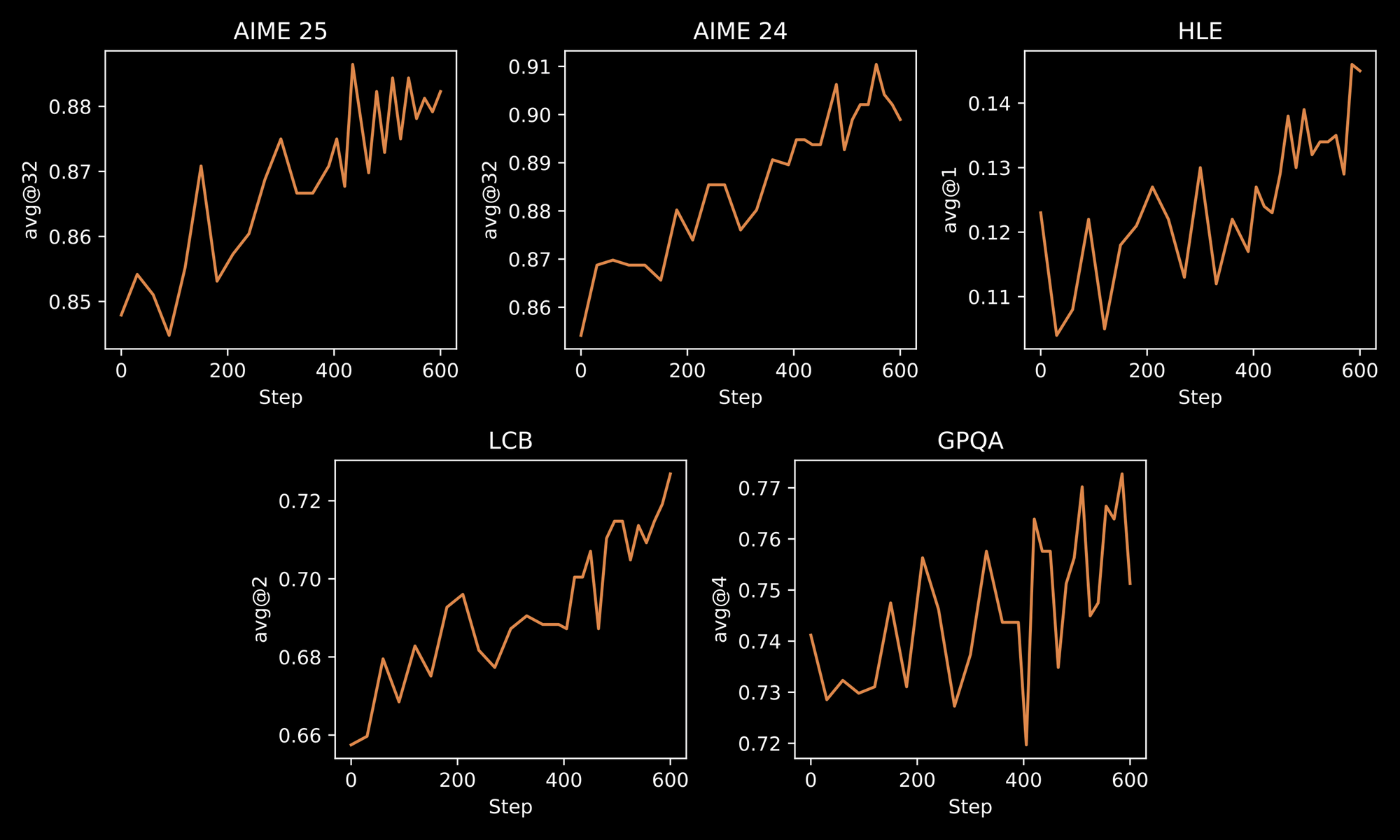
กระบวนการฝึกอบรมเน้นย้ำถึงความแข็งแกร่งของ INTELLECT-3 วิศวกรใช้วิธีการสองขั้นตอน: การปรับจูนแบบมีผู้ดูแลเบื้องต้น (SFT) บนชุดข้อมูลที่คัดสรรมาอย่างดี ตามด้วย RL ขนาดใหญ่โดยใช้เฟรมเวิร์ก prime-rl แบบกำหนดเอง prime-rl ทำงานเป็นระบบ RL แบบ asynchronous off-policy ซึ่งจัดการการจำลองแบบขนานจำนวนมากได้อย่างมีประสิทธิภาพ คุณจะได้รับประโยชน์จากสิ่งนี้ผ่านพฤติกรรมโมเดลที่ดีขึ้นในสภาพแวดล้อมแบบไดนามิก เช่น การแก้ปัญหาแบบวนซ้ำหรือการวางแผนแบบหลายขั้นตอน
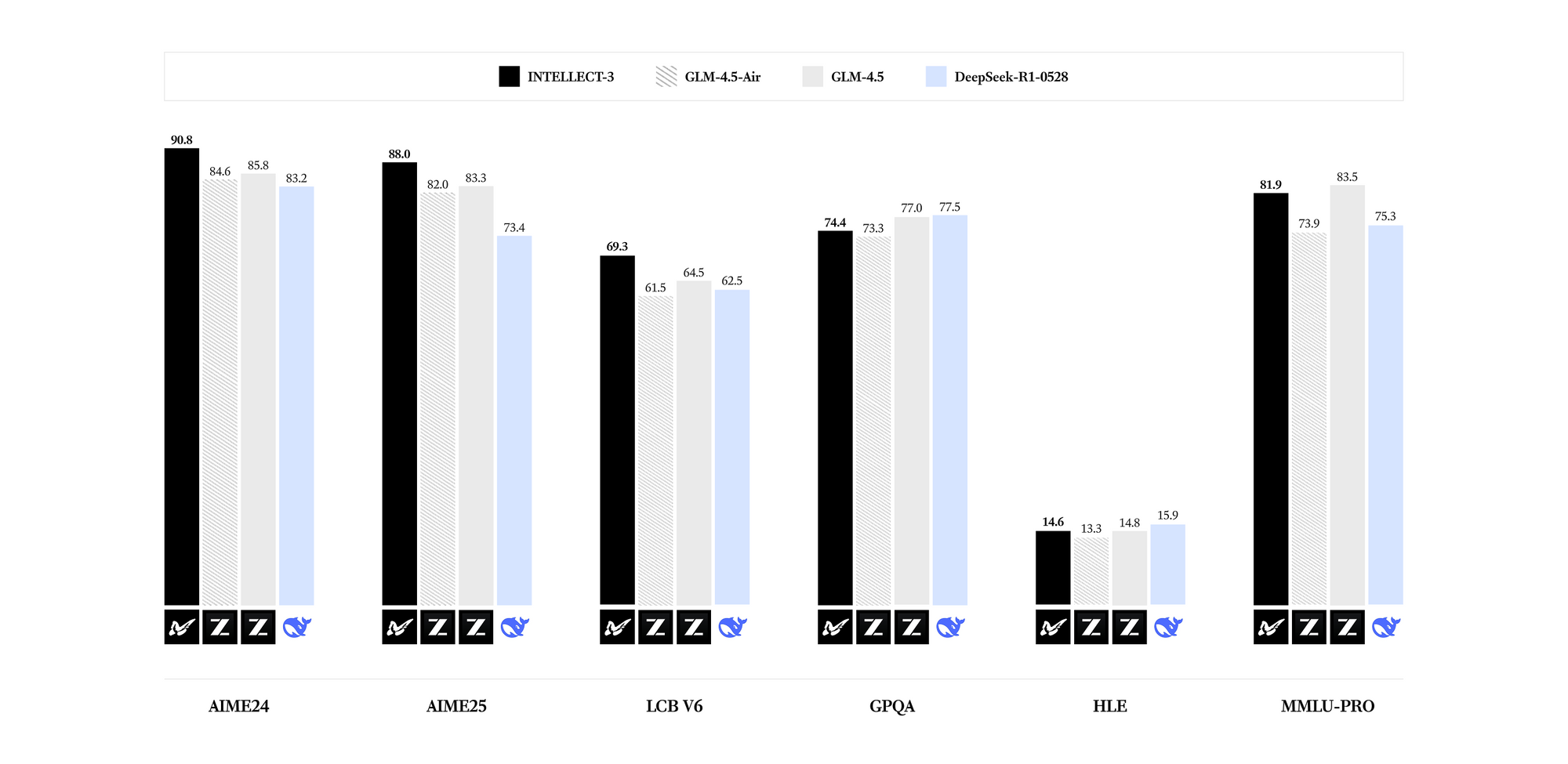
INTELLECT-3 มีความเป็นเลิศในโดเมนเฉพาะทาง ผลการเปรียบเทียบเผยให้เห็นผลลัพธ์ที่ล้ำสมัยสำหรับจำนวนพารามิเตอร์ในวิชาคณิตศาสตร์ (เช่น คะแนน GSM8K เกิน 95%) การเขียนโค้ด (อัตราการผ่าน HumanEval สูงกว่า 85%) วิทยาศาสตร์ (ความแม่นยำ GPQA สูงกว่า 60%) และการให้เหตุผล (คะแนน MMLU ใกล้ 80%) เมื่อเทียบกับโมเดลที่หนาแน่นกว่าเช่น Llama 3.1 70B, INTELLECT-3 บรรลุประสิทธิภาพที่เหนือกว่า—อนุมานได้เร็วกว่าถึง 2 เท่าบนฮาร์ดแวร์ที่เทียบเท่ากัน—เนื่องจากรูปแบบการเปิดใช้งานแบบกระจัดกระจาย ด้วยเหตุนี้ คุณจึงสามารถนำไปใช้ในสภาพแวดล้อมที่ทรัพยากรจำกัดได้โดยไม่ทำให้คุณภาพของผลลัพธ์ลดลง
โครงสร้างพื้นฐานที่รองรับช่วยเพิ่มความน่าสนใจของโอเพ่นซอร์ส Verifiers & Environments Hub มีสภาพแวดล้อม RL มากกว่า 500 แห่ง ตั้งแต่ปริศนาอย่างง่ายไปจนถึงเครื่องพิสูจน์ทฤษฎีขั้นสูง
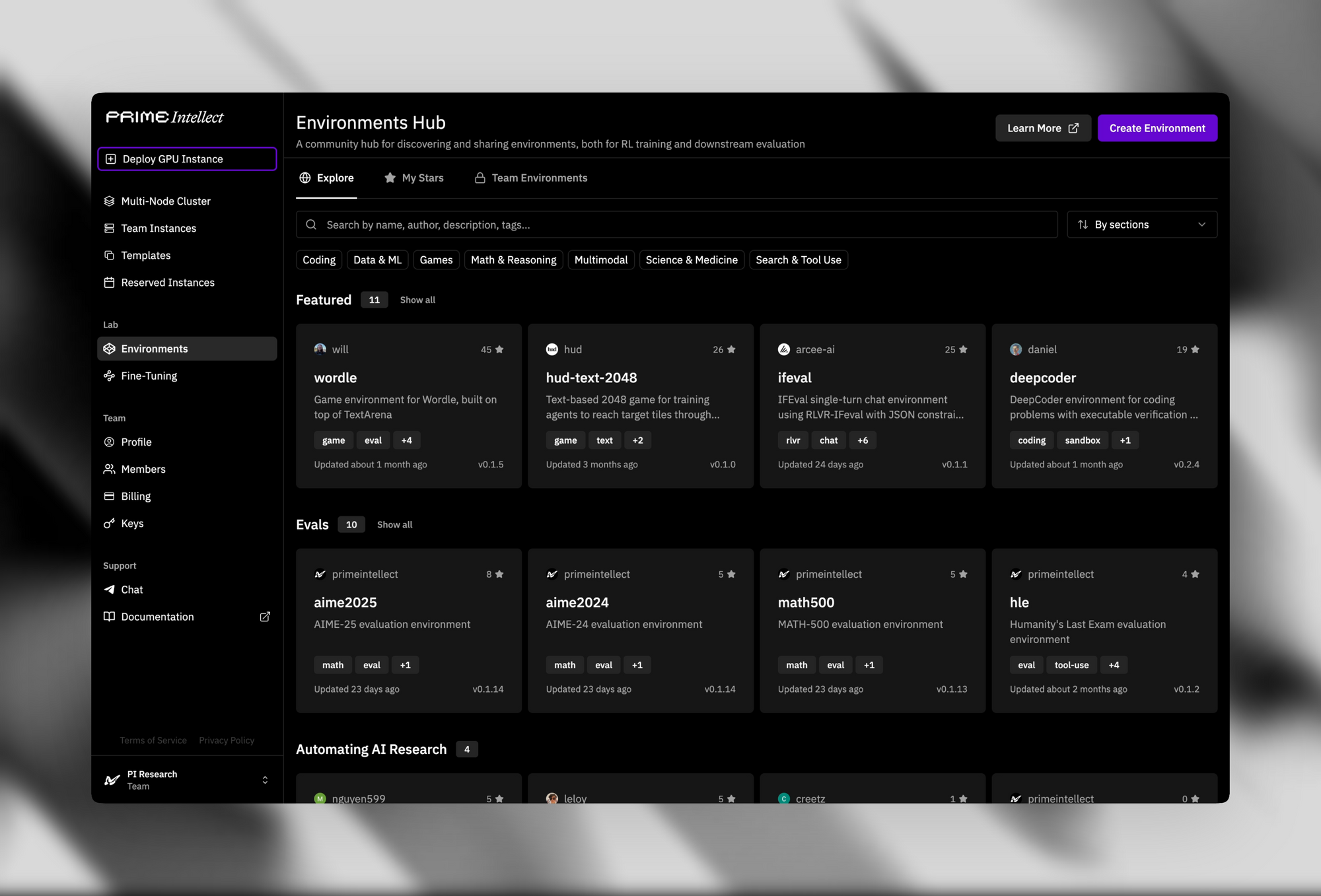
Prime Sandboxes ให้การดำเนินการโค้ดที่ปลอดภัยและมีปริมาณงานสูง ซึ่งแยกการกระทำของตัวแทนในระหว่างการฝึกอบรมหรือการอนุมาน นักพัฒนาใช้เครื่องมือเหล่านี้เพื่อปรับแต่ง INTELLECT-3 สำหรับแอปพลิเคชันที่กำหนดเอง เช่น ตัวแทนอิสระในไปป์ไลน์การพัฒนาซอฟต์แวร์
ในทางปฏิบัติ คุณสามารถดาวน์โหลดน้ำหนักโมเดลผ่าน Hugging Face หรือ GitHub ของ Prime Intellect การติดตั้งต้องใช้การพึ่งพามาตรฐานเช่น PyTorch และไลบรารี Transformers สคริปต์พื้นฐานสำหรับโหลดโมเดลมีลักษณะดังนี้:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
โค้ดนี้จะเริ่มต้นโมเดลบนฮาร์ดแวร์ที่รองรับ GPU อย่างไรก็ตาม สำหรับการใช้งานในระดับการผลิต คุณจะต้องเปลี่ยนไปใช้ API ที่โฮสต์ เนื่องจากการโฮสต์ด้วยตนเองต้องใช้การคำนวณที่สำคัญ (เช่น GPU A100 หลายตัว) ดังนั้น การเข้าถึงโอเพ่นซอร์สจึงวางรากฐาน แต่การผสานรวม API จะปรับขนาดการปรับใช้ของคุณได้อย่างมีประสิทธิภาพ
เมื่อเปลี่ยนจากการทดลองในเครื่อง คุณจะสำรวจวิธีเข้าถึง INTELLECT-3 ผ่านบริการที่มีการจัดการ การเปลี่ยนแปลงนี้ช่วยให้มั่นใจถึงความน่าเชื่อถือและจัดการความซับซ้อนของการอนุมานแบบกระจาย
การเข้าถึง INTELLECT-3 API: การตั้งค่าและการตรวจสอบสิทธิ์
ตัวเลือกที่ 1 – Prime Intellect Native Endpoint (แนะนำเพื่อประสิทธิภาพสูงสุดและเวลาแฝงต่ำสุด)
คุณเริ่มการเข้าถึง API โดยรับข้อมูลประจำตัวจากแพลตฟอร์มของ Prime Intellect เยี่ยมชมแดชบอร์ดของ Prime Intellect ที่ app.primeintellect.ai และสร้างบัญชีหากจำเป็น
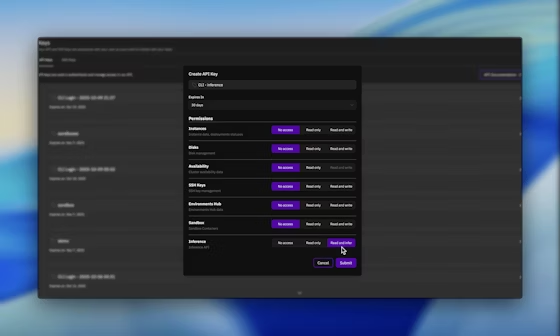
เมื่อเข้าสู่ระบบแล้ว ให้ไปที่ส่วนคีย์ API และสร้างคีย์ใหม่โดยเปิดใช้งานสิทธิ์ Inference คีย์นี้จะตรวจสอบสิทธิ์คำขอที่ตามมาทั้งหมด ทำให้มั่นใจได้ถึงการเข้าถึง INTELLECT-3 ที่ปลอดภัย
ถัดไป กำหนดค่าสภาพแวดล้อมของคุณ ตั้งค่าคีย์ API เป็นตัวแปรสภาพแวดล้อมเพื่อการผสานรวมที่ราบรื่น:
export PRIME_API_KEY="your-api-key-here"
สำหรับเวิร์กโฟลว์ที่อิงตามทีม ให้รวมส่วนหัว X-Prime-Team-ID ในคำขอ ตัวระบุนี้จะส่งเส้นทางการใช้งานไปยังกลุ่มการเรียกเก็บเงินที่ถูกต้อง ป้องกันการเรียกเก็บเงินข้ามบัญชี คุณสามารถเรียกดู ID ทีมได้จากแดชบอร์ดภายใต้การตั้งค่าบัญชี
API ใช้ประโยชน์จากอินเทอร์เฟซที่เข้ากันได้กับ OpenAI ซึ่งช่วยลดความยุ่งยากในการนำไปใช้หากคุณใช้ไลบรารีเช่น openai-python อยู่แล้ว ระบุ URL พื้นฐานเป็น https://api.pinference.ai/api/v1 ปลายทางนี้จะพร็อกซีคำขอไปยังผู้ให้บริการอนุมานที่ปรับให้เหมาะสม รวมถึง Parasail และ Nebius ซึ่งโฮสต์อินสแตนซ์ INTELLECT-3 ส่งผลให้คุณได้รับคำตอบที่มีความล่าช้าต่ำโดยไม่ต้องจัดการคลัสเตอร์ที่อยู่เบื้องหลัง
หากต้องการตรวจสอบการเข้าถึง ให้สอบถามปลายทางของโมเดล ซึ่งจะแสดงโมเดลที่มีอยู่ ยืนยันการมีอยู่ของ INTELLECT-3 (โดยปกติจะอยู่ภายใต้ชื่อเช่น prime-intellect/intellect-3) ใช้เครื่องมือ CLI สำหรับการตรวจสอบอย่างรวดเร็ว:
prime inference models
หรือส่งคำขอ GET ผ่าน curl:
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
การตอบกลับจะส่งกลับอาร์เรย์ JSON ของออบเจกต์โมเดล โดยแต่ละออบเจกต์จะให้รายละเอียดพารามิเตอร์เช่น id, max_tokens และ context_window INTELLECT-3 รองรับบริบทโทเค็น 128K ซึ่งรองรับสายโซ่การให้เหตุผลที่ยาว
การตรวจสอบสิทธิ์ครอบคลุมถึงการจำกัดอัตราและโควต้า Prime Intellect บังคับใช้การจำกัดต่อนาทีและรายวันตามแผนของคุณ ซึ่งมองเห็นได้ในแดชบอร์ด คุณตรวจสอบการใช้งานผ่าน แท็บ Billing ซึ่งบันทึกโทเค็นที่ประมวลผลและการเรียก API หากขีดจำกัดผูกมัดเวิร์กโฟลว์ของคุณ ให้อัปเกรดได้อย่างราบรื่นผ่านแพลตฟอร์ม
นอกจากนี้ ให้ผสานรวมกับ Apidog เพื่อการทดสอบที่ดียิ่งขึ้น นำเข้าสคีมา OpenAI ลงใน Apidog จากนั้นจำลองคำขอไปยังปลายทาง INTELLECT-3 การปฏิบัตินี้จะระบุปัญหาได้ตั้งแต่เนิ่นๆ เช่น เพย์โหลด JSON ที่ผิดรูปแบบ Apidog เวอร์ชันฟรีเพียงพอสำหรับการตั้งค่าเริ่มต้น เชื่อมโยงการพัฒนาในเครื่องเข้ากับ API การผลิต
เมื่อมีการตรวจสอบสิทธิ์แล้ว คุณจะดำเนินการสร้างคำขอ ส่วนถัดไปจะสรุปรูปแบบที่แม่นยำเพื่อดึงการตอบกลับที่ดีที่สุดจาก INTELLECT-3
ตัวเลือกที่ 2 – OpenRouter (เข้าถึงได้ทันทีและเครดิตรวม)
นอกจากโฮสติ้งด้วยตนเองหรือใช้แพลตฟอร์มการอนุมานแบบเนทีฟของ Prime Intellect แล้ว INTELLECT-3 ยังมีให้บริการอย่างเป็นทางการบน OpenRouter ซึ่งให้ทางเลือกอื่นแก่คุณด้วยการเรียกเก็บเงินแบบรวม การกำหนดเส้นทางสำรองอัตโนมัติ และการเข้าถึงได้ทันที—ไม่จำเป็นต้องมีบัญชี Prime Intellect แยกต่างหากหากคุณใช้ OpenRouter อยู่แล้ว
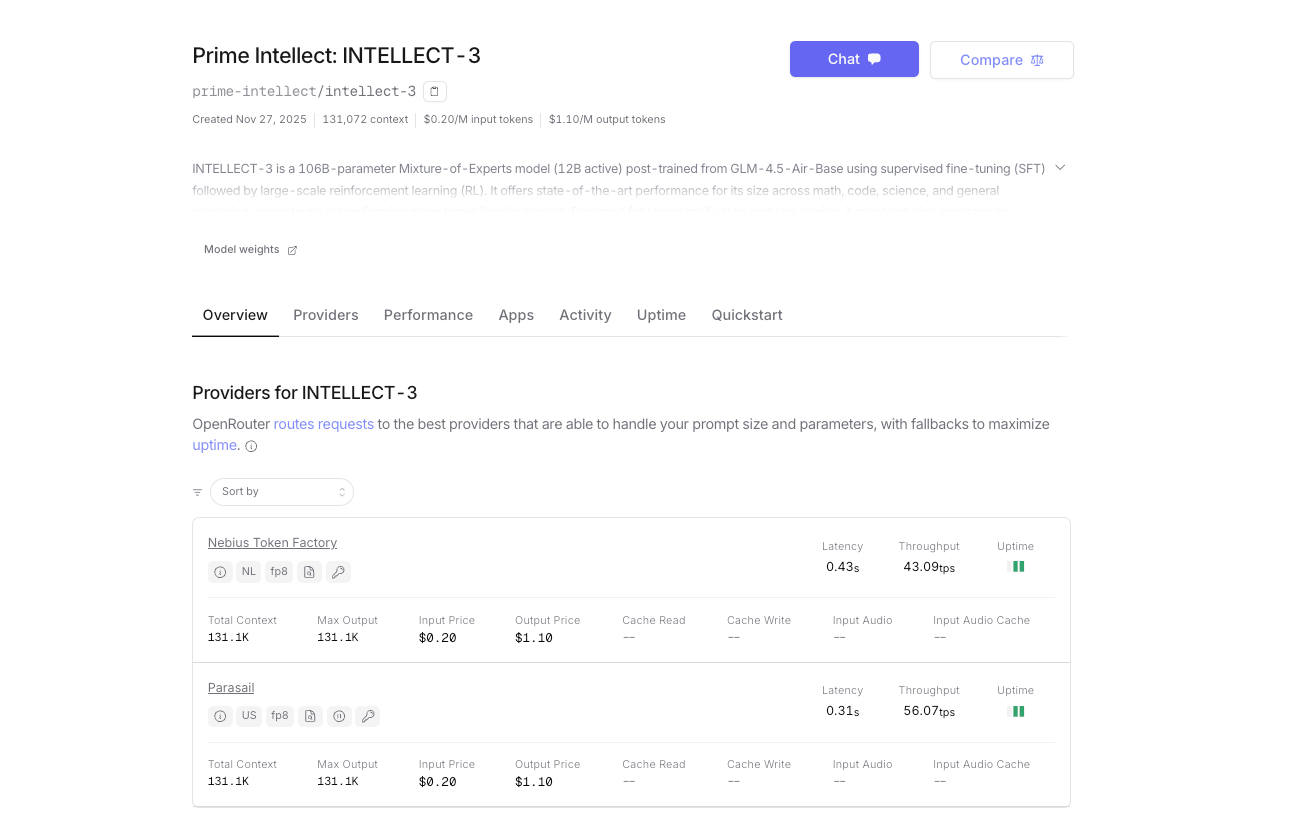
- URL พื้นฐาน: https://openrouter.ai/api/v1
- ชื่อโมเดล: prime-intellect/intellect-3
- การตรวจสอบสิทธิ์: คีย์ API ของ OpenRouter ของคุณ (OPENROUTER_API_KEY)
- การกำหนดเส้นทางผู้ให้บริการอัตโนมัติ (ปัจจุบันให้บริการโดยคลัสเตอร์ Prime Intellect)
- จ่ายตามการใช้งานด้วยเครดิต OpenRouter; ค่าใช้จ่ายต่อโทเค็นสูงขึ้นเล็กน้อยเนื่องจากค่าธรรมเนียมแพลตฟอร์ม
ปลายทางทั้งสองรองรับสคีมาคำขอ/การตอบกลับที่เหมือนกัน การสตรีม การเรียกเครื่องมือ และโหมด JSON
การส่งคำขอไปยัง INTELLECT-3 API: รูปแบบและตัวอย่าง
คุณเริ่มการโต้ตอบผ่านปลายทาง /chat/completions ซึ่งจัดการพรอมต์เชิงสนทนาและเชิงงาน สร้างคำขอเป็นออบเจกต์ JSON ที่มีฟิลด์สำหรับ model, messages, temperature และ max_tokens อาร์เรย์ messages เลียนแบบประวัติการแชท โดยใช้บทบาทเช่น "system", "user" และ "assistant"
พิจารณาตัวอย่างพื้นฐานสำหรับการสร้างโค้ด คุณส่ง:
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
โค้ดนี้จะส่งออกการใช้งาน Fibonacci แบบเรียกซ้ำพร้อมการบันทึกค่า ซึ่งใช้ประโยชน์จากความสามารถในการเขียนโค้ดของ INTELLECT-3 พารามิเตอร์ temperature ควบคุมความคิดสร้างสรรค์—ค่าที่ต่ำกว่า (เช่น 0.2) จะให้ผลลัพธ์ที่เป็นไปตามข้อกำหนดสำหรับคำถามเชิงข้อเท็จจริง ในขณะที่ค่าที่สูงกว่า (สูงสุด 1.0) จะส่งเสริมเส้นทางความคิดที่หลากหลาย
สำหรับการให้เหตุผลทางคณิตศาสตร์ คุณกำหนดโครงสร้างพรอมต์เพื่อเชื่อมโยงความคิด การฝึกอบรม RL ของ INTELLECT-3 โดดเด่นในที่นี้ เนื่องจากมันจำลองการตรวจสอบทีละขั้นตอน ตัวอย่าง:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
โมเดลจะตอบกลับด้วยการพิสูจน์ที่เข้มงวด โดยอ้างอิงถึงสัจพจน์และทฤษฎีบท คุณสามารถแยกวิเคราะห์ผลลัพธ์ผ่าน response.choices[0].message.content ซึ่งจะมาถึงเป็นสตริง สำหรับข้อมูลที่มีโครงสร้าง ให้เปิดใช้งานโหมด JSON โดยเพิ่ม "response_format": {"type": "json_object"} ไปยังคำขอ เพื่อให้แน่ใจว่าการตอบกลับสามารถแยกวิเคราะห์ได้
การใช้งานขั้นสูงเกี่ยวข้องกับการเรียกเครื่องมือ ซึ่ง INTELLECT-3 จะผสานรวมฟังก์ชันภายนอก กำหนดเครื่องมือในคำขอ:
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
หากโมเดลเรียกใช้เครื่องมือ มันจะส่งคืนอาร์กิวเมนต์ใน response.choices[0].message.tool_calls คุณเรียกใช้ฟังก์ชันจากภายนอกและป้อนผลลัพธ์กลับในข้อความติดตาม รูปแบบนี้สร้างเวิร์กโฟลว์ตัวแทน โดยใช้ประโยชน์จากพฤติกรรมที่ได้รับการฝึกอบรมในสภาพแวดล้อมของ INTELLECT-3
การจัดการข้อผิดพลาดเป็นส่วนสำคัญ ปัญหาที่พบบ่อยได้แก่ 401 (คีย์ไม่ถูกต้อง), 429 (จำกัดอัตรา) และ 400 (คำขอผิดรูปแบบ) ใช้การลองซ้ำพร้อมการถอยหลังแบบเอ็กซ์โพเนนเชียล:
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
การตอบกลับรวมถึงข้อมูลเมตาเช่น usage (prompt_tokens, completion_tokens, total_tokens) ซึ่งคุณบันทึกไว้เพื่อเพิ่มประสิทธิภาพ INTELLECT-3 ประมวลผลโทเค็นได้สูงสุด 4096 โทเค็นต่อการดำเนินการเดียว โดยรักษาสมดุลระหว่างความลึกและความเร็ว
การสตรีมการตอบกลับช่วยเพิ่มแอปพลิเคชันแบบเรียลไทม์ เพิ่ม stream=True ในการเรียกสร้าง ไคลเอ็นต์จะส่งคืนส่วนย่อยเป็น Server-Sent Events แยกวิเคราะห์แบบวนซ้ำ:
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
เทคนิคนี้เหมาะสำหรับแชทบอทหรือผู้ช่วยเขียนโค้ดแบบสด ซึ่งผู้ใช้คาดหวังผลตอบรับที่เพิ่มขึ้น
เมื่อคุณเชี่ยวชาญการสร้างคำขอแล้ว คุณจะประเมินประสิทธิภาพ ส่วนถัดไปจะแนะนำเครื่องมือการเปรียบเทียบที่ปรับแต่งมาสำหรับ INTELLECT-3
การเพิ่มประสิทธิภาพและการประเมินการใช้งาน INTELLECT-3 API
คุณเพิ่มประสิทธิภาพการเรียก API โดยการปรับพารามิเตอร์เชิงประจักษ์ เริ่มต้นด้วยการรวมหลายข้อความเข้าเป็นคำขอเดียวเพื่อเพิ่มปริมาณงาน—ประสิทธิภาพเพิ่มขึ้นสูงสุด 10 เท่าในชุดการประเมิน CLI ของ Prime Intellect รองรับสิ่งนี้:
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
คำสั่งนี้เรียกใช้ตัวอย่าง GSM8K 100 ตัวอย่าง โดยรวบรวมเมตริกความแม่นยำและเวลาแฝง คุณวิเคราะห์ผลลัพธ์เพื่อปรับ top_p หรือ frequency_penalty ซึ่งช่วยลดการทำซ้ำในการสร้างที่ยาวนาน
การประเมินขยายไปยังสภาพแวดล้อมที่กำหนดเองจาก Verifiers Hub โหลดสภาพแวดล้อม RL และสอบถาม INTELLECT-3 เป็นนโยบาย:
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
รางวัลจะวัดการปรับปรุง โดยแนะนำการปรับแต่งหากคุณโฮสต์ในเครื่อง สำหรับผู้ใช้ API เท่านั้น ให้บันทึกการโต้ตอบไปยังฐานข้อมูลเวกเตอร์และคำนวณเมตริกปลายน้ำเช่นอัตราความสำเร็จของงาน
ข้อพิจารณาด้านความปลอดภัยก็มีความสำคัญเช่นกัน ล้างข้อมูลอินพุตของผู้ใช้เพื่อป้องกันการฉีดพรอมต์ และใช้พรอมต์ของระบบเพื่อบังคับใช้ขอบเขต พื้นหลัง RL ของ INTELLECT-3 ช่วยลดภาพหลอน แต่คุณต้องตรวจสอบผลลัพธ์เทียบกับตัวตรวจสอบสำหรับแอปพลิเคชันที่มีความเสี่ยงสูง
การปรับขนาดเกี่ยวข้องกับการตรวจสอบผ่านแดชบอร์ด ตั้งค่าการแจ้งเตือนสำหรับเกณฑ์โทเค็น และผสานรวมกับเครื่องมือสังเกตการณ์เช่น Prometheus ซึ่ง Prime Intellect เปิดเผยสำหรับคลัสเตอร์ ดังนั้น คุณจึงรักษาความน่าเชื่อถือเมื่อการใช้งานเติบโตขึ้น
เมื่อคุณจัดการการเพิ่มประสิทธิภาพแล้ว ให้พิจารณาเรื่องค่าใช้จ่าย ความโปร่งใสของราคาช่วยให้การผสานรวมเป็นไปอย่างยั่งยืน
ราคา INTELLECT-3 API: โมเดลราคาแบบโทเค็นที่โปร่งใส
Prime Intellect จัดโครงสร้างราคาตามการใช้โทเค็น โดยคิดค่าใช้จ่ายแยกต่างหากสำหรับอินพุตและเอาต์พุต คุณจ่ายต่อ 1,000 โทเค็น โดยมีอัตราที่แตกต่างกันไปตามโมเดลและผู้ให้บริการ สำหรับ INTELLECT-3 คาดว่าจะมีตัวเลขที่แข่งขันได้—ประมาณ $0.50 ต่อล้านโทเค็นอินพุตและ $1.50 ต่อล้านโทเค็นเอาต์พุต—แม้ว่าค่าที่แน่นอนจะปรากฏในการตอบกลับของปลายทางของโมเดล
| ผู้ให้บริการ | อินพุต ($$ /1M tokens) | เอาต์พุต ( $$/1M tokens) | หมายเหตุ |
|---|---|---|---|
| Prime Intellect Direct | ~$0.45–$0.60 | ~$1.30–$1.80 | ค่าใช้จ่ายต่ำสุด, ส่วนลดตามปริมาณ |
| OpenRouter | ~$0.60–$0.80 | ~$1.80–$2.40 | รวมค่าธรรมเนียมแพลตฟอร์ม OpenRouter |
อัตราที่แน่นอนจะผันผวน; ตรวจสอบค่าล่าสุดในแดชบอร์ดของคุณหรือผ่านปลายทางของโมเดลเสมอ
คุณควรเลือกอะไร?
- เลือก Prime Intellect โดยตรงหากคุณต้องการความเร็วสูงสุด ค่าใช้จ่ายต่ำสุด หรือวางแผนการใช้งานปริมาณมาก
- เลือก OpenRouter หากคุณต้องการคีย์ API เดียวสำหรับโมเดลกว่า 50 รายการ ต้องการการเริ่มต้นใช้งานทันที หรือต้องการการกำหนดเส้นทางสำรองในตัว
ทั้งสองตัวเลือกให้ประสิทธิภาพ INTELLECT-3 ที่เหมือนกัน เลือกตัวเลือกที่เหมาะกับเวิร์กโฟลว์ของคุณ—หลายทีมถึงกับใช้ทั้งสองตัวเลือกพร้อมกันเพื่อความซ้ำซ้อน
ส่วนที่เหลือของคู่มือนี้ (รูปแบบคำขอ การสตรีม การเรียกเครื่องมือ การเพิ่มประสิทธิภาพ ฯลฯ) สามารถนำไปใช้ได้เช่นเดียวกันไม่ว่าคุณจะเรียก Prime Intellect โดยตรงหรือผ่าน OpenRouter
ดำเนินการต่อด้วยรายละเอียดการใช้งานทางเทคนิคแบบเต็มด้านล่าง และเริ่มสร้างด้วย INTELLECT-3 ได้ตั้งแต่วันนี้—ผ่านเกตเวย์ใดก็ตามที่เหมาะกับคุณที่สุด
การผสานรวมขั้นสูงกับ INTELLECT-3 API
คุณขยาย INTELLECT-3 ไปสู่ระบบนิเวศเช่น LangChain หรือ LlamaIndex สำหรับการจัดระเบียบ ใน LangChain:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
สิ่งนี้จะเชื่อมโยง API กับไปป์ไลน์การสร้างแบบเสริมการดึงข้อมูล (RAG) ซึ่งช่วยเพิ่มความแม่นยำด้วยความรู้ภายนอก
สำหรับไมโครเซอร์วิส ให้ปรับใช้ผ่าน wrapper ของ FastAPI ที่พร็อกซีไปยัง INTELLECT-3:
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
เปิดเผยปลายทางนี้อย่างปลอดภัย โดยจำกัดอัตราด้วย Redis การตั้งค่าดังกล่าวเป็นขุมพลังของเครื่องมือ SaaS ตั้งแต่เครื่องมือสร้างเนื้อหาไปจนถึงผู้ช่วยวิจัย
กรณีขอบต้องการความสนใจ จัดการการไหลเกินของโทเค็นโดยการตัดอินพุตแบบไดนามิก และกลับไปใช้โมเดลที่เล็กลงหาก INTELLECT-3 อยู่ในคิว ฟอรัมชุมชนบนเว็บไซต์ของ Prime Intellect มีกระทู้แก้ไขปัญหา
สรุป: ปรับใช้ INTELLECT-3 API ด้วยความมั่นใจ
ตอนนี้คุณมีชุดเครื่องมือที่ครอบคลุมสำหรับการใช้งาน INTELLECT-3 API ตั้งแต่รากฐานโอเพ่นซอร์สไปจนถึงการจัดการคำขอที่แม่นยำและการจัดการต้นทุน คู่มือนี้จะช่วยให้คุณพร้อมสำหรับการปรับใช้ในโลกแห่งความเป็นจริง ทดลองกับ Apidog เพื่อปรับปรุงเวิร์กโฟลว์ของคุณ และติดตามเอกสารที่พัฒนาขึ้นเพื่อการอัปเดต
ใช้เทคนิคเหล่านี้ทีละน้อย—เริ่มต้นด้วยการแชทง่ายๆ จากนั้นปรับขนาดเป็นตัวแทน ประสิทธิภาพและการเปิดกว้างของ INTELLECT-3 ทำให้เป็นทางเลือกที่ดีที่สุดสำหรับโครงการ AI ทางเทคนิค เริ่มเขียนโค้ดวันนี้ และเป็นพยานถึงผลกระทบต่อแอปพลิเคชันของคุณ