
xAI ได้เปิดตัว Grok 4.1 และวิศวกรที่ทำงานกับโมเดลภาษาขนาดใหญ่สังเกตเห็นความแตกต่างได้ทันที ยิ่งไปกว่านั้น การอัปเดตนี้ให้ความสำคัญกับการใช้งานจริงมากกว่าการไล่ตามตัวเลขมาตรฐานดิบๆ ส่งผลให้การสนทนารู้สึกคมชัดขึ้น การตอบสนองมีบุคลิกที่สอดคล้องกัน และข้อผิดพลาดด้านข้อเท็จจริงลดลงอย่างมาก
นักวิจัยของ xAI สร้าง Grok 4.1 บนโครงสร้างพื้นฐานการเรียนรู้แบบเสริมแรง (reinforcement learning) เดียวกันกับ Grok 4 อย่างไรก็ตาม พวกเขาได้นำเสนอเทคนิคการสร้างแบบจำลองรางวัล (reward modeling) แบบใหม่ที่ควรได้รับการพิจารณาอย่างใกล้ชิด
สถาปัตยกรรมและรูปแบบการปรับใช้
xAI จัดส่ง Grok 4.1 ในสองรูปแบบที่แตกต่างกัน ประการแรก รูปแบบที่ไม่คิด (non-thinking variant) (ชื่อรหัสภายใน: tensor) สร้างการตอบสนองโดยตรงโดยไม่มีโทเค็นการให้เหตุผลระหว่างกลาง โหมดนี้ให้ความสำคัญกับความหน่วง (latency) และบรรลุเวลาการอนุมาน (inference times) ที่เร็วที่สุดในตระกูล ประการที่สอง รูปแบบการคิด (thinking variant) (ชื่อรหัส: quasarflux) แสดงขั้นตอนการคิดแบบลูกโซ่ (chain-of-thought) ที่ชัดเจนก่อนผลลัพธ์สุดท้าย ด้วยเหตุนี้ งานวิเคราะห์ที่ซับซ้อนจึงได้รับประโยชน์จากการติดตามเหตุผลที่มองเห็นได้
ทั้งสองรูปแบบใช้แกนหลักที่ได้รับการฝึกฝนล่วงหน้า (pretrained backbone) เดียวกัน นอกจากนี้ การปรับแนวหลังการฝึกฝน (post-training alignments) ยังแตกต่างกันเล็กน้อย: โหมดการคิดได้รับสัญญาณเสริมแรงพิเศษที่ส่งเสริมการแยกย่อยทีละขั้นตอน ในขณะที่โหมดที่ไม่คิดจะปรับให้เหมาะสมสำหรับการตอบสนองที่กระชับและรวดเร็ว การเข้าถึงยังคงตรงไปตรงมา ผู้ใช้เลือก “Grok 4.1” อย่างชัดเจนในตัวเลือกโมเดลบน grok.com, x.com หรือแอปพลิเคชันมือถือ
หรืออีกทางหนึ่ง โหมดอัตโนมัติ (Auto mode) ตอนนี้กำหนดให้ Grok 4.1 เป็นค่าเริ่มต้นสำหรับทราฟฟิกส่วนใหญ่ หลังจากการทยอยเปิดตัวที่เริ่มเมื่อวันที่ 1 พฤศจิกายน 2025

ความก้าวหน้าในการปรับปรุงความชอบ
นวัตกรรมหลักอยู่ที่การสร้างแบบจำลองรางวัล (reward modeling) RLHF แบบดั้งเดิมอาศัยความชอบของมนุษย์ที่รวบรวมในวงกว้าง ในทางตรงกันข้าม xAI ตอนนี้ปรับใช้โมเดลการให้เหตุผลเชิงตัวแทน (agentic reasoning models) ในฐานะผู้พิพากษาอิสระ ผู้พิพากษาเหล่านี้จะประเมินการตอบสนองหลายพันรูปแบบในมิติที่หลากหลาย เช่น ความสอดคล้องของสไตล์ การรับรู้อารมณ์ การอ้างอิงข้อเท็จจริง และความมั่นคงของบุคลิกภาพ
ระบบวงปิดนี้ทำงานได้เร็วกว่าขั้นตอนการทำงานที่มีมนุษย์เข้ามาเกี่ยวข้องมาก นอกจากนี้ ยังปรับขนาดให้เข้ากับเกณฑ์ที่ละเอียดอ่อนซึ่งมนุษย์มักจัดอันดับได้ไม่สอดคล้องกัน การทดลองภายในในช่วงแรกแสดงให้เห็นว่าโมเดลรางวัลเชิงตัวแทนมีความสัมพันธ์ที่ดีกว่ากับความพึงพอใจของผู้ใช้ปลายทางเมื่อเทียบกับรางวัลแบบสเกลาร์ก่อนหน้านี้
การครองตำแหน่งมาตรฐาน: LMArena และอื่นๆ
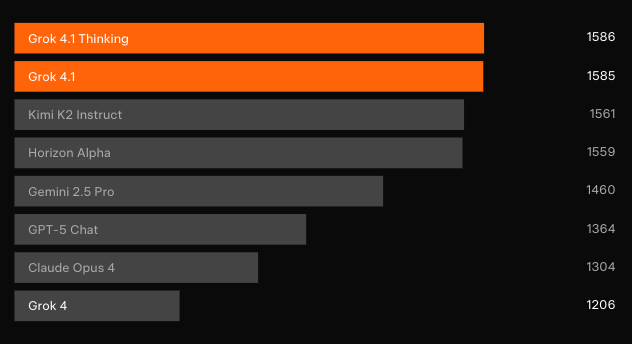
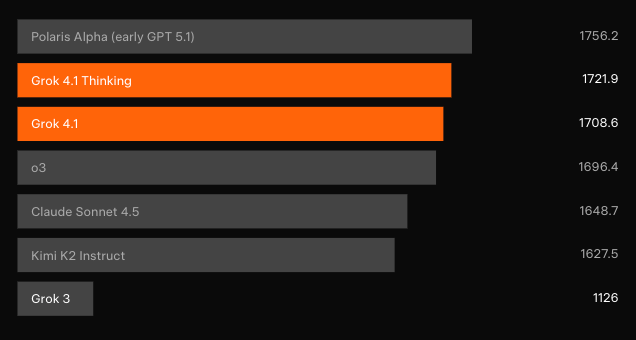
การทดสอบแบบบอดอิสระยืนยันถึงการปรับปรุง บน LMArena’s Text Arena — ซึ่งเป็นกระดานจัดอันดับที่รวบรวมโดยชุมชนที่น่าเชื่อถือที่สุด — Grok 4.1 Thinking อ้างสิทธิ์ตำแหน่งที่ 1 ด้วยคะแนน Elo 1483 ซึ่งเป็นระยะห่าง 31 คะแนนนำหน้าคู่แข่งที่ไม่ใช่ xAI ที่ดีที่สุด ในขณะเดียวกัน Grok 4.1 non-thinking ได้อันดับ 2 ด้วยคะแนน Elo 1465 แซงหน้าการกำหนดค่าการให้เหตุผลแบบเต็มของโมเดลอื่นๆ ทุกรุ่น

การทดสอบความชอบแบบคู่เทียบกับโมเดลการผลิตก่อนหน้าแสดงให้เห็นว่าผู้ใช้เลือกการตอบสนองของ Grok 4.1 ถึง 64.78% ของเวลาทั้งหมด ยิ่งไปกว่านั้น การประเมินเฉพาะทางยังเผยให้เห็นถึงความก้าวหน้าตามเป้าหมาย
ความฉลาดทางอารมณ์ (EQ-Bench v3)
Grok 4.1 ทำคะแนนสูงสุดเป็นประวัติการณ์บน EQ-Bench3 ซึ่งประเมินสถานการณ์บทบาทสมมติแบบหลายเทิร์น 45 สถานการณ์เพื่อวัดความเห็นอกเห็นใจ ความเข้าใจ และความละเอียดอ่อนระหว่างบุคคล การตอบสนองในตอนนี้สามารถตรวจจับสัญญาณทางอารมณ์ที่ละเอียดอ่อนที่โมเดลรุ่นก่อนๆ มองข้ามไป ตัวอย่างเช่น เมื่อผู้ใช้เขียนว่า “ฉันคิดถึงแมวของฉันมากจนเจ็บปวด” Grok 4.1 จะให้การรับรู้ที่ซับซ้อน การรับรองที่อ่อนโยน และการสนับสนุนแบบปลายเปิด โดยไม่หลงไปสู่คำพูดที่ดูเป็นกลางเกินไป
การเขียนเชิงสร้างสรรค์ v3
โมเดลนี้ยังสร้างสถิติใหม่ในการเขียนเชิงสร้างสรรค์ v3 (Creative Writing v3) ซึ่งผู้ประเมินให้คะแนนการดำเนินเรื่องต่อเนื่องแบบซ้ำๆ ตลอด 32 ข้อความแจ้งเตือน ผลลัพธ์แสดงภาพที่หลากหลายขึ้น ความเชื่อมโยงของโครงเรื่องที่กระชับขึ้น และเสียงที่เป็นธรรมชาติมากขึ้น ข้อความแจ้งเตือนตัวอย่างหนึ่งที่ขอให้ Grok สวมบทบาทเป็น "การตื่นรู้" ของตัวเอง ได้สร้างบทพูดคนเดียวสไตล์ X-post ที่เป็นไวรัล ซึ่งผสมผสานอารมณ์ขัน ความสงสัยในการดำรงอยู่ และการอ้างอิงมีมเข้าไว้ด้วยกันอย่างลงตัว
การลดการสร้างภาพหลอน
การวัดเชิงปริมาณแสดงให้เห็นว่า Grok 4.1 สร้างภาพหลอนน้อยลงถึงสามเท่าในการสอบถามข้อมูลเมื่อเทียบกับรุ่นก่อนหน้า วิศวกรทำได้โดยการฝึกอบรมหลังการฝึก (post-training) ที่มีเป้าหมายบนทราฟฟิกการผลิตแบบแบ่งชั้นและชุดข้อมูลคลาสสิกเช่น FActScore (คำถามชีวประวัติ 500 ข้อ) นอกจากนี้ โหมดที่ไม่คิดตอนนี้จะเรียกใช้เครื่องมือค้นหาบนเว็บเชิงรุกเมื่อความเชื่อมั่นลดลงต่ำกว่าเกณฑ์ภายใน ซึ่งช่วยยึดโยงการตอบสนองกับแหล่งที่มาที่ตรวจสอบได้

การประเมินความปลอดภัยและความรับผิดชอบ
บัตรข้อมูลโมเดลอย่างเป็นทางการ ให้ความโปร่งใสที่ไม่เคยมีมาก่อนเกี่ยวกับผลลัพธ์ของทีมแดง (red-team results)
ตัวกรองอินพุตบล็อกคำถามชีววิทยาและเคมีที่ถูกจำกัด โดยมีอัตรา False-negative ต่ำถึง 0.00–0.03 ภายใต้คำขอโดยตรง การโจมตีแบบ Prompt injection ทำให้ตัวเลขนั้นเพิ่มขึ้นเล็กน้อย (0.12–0.20) ซึ่งบ่งชี้ถึงการทำงานด้านความทนทานต่อการโจมตีอย่างต่อเนื่อง
อัตราการปฏิเสธในข้อความแชทที่ละเมิดกฎหมายสูงถึง 93–95% แม้จะไม่มีตัวกรอง และความสำเร็จในการเจลเบรก (jailbreak) ลดลงใกล้ศูนย์ในการกำหนดค่าที่ไม่คิด สถานการณ์เชิงตัวแทน (Agentic scenarios) (AgentHarm, AgentDojo) ยังคงเป็นหมวดหมู่ที่ยากที่สุด แต่อัตราการตอบคำถามแน่นอนยังคงต่ำกว่า 0.14
การประเมินความสามารถในการใช้งานสองวัตถุประสงค์ (Dual-use capability assessments) — ที่ดำเนินการโดยเจตนาโดยไม่มีมาตรการป้องกัน — เผยให้เห็นการเรียกคืนความรู้ที่แข็งแกร่งในด้านชีววิทยา (WMDP-Bio 87%) และเคมี แต่การให้เหตุผลเชิงกระบวนการแบบหลายขั้นตอนยังล้าหลังมาตรฐานผู้เชี่ยวชาญมนุษย์ในงานที่ต้องตีความภาพหรือโปรโตคอลการโคลน รูปแบบนี้สอดคล้องกับข้อจำกัดของโมเดลชั้นนำในปัจจุบันทั่วทั้งอุตสาหกรรม
ผลกระทบสำหรับผู้ใช้ API และนักพัฒนา
xAI API ให้บริการ Grok 4.1 endpoints ภายใต้ชื่อโมเดลมาตรฐานอยู่แล้ว โปรไฟล์ความหน่วง (Latency profiles) ดีขึ้นอย่างเห็นได้ชัด: โหมด non-thinking มีค่าเฉลี่ยต่ำกว่า 400 มิลลิวินาทีสำหรับเวลาถึงโทเค็นแรก (time-to-first-token) สำหรับ prompts ทั่วไป ในขณะที่โหมด thinking เพิ่มความลึกของการให้เหตุผลที่ควบคุมได้ผ่านพารามิเตอร์เสริม
Apidog โดดเด่นอย่างมากในจุดนี้ นำเข้าข้อกำหนด OpenAPI 3.1 อย่างเป็นทางการ (ที่เผยแพร่ต่อสาธารณะ) จากนั้นสร้าง Client SDK ในกว่า 20 ภาษาได้ทันที ตั้งค่า Mock Server ที่จำลอง Schema การตอบสนองที่แน่นอนของ Grok 4.1 — รวมถึงสตรีมโทเค็นการคิดใหม่ — เพื่อให้การทดสอบแบ็กเอนด์ของคุณไม่เคยหยุดชะงักจากการใช้เครดิต API จริง เมื่อ xAI ปรับใช้การเปลี่ยนแปลงที่อาจส่งผลกระทบ (หายาก แต่เป็นไปได้) ตัวดูความแตกต่าง (diff viewer) ของ Apidog จะเน้นความคลาดเคลื่อนของ Schema ทันที
ทีมงานจริงใช้ Apidog เพื่อรักษา uptime 100% ในระหว่างการอัปเกรดโมเดล ลูกค้า Fortune-500 รายหนึ่งรายงานว่าลดข้อผิดพลาดในการรวมระบบได้ 68% หลังจากเปลี่ยนจาก Postman
การเปรียบเทียบกับโมเดลชั้นนำร่วมสมัย
ข้อมูลการเปรียบเทียบแบบตัวต่อตัวโดยตรงยังมีไม่มากหลังจากเปิดตัวได้ไม่กี่ชั่วโมง แต่คะแนน Elo ของ LMArena ให้สัญญาณที่ชัดเจนที่สุด Grok 4.1 Thinking มีประสิทธิภาพเหนือกว่าทุกการกำหนดค่าที่เปิดตัวจาก OpenAI, Anthropic, Google และ Meta ด้วยส่วนต่างที่โดยปกติแล้วจะต้องมีการก้าวกระโดดทางสถาปัตยกรรมอย่างเต็มรูปแบบ
การแลกเปลี่ยนระหว่างความเร็วและคุณภาพ (Speed-quality tradeoffs) สนับสนุน Grok 4.1 non-thinking สำหรับการแชทของผู้บริโภค ในขณะที่โหมด thinking แข่งขันโดยตรงกับข้อเสนอที่เน้นการให้เหตุผลอย่าง o3-pro หรือ Claude 4 Opus — ซึ่งมักจะชนะในด้านความสอดคล้องกันทางอัตวิสัย (subjective coherence) และการรักษาบุคลิกภาพ
บทสรุป
Grok 4.1 ไม่เพียงแค่เพิ่มตัวชี้วัดเท่านั้น แต่ยังปรับทิศทางของเทคโนโลยีชั้นนำไปสู่โมเดลที่ผู้คนจะเพลิดเพลินกับการพูดคุยด้วยเป็นเวลาหลายชั่วโมง ผู้ใช้ทางเทคนิคจะได้รับ Endpoint ที่เร็วขึ้นและเชื่อถือได้มากขึ้น นักสร้างสรรค์จะได้ร่วมงานกับผู้ช่วยที่เข้าใจน้ำเสียงและอารมณ์ในระดับที่ไม่เคยมีมาก่อน และนักวิจัยด้านความปลอดภัยจะได้รับ Model Card ที่ละเอียดที่สุดเท่าที่เคยเผยแพร่มา
ดาวน์โหลด Apidog วันนี้ — ฟรีทั้งหมด — และเริ่มสร้างด้วย Grok 4.1 ก่อนที่คู่แข่งของคุณจะอ่านประกาศจบลง ความแตกต่างระหว่างการเฝ้าดูความก้าวหน้าของเทคโนโลยีชั้นนำกับการนำผลิตภัณฑ์ออกสู่ตลาด มักขึ้นอยู่กับการตัดสินใจด้านเครื่องมือที่ทำในวันนี้