
วิศวกรและนักพัฒนาต่างมองหารูปแบบโมเดลที่มีประสิทธิภาพสูงโดยไม่ใช้ทรัพยากรมากเกินไป GLM-4.7-Flash ได้ก้าวขึ้นมาเป็นตัวเลือกที่น่าสนใจในสถานการณ์นี้ โมเดล Mixture-of-Experts (MoE) 30B-A3B นี้ พัฒนาโดย Zhipu AI (Z.ai) โดดเด่นด้วยความสมดุลระหว่างความแข็งแกร่งและประสิทธิภาพ โดยมีความสามารถที่ยอดเยี่ยมในการทำคะแนนเกณฑ์มาตรฐานการเขียนโค้ด งานการให้เหตุผล และการผสานรวมเครื่องมือ ทำให้เหมาะสำหรับสถานการณ์การติดตั้งใช้งานในเครื่อง
การรัน GLM-4.7-Flash บนเครื่องช่วยให้ผู้ใช้สามารถรักษาความเป็นส่วนตัวของข้อมูล ลดความหน่วง และปรับแต่งการผสานรวมได้ เครื่องมืออย่าง Ollama, LM Studio และ Hugging Face ทำให้กระบวนการนี้ง่ายขึ้น
เมื่อคุณดำเนินการตามคู่มือนี้ คุณจะได้รับข้อมูลเชิงลึกที่เป็นประโยชน์เกี่ยวกับการติดตั้งและการใช้งาน ก่อนอื่น ให้พิจารณาข้อกำหนดพื้นฐานของระบบ
GLM-4.7-Flash คืออะไร และเหตุใดจึงควรใช้ในเครื่อง
GLM-4.7-Flash แสดงถึงความก้าวหน้าในโมเดลภาษาโอเพนซอร์ส สร้างขึ้นบนสถาปัตยกรรม glm4_moe_lite โดยใช้ประเภทเทนเซอร์ BF16 และ F32 ภายใต้ใบอนุญาต MIT เอกสารของโมเดล "GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models" ให้รายละเอียดเกี่ยวกับการฝึกอบรมเพื่อการใช้เครื่องมือและการให้เหตุผล โดยอ้างอิงจาก arXiv:2508.06471
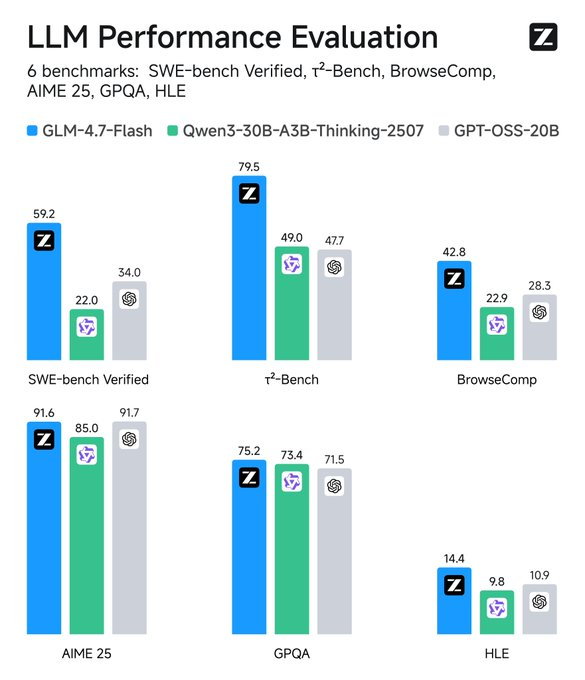
คุณสมบัติหลัก ได้แก่ การรองรับภาษาอังกฤษและจีน การสร้างข้อความ และงานสนทนา รองรับอินพุตแบบหลายรูปแบบเป็นข้อความ แต่เน้นที่เอาต์พุตแบบข้อความเท่านั้น ข้อจำกัดเกิดขึ้นจากขนาดของโมเดล—แม้จะมีประสิทธิภาพ แต่ก็อาจไม่ตรงกับโมเดลขนาดใหญ่กว่าในโดเมนเฉพาะทางโดยไม่ต้องปรับแต่ง ข้อมูลรายละเอียดการฝึกอบรมยังไม่เปิดเผย แต่การประเมินยืนยันความได้เปรียบในการเขียนโค้ดและสถานการณ์ที่เกี่ยวข้องกับเอเจนต์
ผู้ใช้เลือกที่จะรันในเครื่องเพื่อหลีกเลี่ยงค่าใช้จ่าย API Z.ai เสนอระดับฟรีสำหรับ GLM-4.7-Flash ผ่านแพลตฟอร์มของพวกเขา แต่การติดตั้งใช้งานในเครื่องจะขจัดความพึ่งพาบริการภายนอก วิธีการนี้เหมาะสำหรับนักพัฒนาที่สร้างแอปพลิเคชันที่กำหนดเอง นักวิจัยที่ทดสอบสมมติฐาน หรือองค์กรที่ให้ความสำคัญกับความปลอดภัย ตัวอย่างเช่น คุณสามารถควบคุมระดับการควอนไทซ์เพื่อให้เหมาะสมกับข้อจำกัดของฮาร์ดแวร์ เพื่อให้มั่นใจถึงประสิทธิภาพสูงสุด
ข้อกำหนดของระบบสำหรับการรัน GLM-4.7-Flash ในเครื่อง
ฮาร์ดแวร์มีบทบาทสำคัญในการอนุมานโมเดล GLM-4.7-Flash ต้องการหน่วยความจำระบบอย่างน้อย 16 GB สำหรับการทำงานพื้นฐาน ตามที่ระบุในแนวทางของ LM Studio อย่างไรก็ตาม การเร่งความเร็ว GPU ช่วยเพิ่มความเร็วได้อย่างมาก
สำหรับเวอร์ชัน Ollama:
- q4_K_M: 19 GB VRAM
- q8_0: 32 GB VRAM
- bf16: 60 GB VRAM
Hugging Face แนะนำให้ใช้ torch.bfloat16 เพื่อประสิทธิภาพ ซึ่งต้องใช้ NVIDIA GPU ที่เข้ากันได้ (สถาปัตยกรรม Ampere หรือใหม่กว่า) การอนุมานเฉพาะ CPU สามารถทำได้ แต่จะช้าลงอย่างมากสำหรับบริบทขนาดใหญ่
ข้อกำหนดเบื้องต้นของซอฟต์แวร์ ได้แก่ Python 3.8+, pip และ Git เฟรมเวิร์กเช่น Transformers ต้องการการติดตั้งเพิ่มเติม ตรวจสอบให้แน่ใจว่า OS ของคุณรองรับ CUDA สำหรับการใช้ GPU—Ubuntu 20.04 หรือ Windows ที่มี WSL2 ทำงานได้ดี
หากทรัพยากรไม่เพียงพอ การควอนไทซ์จะลดการใช้หน่วยความจำ เครื่องมืออย่าง llama.cpp หรือ Unsloth เสนอเวอร์ชัน 4 บิตหรือ 2 บิต ทำให้ลดความต้องการ VRAM เหลือ 15-20 GB ความยืดหยุ่นนี้ช่วยให้สามารถติดตั้งใช้งานบนฮาร์ดแวร์ของผู้ใช้ทั่วไป เช่น RTX 4090
เมื่อตรงตามข้อกำหนดแล้ว ให้สำรวจวิธีการติดตั้ง เริ่มต้นด้วย Ollama เพื่อความเรียบง่าย
วิธีการติดตั้งและใช้ GLM-4.7-Flash ด้วย Ollama
Ollama มอบแพลตฟอร์มที่เข้าถึงได้สำหรับการรันโมเดลขนาดใหญ่ในเครื่อง จัดการการควอนไทซ์และการให้บริการ API โดยอัตโนมัติ
ขั้นแรก ติดตั้ง Ollama ดาวน์โหลดไฟล์ปฏิบัติการสำหรับ OS ของคุณและรัน

ตรวจสอบการติดตั้งด้วย ollama --version เพื่อให้แน่ใจว่าเป็นเวอร์ชัน 0.14.3 หรือใหม่กว่า เนื่องจาก GLM-4.7-Flash ต้องการเวอร์ชันดังกล่าว

ถัดไป ดึงโมเดล: รัน ollama pull glm-4.7-flash

เลือกเวอร์ชันเช่น glm-4.7-flash:q4_K_M เพื่อการใช้หน่วยความจำที่ต่ำลง คำสั่งนี้จะดาวน์โหลดประมาณ 19 GB สำหรับเวอร์ชัน q4
รันโมเดลแบบโต้ตอบ: พิมพ์ ollama run glm-4.7-flash ป้อนพรอมต์เช่น "Generate Python code for a Fibonacci sequence." โมเดลจะตอบสนองด้วยเอาต์พุตที่มีเหตุผล โดยใช้ประโยชน์จากความแข็งแกร่งในการเขียนโค้ด
สำหรับการเข้าถึงแบบโปรแกรม ให้ใช้ API ส่งคำขอ curl:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
สิ่งนี้จะส่งคืน JSON พร้อมการตอบสนอง ใน Python ให้ผสานรวมกับไลบรารี ollama:
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
JavaScript ก็คล้ายกันด้วยแพ็กเกจ npm ของ ollama
ปรับแต่งการกำหนดค่าโดยการแก้ไข Modelfile ตั้งค่าอุณหภูมิเป็น 0.7 สำหรับเอาต์พุตที่แน่นอนในงานการเขียนโค้ด โหมดล่าสุดของ Ollama จะดึงโพสต์ล่าสุดหากจำเป็น แต่ในที่นี้เน้นที่การอนุมานในเครื่อง
วิธีนี้เหมาะสำหรับการตั้งค่าอย่างรวดเร็ว อย่างไรก็ตาม สำหรับส่วนติดต่อผู้ใช้แบบกราฟิก ให้ใช้ LM Studio
การตั้งค่า GLM-4.7-Flash ใน LM Studio
LM Studio นำเสนอ GUI ที่ใช้งานง่ายสำหรับการจัดการโมเดล ดาวน์โหลดและติดตั้ง
ค้นหา "zai-org/glm-4.7-flash" ในโมเดลฮับ เลือกเวอร์ชันที่ควอนไทซ์—MLX-4bit, 6bit หรือ 8bit—จากที่เก็บ Hugging Face ที่เชื่อมโยง การดาวน์โหลดจะเสร็จสมบูรณ์ในแอป
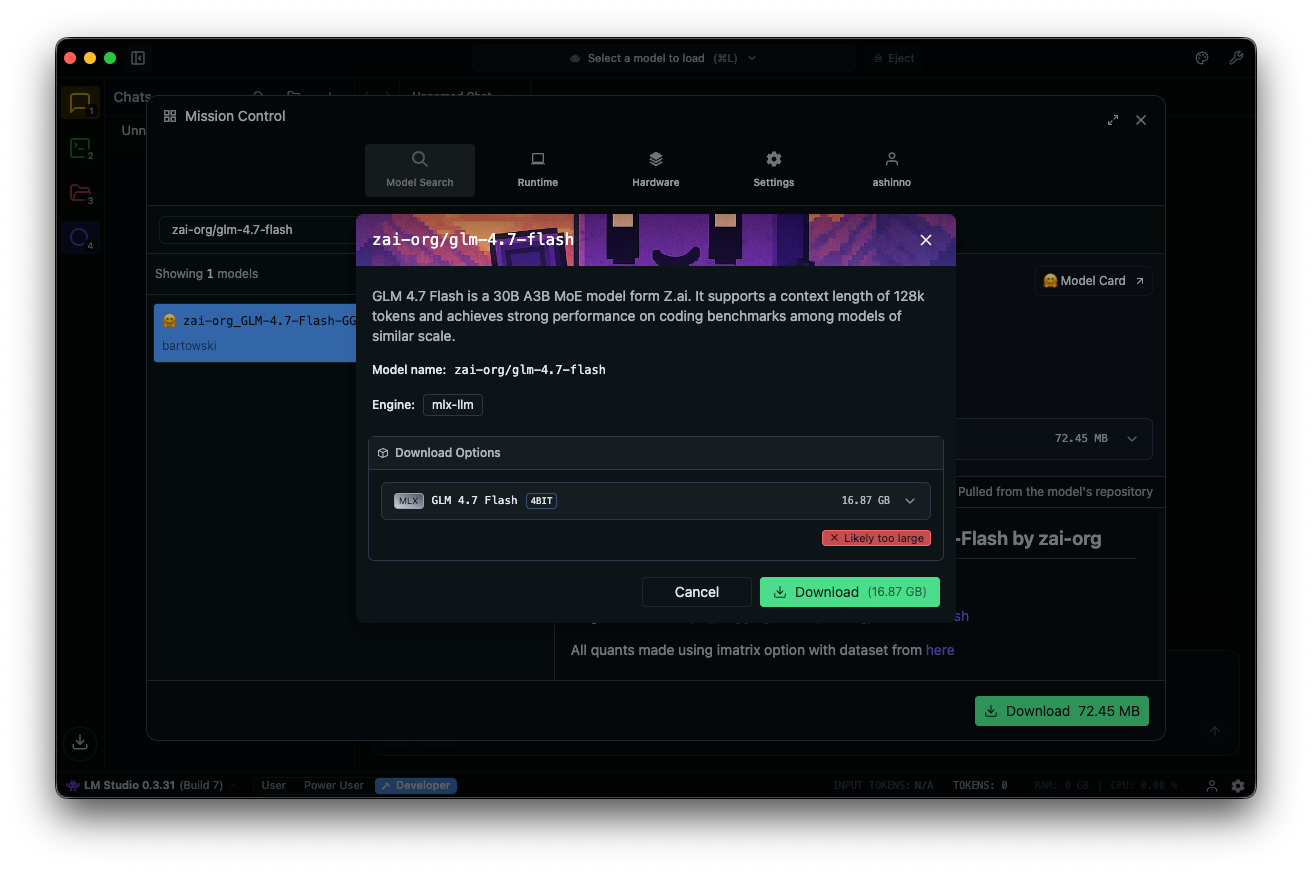
โหลดโมเดล: ไปที่ส่วนติดต่อการสนทนา เลือก GLM-4.7-Flash และปรับพารามิเตอร์ เปิดใช้งานการคิด (ค่าเริ่มต้น: จริง) สำหรับการให้เหตุผลแบบทีละขั้นตอน ตั้งค่าอุณหภูมิเป็น 1, top_k เป็น 50, top_p เป็น 0.95 และปิดใช้งานการลงโทษการทำซ้ำ
ทดสอบด้วยพรอมต์: "ออกแบบ REST API สำหรับการยืนยันตัวตนผู้ใช้" LM Studio จะแสดงเอาต์พุตพร้อมความเร็วของโทเค็น ซึ่งช่วยในการปรับแต่งประสิทธิภาพ
ฟิลด์ที่กำหนดเองเช่น clear_thinking (ค่าเริ่มต้น: เท็จ) จัดการประวัติ สำหรับโมเดล MoE ให้ตรวจสอบผู้เชี่ยวชาญที่ใช้งานอยู่—A3B หมายถึงผู้เชี่ยวชาญสามคนที่ทำงานในการส่งผ่านไปข้างหน้าแต่ละครั้ง ซึ่งช่วยเพิ่มประสิทธิภาพ
LM Studio รองรับ deeplinks สำหรับการเข้าถึงโมเดลโดยตรง หากเกิดปัญหา ให้ตรวจสอบหน่วยความจำระบบ—ขั้นต่ำ 16 GB ป้องกันการแครช
เครื่องมือนี้ยอดเยี่ยมสำหรับการทดลอง สำหรับการเขียนสคริปต์ขั้นสูง ให้ผสานรวมกับ Hugging Face
การใช้ GLM-4.7-Flash กับ Hugging Face Transformers
Hugging Face มีไลบรารีที่แข็งแกร่งสำหรับการควบคุมอย่างละเอียด ติดตั้ง Transformers จากสาขาหลัก:
pip install git+https://github.com/huggingface/transformers.git
โหลดโมเดล:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
เตรียมอินพุต:
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
สร้าง:
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
การตั้งค่านี้รองรับการควอนไทซ์ผ่าน bitsandbytes สำหรับ VRAM ที่ต่ำลง เพิ่ม load_in_4bit=True ในการโหลดโมเดล
สำหรับการให้บริการ ให้ใช้ vLLM หรือ SGLang ติดตั้ง vLLM:
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
รันเซิร์ฟเวอร์:
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
เข้าถึงผ่านปลายทางที่เข้ากันได้กับ OpenAI SGLang ต้องการการติดตั้งจากซอร์สและทำตามขั้นตอนที่คล้ายกัน
เฟรมเวิร์กเหล่านี้ช่วยให้สามารถติดตั้งใช้งานระดับโปรดักชันได้ ตอนนี้ พิจารณาการทดสอบ API ด้วย Apidog
การผสานรวม Apidog สำหรับการทดสอบ API ด้วย GLM-4.7-Flash ในเครื่อง
เมื่อคุณให้บริการ GLM-4.7-Flash ผ่าน Ollama หรือ vLLM แล้ว ให้ทดสอบปลายทางได้อย่างมีประสิทธิภาพ Apidog ซึ่งเป็นแพลตฟอร์ม API แบบครบวงจร จะช่วยอำนวยความสะดวกในเรื่องนี้
ดาวน์โหลด Apidog ฟรี รองรับคุณสมบัติ AI โดยการกำหนดค่าโมเดลในเครื่องของคุณเป็นผู้ให้บริการ—ใช้คีย์ API หากมี หรือปลายทางโดยตรง
MCP Server ของ Apidog ผสานรวมกับ IDEs เช่น Cursor โดยใช้ข้อมูลจำเพาะของ API สำหรับการสร้างโค้ด สิ่งนี้เชื่อมโยงกลับไปที่ความสามารถในการเขียนโค้ดของ GLM-4.7-Flash—ทดสอบเอาต์พุตเชิงตัวแทนโดยตรง
ตัวอย่างเช่น สอบถามเซิร์ฟเวอร์ในเครื่องของคุณและตรวจสอบการตอบสนอง สิ่งนี้ช่วยให้มั่นใจถึงความน่าเชื่อถือในแอปพลิเคชัน
สร้างจากพื้นฐาน ไปสู่การเพิ่มประสิทธิภาพ
เคล็ดลับขั้นสูงสำหรับการเพิ่มประสิทธิภาพ GLM-4.7-Flash
ปรับแต่งพารามิเตอร์สำหรับงานต่างๆ ตั้งค่าอุณหภูมิเป็น 0.7 สำหรับการเขียนโค้ด 1.0 สำหรับการเขียนเชิงสร้างสรรค์ ใช้ top_p 0.95 เพื่อรักษาสมดุลของความหลากหลาย
ควอนไทซ์เพิ่มเติมด้วยรูปแบบ GGUF ผ่าน llama.cpp คอมไพล์ llama.cpp ด้วย CUDA จากนั้นแปลง:
./llama-gguf-split --model GLM-4.7-Flash.gguf
รันด้วย --jinja สำหรับการรองรับเทมเพลต
จัดการบริบทที่ยาว: แบ่งอินพุตหากเกิน 128K เปิดใช้งานการคิดสำหรับคำถามที่ซับซ้อน
ตรวจสอบเมตริก: เครื่องมืออย่าง TensorBoard ติดตามความหน่วง เปรียบเทียบกับเกณฑ์มาตรฐาน—GLM-4.7-Flash ชนะคู่แข่งใน SWE-bench 37.2 คะแนน
ผสานรวมเครื่องมือ: เพิ่มการเรียกใช้ฟังก์ชันในพรอมต์สำหรับพฤติกรรมเชิงตัวแทน
ความปลอดภัย: รันในสภาพแวดล้อมที่แยกต่างหากเพื่อป้องกันข้อมูลรั่วไหล
กลยุทธ์เหล่านี้ช่วยเพิ่มประโยชน์สูงสุด พิจารณาแอปพลิเคชันต่อไป
การแก้ไขปัญหาทั่วไป
พบข้อผิดพลาดหน่วยความจำไม่พอใช่หรือไม่? ลดขนาดแบตช์หรือควอนไทซ์ให้ต่ำลง
การอนุมานช้าใช่หรือไม่? อัปเกรด GPU หรือใช้เฟรมเวิร์กที่เร็วกว่าเช่น vLLM
ปัญหาความเข้ากันได้ใช่หรือไม่? อัปเดต Transformers เป็นเวอร์ชันหลัก
หาก Ollama ล้มเหลว ให้ตรวจสอบความพร้อมใช้งานของพอร์ต 11434
LM Studio แครชใช่หรือไม่? ตรวจสอบความสมบูรณ์ของโมเดล
จัดการปัญหาเหล่านี้เชิงรุก
บทสรุป: เพิ่มประสิทธิภาพการทำงานของคุณด้วย GLM-4.7-Flash
การรัน GLM-4.7-Flash ในเครื่องจะปลดล็อกความสามารถ AI ที่ทรงพลัง มีตัวเลือกมากมายตั้งแต่ความง่ายของ Ollama ไปจนถึงความยืดหยุ่นของ Hugging Face ผสานรวม Apidog สำหรับการจัดการ API ที่ราบรื่น—ดาวน์โหลดฟรีเพื่อยกระดับการตั้งค่าของคุณ
เมื่อเทคโนโลยีก้าวหน้า โมเดลเช่นนี้จะเชื่อมโยงประสิทธิภาพและการเข้าถึงได้ นำขั้นตอนเหล่านี้ไปใช้ แล้วคุณจะบรรลุการติดตั้งใช้งาน AI ที่มีประสิทธิภาพและเป็นส่วนตัว การปรับเปลี่ยนพารามิเตอร์หรือเครื่องมือเพียงเล็กน้อยจะนำมาซึ่งการปรับปรุงที่สำคัญ เปลี่ยนงานประจำให้เป็นกระบวนการที่คล่องตัว