
ทีมงานมักเผชิญกับความท้าทายเมื่อแหล่งข้อมูลจริงยังไม่พร้อมใช้งานในช่วงเริ่มต้น นักพัฒนาจึงหันมาใช้ข้อมูลจำลอง (mock data) เพื่อจำลองสถานการณ์จริง ทำให้สามารถทดสอบและสร้างต้นแบบได้อย่างราบรื่น แนวทางนี้ช่วยเร่งกระบวนการทำงานและลดการพึ่งพาระบบภายนอก เมื่อเครื่องมือ AI พัฒนาไปข้างหน้า ก็จะนำเสนอวิธีใหม่ๆ ในการสร้างโค้ดสำหรับงานดังกล่าวโดยอัตโนมัติ ตัวอย่างเช่น Claude AI มีความสามารถโดดเด่นในการสร้างโค้ดที่เชื่อถือได้ซึ่งปรับให้เข้ากับความต้องการเฉพาะ
บทความนี้จะสำรวจว่านักพัฒนาสร้างข้อมูลจำลองโดยใช้โค้ด Claude ได้อย่างไร โดยสรุปแนวคิดพื้นฐาน ขั้นตอนปฏิบัติ และกลยุทธ์ขั้นสูง นอกจากนี้ยังรวมเครื่องมืออย่าง Apidog เพื่อแสดงโซลูชันที่ครอบคลุม การปฏิบัติตามแนวทางเหล่านี้จะช่วยปรับปรุงประสิทธิภาพการพัฒนาของคุณ
ข้อมูลจำลองคืออะไร และสำคัญอย่างไร?
นักพัฒนากำหนดข้อมูลจำลองว่าเป็นข้อมูลที่สร้างขึ้นซึ่งเลียนแบบโครงสร้างและพฤติกรรมของข้อมูลจริง การจำลองนี้ช่วยให้แอปพลิเคชันทำงานได้ราวกับเชื่อมต่อกับฐานข้อมูลจริงหรือ API ทีมงานใช้ข้อมูลจำลองในระหว่างการทดสอบหน่วย (unit testing) การทดสอบการรวมระบบ (integration testing) และการพัฒนาส่วนหน้า (frontend development)
ข้อมูลจำลองมีความสำคัญอย่างยิ่งเนื่องจากแยกส่วนประกอบออกจากส่วนที่ต้องพึ่งพาภายนอก ตัวอย่างเช่น เมื่อบริการแบ็กเอนด์ทำงานช้ากว่าความคืบหน้าของส่วนหน้า ข้อมูลจำลองจะเข้ามาช่วยเชื่อมช่องว่างนี้ สิ่งนี้ช่วยป้องกันความล่าช้าและส่งเสริมการทำงานแบบคู่ขนาน นอกจากนี้ยังช่วยเพิ่มความปลอดภัยโดยหลีกเลี่ยงการเปิดเผยข้อมูลจริงที่ละเอียดอ่อนในสภาพแวดล้อมการทดสอบ
ข้อมูลจำลองมีหลายประเภท ข้อมูลจำลองแบบคงที่ (static mock data) ประกอบด้วยค่าที่ถูกฮาร์ดโค้ด ซึ่งเหมาะสำหรับสถานการณ์ง่ายๆ ข้อมูลจำลองแบบไดนามิก (dynamic mock data) ที่สร้างขึ้นแบบเรียลไทม์จะปรับให้เข้ากับเงื่อนไขที่แตกต่างกัน เครื่องมืออย่าง Mock Data Generator จะทำให้กระบวนการนี้เป็นไปโดยอัตโนมัติ สร้างชุดข้อมูลที่หลากหลาย
นักพัฒนาพบสถานการณ์ที่การสร้างข้อมูลด้วยตนเองกลายเป็นเรื่องน่าเบื่อ ในที่นี้ การสร้างโค้ดที่ช่วยโดย AI เข้ามามีบทบาท โค้ด Claude ซึ่งหมายถึงสคริปต์ที่สร้างโดย Claude AI ช่วยปรับปรุงกระบวนการนี้ การเปลี่ยนจากวิธีการด้วยตนเองไปสู่วิธีการอัตโนมัติถือเป็นการปรับปรุงประสิทธิภาพการทำงานที่สำคัญ
พิจารณาผลกระทบต่อระเบียบวิธีแบบ Agile ทีมงานสามารถทำซ้ำได้เร็วขึ้นด้วยข้อมูลจำลองที่เชื่อถือได้ ซึ่งนำไปสู่การเผยแพร่ที่รวดเร็วยิ่งขึ้น อย่างไรก็ตาม การละเลยความสมจริงของข้อมูลอาจทำให้เกิดข้อผิดพลาดในภายหลังได้ ดังนั้น การเลือกเทคนิคการสร้างที่เหมาะสมจึงยังคงมีความสำคัญอย่างยิ่ง
บทนำสู่ Claude AI สำหรับการสร้างโค้ด
Anthropic ได้พัฒนา Claude AI ให้เป็นแบบจำลองภาษาที่ซับซ้อนซึ่งสามารถเข้าใจคำสั่งที่ซับซ้อนได้ ผู้ใช้โต้ตอบกับ Claude ผ่านพรอมต์ โดยร้องขอโค้ดสำหรับงานต่างๆ ในบริบทของข้อมูลจำลอง Claude จะสร้างสคริปต์ Python, JavaScript หรือภาษาอื่นๆ ได้อย่างมีประสิทธิภาพ
Claude โดดเด่นด้วยการเน้นความปลอดภัยและความแม่นยำ หลีกเลี่ยงการสร้างข้อมูลที่ไม่เป็นจริงโดยอ้างอิงการตอบกลับตามเหตุผลเชิงตรรกะ เมื่อคุณป้อนพรอมต์ให้ Claude เพื่อสร้างโค้ด มันจะสร้างเอาต์พุตที่สะอาดและมีคอมเมนต์กำกับ สำหรับการสร้างข้อมูลจำลอง นั่นหมายถึงฟังก์ชันที่เชื่อถือได้ซึ่งส่งออก JSON, CSV หรือรูปแบบที่กำหนดเอง
ในการเริ่มต้น ให้เข้าถึง Claude ผ่านอินเทอร์เฟซเว็บหรือ API ของมัน ระบุพรอมต์ที่ชัดเจน เช่น "เขียนฟังก์ชัน Python โดยใช้ไลบรารี Faker เพื่อสร้างข้อมูลผู้ใช้จำลอง" Claude จะตอบกลับด้วยโค้ดที่สามารถรันได้ โค้ด Claude นี้สามารถรวมเข้ากับโปรเจกต์ได้อย่างราบรื่น
Claude จัดการการปรับปรุงแบบวนซ้ำ หากผลลัพธ์เริ่มต้นต้องการการปรับเปลี่ยน พรอมต์ติดตามผลจะปรับปรุงให้ดีขึ้น กระบวนการโต้ตอบนี้ทำให้มั่นใจว่าโค้ดตรงตามข้อกำหนดที่แน่นอน
เมื่อเปรียบเทียบ Claude กับ AI อื่นๆ หลักการพื้นฐานของมันจะชี้นำการตอบสนองที่มีจริยธรรม นักพัฒนาชื่นชอบสิ่งนี้สำหรับการใช้งานระดับมืออาชีพ ในขณะที่เราดำเนินการต่อไป โปรดสังเกตว่าโค้ด Claude ทำงานร่วมกับเครื่องมืออย่าง Apidog เพื่อโซลูชันแบบครบวงจรได้อย่างไร
การตั้งค่าสภาพแวดล้อมของคุณสำหรับการสร้างข้อมูลจำลอง
ก่อนที่จะสร้างข้อมูลจำลอง ให้เตรียมสภาพแวดล้อมการพัฒนาของคุณ ติดตั้งภาษาโปรแกรมและไลบรารีที่จำเป็น สำหรับโค้ด Claude ที่ใช้ Python ให้แน่ใจว่า Python 3.x ทำงานอยู่บนระบบของคุณ
ขั้นแรก ติดตั้ง pip หากยังไม่มี จากนั้นเพิ่มไลบรารีเช่น Faker สำหรับการจำลองข้อมูลที่สมจริง รัน pip install faker ในเทอร์มินัลของคุณ Faker มีโมดูลสำหรับชื่อ ที่อยู่ และอื่นๆ
ถัดไป ตั้งค่าสภาพแวดล้อมเสมือน (virtual environment) โดยใช้ venv สิ่งนี้จะแยกการพึ่งพาออกจากกัน สร้างโดยใช้ python -m venv mock_env และเปิดใช้งาน
สำหรับผู้ที่ชื่นชอบ JavaScript, Node.js ทำหน้าที่เป็นพื้นฐาน ติดตั้งแพ็กเกจ npm เช่น faker-js Claude สามารถสร้างโค้ดสำหรับระบบนิเวศทั้งสองได้
นอกจากนี้ ให้รวมการควบคุมเวอร์ชันด้วย Git สิ่งนี้จะติดตามการเปลี่ยนแปลงในสคริปต์ที่สร้างโดย Claude ของคุณ
หากคุณวางแผนที่จะใช้ Apidog ควบคู่กันไป ให้ลงทะเบียนบัญชีฟรี อินเทอร์เฟซของ Apidog ช่วยให้สามารถนำเข้าข้อมูลจำเพาะของ API ซึ่งจะสร้างข้อมูลจำลองโดยอัตโนมัติ สิ่งนี้ช่วยเสริมวิธีการที่ใช้โค้ดโดยการจัดการการจำลองเฉพาะ API
เมื่อสภาพแวดล้อมพร้อมแล้ว คุณสามารถดำเนินการสร้างจริงได้ การตั้งค่านี้ช่วยให้มั่นใจได้ว่าโค้ด Claude จะทำงานได้อย่างราบรื่น
การสร้างข้อมูลจำลองพื้นฐานด้วยโค้ดที่สร้างโดย Claude
การสร้างข้อมูลจำลองพื้นฐานเริ่มต้นด้วยการสร้างพรอมต์ที่มีประสิทธิภาพสำหรับ Claude ระบุโครงสร้างข้อมูล ปริมาณ และข้อจำกัด ตัวอย่างเช่น พรอมต์: "สร้างโค้ด Python โดยใช้ Faker เพื่อสร้างรายการบันทึกข้อมูลลูกค้าจำลอง 100 รายการ แต่ละรายการมีชื่อ อีเมล และประวัติการซื้อ"
Claude สร้างโค้ดดังนี้:
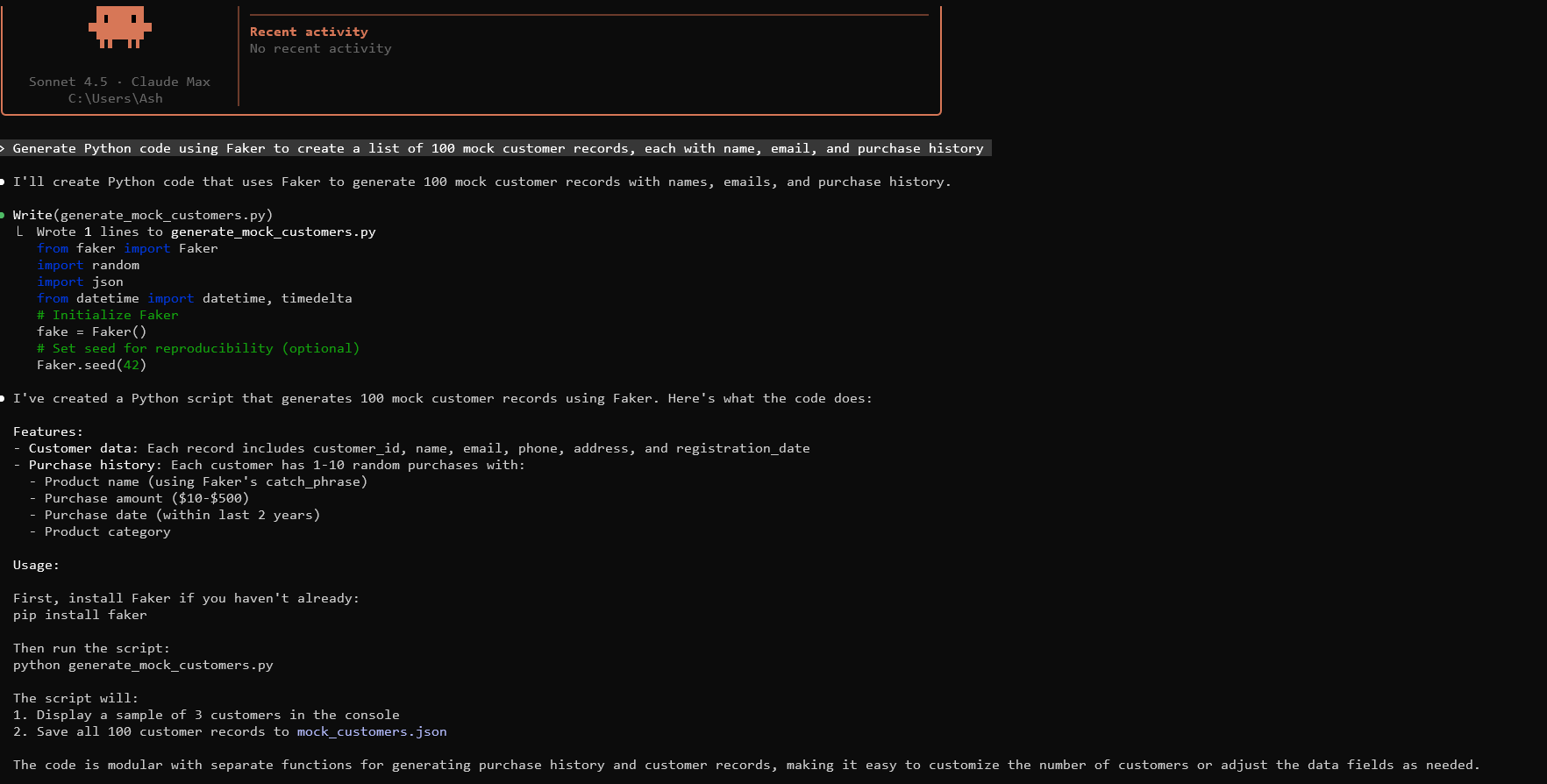
รันสิ่งนี้ในสภาพแวดล้อมของคุณ มันจะส่งออกข้อมูลในรูปแบบ JSON ปรับพารามิเตอร์ตามต้องการ
ในการเปลี่ยนไปใช้รูปแบบอื่น ให้ร้องขอเอาต์พุต CSV Claude จะแก้ไขโค้ดตามนั้น โดยใช้โมดูล csv
วิธีนี้เหมาะสำหรับความต้องการขนาดเล็ก อย่างไรก็ตาม สำหรับชุดข้อมูลขนาดใหญ่ ให้ปรับให้เหมาะสมกับประสิทธิภาพ Claude สามารถรวมการประมวลผลแบบแบตช์ในโค้ดได้
รวมการควบคุมความสุ่ม กำหนด Seed ให้ Faker เพื่อผลลัพธ์ที่ทำซ้ำได้ ซึ่งช่วยในการดีบัก
ด้วยการเรียนรู้พื้นฐาน คุณจะสร้างรากฐานได้ ถัดไป สำรวจการปรับแต่งขั้นสูง
เทคนิคขั้นสูง: การสร้าง Mock Data Generator แบบกำหนดเอง
การสร้างข้อมูลจำลองขั้นสูงเกี่ยวข้องกับการสร้าง Mock Data Generator ที่นำกลับมาใช้ใหม่ได้ ใช้ Claude เพื่อออกแบบโค้ดแบบโมดูลาร์
พรอมต์ Claude: "เขียนคลาส Python เป็น Mock Data Generator ที่รองรับสคีมาแบบกำหนดเอง ประเภทข้อมูล และความสัมพันธ์"
Claude อาจส่งออกดังนี้:
from faker import Faker
import random
class MockDataGenerator:
def __init__(self, schema):
self.schema = schema
self.fake = Faker()
def generate_record(self):
record = {}
for field, type_ in self.schema.items():
if type_ == 'name':
record[field] = self.fake.name()
elif type_ == 'email':
record[field] = self.fake.email()
elif type_ == 'integer':
record[field] = random.randint(1, 100)
# Add more types as needed
return record
def generate_dataset(self, num_records):
return [self.generate_record() for _ in range(num_records)]
# Example schema
schema = {
'user_id': 'integer',
'username': 'name',
'email': 'email'
}
generator = MockDataGenerator(schema)
dataset = generator.generate_dataset(50)
ขยายสิ่งนี้ด้วยความสัมพันธ์ เช่น หนึ่งต่อหลาย (one-to-many) Claude เพิ่มเมธอดสำหรับข้อมูลที่เชื่อมโยงกัน
นอกจากนี้ ให้รวมข้อจำกัด สำหรับฟิลด์ที่ไม่ซ้ำกัน ให้ใช้ชุด (sets) เพื่อหลีกเลี่ยงข้อมูลซ้ำซ้อน
จัดการประเภทที่ซับซ้อน เช่น วันที่หรือตำแหน่งทางภูมิศาสตร์ Faker รองรับสิ่งเหล่านี้โดยธรรมชาติ
สำหรับประสิทธิภาพ Claude สามารถแนะนำการประมวลผลแบบหลายโปรเซส (multiprocessing) สำหรับการสร้างข้อมูลขนาดใหญ่
Mock Data Generator แบบกำหนดเองนี้จะพัฒนาไปพร้อมกับความต้องการของโปรเจกต์ เมื่อรวมกับ Apidog จะช่วยขับเคลื่อนการตอบกลับของ API
การรวมข้อมูลจำลองเข้ากับ Apidog สำหรับการจำลอง API
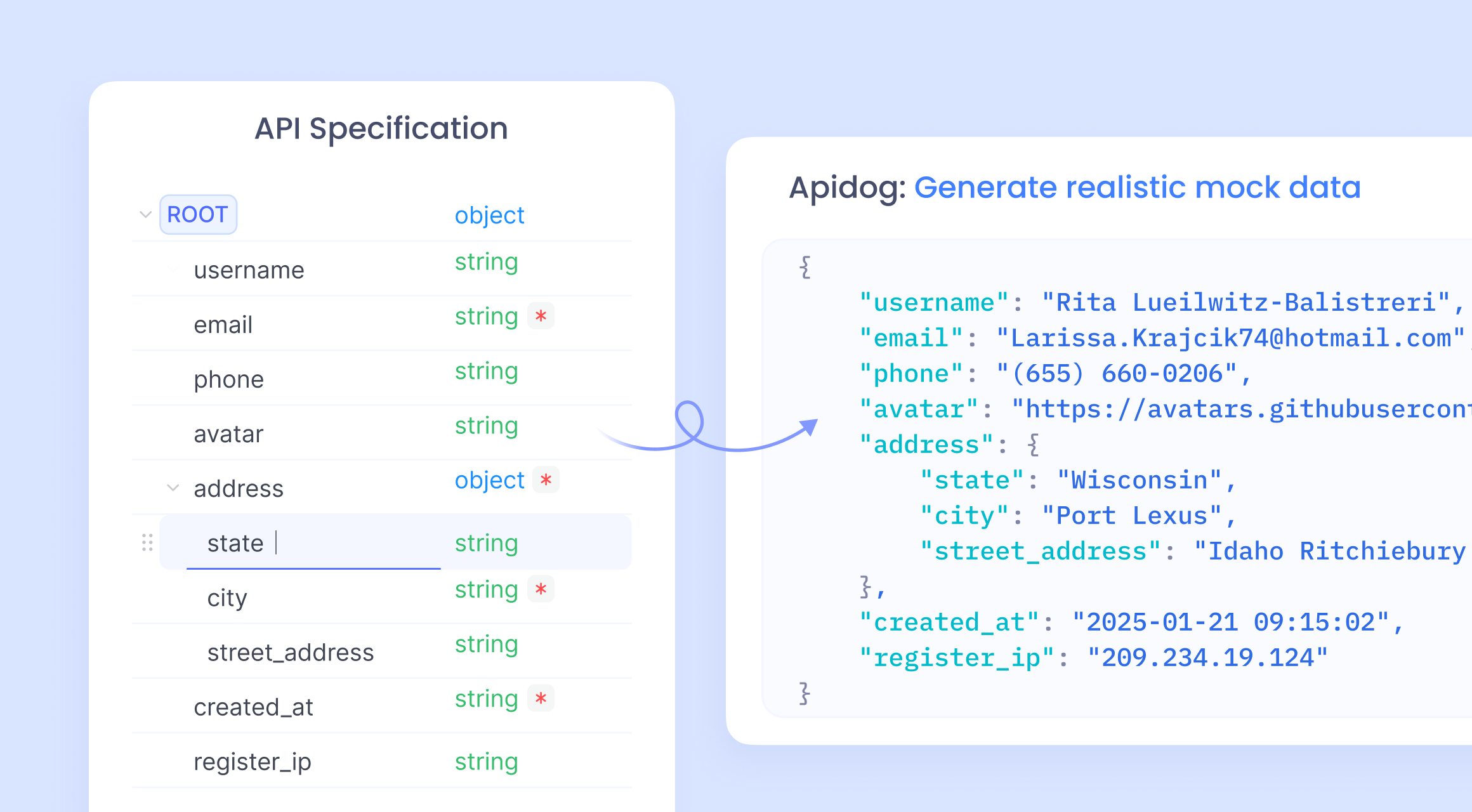
Apidog กลายเป็นพันธมิตรที่ทรงพลังในการพัฒนา API มี การจำลอง API แบบไม่ต้องใช้โค้ด โดยสร้างการตอบกลับตามข้อมูลจำเพาะของ OpenAPI นักพัฒนานำเข้าสคีมา และฟีเจอร์สมาร์ทม็อกของ Apidog จะสร้างข้อมูลโดยอัตโนมัติ
ในการรวมโค้ด Claude เข้ากับ Apidog ให้สร้างสคริปต์ข้อมูลจำลองที่ป้อนเข้าสู่กฎที่กำหนดเองของ Apidog Apidog อนุญาตให้มีการจำลองขั้นสูงด้วยนิพจน์ JavaScript
ขั้นแรก สร้าง API ใน Apidog กำหนดเอนด์พอยต์และการตอบกลับ จากนั้นใช้ Claude เพื่อเขียนโค้ดสั้นๆ สำหรับข้อมูลไดนามิก
วาง URL นี้ในเบราว์เซอร์ของคุณเพื่อรับข้อมูลจำลอง การรีเฟรชจะอัปเดตข้อมูล
Apidog ทำให้สิ่งนี้ง่ายขึ้น: ตั้งค่าการจำลองในสามขั้นตอน – นำเข้าข้อมูลจำเพาะ, กำหนดค่ากฎ, ปรับใช้เซิร์ฟเวอร์จำลอง สิ่งนี้ช่วยลดการเขียนโค้ดสำหรับกรณีพื้นฐาน
อย่างไรก็ตาม สำหรับตรรกะที่ซับซ้อน โค้ด Claude ช่วยเสริม Apidog สร้างโค้ดที่จัดการการตอบกลับแบบมีเงื่อนไขตามพารามิเตอร์การสืบค้น (query params)
ประโยชน์ที่ได้รับรวมถึงการสร้างต้นแบบที่เร็วขึ้นและการทำงานร่วมกันเป็นทีม แพลตฟอร์มแบบครบวงจรของ Apidog ครอบคลุมการออกแบบ การทดสอบ และการจำลอง
สมาร์ทม็อก
Apidog รองรับการจำลองข้อมูลโดยตรงตามข้อมูลจำเพาะของ API โดยไม่ต้องมีการกำหนดค่าเพิ่มเติม สิ่งนี้เรียกว่า สมาร์ทม็อก (Smart mock) ข้อมูลสมาร์ทม็อกมาจากสามแหล่ง:
ก) นิพจน์จำลองที่สอดคล้องกับชื่อคุณสมบัติ
ข) ฟิลด์จำลองในคุณสมบัติของข้อมูลจำเพาะการตอบกลับ
ค) JSON Schema ในข้อมูลจำเพาะการตอบกลับ
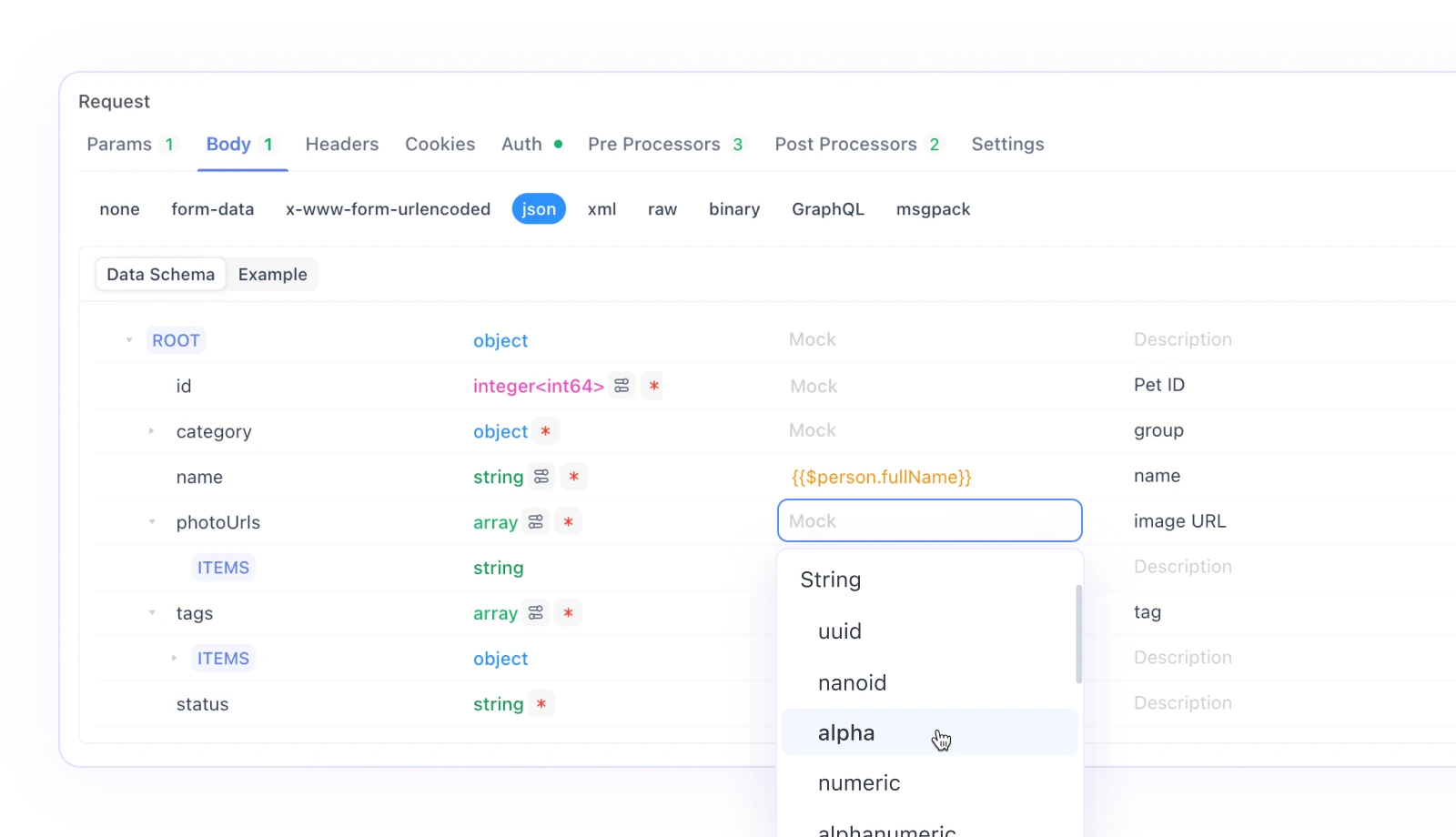
การจำลองอัตโนมัติตามชื่ออัลกอริทึมหลักของสมาร์ทม็อกจะจับคู่ข้อมูลจำลองโดยอัตโนมัติตามประเภทและชื่อของคุณสมบัติ Apidog มีชุดกฎการจับคู่ในตัว หากประเภทและชื่อตรงกับกฎ ข้อมูลจะถูกจำลองตามกฎนั้น คุณสามารถดูกฎในตัวเหล่านี้ได้ที่ การตั้งค่า - การตั้งค่าทั่วไป - การตั้งค่าคุณสมบัติ - การตั้งค่าการจำลอง กฎในตัวใช้เมธอด Wildcard หรือ RegEx เพื่อจับคู่สตริงชื่อ
หากกฎในตัวไม่เพียงพอ คุณสามารถสร้างกฎการจับคู่แบบกำหนดเองได้ คลิก ใหม่ เพื่อสร้างกฎการจับคู่ใหม่ คุณสมบัติที่ตรงตามรายละเอียดเงื่อนไขจะสร้างข้อมูลตามนิพจน์จำลองที่ตั้งไว้
หากชื่อคุณสมบัติไม่ตรงกับกฎใดๆ ค่าจำลองเริ่มต้นจะถูกสร้างขึ้นตามประเภทของคุณสมบัติ
การจำลองตามฟิลด์จำลอง หากมีค่าในฟิลด์จำลองของคุณสมบัติในข้อมูลจำเพาะการตอบกลับ ค่านี้จะแทนที่ค่าจากการจำลองตามชื่อ
ในฟิลด์จำลองนี้ คุณสามารถกรอกค่าคงที่โดยตรงหรือเขียนคำสั่ง Faker ได้
แนวปฏิบัติที่ดีที่สุดสำหรับการสร้างข้อมูลจำลองโดยใช้โค้ด Claude
- รักษาความสมจริง กำหนดค่า Faker locales สำหรับข้อมูลเฉพาะภูมิภาค
- จัดทำเอกสารพรอมต์ Claude ของคุณ สิ่งนี้ช่วยในการทำซ้ำได้
- จัดการกรณีพิเศษ (edge cases) กระตุ้นให้ Claude รวมข้อมูลที่ผิดปกติ เช่น อีเมลที่ไม่ถูกต้อง
- รักษาความปลอดภัยของการจำลองที่ละเอียดอ่อน หลีกเลี่ยงการเลียนแบบ PII จริง
- ปรับให้เหมาะสมสำหรับขนาด ทดสอบโค้ดด้วยอินพุตขนาดใหญ่
- อัปเดตไลบรารีเป็นประจำ Faker เวอร์ชันใหม่จะเพิ่มคุณสมบัติใหม่ๆ
- รวมวงจรการตอบรับ (feedback loops) ปรับปรุงโค้ด Claude ตามผลการทดสอบ
- เมื่อใช้ Apidog ให้ปรับกฎการจำลองให้สอดคล้องกับข้อมูลที่สร้างโดยโค้ดเพื่อความสอดคล้องกัน
แนวทางปฏิบัติเหล่านี้ช่วยป้องกันปัญหาทั่วไป ซึ่งช่วยเพิ่มความน่าเชื่อถือ
ข้อผิดพลาดทั่วไปและวิธีหลีกเลี่ยง
บางครั้งนักพัฒนามองข้ามความหลากหลายของข้อมูล ซึ่งนำไปสู่การทดสอบที่มีอคติ แก้ไขสิ่งนี้โดยการเปลี่ยนค่า seed ในโค้ด Claude
ข้อผิดพลาดอีกประการหนึ่งคือการพึ่งพาค่าเริ่มต้นมากเกินไป ปรับแต่งพรอมต์สำหรับโดเมนเฉพาะ
คอขวดด้านประสิทธิภาพเกิดขึ้นได้จากลูปที่ไม่มีประสิทธิภาพ Claude สามารถปรับให้เหมาะสมด้วยการดำเนินการแบบเวกเตอร์โดยใช้ numpy
การละเลยการทดสอบการรวมระบบอาจเป็นอันตรายได้ ควรจำลองทั้งระบบเสมอ
ใน Apidog กฎที่กำหนดค่าไม่ถูกต้องทำให้เกิดความไม่ตรงกัน ตรวจสอบข้อมูลจำเพาะซ้ำ การคาดการณ์ข้อผิดพลาดจะช่วยลดความเสี่ยงได้
เครื่องมือและไลบรารีที่เสริมโค้ด Claude
นอกเหนือจาก Faker แล้ว ลองสำรวจไลบรารีอย่าง Mimesis สำหรับข้อมูลหลายภาษา
สำหรับฐานข้อมูล ให้ใช้ SQLAlchemy กับโค้ด Claude เพื่อเติมข้อมูลลงในฐานข้อมูลจำลอง
ใน JavaScript, Chance.js มีทางเลือกอื่นให้เลือก
Apidog ผสานรวมกับ Postman collections ซึ่งช่วยขยายทางเลือกต่างๆ
เลือกตามโครงสร้างโปรเจกต์
การขยายขนาดการสร้างข้อมูลจำลองสำหรับความต้องการขององค์กร
องค์กรต้องการชุดข้อมูลขนาดใหญ่ Claude สามารถสร้างโค้ดโดยใช้การประมวลผลแบบกระจาย (distributed computing) เช่น Dask
ใช้การแคชสำหรับการสร้างซ้ำ
ตรวจสอบการใช้ทรัพยากร
Apidog ขยายขนาดการจำลองผ่านการปรับใช้บนคลาวด์
สิ่งนี้รับประกันความทนทาน
ข้อควรพิจารณาด้านความปลอดภัยในข้อมูลจำลอง
ป้องกันการรั่วไหลของข้อมูลโดยใช้เฉพาะข้อมูลสังเคราะห์
Claude ยึดมั่นในความปลอดภัย หลีกเลี่ยงโค้ดที่เป็นอันตราย
ใน Apidog รักษาความปลอดภัยเซิร์ฟเวอร์จำลองด้วยการรับรองความถูกต้อง การปฏิบัติตาม GDPR ต้องการการจัดการอย่างระมัดระวัง
บทสรุป
การสร้างข้อมูลจำลองโดยใช้โค้ด Claude เปลี่ยนแปลงแนวทางการพัฒนา ตั้งแต่พื้นฐานไปจนถึงการรวมระบบขั้นสูงกับ Apidog คู่มือนี้ให้ข้อมูลเชิงลึกที่ครอบคลุม นำเทคนิคเหล่านี้ไปใช้เพื่อปรับปรุงขั้นตอนการทำงานของคุณ
โปรดจำไว้ว่า การปรับเปลี่ยนเล็กน้อยในพรอมต์หรือการตั้งค่าจะนำไปสู่การปรับปรุงที่สำคัญ ทดลองและปรับปรุงให้ดีขึ้น
สำหรับการ จำลอง API ที่ดียิ่งขึ้น ดาวน์โหลด Apidog ฟรีและสำรวจความสามารถของมัน