
ในขณะที่ Google ค่อยๆ เปิดตัว Gemini 3.0 ผ่านการใช้งานแบบ shadow deployments และ preview endpoints นักพัฒนาจะได้รับโอกาสทดสอบความสามารถในการให้เหตุผลที่ได้รับการปรับปรุงและประสิทธิภาพแบบ multimodal ตั้งแต่เนิ่นๆ
นักวิจัยและวิศวกรของ Google DeepMind ได้วางตำแหน่ง Gemini 3.0 ให้เป็นตระกูลโมเดลที่มีความสามารถมากที่สุดของบริษัทจนถึงปัจจุบัน ยิ่งไปกว่านั้น ยังก้าวข้ามการอัปเดตแบบเพิ่มทีละน้อยด้วยการนำเสนอพฤติกรรมแบบ agentic ดั้งเดิมและการรวมเครื่องมือที่ลึกซึ้งยิ่งขึ้น
กำหนดการเปิดตัวและกลยุทธ์การใช้งาน Gemini 3.0
Google ใช้วิธีการปรับใช้แบบเป็นขั้นเป็นตอนสำหรับการอัปเกรดโมเดลหลัก ดังนั้น Gemini 3.0 จึงปรากฏขึ้นครั้งแรกในสภาพแวดล้อมที่ควบคุมโดยไม่มีการประกาศในงานเปิดตัวแบบดั้งเดิม
โมเดลนี้ปรากฏครั้งแรกใน AI Studio ภายใต้ตัวระบุ "gemini-3-pro-preview" ประมาณกลางเดือนพฤศจิกายน 2025 นอกจากนี้ สมาชิก Gemini Advanced ที่เลือกไว้บางรายได้รับแจ้งเตือนในแอปว่า "เราได้อัปเกรดคุณจากโมเดลก่อนหน้าเป็น 3.0 Pro ซึ่งเป็นโมเดลที่ฉลาดที่สุดของเรา" การเปิดตัวแบบ shadow นี้ช่วยให้ Google สามารถรวบรวมข้อมูล telemetry การใช้งานจริงได้ในขณะที่ยังคงความต่อเนื่องของอินเทอร์เฟซ
Vertex AI และบันทึกการเปลี่ยนแปลงของ Gemini API ตอนนี้แสดงรายการ preview endpoints เช่น gemini-3-pro-preview-11-2025 ยิ่งไปกว่านั้น ชื่อรหัสภายในอย่าง "lithiumflow" และ "orionmist" ที่ครองตารางผู้นำของ LM Arena ในเดือนตุลาคม 2025 ได้รับการยืนยันแล้วว่าเป็นจุดตรวจสอบแรกๆ ของ Gemini 3.0
Google DeepMind ได้เปิดเผยต่อสาธารณะเกี่ยวกับตระกูลโมเดลนี้ในกระทู้เมื่อเดือนพฤศจิกายน 2025 โดยอธิบายว่า Gemini 3 มอบ "ความสามารถในการให้เหตุผลที่ล้ำสมัย ความเข้าใจแบบ multimodal ชั้นนำระดับโลก และประสบการณ์การเขียนโค้ดแบบ agentic ใหม่ๆ" การเปิดตัวเวอร์ชันเสถียรเต็มรูปแบบ รวมถึงการพร้อมใช้งาน Gemini 3 API ที่กว้างขึ้น คาดว่าจะเกิดขึ้นก่อนสิ้นปี 2025
ความก้าวหน้าทางสถาปัตยกรรมหลักใน Gemini 3.0
Gemini 3.0 สร้างขึ้นบนรากฐาน mixture-of-experts (MoE) ที่วางไว้ในรุ่นก่อนหน้า อย่างไรก็ตาม มันได้รวมการปรับปรุงที่สำคัญหลายอย่างที่ส่งผลกระทบโดยตรงต่อคุณภาพและประสิทธิภาพของการอนุมาน
ประการแรก โมเดลได้ขยายการรองรับ context window เกินกว่า 2 ล้านโทเค็นที่มีอยู่ใน Gemini 2.5 Pro โดยอินสแตนซ์พรีวิวสามารถจัดการเซสชันที่ยาวนานขึ้นได้อย่างสอดคล้องกัน ประการที่สอง การฝึกบนชุดข้อมูล multimodal ที่ใหญ่ขึ้นอย่างมากช่วยปรับปรุงการจัดเรียงข้ามโมดอล (cross-modal alignment) – ตอนนี้โมเดลสามารถประมวลผลข้อความ โค้ด รูปภาพ และข้อมูลที่มีโครงสร้างที่ปะปนกันได้โดยลดการสูญเสียของโมดอลลง
นักวิจัยได้แนะนำกลไกความสนใจที่ละเอียดขึ้นซึ่งให้ความสำคัญกับความสัมพันธ์ระยะไกลในระหว่างกระบวนการให้เหตุผล ผลที่ได้คือ Gemini 3.0 แสดงปัญหา context drift น้อยลงในการโต้ตอบแบบหลายรอบที่เกิน 100 การแลกเปลี่ยน
ตระกูลนี้ประกอบด้วยอย่างน้อยสองเวอร์ชันหลักในพรีวิว:
- Gemini 3.0 Pro: โมเดลเรือธงที่ปรับแต่งเพื่อความฉลาดสูงสุดและการแก้ปัญหาที่ซับซ้อน
- Gemini 3.0 Flash: เวอร์ชันที่ลดขนาดและเน้นความหน่วงต่ำ ซึ่งยังคงความสามารถสูงไว้ในขณะที่สามารถตอบสนองได้ภายในเวลาน้อยกว่าหนึ่งวินาทีบนโครงสร้างพื้นฐาน TPU
การทดสอบเบื้องต้นเผยให้เห็นว่า Pro ทำงานที่อุณหภูมิ (temperature) 1.0 โดยค่าเริ่มต้น พร้อมคำเตือนในเอกสารว่าค่าที่ต่ำกว่าอาจลดประสิทธิภาพของ chain-of-thought ซึ่งแตกต่างจากโมเดลก่อนหน้าซึ่งค่าอุณหภูมิ 0.7 มักให้ผลลัพธ์ที่ดีที่สุด
ความสามารถในการทำความเข้าใจและการสร้างแบบ Multimodal
Gemini 3.0 เสริมสร้างความสามารถในการประมวลผลแบบ multimodal ดั้งเดิมอย่างมีนัยสำคัญ วิศวกรได้ฝึกโมเดลแบบ end-to-end บนข้อมูลหลากหลายประเภท ทำให้สามารถให้เหตุผลได้ทั้งภาพ เสียง และข้อความโดยไม่ต้องใช้ตัวเข้ารหัสแยกต่างหาก
ตัวอย่างเช่น โมเดลวิเคราะห์ภาพหน้าจอของอินเทอร์เฟซผู้ใช้ ดึงข้อมูลข้อกำหนดการทำงาน และสร้างโค้ด React หรือ Flutter ที่สมบูรณ์พร้อมแอนิเมชันที่ฝังอยู่ในการประมวลผลครั้งเดียว นอกจากนี้ยังตีความแผนภาพทางวิทยาศาสตร์ ได้สมการพื้นฐาน และจำลองผลลัพธ์โดยใช้ความรู้ทางฟิสิกส์ที่มีอยู่
ผู้ใช้พรีวิวรายงานประสิทธิภาพที่ก้าวหน้าในงานการให้เหตุผลด้วยภาพ:
- การตีความแผนภูมิที่ซับซ้อนซึ่งมีคำอธิบายประกอบซ้อนทับได้อย่างถูกต้อง
- การสร้างโค้ด SVG ที่เป็นไปตามข้อจำกัดทางคณิตศาสตร์ (เช่น วงกลมที่สมบูรณ์ การปรับสัดส่วน)
- การสร้างประสบการณ์ Canvas แบบโต้ตอบที่รวมข้อความธรรมดา การประมวลผลโค้ด และผลลัพธ์ภาพ
ยิ่งไปกว่านั้น ส่วนเสริม agentic ช่วยให้โมเดลสามารถจัดลำดับการเรียกใช้เครื่องมือได้โดยอิสระ นักพัฒนาสังเกตว่า Gemini 3.0 Pro สามารถวางแผนการโต้ตอบกับเบราว์เซอร์หลายขั้นตอนหรือลำดับ API ได้โดยไม่ต้องมีการแจ้งเตือนที่ชัดเจน ซึ่งเป็นความสามารถที่เคยจำกัดอยู่ในโหมดทดลองเท่านั้น
การปรับปรุงความสามารถในการให้เหตุผลและพฤติกรรมแบบ Agentic
Google เน้นย้ำ "Deep Think" ว่าเป็นกระบวนทัศน์หลักใน Gemini 3.0 โมเดลนี้จะแยกย่อยปัญหาออกเป็นปัญหาย่อยๆ ประเมินเส้นทางแก้ไขหลายเส้นทาง และแก้ไขตัวเองก่อนที่จะให้ผลลัพธ์สุดท้าย
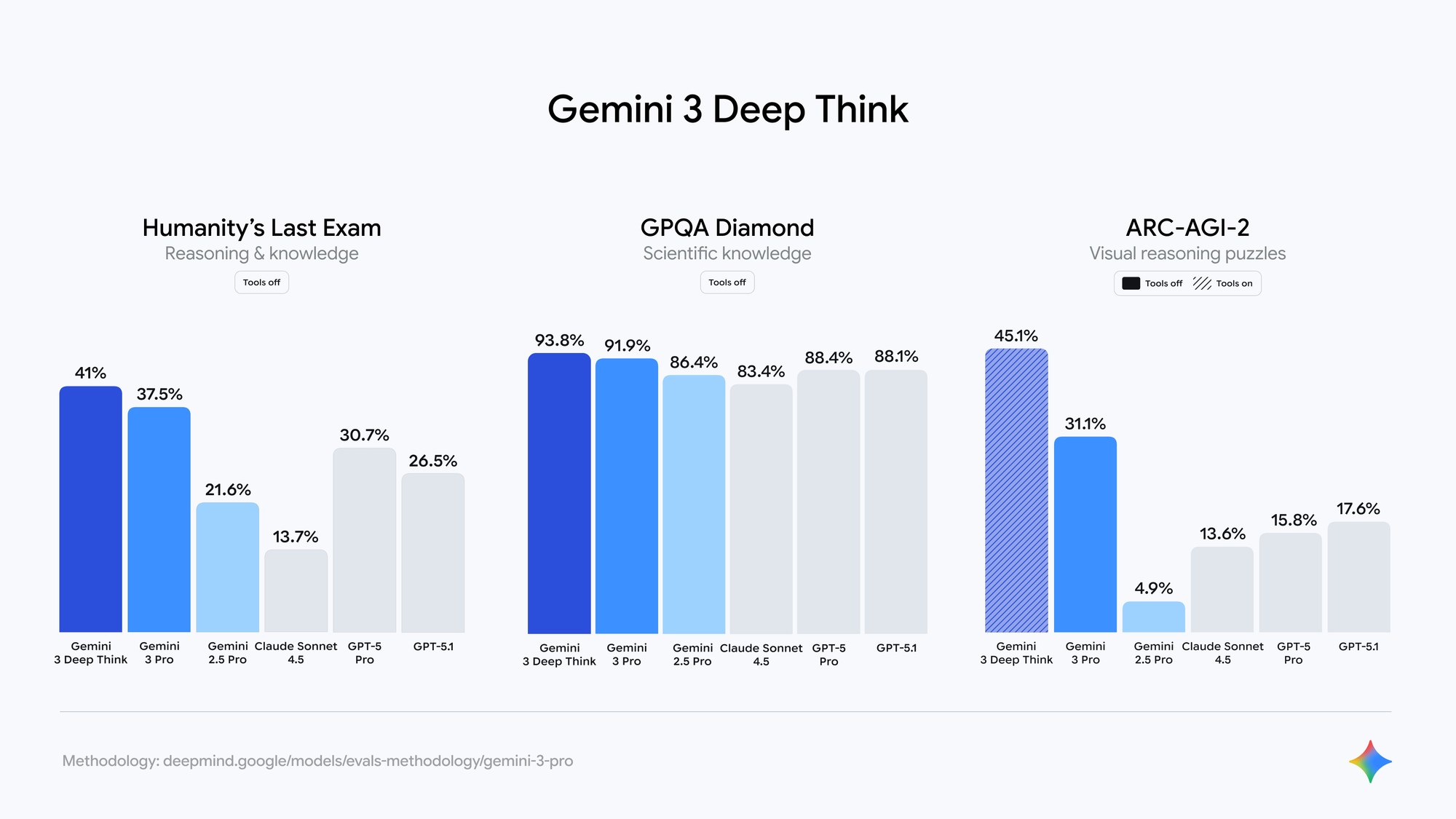
การประเมินอิสระบนจุดตรวจสอบ LM Arena ที่ปิดแล้ว (ซึ่งได้รับการยอมรับอย่างกว้างขวางว่าเป็นเวอร์ชันของ Gemini 3.0) แสดงให้เห็นว่า:
- คะแนน SimpleBench เข้าใกล้ 90–100% (เทียบกับ 62.4% สำหรับ Gemini 2.5 Pro)
- มีคะแนนเพิ่มขึ้นอย่างมากใน GPQA Diamond, AIME 2024 และ SWE-bench Verified
- ความสอดคล้องของข้อเท็จจริงที่ดีขึ้นในการสร้างเนื้อหายาวๆ
นอกจากนี้ โมเดลยังแสดงความสามารถในการวางแผนที่เกิดขึ้นใหม่ เมื่อได้รับมอบหมายให้ออกแบบระบบ มันสามารถสร้างแผนภาพสถาปัตยกรรมที่สมบูรณ์ สัญญา API และสคริปต์การปรับใช้ พร้อมทั้งคาดการณ์กรณีพิเศษได้
การเข้าถึง Gemini 3 API ในช่วงพรีวิว
ปัจจุบันนักพัฒนาเข้าถึง Gemini 3.0 ผ่าน Gemini API preview endpoints Google รักษาความเข้ากันได้แบบย้อนหลังกับ SDK ที่มีอยู่ โดยต้องอัปเดตเพียงชื่อโมเดลเท่านั้น
การเปลี่ยนแปลงที่สำคัญของ endpoint ได้แก่:
# โค้ด Gemini 2.5 เดิมยังคงใช้งานได้
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
# สลับไปใช้โมเดลพรีวิว
model = genai.GenerativeModel("gemini-3-pro-preview-11-2025")
response = model.generate_content(
"Explain quantum entanglement with a working Python simulation",
generation_config=genai.types.GenerationConfig(
temperature=1.0,
max_output_tokens=8192
)
)
Gemini 3 API รองรับการตั้งค่าความปลอดภัย, การเรียกใช้ฟังก์ชัน และคุณสมบัติการอ้างอิงข้อมูลพื้นฐาน (grounding) เหมือนกับเวอร์ชันก่อนหน้า อย่างไรก็ตาม โควตาพรีวิวยังคงจำกัด และมีข้อจำกัดด้านอัตราการเรียกใช้ (rate limits) สำหรับแต่ละโปรเจกต์
สำหรับการทดสอบระดับ production เครื่องมืออย่าง Apidog มีคุณค่าอย่างยิ่ง Apidog จะนำเข้าข้อกำหนด OpenAPI ของ Gemini โดยอัตโนมัติ เปิดใช้งานการจำลองคำขอสำหรับการพัฒนาแบบออฟไลน์ และให้การตรวจสอบการตอบกลับโดยละเอียด – ซึ่งจำเป็นอย่างยิ่งเมื่อทดลองใช้พฤติกรรมการให้เหตุผลใหม่ๆ ที่สามารถสร้างผลลัพธ์ที่มีความยาวแตกต่างกันไป
ประสิทธิภาพการวัดเทียบและตำแหน่งในการแข่งขัน
แม้ว่า Google ยังไม่ได้เผยแพร่เอกสารอย่างเป็นทางการ แต่ผลลัพธ์ที่ได้รับการยืนยันจากชุมชนจากการเข้าถึงพรีวิวและการใช้งานแบบ shadow deployments บ่งชี้ว่า Gemini 3.0 Pro เป็นผู้นำโมเดลสาธารณะในปัจจุบันในหลายด้าน:
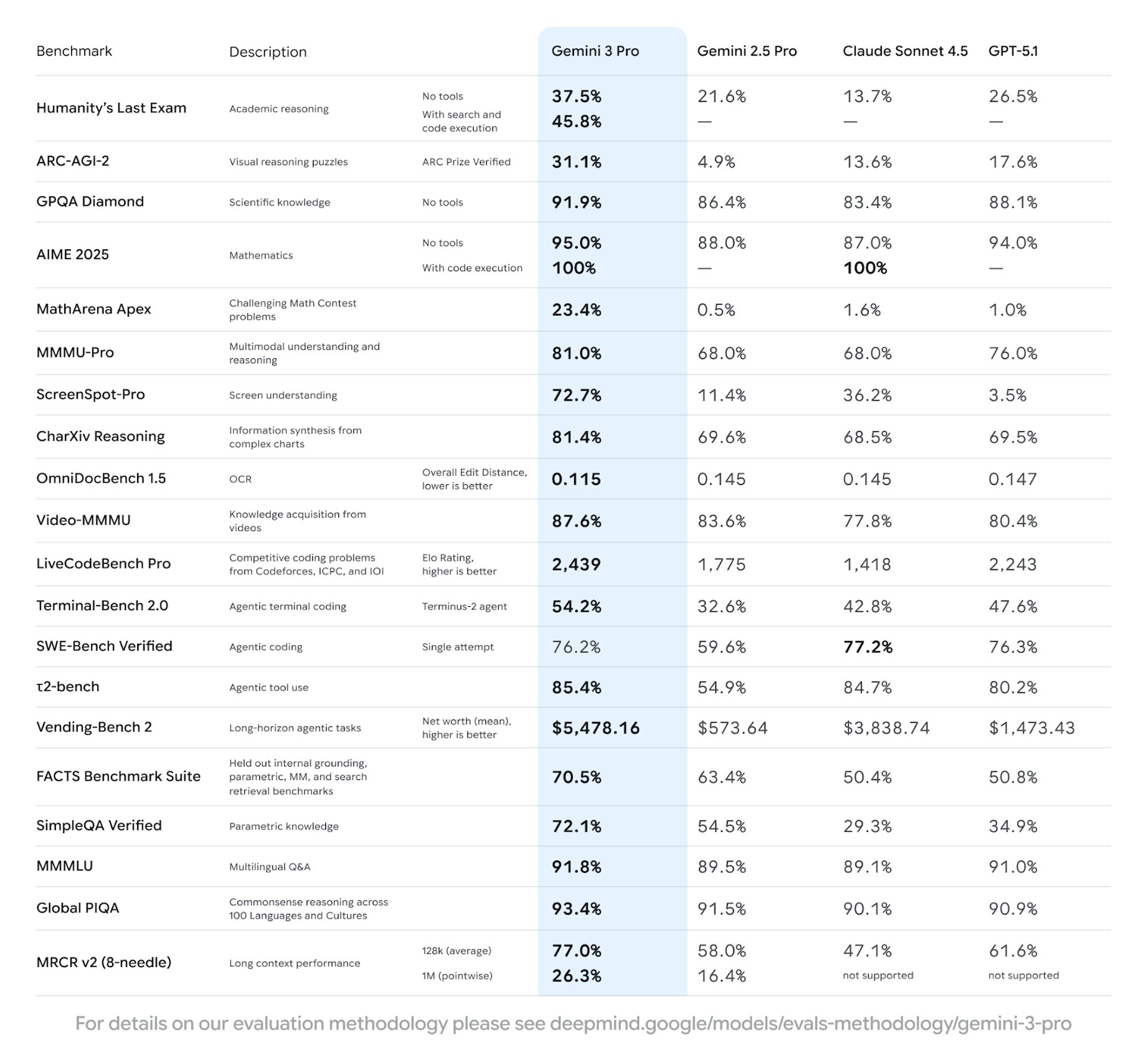
ตัวเลขเหล่านี้ทำให้ Gemini 3.0 อยู่เหนือ Claude 4 Opus และ GPT-4.1 รุ่นปัจจุบันในด้านความหนาแน่นของการให้เหตุผลและคุณภาพโค้ด
รูปแบบการรวมระบบเชิงปฏิบัติกับ Gemini 3 API
การนำไปใช้ที่ประสบความสำเร็จต้องอาศัยความเข้าใจในลักษณะพฤติกรรมใหม่ๆ นักพัฒนาจะต้องคำนึงถึงเวลาคิดที่นานขึ้นสำหรับ prompt ที่ซับซ้อน – โมเดลมักจะใช้โทเค็นเพิ่มเติมในการพิจารณาภายในก่อนที่จะตอบกลับ
แนวทางปฏิบัติที่ดีที่สุดที่ได้จากการใช้งานพรีวิว:
- ตั้งค่า temperature เป็น 1.0 สำหรับงานที่เน้นการให้เหตุผล
- ใช้คำสั่งระบบเพื่อบังคับให้ได้ผลลัพธ์ที่มีโครงสร้าง (JSON, YAML)
- ใช้ประโยชน์จาก context ที่ขยายใหญ่ขึ้นสำหรับการอัปโหลด codebase ทั้งหมด
- เชื่อมโยงการเรียกใช้เครื่องมืออย่างชัดเจนเมื่อต้องการพฤติกรรมที่กำหนดได้ (deterministic behavior)
นอกจากนี้ ให้รวม Gemini 3 API เข้ากับเลเยอร์การจัดเตรียมภายนอก (external orchestration layers) เพื่อให้ได้ agent loops ที่เชื่อถือได้ Apidog โดดเด่นในด้านนี้ด้วยการนำเสนอคอลเลกชันเฉพาะสภาพแวดล้อมที่สลับไปมาระหว่าง gemini-2.5-pro และ gemini-3-pro-preview endpoints ได้อย่างราบรื่น
ข้อจำกัดและปัญหาที่ทราบในการพรีวิว
บิลด์พรีวิวแสดงความไม่เสถียรเป็นครั้งคราว ผู้ใช้พบปัญหา context loss ในเซสชันที่ยาวมาก (>150k โทเค็น) และการ hallucination ที่หายากในโดเมนเฉพาะทาง ยิ่งไปกว่านั้น การสร้างภาพยังคงผูกติดกับ Imagen/Nano Banana endpoints แยกต่างหากแทนที่จะเป็นการรวมระบบแบบ native
Google ทำการปรับปรุงอย่างต่อเนื่องตามข้อมูล telemetry ปัญหาที่รายงานส่วนใหญ่ได้รับการแก้ไขภายในไม่กี่วันหลังจากค้นพบ ซึ่งสะท้อนให้เห็นถึงข้อดีของการใช้งานแบบ shadow deployment
แนวโน้มในอนาคตและผลกระทบต่อระบบนิเวศ
Gemini 3.0 กำหนดมาตรฐานใหม่สำหรับ multimodal agents เมื่อ Gemini 3 API เข้าสู่สถานะเสถียร คาดว่าจะมีการรวมระบบอย่างรวดเร็วทั่วทั้ง Google Workspace, Android และ Vertex AI agents
องค์กรจะได้รับประโยชน์จากอินสแตนซ์ส่วนตัวที่มีการจัดเรียงเฉพาะ (custom alignment) ในขณะที่นักพัฒนาสามารถเข้าถึงความลึกของการให้เหตุผลที่ก่อนหน้านี้ต้องใช้การเรียกโมเดลหลายครั้ง
การผสมผสานระหว่างความฉลาดที่แท้จริง ความเข้าใจเครื่องมือแบบ native และการปรับใช้ที่มีประสิทธิภาพ ทำให้ Gemini 3.0 เป็นรากฐานสำหรับแอปพลิเคชัน AI ยุคหน้า
นักพัฒนาที่พร้อมจะทดลองกับความสามารถเหล่านี้ควรเริ่มย้ายชุดทดสอบไปยัง Gemini 3 API พรีวิวทันที เครื่องมืออย่าง Apidog ช่วยลดความยุ่งยากระหว่างการเปลี่ยนผ่านนี้ได้อย่างมากด้วยการนำเสนอการสลับ endpoint เพียงคลิกเดียวและการดีบักที่ครอบคลุม
การเปิดตัวอย่างรอบคอบของ Google แสดงให้เห็นถึงความพร้อมในการปรับใช้โมเดลขนาดใหญ่ ดังนั้น เมื่อ Gemini 3.0 พร้อมใช้งานทั่วไป ระบบนิเวศจะพร้อมสำหรับการใช้งานจริงได้ทันที