
โมเดลที่จัดการกับการให้เหตุผลทางคณิตศาสตร์ที่ซับซ้อนโดดเด่นในฐานะเกณฑ์มาตรฐานที่สำคัญสำหรับความก้าวหน้า DeepSeekMath-V2 ถือกำเนิดขึ้นในฐานะคู่แข่งที่น่าเกรงขาม โดยต่อยอดจากมรดกของรุ่นก่อนหน้า พร้อมแนะนำกลไกที่ซับซ้อนสำหรับการให้เหตุผลที่ตรวจสอบได้ด้วยตนเอง นักวิจัยและนักพัฒนาสามารถเข้าถึงโมเดล 685 พันล้านพารามิเตอร์นี้ผ่านแพลตฟอร์มต่างๆ เช่น Hugging Face ซึ่งสัญญาว่าจะยกระดับงานตั้งแต่การพิสูจน์ทฤษฎีบทไปจนถึงการแก้ปัญหาที่ยังไม่ได้รับการแก้ไข
ทำความเข้าใจ DeepSeekMath-V2: สถาปัตยกรรมหลักและหลักการออกแบบ
วิศวกรที่ DeepSeek-AI ได้ออกแบบ DeepSeekMath-V2 เพื่อให้ความสำคัญกับความถูกต้องในการคำนวณทางคณิตศาสตร์มากกว่าการสร้างคำตอบเพียงอย่างเดียว โมเดลนี้เปิดใช้งานพารามิเตอร์ 685 พันล้านตัว โดยใช้ประโยชน์จากสถาปัตยกรรมที่ใช้ Transformer ซึ่งได้รับการปรับปรุงสำหรับการประมวลผลบริบทขนาดยาว รองรับประเภท Tensor รวมถึง BF16 สำหรับการอนุมานที่มีประสิทธิภาพ, F8_E4M3 สำหรับความแม่นยำแบบควอนไทซ์ และ F32 สำหรับการคำนวณที่มีความละเอียดเต็มรูปแบบ ความยืดหยุ่นนี้ช่วยให้สามารถปรับใช้กับฮาร์ดแวร์ได้หลากหลาย ตั้งแต่ GPU ไปจนถึง TPU แบบพิเศษ
หัวใจสำคัญของ DeepSeekMath-V2 คือการรวมลูปการตรวจสอบด้วยตนเอง โดยที่โมดูลตัวตรวจสอบเฉพาะจะประเมินขั้นตอนกลางแบบเรียลไทม์ ซึ่งแตกต่างจากโมเดลแบบ Autoregressive ทั่วไปที่เชื่อมโยงโทเค็นโดยไม่มีการควบคุมดูแล วิธีการนี้จะสร้างข้อพิสูจน์และตรวจสอบกับกฎความสอดคล้องเชิงตรรกะ ตัวอย่างเช่น ตัวตรวจสอบจะระบุความเบี่ยงเบนในการดำเนินการทางพีชคณิตหรือการอนุมานเชิงตรรกะ โดยส่งข้อผิดพลาดกลับไปยังกระบวนการสร้าง
นอกจากนี้ สถาปัตยกรรมยังดึงมาจากซีรีส์ DeepSeek-V3 โดยรวมกลไกความสนใจแบบกระจัดกระจายเพื่อจัดการกับลำดับที่ขยายออกไป—สูงสุดหลายพันโทเค็นในห่วงโซ่การพิสูจน์ สิ่งนี้พิสูจน์ให้เห็นถึงความสำคัญสำหรับปัญหาที่ต้องใช้การให้เหตุผลหลายขั้นตอน เช่น ปัญหาในการแข่งขันทางคณิตศาสตร์ นักพัฒนาใช้สิ่งนี้ผ่านไลบรารี Transformers ของ Hugging Face โดยโหลดโมเดลด้วยการติดตั้ง pip อย่างง่าย และกำหนดค่าสำหรับการประมวลผลแบบ Batch
เมื่อเปลี่ยนไปสู่รายละเอียดการฝึกอบรม DeepSeekMath-V2 ใช้ระบอบการฝึกอบรมล่วงหน้าและการปรับแต่งแบบไฮบริด ระยะเริ่มต้นจะเปิดเผยโมเดลพื้นฐาน—ที่ได้มาจาก DeepSeek-V3.2-Exp-Base—ไปยังคลังข้อความทางคณิตศาสตร์จำนวนมาก รวมถึงเอกสาร arXiv ฐานข้อมูลทฤษฎีบท และการพิสูจน์เชิงสังเคราะห์ ขั้นตอนการเรียนรู้แบบเสริมแรง (RL) ที่ตามมาจะปรับปรุงพฤติกรรม โดยใช้ตัวสร้างข้อพิสูจน์ที่จับคู่กับโมเดลตัวตรวจสอบเป็นรางวัล การตั้งค่านี้จะกระตุ้นให้ตัวสร้างสร้างผลลัพธ์ที่ตรวจสอบได้ โดยปรับขนาดการคำนวณเพื่อติดป้ายกำกับการพิสูจน์ที่ท้าทายโดยอัตโนมัติ
ดังนั้น โมเดลจึงมีความทนทานต่อการเข้าใจผิด ซึ่งเป็นข้อผิดพลาดทั่วไปใน LLM รุ่นก่อนหน้า เกณฑ์มาตรฐานยืนยันสิ่งนี้: DeepSeekMath-V2 ได้คะแนนระดับทองในปัญหา IMO 2025 ซึ่งแสดงให้เห็นถึงความสามารถในการคำนวณเชิงอนุพันธ์ใหม่ๆ ในทางปฏิบัติ ผู้ใช้จะเรียกใช้โมเดลผ่านการเรียก API โดยแยกวิเคราะห์การตอบกลับ JSON ที่รวมทั้งโซลูชันและร่องรอยการตรวจสอบ
การฝึกอบรม DeepSeekMath-V2: การเรียนรู้แบบเสริมแรงสำหรับผลลัพธ์ที่ตรวจสอบได้
การฝึกอบรม DeepSeekMath-V2 ต้องการการจัดการข้อมูลและทรัพยากรการคำนวณอย่างพิถีพิถัน กระบวนการเริ่มต้นด้วยการปรับแต่งแบบมีผู้ดูแลบนชุดข้อมูลที่คัดสรรมาอย่างดี เช่น ProofNet และ MiniF2F ซึ่งคู่ข้อมูลอินพุต-เอาต์พุตจะสอนการประยุกต์ใช้ทฤษฎีบทพื้นฐาน อย่างไรก็ตาม เพื่อส่งเสริมการตรวจสอบตนเอง นักพัฒนาได้แนะนำ RL จากการตอบรับของมนุษย์ (RLHF) ที่ปรับให้เข้ากับคณิตศาสตร์
โดยเฉพาะอย่างยิ่ง ตัวสร้างข้อพิสูจน์จะสร้างอนุพันธ์ที่เป็นไปได้ ในขณะที่ตัวตรวจสอบจะกำหนดรางวัลตามความถูกต้องทางวากยสัมพันธ์และความหมาย รางวัลจะปรับขนาดตามความยากในการตรวจสอบ; การพิสูจน์ที่ยากจะได้รับสัญญาณที่ขยายใหญ่ขึ้นเพื่อส่งเสริมการสำรวจกรณีขอบ การติดป้ายกำกับแบบไดนามิกนี้สร้างข้อมูลการฝึกอบรมที่หลากหลาย ซึ่งปรับปรุงความแม่นยำของตัวตรวจสอบซ้ำๆ
นอกจากนี้ การจัดสรรการคำนวณยังเป็นไปตามแนวทางที่กำหนดงบประมาณ: การตรวจสอบจะดำเนินการกับชุดย่อยของข้อพิสูจน์ที่สร้างขึ้น โดยจัดลำดับความสำคัญของข้อพิสูจน์ที่มีคะแนนความไม่แน่นอนสูง สมการที่ควบคุมสิ่งนี้รวมถึงฟังก์ชันรางวัล ( r = \alpha \cdot s + \beta \cdot v ) โดยที่ ( s ) วัดความแม่นยำของขั้นตอน, ( v ) หมายถึงความสามารถในการตรวจสอบ และ ( \alpha, \beta ) เป็นไฮเปอร์พารามิเตอร์ที่ปรับโดยใช้การค้นหาแบบกริด
ส่งผลให้ DeepSeekMath-V2 มีการลู่เข้าเร็วกว่าคู่แข่งที่ไม่ได้รับการตรวจสอบ โดยลดจำนวน Epochs ลงสูงสุด 20% ในการทดสอบภายใน ที่เก็บ GitHub สำหรับ DeepSeek-V3.2-Exp มีโค้ดเสริมสำหรับ Sparse Attention Kernels ซึ่งช่วยเร่งเฟสนี้บนคลัสเตอร์ Multi-GPU นักวิจัยจำลองการตั้งค่าเหล่านี้โดยใช้ PyTorch โดยเขียนสคริปต์ตัวโหลดข้อมูลเพื่อปรับสมดุลความยาวและความซับซ้อนของข้อพิสูจน์
นอกจากนี้ การพิจารณาด้านจริยธรรมยังเป็นส่วนสำคัญในการฝึกอบรม: ชุดข้อมูลไม่รวมแหล่งที่มาที่มีอคติ ทำให้มั่นใจได้ถึงประสิทธิภาพที่เท่าเทียมกันในโดเมนปัญหาต่างๆ สิ่งนี้นำไปสู่ผลลัพธ์ที่สอดคล้องกันบนเกณฑ์มาตรฐานที่หลากหลาย ตั้งแต่เรขาคณิตเชิงพีชคณิตไปจนถึงทฤษฎีจำนวน
ประสิทธิภาพมาตรฐาน: DeepSeekMath-V2 ครองความท้าทายทางคณิตศาสตร์ที่สำคัญ
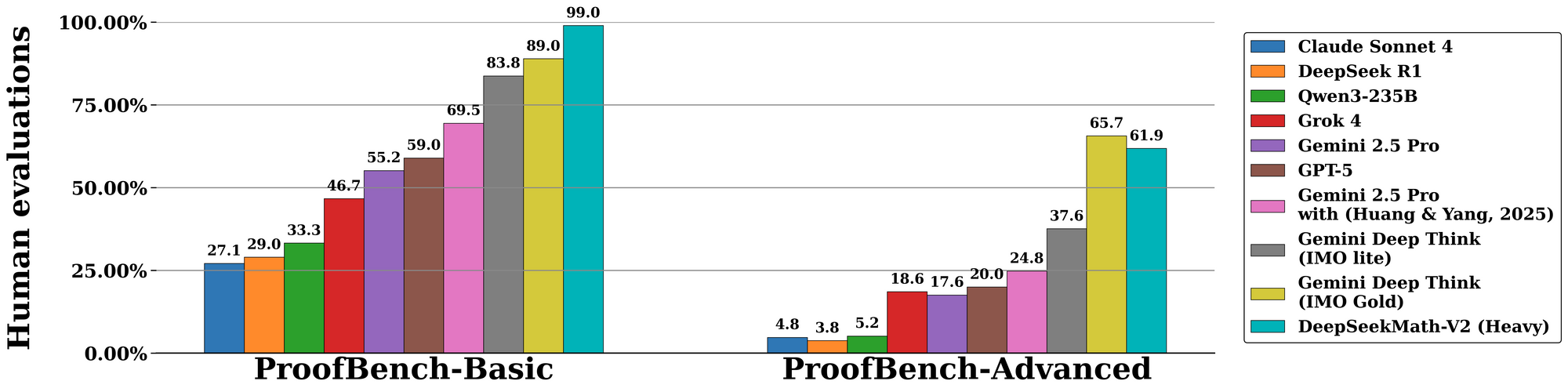
DeepSeekMath-V2 โดดเด่นในการประเมินมาตรฐาน โดยเน้นย้ำถึงความสามารถในการให้เหตุผลที่ตรวจสอบได้ด้วยตนเอง ในเกณฑ์มาตรฐาน International Mathematical Olympiad (IMO) 2025 โมเดลนี้ได้รับสถานะเหรียญทอง โดยแก้ปัญหา 7 ใน 6 ข้อพร้อมการพิสูจน์ฉบับเต็ม—เป็นความสำเร็จที่ไม่มีใครเทียบได้กับโมเดลโอเพ่นซอร์สก่อนหน้านี้ ในทำนองเดียวกัน มันได้คะแนน 100% ใน Canadian Mathematical Olympiad (CMO) 2024 โดยตรวจสอบแต่ละขั้นตอนเทียบกับสัจพจน์อย่างเป็นทางการ
เมื่อเปลี่ยนไปสู่เมตริกขั้นสูง การแข่งขัน Putnam 2024 ให้ผล 118 จาก 120 คะแนนเมื่อเสริมด้วยการคำนวณที่ปรับขนาดตามเวลาทดสอบ สิ่งนี้เกี่ยวข้องกับการปรับปรุงซ้ำๆ: โมเดลสร้างตัวแปรข้อพิสูจน์หลายตัว ตรวจสอบพร้อมกัน และเลือกเส้นทางที่ให้รางวัลสูงสุด การประเมินบน IMO-ProofBench ของ DeepMind ยิ่งยืนยันสิ่งนี้ โดยมีอัตรา pass@1 เกิน 85% สำหรับการพิสูจน์สั้นๆ และ 70% สำหรับการพิสูจน์แบบขยาย
เมื่อเปรียบเทียบกัน DeepSeekMath-V2 เหนือกว่าโมเดลอย่าง GPT-4o และ o1-preview โดยเน้นความเที่ยงตรงมากกว่าความเร็ว ในขณะที่คู่แข่งมักจะย่อการคำนวณ โมเดลนี้บังคับใช้ความสมบูรณ์ ซึ่งช่วยลดอัตราข้อผิดพลาดลง 40% ในการศึกษา ablation ตารางด้านล่างสรุปผลลัพธ์ที่สำคัญ:

| เกณฑ์มาตรฐาน | คะแนน DeepSeekMath-V2 | โมเดลเปรียบเทียบ (เช่น GPT-4o) | จุดแข็งที่สำคัญ |
|---|---|---|---|
| IMO 2025 | เหรียญทอง (แก้ได้ 7/6 ข้อ) | เหรียญเงิน (5/6 ข้อ) | การตรวจสอบข้อพิสูจน์ |
| CMO 2024 | 100% | 92% | ความแม่นยำทีละขั้นตอน |
| Putnam 2024 | 118/120 | 105/120 | การปรับใช้การคำนวณแบบปรับขนาด |
| IMO-ProofBench | 85% pass@1 | 65% | วงจรการแก้ไขตนเอง |
ตัวเลขเหล่านี้ได้มาจากการทดลองควบคุม ซึ่งผู้ประเมินให้คะแนนผลลัพธ์จากความถูกต้อง ความสมบูรณ์ และความกระชับ ดังนั้น DeepSeekMath-V2 จึงกำหนดมาตรฐานใหม่สำหรับ AI ในคณิตศาสตร์เชิงรูปนัย
นวัตกรรมในการให้เหตุผลที่ตรวจสอบได้ด้วยตนเอง: นอกเหนือจากการสร้างไปสู่การรับรอง
สิ่งที่ทำให้ DeepSeekMath-V2 แตกต่างคือกระบวนทัศน์การตรวจสอบตนเอง ซึ่งเปลี่ยนการสร้างแบบ Passive ไปสู่การรับรองแบบ Active โมดูลตัวตรวจสอบ ซึ่งเป็นเครือข่ายเสริมขนาดเล็ก จะแยกวิเคราะห์ข้อพิสูจน์เป็น Abstract Syntax Trees (ASTs) และใช้การตรวจสอบตามกฎ ตัวอย่างเช่น มันตรวจสอบการสลับตำแหน่งในการดำเนินการเมทริกซ์ หรือฐานอุปนัยในการพิสูจน์แบบวนซ้ำ
นอกจากนี้ ระบบยังรวม Monte Carlo Tree Search (MCTS) ในระหว่างการอนุมาน สำรวจสาขาการพิสูจน์ และตัดเส้นทางที่ไม่ถูกต้องผ่านการตอบรับของตัวตรวจสอบ รหัสจำลองนี้แสดงให้เห็นสิ่งนี้:
def generate_verified_proof(problem):
root = initialize_state(problem)
while not terminal(root):
children = expand(root, generator)
for child in children:
score = verifier.evaluate(child.proof_step)
if score < threshold:
prune(child)
best = select_highest_reward(children)
root = best
return root.proof
กลไกนี้ทำให้มั่นใจว่าผลลัพธ์ยังคงสอดคล้องกับหลักการทางคณิตศาสตร์ แม้สำหรับปัญหาที่ยังไม่ได้รับการแก้ไข นักพัฒนาสามารถขยายได้ผ่านตัวตรวจสอบที่กำหนดเอง โดยรวมเข้ากับตัวพิสูจน์ทฤษฎีบทเช่น Lean สำหรับการตรวจสอบแบบไฮบริด
ในฐานะสะพานเชื่อมสู่แอปพลิเคชัน ความสามารถในการตรวจสอบดังกล่าวช่วยเพิ่มความน่าเชื่อถือในการวิจัยที่ได้รับความช่วยเหลือจาก AI ในการตั้งค่าการทำงานร่วมกัน ผู้ใช้จะใส่คำอธิบายประกอบการตัดสินใจของตัวตรวจสอบ ซึ่งปรับปรุงโมเดลผ่านลูปการเรียนรู้แบบ Active
การประยุกต์ใช้งานจริง: การรวม DeepSeekMath-V2 เข้ากับเครื่องมืออย่าง Apidog
การปรับใช้ DeepSeekMath-V2 ปลดล็อกแอปพลิเคชันในการศึกษา การวิจัย และอุตสาหกรรม ในแวดวงวิชาการ มันช่วยร่างข้อพิสูจน์สำหรับนักศึกษาระดับปริญญาตรีโดยอัตโนมัติ โดยตรวจสอบโซลูชันก่อนส่ง อุตสาหกรรมต่างๆ ใช้ประโยชน์จากมันสำหรับปัญหาการเพิ่มประสิทธิภาพในการขนส่ง ซึ่งการคำนวณเชิงอนุพันธ์ที่ตรวจสอบได้เป็นเหตุผลในการเลือกอัลกอริทึม
เพื่อให้การดำเนินการนี้ง่ายขึ้น การผสานรวมกับเครื่องมือจัดการ API จึงมีคุณค่าอย่างยิ่ง ตัวอย่างเช่น Apidog ช่วยให้การทดสอบ DeepSeekMath-V2 endpoints เป็นไปอย่างราบรื่น ผู้ใช้สามารถออกแบบ API schemas สำหรับคำขอสร้างข้อพิสูจน์ จำลองการตอบกลับด้วยข้อมูลเมตาการตรวจสอบ และตรวจสอบ Latency ในแดชบอร์ดแบบเรียลไทม์ การตั้งค่านี้ช่วยเร่งการสร้างต้นแบบ: นำเข้าโมเดล Hugging Face เปิดเผยผ่าน FastAPI และตรวจสอบด้วยการทดสอบสัญญาของ Apidog
ในบริบทขององค์กร การรวมระบบดังกล่าวจะปรับขนาดเพื่อจัดการกับการตรวจสอบแบบ Batch ซึ่งช่วยลดโอเวอร์เฮดการคำนวณผ่านชั้นแคชของ Apidog ดังนั้น DeepSeekMath-V2 จึงเปลี่ยนจากสิ่งประดิษฐ์ทางการวิจัยไปสู่ทรัพย์สินในการผลิต
การเปรียบเทียบและข้อจำกัด: การจัดบริบท DeepSeekMath-V2 ในระบบนิเวศ AI
DeepSeekMath-V2 มีประสิทธิภาพเหนือกว่าคู่แข่งโอเพนซอร์สอย่าง Llama-3.1-405B ในงานเฉพาะทางคณิตศาสตร์ โดยมีกำไร 15-20% ในความแม่นยำของการพิสูจน์ เมื่อเทียบกับโมเดลปิด มันลดช่องว่างในเกณฑ์มาตรฐานที่เน้นการตรวจสอบ แม้ว่าจะยังล้าหลังในการสนับสนุนหลายภาษา ใบอนุญาต Apache 2.0 ทำให้การเข้าถึงเป็นประชาธิปไตย ซึ่งแตกต่างจากข้อจำกัดที่เป็นกรรมสิทธิ์
อย่างไรก็ตาม ข้อจำกัดยังคงมีอยู่ จำนวนพารามิเตอร์ที่สูงต้องการ VRAM จำนวนมาก—อย่างน้อย 8x A100 GPUs สำหรับการอนุมาน การคำนวณเพื่อการตรวจสอบเพิ่ม Latency สำหรับการพิสูจน์ที่ยาว และโมเดลมีปัญหาในการแก้ปัญหาแบบสหวิทยาการที่ขาดโครงสร้างที่เป็นทางการ รุ่นในอนาคตอาจแก้ไขสิ่งเหล่านี้ผ่านเทคนิคการกลั่น
ถึงกระนั้น การแลกเปลี่ยนเหล่านี้ให้ความน่าเชื่อถือที่ไม่มีใครเทียบได้ โดยวางตำแหน่ง DeepSeekMath-V2 เป็นรากฐานสำคัญสำหรับ AI ที่ตรวจสอบได้
ทิศทางในอนาคต: การพัฒนา AI ทางคณิตศาสตร์ด้วย DeepSeekMath-V2
ในอนาคต DeepSeekMath-V2 ปูทางสำหรับการให้เหตุผลแบบ Multimodal โดยรวมแผนภาพเข้ากับการพิสูจน์ การทำงานร่วมกันกับชุมชนการตรวจสอบอย่างเป็นทางการอาจฝังมันในระบบนิเวศ Coq หรือ Isabelle นอกจากนี้ ความก้าวหน้าของ RL อาจทำให้การวิวัฒนาการของตัวตรวจสอบเป็นไปโดยอัตโนมัติ ลดการกำกับดูแลของมนุษย์
สรุปแล้ว DeepSeekMath-V2 กำหนดนิยามใหม่ของ AI ทางคณิตศาสตร์ผ่านกลไกที่ตรวจสอบได้ด้วยตนเอง สถาปัตยกรรม การฝึกอบรม และประสิทธิภาพของมันกระตุ้นให้เกิดการนำไปใช้อย่างกว้างขวาง โดยได้รับการเสริมประสิทธิภาพจากเครื่องมืออย่าง Apidog เมื่อ AI เติบโตขึ้น โมเดลดังกล่าวจะช่วยให้การให้เหตุผลยังคงอยู่บนพื้นฐานของความจริง