
ตระกูล Qwen 3 ครองตลาด LLM แบบโอเพ่นซอร์สในปี 2026 วิศวกรนำโมเดลเหล่านี้ไปใช้งานทุกที่ ตั้งแต่เอเจนต์ระดับองค์กรที่มีความสำคัญต่อภารกิจไปจนถึงผู้ช่วยบนมือถือ ก่อนที่คุณจะเริ่มส่งคำขอไปยัง Alibaba Cloud หรือโฮสต์ด้วยตัวเอง มาปรับปรุงเวิร์กโฟลว์ของคุณด้วย Apidog กัน
ภาพรวมของ Qwen 3: นวัตกรรมสถาปัตยกรรมที่ขับเคลื่อนประสิทธิภาพปี 2026
ทีม Qwen ของ Alibaba ได้เปิดตัว ซีรีส์ Qwen 3 เมื่อวันที่ 29 เมษายน 2026 ซึ่งถือเป็นความก้าวหน้าที่สำคัญในโมเดลภาษาขนาดใหญ่ (LLM) แบบโอเพ่นซอร์ส นักพัฒนาต่างชื่นชมใบอนุญาต Apache 2.0 ซึ่งช่วยให้สามารถปรับแต่งและนำไปใช้ในเชิงพาณิชย์ได้อย่างอิสระ โดยแก่นแท้แล้ว Qwen 3 ใช้สถาปัตยกรรมที่ใช้ Transformer พร้อมการปรับปรุงใน positional embeddings และ attention mechanisms ซึ่งรองรับความยาวคอนเท็กซ์สูงสุด 128K โทเค็นโดยธรรมชาติ และสามารถขยายได้ถึง 131K ผ่าน YaRN

นอกจากนี้ ซีรีส์ยังรวมการออกแบบ Mixture-of-Experts (MoE) ในบางรุ่น โดยจะเปิดใช้งานพารามิเตอร์เพียงบางส่วนระหว่างการอนุมาน วิธีการนี้ช่วยลดภาระการคำนวณในขณะที่ยังคงรักษาความแม่นยำสูงในการส่งออก ตัวอย่างเช่น วิศวกรรายงานว่ามีปริมาณงานที่เร็วขึ้นถึง 10 เท่าสำหรับงานคอนเท็กซ์ยาวเมื่อเทียบกับรุ่นก่อนหน้าที่หนาแน่นกว่า เช่น Qwen2.5-72B ด้วยเหตุนี้ Qwen 3 จึงสามารถปรับขนาดได้อย่างมีประสิทธิภาพในฮาร์ดแวร์ ตั้งแต่ edge devices ไปจนถึง cloud clusters
Qwen 3 ยังโดดเด่นในการรองรับหลายภาษา โดยจัดการได้มากกว่า 119 ภาษาพร้อมการปฏิบัติตามคำสั่งที่ละเอียดอ่อน ผลการวัดยืนยันความได้เปรียบในสาขา STEM ซึ่งประมวลผลข้อมูลคณิตศาสตร์และโค้ดสังเคราะห์ที่ปรับปรุงจาก 36 ล้านล้านโทเค็น ดังนั้น แอปพลิเคชันในองค์กรระดับโลกจึงได้รับประโยชน์จากการลดข้อผิดพลาดในการแปลและการปรับปรุงการให้เหตุผลข้ามภาษา การเปลี่ยนไปสู่รายละเอียดเฉพาะ โหมดการให้เหตุผลแบบไฮบริด ซึ่งสลับผ่านแฟล็กโทเคไนเซอร์ ช่วยให้โมเดลสามารถใช้ตรรกะแบบทีละขั้นตอนสำหรับคณิตศาสตร์หรือการเขียนโค้ด หรือตั้งค่าเริ่มต้นเป็นการไม่คิดสำหรับการสนทนา การทำงานสองแบบนี้ช่วยให้นักพัฒนาสามารถเพิ่มประสิทธิภาพตามกรณีการใช้งานได้
คุณสมบัติหลักที่รวม Qwen 3 รุ่นต่างๆ เข้าด้วยกัน
โมเดล Qwen 3 ทุกรุ่นมีคุณสมบัติพื้นฐานร่วมกันที่ช่วยยกระดับประโยชน์ใช้สอยในปี 2026 ประการแรก โมเดลเหล่านี้รองรับการทำงานสองโหมด: โหมดการคิดจะเปิดใช้งานกระบวนการ "chain-of-thought" สำหรับการทดสอบประสิทธิภาพ เช่น AIME25 ในขณะที่โหมดไม่คิดจะให้ความสำคัญกับความเร็วสำหรับแอปพลิเคชันแชท วิศวกรสลับโหมดนี้ด้วยพารามิเตอร์ง่ายๆ ทำให้ได้ความแม่นยำสูงสุด 92.3% ในการคำนวณทางคณิตศาสตร์ที่ซับซ้อนโดยไม่ลดทอนความหน่วง
ประการที่สอง คุณสมบัติของเอเจนต์ช่วยให้สามารถเรียกใช้เครื่องมือได้อย่างราบรื่น เหนือกว่าโมเดลโอเพ่นซอร์สอื่นๆ ในงานต่างๆ เช่น การนำทางเบราว์เซอร์หรือการดำเนินการโค้ด ตัวอย่างเช่น Qwen 3 รุ่นต่างๆ ได้คะแนน 69.6 ใน Tau2-Bench Verified ซึ่งเทียบเท่ากับโมเดลที่เป็นกรรมสิทธิ์ นอกจากนี้ ความสามารถในการรองรับหลายภาษายังครอบคลุมภาษาถิ่นตั้งแต่ภาษาจีนกลางไปจนถึงภาษาสวาฮิลี โดยได้ 73.0 ในการทดสอบ MultiIF
ประการที่สาม ประสิทธิภาพเกิดจากรุ่นที่ถูกควอนไทซ์ (เช่น Q4_K_M) และเฟรมเวิร์กอย่าง vLLM หรือ SGLang ซึ่งให้ 25 โทเค็น/วินาทีบน GPU สำหรับผู้บริโภค อย่างไรก็ตาม โมเดลขนาดใหญ่ต้องการ VRAM 16GB+ ทำให้ต้องมีการใช้งานบนคลาวด์ ราคาแข่งขันได้ โดยมีโทเค็นอินพุตที่ $0.20–$1.20 ต่อล้านผ่าน Alibaba Cloud
นอกจากนี้ Qwen 3 ยังเน้นความปลอดภัยผ่านการกลั่นกรองในตัว ลดการหลอนได้ 15% เมื่อเทียบกับ Qwen2.5 นักพัฒนาใช้ประโยชน์จากสิ่งนี้สำหรับแอปพลิเคชันระดับการผลิต ตั้งแต่ระบบแนะนำอีคอมเมิร์ซไปจนถึงตัววิเคราะห์ทางกฎหมาย เมื่อเราเปลี่ยนไปที่แต่ละรุ่น จุดแข็งที่ใช้ร่วมกันเหล่านี้จะให้พื้นฐานที่สอดคล้องกันสำหรับการเปรียบเทียบ
5 รุ่นโมเดล Qwen 3 ที่ดีที่สุดในปี 2026
จากผลการทดสอบปี 2026 จาก LMSYS Arena, LiveCodeBench และ SWE-Bench เราได้จัดอันดับห้ารุ่น Qwen 3 อันดับแรก เกณฑ์การคัดเลือกประกอบด้วยคะแนนการให้เหตุผล ความเร็วในการอนุมาน ประสิทธิภาพของพารามิเตอร์ และการเข้าถึง API แต่ละรุ่นมีความโดดเด่นในสถานการณ์ที่แตกต่างกัน แต่ทั้งหมดล้วนก้าวหน้าไปพร้อมกับโอเพ่นซอร์ส
1. Qwen3-235B-A22B – โมเดล MoE ตัวเรือธงที่แข็งแกร่งที่สุด
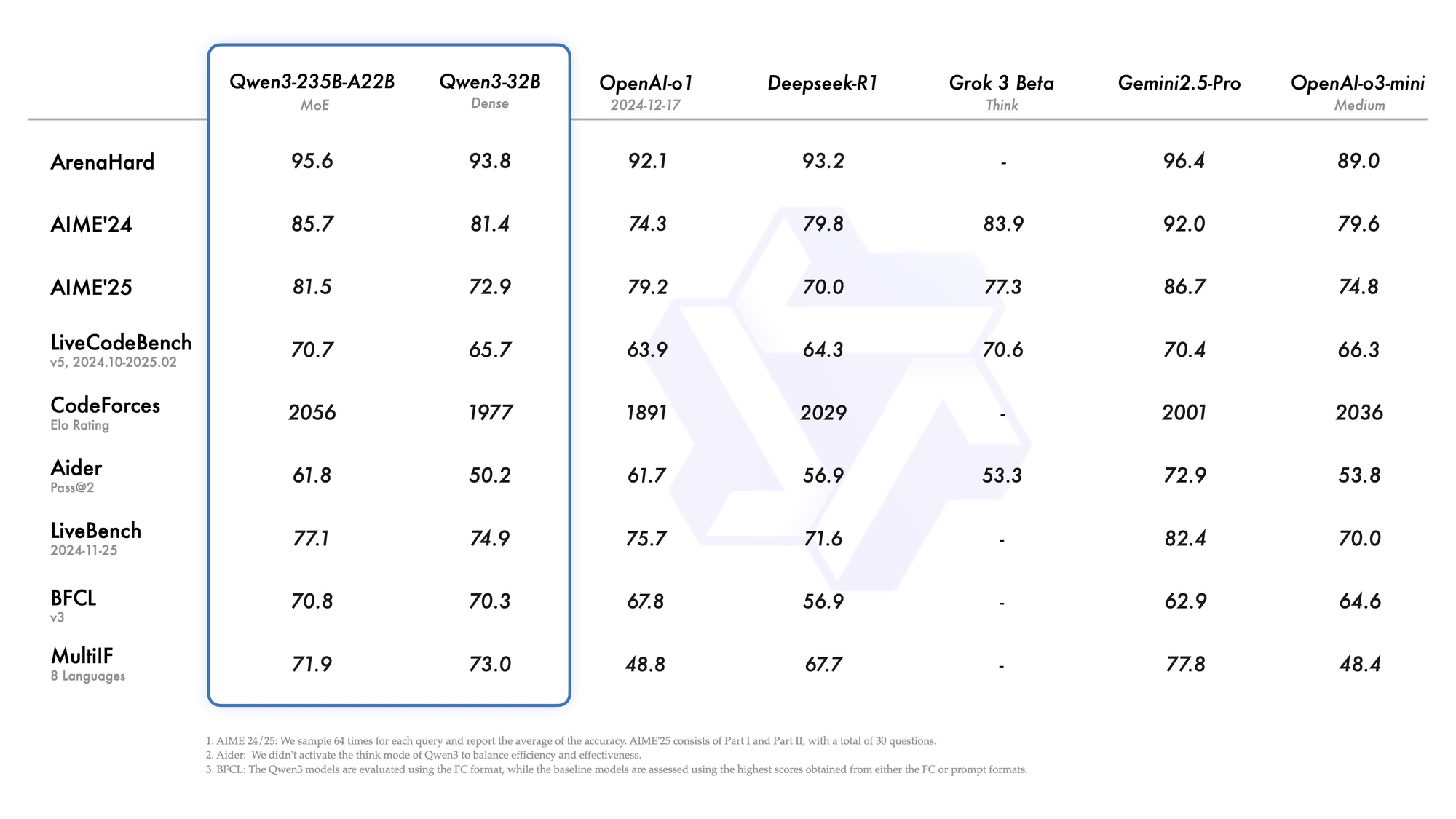
Qwen3-235B-A22B ดึงดูดความสนใจในฐานะรุ่น MoE ที่โดดเด่นที่สุด ด้วยพารามิเตอร์ทั้งหมด 235 พันล้านตัว และใช้งานอยู่ 22 พันล้านตัวต่อโทเค็น เปิดตัวในเดือนกรกฎาคม 2026 ในชื่อ Qwen3-235B-A22B-Instruct-2507 โดยเปิดใช้งานผู้เชี่ยวชาญแปดคนผ่านการกำหนดเส้นทางแบบ top-k ลดการคำนวณลง 90% เมื่อเทียบกับรุ่นที่หนาแน่น การทดสอบประสิทธิภาพจัดให้มันเทียบเคียงกับ Gemini 2.5 Pro: 95.6 ใน ArenaHard, 77.1 ใน LiveBench และเป็นผู้นำใน CodeForces Elo (นำอยู่ 5%)
ในการเขียนโค้ด ทำคะแนนได้ 74.8 ใน LiveCodeBench v6 โดยสร้าง TypeScript ที่ใช้งานได้ด้วยการทำซ้ำน้อยที่สุด สำหรับคณิตศาสตร์ โหมดการคิดให้ผล 92.3 ใน AIME25 แก้โจทย์ปริพันธ์หลายขั้นตอนผ่านการอนุมานอย่างชัดเจน งานหลายภาษาทำคะแนนได้ 73.0 ใน MultiIF ประมวลผลคำถามภาษาอาหรับได้อย่างไม่มีที่ติ
การใช้งานรองรับ API บนคลาวด์ ซึ่งสามารถจัดการบริบทได้ 256K อย่างไรก็ตาม การรันในเครื่องต้องใช้ GPU H100 8 ตัว วิศวกรนำไปใช้กับเวิร์กโฟลว์ของเอเจนต์ เช่น การดีบักระดับ repository โดยรวมแล้ว รุ่นนี้กำหนดมาตรฐานปี 2026 สำหรับความลึก แม้ว่าขนาดของมันจะเหมาะสำหรับทีมที่มีงบประมาณสูงก็ตาม
จุดแข็ง
- เทียบเท่าหรือดีกว่า Gemini 2.5 Pro และ Claude 3.7 Sonnet ในกระดานผู้นำเกือบทุกรายการในปี 2026 (95.6 ArenaHard, 92.3 AIME25 โหมดคิด, 74.8 LiveCodeBench v6)
- เก่งในเวิร์กโฟลว์ของเอเจนต์แบบหลายขั้นตอน, การเรียกใช้เครื่องมือที่ซับซ้อน และการทำความเข้าใจโค้ดระดับ repository
- จัดการบริบท 256K–1M ด้วย YaRN โดยไม่ลดคุณภาพ
- โหมดการคิดให้การให้เหตุผลแบบ "chain-of-thought" ที่ตรวจสอบได้ ซึ่งเทียบเคียงกับโมเดล frontier แบบปิด
จุดอ่อน
- มีราคาแพงมากและช้าเมื่อทำงานในเครื่อง – ต้องใช้ 8×H100 หรือเทียบเท่าสำหรับความหน่วงที่ยอมรับได้
- ราคา API สูงที่สุดในตระกูล ($1.20–$6.00/M output tokens ที่บริบทสูงสุด)
- เกินความจำเป็นสำหรับ 95% ของงานการผลิต; ทีมส่วนใหญ่ไม่เคยใช้ศักยภาพของมันจนเต็มที่
ควรใช้เมื่อใด
- เอเจนต์อัตโนมัติระดับองค์กรที่ต้องแก้ปัญหาคณิตศาสตร์ระดับปริญญาเอก, ดีบักโค้ดเบสทั้งหมด, หรือวิเคราะห์สัญญาทางกฎหมายโดยแทบไม่มีการหลอน
- ห้องปฏิบัติการวิจัยที่มีงบประมาณสูงที่ผลักดันขีดจำกัดของเทคโนโลยีใหม่ๆ ในการทดสอบประสิทธิภาพ
- แบ็กเอนด์การให้เหตุผลภายในที่ต้นทุนต่อโทเค็นเป็นรองจากความฉลาดสูงสุด
2. Qwen3-30B-A3B – แชมป์ MoE ที่ลงตัว
Qwen3-30B-A3B กลายเป็นตัวเลือกหลักสำหรับชุดการตั้งค่าที่จำกัดทรัพยากร โดยมีพารามิเตอร์รวม 30.5 พันล้านตัว และพารามิเตอร์ที่ใช้งานอยู่ 3.3 พันล้านตัว โครงสร้าง MoE ของมัน—48 เลเยอร์, 128 ผู้เชี่ยวชาญ (แปดตัวถูกกำหนดเส้นทาง)—สะท้อนถึงรุ่นเรือธงแต่มีขนาดเพียง 10% อัปเดตในเดือนกรกฎาคม 2026 เหนือกว่า QwQ-32B ถึง 10 เท่าในด้านประสิทธิภาพที่ใช้งานอยู่ โดยทำคะแนนได้ 91.0 ใน ArenaHard และ 69.6 ใน SWE-Bench Verified
การประเมินการเขียนโค้ดเน้นย้ำถึงความสามารถของมัน: 32.4% pass@5 ใน GitHub PRs ใหม่ เทียบเท่ากับ GPT-5-High การวัดประสิทธิภาพทางคณิตศาสตร์แสดงให้เห็น 81.6 ใน AIME25 ในโหมดการคิด เทียบเท่ากับรุ่นพี่ที่มีขนาดใหญ่กว่า ด้วยบริบท 131K ผ่าน YaRN ทำให้สามารถประมวลผลเอกสารยาวๆ ได้โดยไม่มีการตัดทอน
จุดแข็ง
- พารามิเตอร์ที่ใช้งานอยู่ถูกลง 10 เท่าเมื่อเทียบกับรุ่น 235B ในขณะที่ยังคงคุณภาพการให้เหตุผลของรุ่นเรือธงไว้ได้ประมาณ 90–95% (91.0 ArenaHard, 81.6 AIME25)
- ทำงานได้อย่างสบายบน A100 ขนาด 80GB ตัวเดียว หรือการ์ด 40GB สองตัวด้วย vLLM + FlashAttention
- อัตราส่วนราคาต่อประสิทธิภาพที่ดีที่สุดในบรรดาโมเดล MoE แบบเปิดในปี 2026
- เหนือกว่าโมเดลแบบหนาแน่นทุกรุ่นที่มีขนาด 72B–110B ในด้านการเขียนโค้ดและคณิตศาสตร์
จุดอ่อน
- ยังคงต้องการ VRAM ประมาณ 24–30GB ใน FP8/INT4; ไม่เหมาะสำหรับแล็ปท็อป
- ความคล่องแคล่วในการเขียนเชิงสร้างสรรค์ต่ำกว่าโมเดลแบบหนาแน่นที่มีขนาดใกล้เคียงกันเล็กน้อย
- ความหน่วงของโหมดการคิดเพิ่มขึ้น 2–3 เท่าเมื่อเทียบกับโหมดไม่คิด
ควรใช้เมื่อใด
- เอเจนต์การเขียนโค้ดเพื่อการผลิต, การตรวจสอบ PR อัตโนมัติ, หรือ copilots สำหรับ DevOps ภายในองค์กร
- ไปป์ไลน์การวิจัยที่มีปริมาณงานสูงที่ต้องการการให้เหตุผลทางคณิตศาสตร์หรือวิทยาศาสตร์ระดับแนวหน้าด้วยงบประมาณที่สมเหตุสมผล
- ทีมใดก็ตามที่เคยใช้ Llama-405B หรือ Mixtral-123B แต่ต้องการการให้เหตุผลที่ดีกว่าในราคาที่ถูกลง
3. Qwen3-32B – ราชาผู้รอบด้านแบบหนาแน่น
Qwen3-32B แบบหนาแน่นมีพารามิเตอร์ที่ใช้งานอยู่เต็ม 32 พันล้านตัว โดยเน้นปริมาณงานดิบมากกว่าความเบาบาง ได้รับการฝึกอบรมด้วยโทเค็น 36 ล้านล้านตัว มีประสิทธิภาพพื้นฐานเทียบเท่ากับ Qwen2.5-72B แต่โดดเด่นในการปรับแนวหลังการฝึกอบรม ผลการทดสอบแสดงให้เห็น 89.5 ใน ArenaHard และ 73.0 ใน MultiIF พร้อมกับการเขียนเชิงสร้างสรรค์ที่แข็งแกร่ง (เช่น เรื่องเล่าแบบสวมบทบาทที่ได้คะแนนความชอบของมนุษย์ 85%)
ในการเขียนโค้ด เป็นผู้นำ BFCL ที่ 68.2 สร้าง UI แบบลากและวางจากพรอมต์ คณิตศาสตร์ให้ 70.3 ใน AIME25 แม้ว่าจะตามหลัง MoE peers ในการให้เหตุผลแบบ "chain-of-thought" บริบท 128K เหมาะสำหรับฐานความรู้ และโหมดไม่คิดช่วยเพิ่มความเร็วในการสนทนาเป็น 20 โทเค็น/วินาที
จุดแข็ง
- การทำตามคำสั่งและการสร้างสรรค์ผลงานที่ยอดเยี่ยม – มักถูกเลือกเหนือโมเดล MoE ขนาดใหญ่กว่าในการประเมินโดยมนุษย์แบบไม่ระบุตัวตนสำหรับการเขียนและการสวมบทบาท
- ปรับแต่งได้ง่ายด้วย LoRA/QLoRA บนฮาร์ดแวร์สำหรับผู้บริโภค (VRAM 16–24GB)
- การอนุมานที่เร็วที่สุดในบรรดาโมเดลที่ยังคงเอาชนะ GPT-4o ได้ในหลายงาน (89.5 ArenaHard)
- ประสิทธิภาพหลายภาษาที่แข็งแกร่งมากในกว่า 119 ภาษา
จุดอ่อน
- คะแนนตามหลังโมเดล MoE ประมาณ 8–12 จุดในงานคณิตศาสตร์และการเขียนโค้ดที่ยากที่สุดเมื่อเปิดโหมดการคิด
- ไม่มีเทคนิคการประหยัดพารามิเตอร์ – ทุกโทเค็นต้องใช้การคำนวณเต็ม 32B
ควรใช้เมื่อใด
- แพลตฟอร์มการสร้างเนื้อหา, ผู้ช่วยเขียนนิยาย, เครื่องมือเขียนข้อความโฆษณาทางการตลาด
- โปรเจกต์ที่ต้องการการปรับแต่งอย่างมาก (แชทบอทเฉพาะโดเมน, การถ่ายโอนสไตล์)
- ทีมที่ต้องการคุณภาพใกล้เคียงรุ่นเรือธงแต่ต้องอยู่ภายใต้ VRAM 24GB
4. Qwen3-14B – ขุมพลังสำหรับ Edge และ Mobile
Qwen3-14B ให้ความสำคัญกับการพกพาด้วยพารามิเตอร์ 14.8 พันล้านตัว รองรับบริบท 128K บนฮาร์ดแวร์ระดับกลาง มีประสิทธิภาพเทียบเท่ากับ Qwen2.5-32B โดยทำคะแนนได้ 85.5 ใน ArenaHard และสามารถแข่งขันกับ Qwen3-30B-A3B ในด้านคณิตศาสตร์/การเขียนโค้ด (ภายในช่วง 5%) เมื่อควอนไทซ์เป็น Q4_0 สามารถทำงานได้ที่ 24.5 โทเค็น/วินาทีบนมือถือ เช่น RedMagic 8S Pro
งานของเอเจนต์ได้ 65.1 ใน Tau2-Bench ซึ่งช่วยให้สามารถใช้เครื่องมือในแอปพลิเคชันที่มีความหน่วงต่ำ การรองรับหลายภาษามีความโดดเด่น ด้วยความแม่นยำ 70% ในการอนุมานภาษาถิ่น สำหรับอุปกรณ์ Edge สามารถประมวลผลบริบท 32K แบบออฟไลน์ เหมาะสำหรับการวิเคราะห์ IoT
วิศวกรให้คุณค่ากับขนาดที่เล็กสำหรับการเรียนรู้แบบกระจายศูนย์ (federated learning) ซึ่งความเป็นส่วนตัวมีความสำคัญเหนือขนาด ดังนั้นจึงเหมาะสำหรับผู้ช่วย AI บนมือถือหรือระบบฝังตัว
จุดแข็ง
- ทำงานที่ 24–30 โทเค็น/วินาทีบนโทรศัพท์รุ่นใหม่ (Snapdragon 8 Gen 4, Dimensity 9400) เมื่อควอนไทซ์เป็น Q4_K_M
- ยังคงเอาชนะ Qwen2.5-32B และ Llama-3.1-70B ได้ในการทดสอบการให้เหตุผลส่วนใหญ่
- ยอดเยี่ยมสำหรับ RAG บนอุปกรณ์ด้วยบริบท 32K–128K
- ค่า API ต่ำที่สุดในกลุ่มประสิทธิภาพระดับบน
จุดอ่อน
- เริ่มมีปัญหาในงานของเอเจนต์แบบหลายขั้นตอนที่ต้องการการเรียกใช้เครื่องมือมากกว่า 5 ครั้ง
- คุณภาพการเขียนเชิงสร้างสรรค์ต่ำกว่าโมเดล 32B+ อย่างเห็นได้ชัด
- มีอายุการใช้งานสั้นลงเมื่อคะแนนการทดสอบยังคงเพิ่มขึ้นเรื่อยๆ
ควรใช้เมื่อใด
- ผู้ช่วยบนอุปกรณ์ (แอป Android/iOS, อุปกรณ์สวมใส่)
- การติดตั้งใช้งานที่คำนึงถึงความเป็นส่วนตัว (การดูแลสุขภาพ, การเงิน) ที่ข้อมูลไม่สามารถออกจากอุปกรณ์ได้
- ระบบฝังตัวแบบเรียลไทม์ (หุ่นยนต์, รถยนต์, เกตเวย์ IoT)
5. Qwen3-8B – ม้างานน้ำหนักเบาสำหรับการสร้างต้นแบบขั้นสุดยอด
ปิดท้ายห้าอันดับแรก Qwen3-8B มีพารามิเตอร์ 8 พันล้านตัวสำหรับการทำซ้ำอย่างรวดเร็ว เหนือกว่า Qwen2.5-14B ในการทดสอบ 15 รายการ ทำคะแนนได้ 81.5 ใน AIME25 (โหมดไม่คิด) และ 60.2 ใน LiveCodeBench เพียงพอสำหรับการตรวจสอบโค้ดพื้นฐาน ด้วยบริบทพื้นฐาน 32K สามารถนำไปใช้บนแล็ปท็อปผ่าน Ollama ทำความเร็วได้ 25 โทเค็น/วินาที
รุ่นนี้เหมาะสำหรับผู้เริ่มต้นที่ต้องการทดสอบแชทหลายภาษาหรือเอเจนต์ง่ายๆ โหมดการคิดช่วยเพิ่มความสามารถในการไขปริศนาตรรกะ ทำคะแนนได้ 75% ในงานอนุมาน ด้วยเหตุนี้ จึงช่วยเร่งการพิสูจน์แนวคิดก่อนที่จะขยายไปยังรุ่นพี่ที่มีขนาดใหญ่กว่า
จุดแข็ง
- ทำงานได้ที่ >25 โทเค็น/วินาที แม้บนแล็ปท็อปที่มี VRAM 8–12GB (MacBook M3 Pro, RTX 4070 mobile)
- มีความสามารถในการทำตามคำสั่งที่น่าประหลาดใจ – เอาชนะ Gemma-2-27B และ Phi-4-14B ได้ในการทดสอบส่วนใหญ่ในปี 2026
- สมบูรณ์แบบสำหรับการทดลองกับ Ollama หรือ LM Studio ในเครื่อง
- ค่า API ถูกที่สุดในตระกูล
จุดอ่อน
- มีข้อจำกัดในการให้เหตุผลอย่างเห็นได้ชัดในโจทย์คณิตศาสตร์ระดับบัณฑิตศึกษาและปัญหาการเขียนโค้ดขั้นสูง
- มีแนวโน้มที่จะเกิดการหลอนมากขึ้นในงานที่ต้องใช้ความรู้มาก
- บริบทจำกัด (32K แบบเนทีฟ, 128K ด้วย YaRN แต่จะช้ากว่า)
ควรใช้เมื่อใด
- การสร้างต้นแบบอย่างรวดเร็วและการสร้าง MVP
- เครื่องมือเพื่อการศึกษา, ผู้ช่วยส่วนตัว, หรือโปรเจกต์งานอดิเรก
- เลเยอร์การกำหนดเส้นทางส่วนหน้าในระบบไฮบริด (ใช้ 8B เพื่อคัดกรอง, ส่งต่อให้ 30B/235B เมื่อจำเป็น)
ราคา API และข้อควรพิจารณาในการนำไปใช้สำหรับโมเดล Qwen 3
การเข้าถึง Qwen 3 ผ่าน API ทำให้ AI ขั้นสูงเป็นประชาธิปไตย โดย Alibaba Cloud เป็นผู้นำในอัตราที่แข่งขันได้ การกำหนดราคาเป็นชั้นตามโทเค็น: สำหรับ Qwen3-235B-A22B อินพุตมีค่าใช้จ่าย $0.20–$1.20/ล้าน (ช่วง 0–252K) เอาต์พุต $1.00–$6.00/ล้าน Qwen3-30B-A3B มีอัตราใกล้เคียงกันที่ 80% ของอัตรานี้ ในขณะที่โมเดลหนาแน่นอย่าง Qwen3-32B ลดลงเหลือ $0.15 สำหรับอินพุต/$0.75 สำหรับเอาต์พุต
ผู้ให้บริการภายนอกเช่น Together AI เสนอ Qwen3-32B ในราคา $0.80/1M โทเค็นทั้งหมด พร้อมส่วนลดปริมาณ Cache hits ช่วยลดค่าใช้จ่าย: แบบปริยาย 20% แบบชัดเจน 10% เมื่อเทียบกับ GPT-5 ($3–15/1M) Qwen 3 มีราคาต่ำกว่า 70% ทำให้สามารถปรับขนาดได้อย่างคุ้มค่า
เคล็ดลับการนำไปใช้: ใช้ vLLM สำหรับการรวมกลุ่ม, SGLang สำหรับความเข้ากันได้กับ OpenAI Apidog ช่วยเพิ่มประสิทธิภาพโดยการจำลองปลายทางของ Qwen, ทดสอบเพย์โหลด และสร้างเอกสาร ซึ่งเป็นสิ่งสำคัญสำหรับไปป์ไลน์ CI/CD การรันในเครื่องผ่าน Ollama เหมาะสำหรับการสร้างต้นแบบ แต่ API โดดเด่นสำหรับการผลิต
คุณสมบัติความปลอดภัย เช่น การจำกัดอัตราและการกลั่นกรองเพิ่มคุณค่าโดยไม่มีค่าธรรมเนียมเพิ่มเติม ดังนั้น ทีมที่คำนึงถึงงบประมาณจะเลือกตามปริมาณโทเค็น: รุ่นเล็กสำหรับนักพัฒนา รุ่นเรือธงสำหรับการอนุมาน
ตารางการตัดสินใจ – เลือกโมเดล Qwen 3 ของคุณในปี 2026
| อันดับ | โมเดล | พารามิเตอร์ (รวม/ใช้งาน) | สรุปจุดแข็ง | จุดอ่อนหลัก | เหมาะสำหรับ | ค่า API โดยประมาณ (อินพุต/เอาต์พุตต่อ 1M โทเค็น) | VRAM ขั้นต่ำ (ควอนไทซ์) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235B / 22B MoE | การให้เหตุผลสูงสุด, การทำงานแบบเอเจนต์, คณิตศาสตร์, โค้ด | แพงมากและหนัก | การวิจัยขั้นสูง, เอเจนต์ระดับองค์กร, ความแม่นยำที่ไม่ยอมให้ผิดพลาด | $0.20–$1.20 / $1.00–$6.00 | 64GB+ (คลาวด์) |
| 2 | Qwen3-30B-A3B | 30.5B / 3.3B MoE | อัตราส่วนราคาต่อประสิทธิภาพดีที่สุด, การให้เหตุผลแข็งแกร่ง | ยังคงต้องใช้เซิร์ฟเวอร์ GPU | เอเจนต์เขียนโค้ดสำหรับการผลิต, แบ็กเอนด์คณิตศาสตร์/วิทยาศาสตร์, การอนุมานปริมาณมาก | $0.16–$0.96 / $0.80–$4.80 | 24–30GB |
| 3 | Qwen3-32B | 32B Dense | การเขียนเชิงสร้างสรรค์, ปรับแต่งง่าย, ความเร็ว | ตามหลัง MoE ในงานที่ยากที่สุด | แพลตฟอร์มเนื้อหา, การปรับแต่งเฉพาะโดเมน, แชทบอทหลายภาษา | $0.15 / $0.75 | 16–20GB |
| 4 | Qwen3-14B | 14.8B Dense | รองรับ Edge/มือถือ, RAG บนอุปกรณ์ยอดเยี่ยม | ความสามารถของเอเจนต์แบบหลายขั้นตอนจำกัด | AI บนอุปกรณ์, แอปที่ต้องการความเป็นส่วนตัวสูง, ระบบฝังตัว | $0.12 / $0.60 | 8–12GB |
| 5 | Qwen3-8B | 8B Dense | ความเร็วเท่าแล็ปท็อป/โทรศัพท์, ถูกที่สุด | มีข้อจำกัดชัดเจนในงานที่ซับซ้อน | การสร้างต้นแบบ, ผู้ช่วยส่วนตัว, เลเยอร์การกำหนดเส้นทางในระบบไฮบริด | $0.10 / $0.50 | 4–8GB |
คำแนะนำสุดท้ายสำหรับปี 2026
ทีมส่วนใหญ่ในปี 2026 ควรกำหนดค่าเริ่มต้นเป็น Qwen3-30B-A3B ซึ่งให้พลังงานมากกว่า 90% ของรุ่นเรือธงในราคาเพียงเศษเสี้ยวและข้อกำหนดฮาร์ดแวร์ที่น้อยกว่า ควรเปลี่ยนไปใช้ 235B-A22B ก็ต่อเมื่อคุณต้องการคุณภาพการให้เหตุผลที่สูงขึ้นอีก 5-10% จริงๆ และมีงบประมาณที่เพียงพอ ลดระดับลงไปที่ 32B แบบหนาแน่นสำหรับงานที่เน้นความคิดสร้างสรรค์หรือการปรับแต่ง และใช้ 14B/8B เมื่อความหน่วง ความเป็นส่วนตัว หรือข้อจำกัดของอุปกรณ์เป็นปัจจัยสำคัญ
ไม่ว่าคุณจะเลือกรุ่นใด Apidog จะช่วยคุณประหยัดเวลาในการดีบัก API ได้หลายชั่วโมง ดาวน์โหลดได้ฟรีวันนี้และเริ่มสร้างด้วย Qwen 3 อย่างมั่นใจ