
Executar Gemma 3 localmente com Ollama oferece controle total sobre seu ambiente de IA sem depender de serviços em nuvem. Este guia orienta você na configuração do Ollama, download do Gemma 3 e como executá-lo em sua máquina.
Vamos começar.
Por que executar o Gemma 3 localmente com o Ollama?
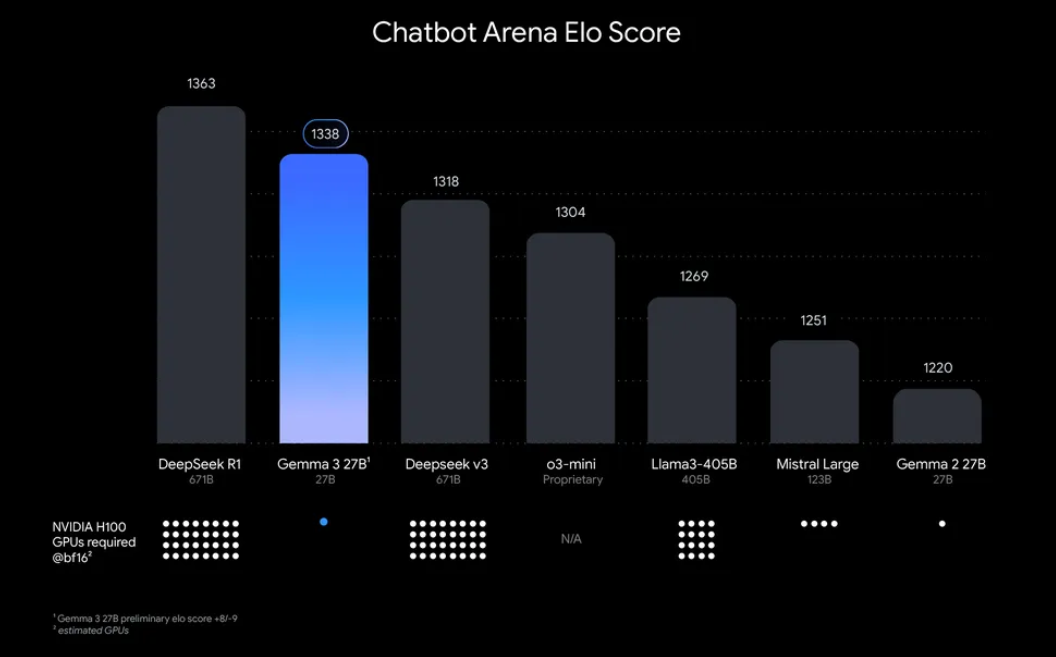
“Por que se preocupar em executar Gemma 3 localmente?” Bem, existem algumas razões convincentes. Para começar, a implantação local oferece controle total sobre seus dados e privacidade, sem necessidade de enviar informações sensíveis para a nuvem. Além disso, é econômico, pois você evita taxas contínuas de uso da API. Além disso, a eficiência do Gemma 3 significa que até mesmo o modelo de 27B pode ser executado em uma única GPU, tornando-o acessível para desenvolvedores com hardware modesto.
Ollama, uma plataforma leve para executar grandes modelos de linguagem (LLMs) localmente, simplifica esse processo. Ele empacota tudo o que você precisa - pesos de modelo, configurações e dependências - em um formato fácil de usar. Esta combinação de Gemma 3 e Ollama é perfeita para tinkering, construção de aplicações ou teste de fluxos de trabalho de IA na sua máquina. Então, vamos arregaçar as mangas e começar!
O que você precisará para executar o Gemma 3 com o Ollama
Antes de começarmos o processo de configuração, certifique-se de que você possui os seguintes requisitos:
- Uma máquina compatível: Você precisará de um computador com GPU (preferencialmente NVIDIA para desempenho ideal) ou um CPU poderoso. O modelo de 27B requer recursos significativos, mas versões menores como 1B ou 4B podem ser executadas em hardware menos potente.
- Ollama instalado: Baixe e instale o Ollama, disponível para MacOS, Windows e Linux. Você pode obtê-lo em ollama.com.
- Conhecimento básico de linha de comando: Você interagirá com o Ollama por meio do terminal ou prompt de comando.
- Conexão à Internet: Inicialmente, você precisará baixar os modelos do Gemma 3, mas uma vez baixados, você poderá executá-los offline.
- Opcional: Apidog para teste de API: Se você planeja integrar o Gemma 3 com uma API ou testar suas respostas programaticamente, a interface intuitiva do Apidog pode economizar seu tempo e esforço.
Agora que você está preparado, vamos nos aprofundar na instalação e no processo de configuração.
Guia passo a passo: instalando o Ollama e baixando o Gemma 3
1. Instale o Ollama na sua máquina
Ollama torna a implantação local de LLM uma brisa, e a instalação é simples. Veja como:
- Para MacOS/Windows: Visite ollama.com e baixe o instalador para seu sistema operacional. Siga as instruções na tela para concluir a instalação.
- Para Linux (por exemplo, Ubuntu): Abra seu terminal e execute o seguinte comando:
curl -fsSL https://ollama.com/install.sh | sh
Esse script detecta automaticamente seu hardware (incluindo GPUs) e instala o Ollama.
Após a instalação, verifique se foi bem-sucedida executando:
ollama --version

Você deve ver o número da versão atual, confirmando que o Ollama está pronto para uso.
2. Baixar modelos do Gemma 3 usando o Ollama
A biblioteca de modelos do Ollama inclui o Gemma 3, graças à sua integração com plataformas como Hugging Face e as ofertas de IA do Google. Para baixar o Gemma 3, use o comando ollama pull.
ollama pull gemma3

Para modelos menores, você pode usar:
ollama pull gemma3:12bollama pull gemma3:4bollama pull gemma3:1b
O tamanho do download varia por modelo; espere que o modelo de 27B tenha vários gigabytes, então assegure-se de que você tem espaço suficiente. Os modelos do Gemma 3 são otimizados para eficiência, mas ainda requerem hardware decente para as variantes maiores.
3. Verifique a instalação
Uma vez baixado, verifique se o modelo está disponível listando todos os modelos:
ollama list

Você deve ver gemma3 (ou seu tamanho escolhido) na lista. Se estiver lá, você está pronto para executar o Gemma 3 localmente!
Executando o Gemma 3 com Ollama: Modo interativo e integração de API
Modo interativo: conversando com o Gemma 3
O modo interativo do Ollama permite que você converse com o Gemma 3 diretamente do terminal. Para começar, execute:
ollama run gemma3
Você verá um prompt onde pode digitar perguntas. Por exemplo, tente:
Quais são os principais recursos do Gemma 3?
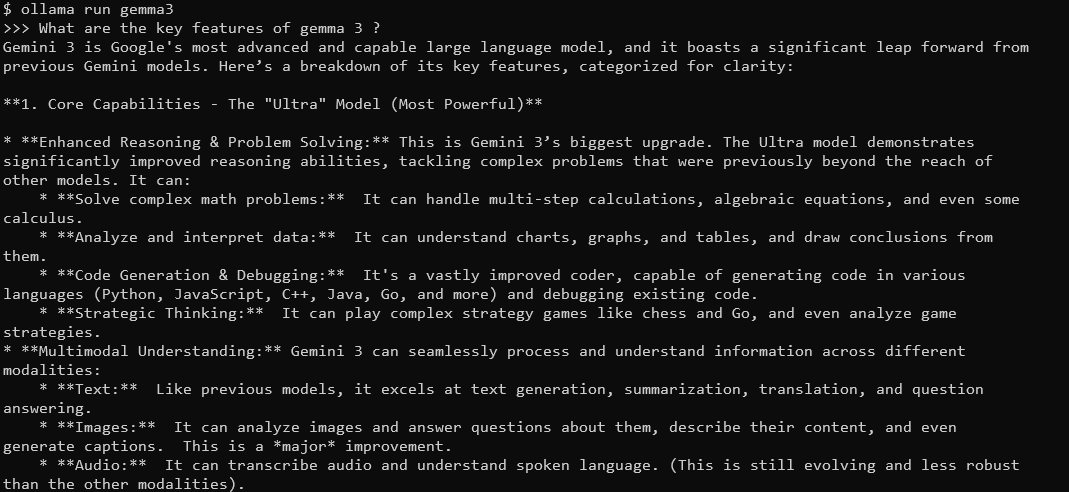
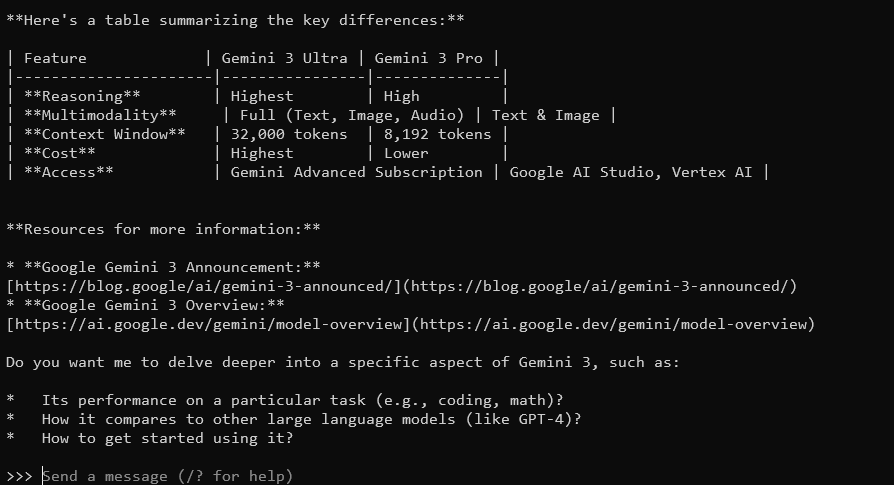
O Gemma 3, com sua janela de contexto de 128K e capacidades multimodais, responderá com respostas detalhadas e contextualizadas. Ele suporta mais de 140 idiomas e pode processar texto, imagens e até entradas de vídeo (para certos tamanhos).
Para sair, digite Ctrl+D ou /bye.
Integrando o Gemma 3 com a API do Ollama
Se você deseja construir aplicações ou automatizar interações, o Ollama fornece uma API que você pode usar. É aqui que o Apidog brilha: sua interface amigável ajuda você a testar e gerenciar requisições API de forma eficiente. Veja como começar:
Inicie o Servidor Ollama: Execute o seguinte comando para iniciar o servidor API do Ollama:
ollama serve
Isso inicia o servidor em localhost:11434 por padrão.
Faça requisições API: Você pode interagir com o Gemma 3 via solicitações HTTP. Por exemplo, use curl para enviar um prompt:
curl http://localhost:11434/api/generate -d '{"model": "gemma3", "prompt": "Qual é a capital da França?"}'
A resposta incluirá a saída do Gemma 3, formatada como JSON.
Use o Apidog para testes: Baixe o Apidog gratuitamente e crie uma requisição API para testar as respostas do Gemma 3. A interface visual do Apidog permite que você insira o endpoint (http://localhost:11434/api/generate), defina o payload JSON e analise as respostas sem escrever código complexo. Isso é especialmente útil para depuração e otimização de sua integração.
Guia passo a passo para usar testes SSE no Apidog
Vamos percorrer o processo de uso da funcionalidade de teste SSE otimizada no Apidog, completa com as novas melhorias de Auto-Merge. Siga estas etapas para configurar e maximizar sua experiência de depuração em tempo real.
Etapa 1: Crie uma nova requisição API
Comece lançando um novo projeto HTTP no Apidog. Adicione um novo endpoint e insira a URL para o seu endpoint de API ou modelo de IA. Este é seu ponto de partida para testar e depurar seus fluxos de dados em tempo real.
Etapa 2: Envie a requisição
Uma vez que seu endpoint esteja configurado, envie a requisição API. Observe cuidadosamente os cabeçalhos de resposta. Se o cabeçalho incluir Content-Type: text/event-stream, o Apidog reconhecerá e interpretará automaticamente a resposta como um fluxo SSE. Essa detecção é crucial para o subsequente processo de auto-merge.

Etapa 3: Monitore a linha do tempo em tempo real
Após a conexão SSE ser estabelecida, o Apidog abrirá uma visualização da linha do tempo dedicada onde todos os eventos SSE recebidos são exibidos em tempo real. Esta linha do tempo é atualizada continuamente à medida que novos dados chegam, permitindo que você monitore o fluxo de dados com precisão. A linha do tempo não é apenas uma descarga bruta de dados - é uma visualização cuidadosamente estruturada que ajuda você a ver exatamente quando e como os dados são transmitidos.
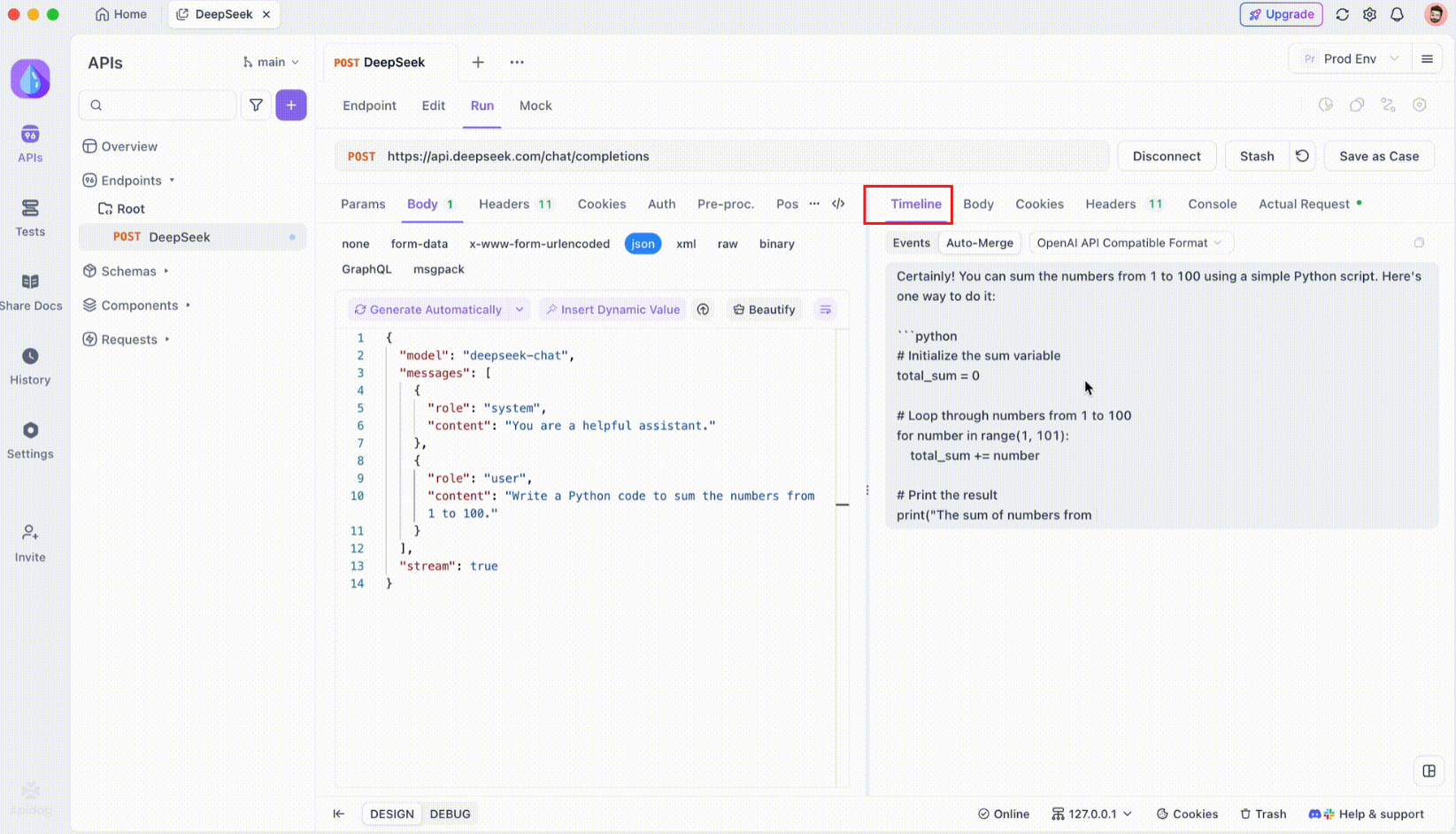
Etapa 4: Auto-Merge Mensagem
Aqui é onde a mágica acontece. Com as melhorias de Auto-Merge, o Apidog reconhece automaticamente os formatos populares de modelos de IA e mescla respostas fragmentadas de SSE em uma resposta completa. Esta etapa inclui:
- Reconhecimento Automático: O Apidog verifica se a resposta está em um formato suportado (OpenAI, Gemini ou Claude).
- Mesclagem de Mensagem: Se o formato for reconhecido, a plataforma combina automaticamente todos os fragmentos de SSE, fornecendo uma resposta completa e contínua.
- Visualização Aprimorada: Para certos modelos de IA, como o DeepSeek R1, a linha do tempo também exibe o processo de pensamento do modelo, oferecendo uma camada extra de insight sobre o raciocínio por trás da resposta gerada.
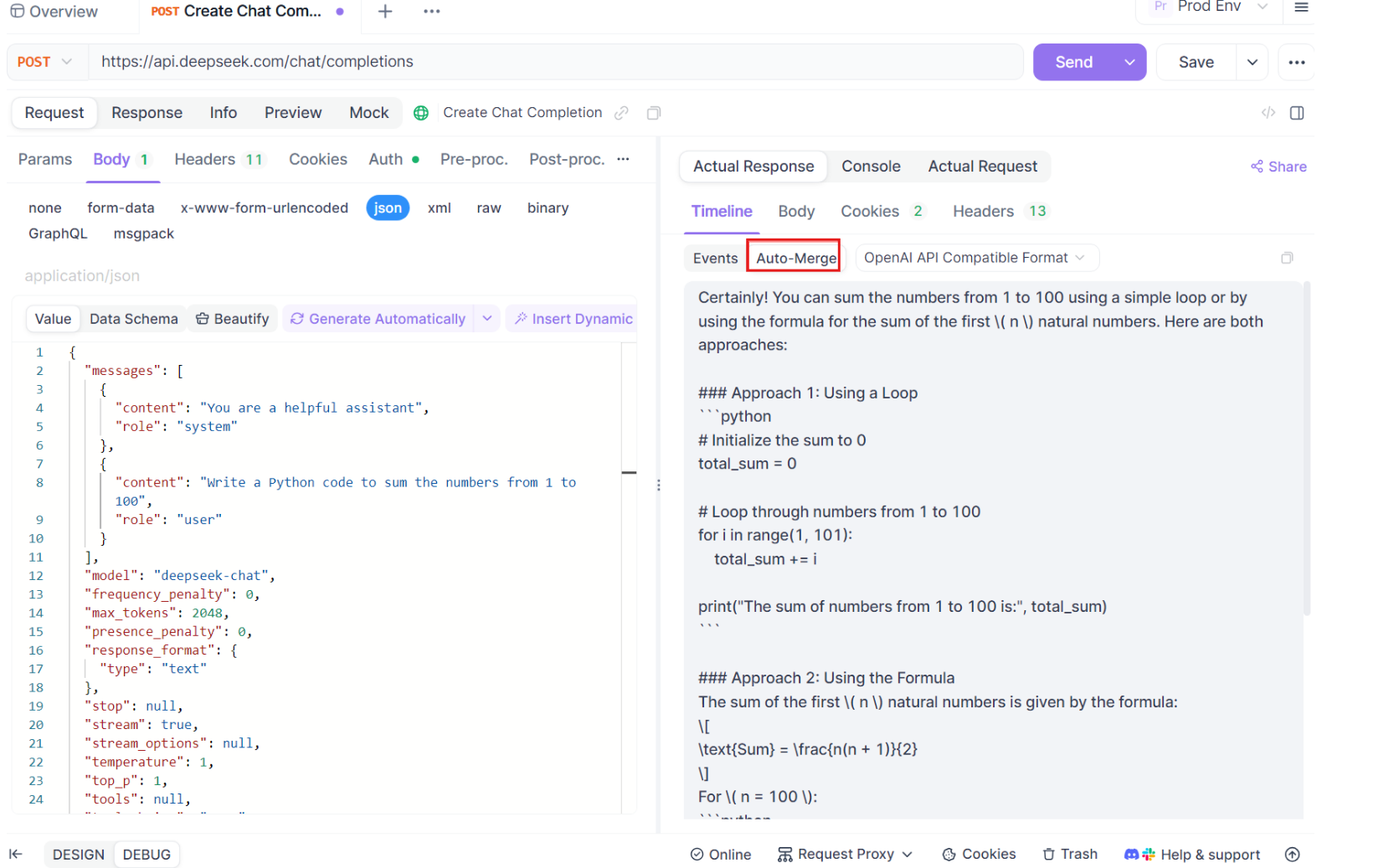
Essa funcionalidade é particularmente útil ao lidar com aplicações movidas por IA, garantindo que cada parte da resposta seja capturada e apresentada em sua totalidade sem intervenção manual.
Etapa 5: Configure regras de extração JSONPath
Nem todas as respostas SSE se conformarão automaticamente a formatos embutidos. Ao lidar com respostas JSON que requerem extração personalizada, o Apidog permite que você configure regras JSONPath. Por exemplo, se sua resposta SSE bruta contém um objeto JSON e você precisa extrair o campo content, você pode configurar uma configuração JSONPath da seguinte forma:
- JSONPath:
$.choices[0].message.content - Explicação:
$refere-se à raiz do objeto JSON.choices[0]seleciona o primeiro elemento do arraychoices.message.contentespecifica o campo de conteúdo dentro do objeto de mensagem.
Essa configuração instrui o Apidog sobre como extrair os dados desejados de sua resposta SSE, garantindo que até mesmo respostas não padronizadas sejam tratadas de forma eficaz.
Conclusão
Executar o Gemma 3 localmente com o Ollama é uma maneira empolgante de aproveitar as capacidades avançadas de IA do Google sem sair da sua máquina. Desde a instalação do Ollama e download do modelo até a interação pelo terminal ou API, este guia o orientou por cada etapa. Com seus recursos multimodais, suporte multilíngue e desempenho impressionante, o Gemma 3 é um divisor de águas para desenvolvedores e entusiastas de IA. Não se esqueça de aproveitar ferramentas como o Apidog para testes e integração de API sem costura - baixe gratuitamente hoje para aprimorar seus projetos com o Gemma 3!
Seja você experimentando com o modelo de 1B em um laptop ou levando ao limite o modelo de 27B em um rig de GPU, você está agora pronto para explorar as possibilidades. Boa codificação e vamos ver que coisas incríveis você cria com o Gemma 3!