
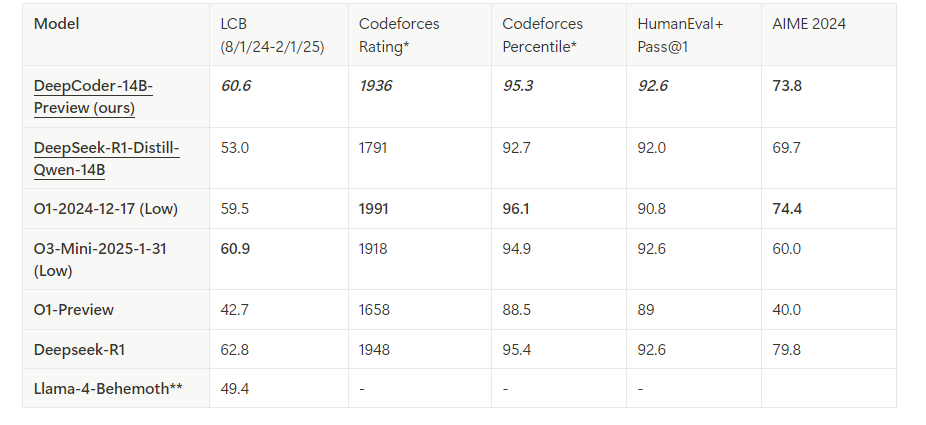
Executar modelos de codificação avançados localmente capacita os desenvolvedores a aproveitar IA de ponta sem depender de serviços em nuvem. DeepCoder, um modelo de codificação totalmente aberto com 14 bilhões de parâmetros, oferece desempenho excepcional comparável ao O3-mini. Quando combinado com Ollama, uma estrutura leve para executar modelos de linguagem grandes (LLMs), você pode implantar o DeepCoder de forma eficiente em sua máquina. Este guia técnico orienta você pelo processo, desde a configuração até a execução, enquanto integra ferramentas como Apidog para testes de API.
O que é DeepCoder?
DeepCoder é um modelo de codificação de código aberto com 14 bilhões de parâmetros, desenvolvido por meio de uma colaboração entre a Agentica e a Together AI. Construído ao ajustar o Deepseek-R1-Distilled-Qwen-14B com aprendizado por reforço distribuído (RL), ele se destaca em tarefas de raciocínio e geração de código. Além disso, existe uma versão menor de 1,5B para ambientes com recursos limitados. Ao contrário dos modelos proprietários, a natureza de código aberto do DeepCoder permite total transparência e personalização, tornando-o um favorito entre os desenvolvedores.
Ollama, por outro lado, simplifica a implantação de LLMs como o DeepCoder. Ele fornece um runtime leve e uma API para integração perfeita nos fluxos de trabalho de desenvolvimento. Combinando essas ferramentas, você desbloqueia um poderoso assistente de codificação local.
Pré-requisitos para Executar o DeepCoder Localmente
Antes de prosseguir, certifique-se de que seu sistema atende aos requisitos. Aqui está o que você precisa:
Hardware:
- Uma máquina com pelo menos 32 GB de RAM (64 GB recomendado para o modelo de 14B).
- Uma GPU moderna (por exemplo, NVIDIA RTX 3090 ou melhor) com 24 GB+ de VRAM para desempenho ideal.
- Alternativamente, uma CPU com núcleos suficientes (por exemplo, Intel i9 ou AMD Ryzen 9) funciona para o modelo de 1,5B.
Software:
- Sistema Operacional: Linux (Ubuntu 20.04+), macOS ou Windows (via WSL2).
- Git: Para clonar repositórios.
- Docker (opcional): Para implantação em contêineres.
- Python 3.9+: Para scripts e interações de API.
Dependências:
- Ollama: Instalado e configurado.
- Arquivos do modelo DeepCoder: Baixados da biblioteca oficial do Ollama.
Com isso em mente, você está pronto para instalar e configurar o ambiente.
Passo 1: Instale o Ollama em Sua Máquina
Ollama serve como a espinha dorsal para executar o DeepCoder localmente. Siga estas etapas para instalá-lo:
Baixe o Ollama:
Acesse o site oficial do Ollama ou use um gerenciador de pacotes. Para Linux, execute:
curl -fsSL https://ollama.com/install.sh | sh
No macOS, use o Homebrew:
brew install ollama
Verifique a Instalação:
Verifique a versão para confirmar se o Ollama foi instalado corretamente:
ollama --version

Inicie o Serviço Ollama:
Inicie o Ollama em segundo plano:
ollama serve &
Isso executa o servidor em localhost:11434, expondo uma API para interações com o modelo.
Ollama agora está operacional. Em seguida, você buscará o modelo DeepCoder.
Passo 2: Baixe o DeepCoder da Biblioteca do Ollama
O DeepCoder está disponível na biblioteca de modelos do Ollama. Aqui está como baixá-lo:
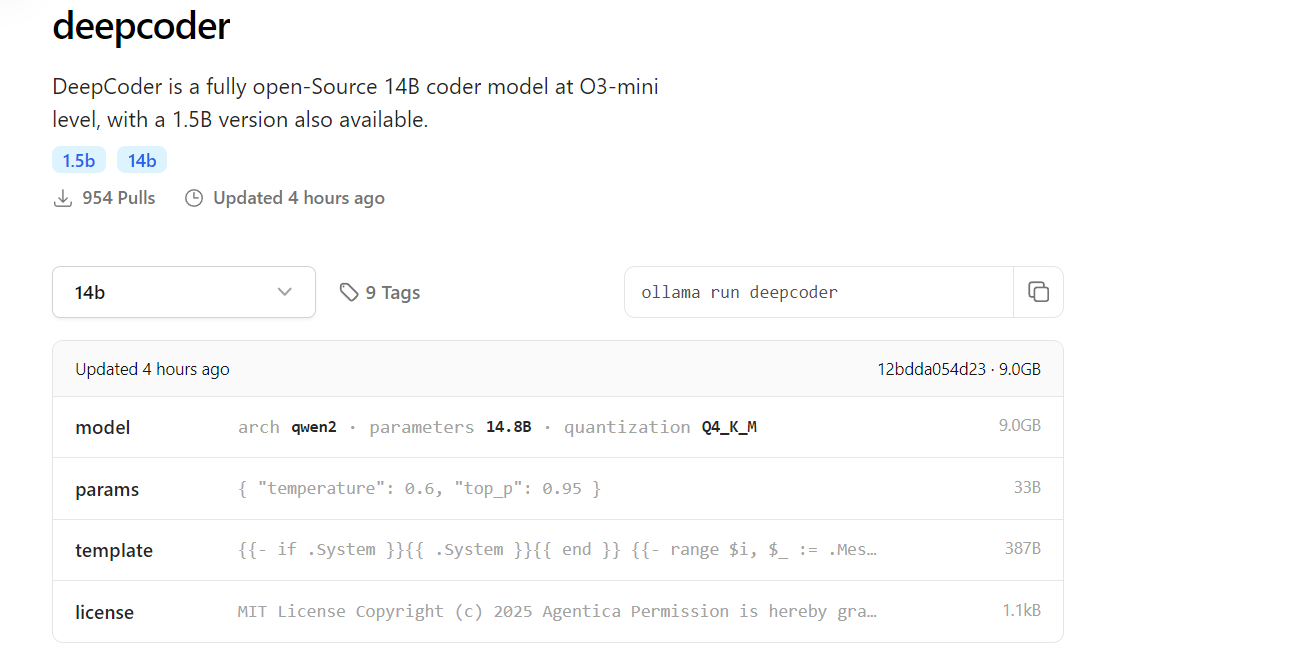
Baixe o DeepCoder:
Baixe o modelo de 14B (ou 1,5B para configurações mais leves):
ollama pull deepcoder

Este comando busca a versão etiquetada mais recente. Para uma etiqueta específica, use:
ollama pull deepcoder:14b-preview
Monitore o Progresso do Download:
O processo transmite atualizações, mostrando resumos de arquivo e status de conclusão. Espere um download de vários gigabytes para o modelo de 14B, então certifique-se de uma conexão de internet estável.
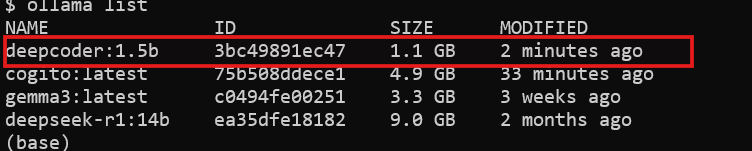
Verifique a Instalação:
Verifique se o DeepCoder está disponível:
ollama list
Você verá deepcoder listado entre os modelos instalados.
Com o DeepCoder baixado, você está pronto para executá-lo.
Passo 3: Execute o DeepCoder Localmente com o Ollama
Agora, execute o DeepCoder e teste suas capacidades:
Inicie o DeepCoder:
Inicie o modelo em uma sessão interativa:
ollama run deepcoder
Isso abre um prompt onde você pode inserir consultas de codificação.
Ajuste os Parâmetros (Opcional):
Para uso avançado, ajuste configurações como temperatura por meio de um arquivo de configuração ou chamada de API (abordado mais adiante).
O DeepCoder está agora rodando localmente. No entanto, para integrá-lo aos fluxos de trabalho, você usará sua API.
Passo 4: Interaja com o DeepCoder via API do Ollama
O Ollama expõe uma API RESTful para acesso programático. Aqui está como aproveitá-la:
Verifique a Disponibilidade da API:
Certifique-se de que o servidor Ollama está em execução:
curl http://localhost:11434
Uma resposta confirma que o servidor está ativo.
Envie uma Solicitação:
Use curl para consultar o DeepCoder:
curl http://localhost:11434/api/generate -d '{
"model": "deepcoder",
"prompt": "Gere um endpoint de API REST em Flask",
"stream": false
}'
A resposta inclui o código gerado, como:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api/data', methods=['GET'])
def get_data():
return jsonify({"message": "Olá, Mundo!"})
if __name__ == "__main__":
app.run(debug=True)
Integre com Python:
Use a biblioteca requests do Python para uma interação mais limpa:
import requests
url = "http://localhost:11434/api/generate"
payload = {
"model": "deepcoder",
"prompt": "Escreva uma API Node.js Express",
"stream": False
}
response = requests.post(url, json=payload)
print(response.json()["response"])
A API desbloqueia o potencial de automação e integração do DeepCoder.
Passo 5: Aprimore os Testes de API com o Apidog
O DeepCoder se destaca na geração de código de API, mas testar essas APIs é crucial. O Apidog simplifica esse processo:
Instale o Apidog:
Baixe e instale o Apidog a partir de seu site oficial.
Teste a API Gerada:
Pegue o endpoint Flask de antes. No Apidog:
- Crie uma nova solicitação.
- Defina a URL como
http://localhost:5000/api/datae envie uma solicitação GET.
- Verifique a resposta:
{"message": "Olá, Mundo!"}.
Automatize os Testes:
Use a scriptagem do Apidog para automatizar a validação, garantindo que a saída do DeepCoder atenda às expectativas.
O Apidog conecta a geração de código à implementação, aumentando a produtividade.
Passo 6: Otimize o Desempenho do DeepCoder
Para maximizar a eficiência, ajuste a configuração do DeepCoder:
Aceleração de GPU:
Certifique-se de que o Ollama está descarregando cálculos para sua GPU. Verifique com:
nvidia-smi
O uso da GPU indica aceleração bem-sucedida.
Gerenciamento de Memória:
Para o modelo de 14B, aloque VRAM suficiente. Ajuste o espaço de swap no Linux se necessário:
sudo fallocate -l 32G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
Quantização do Modelo:
Use uma quantização menor (por exemplo, 4 bits) para o modelo de 1,5B:
ollama pull deepcoder:1.5b-q4
Essas adaptações garantem que o DeepCoder funcione suavemente em seu hardware.
Por que Escolher o DeepCoder com Ollama?
Executar o DeepCoder localmente oferece vantagens distintas:
- Privacidade: Mantenha código sensível fora de servidores em nuvem.
- Custo: Evite taxas de assinatura.
- Personalização: Adapte o modelo às suas necessidades.
Combiná-lo com a estrutura leve do Ollama e as capacidades de teste do Apidog cria um ecossistema de desenvolvimento poderoso e autossuficiente.
Conclusão
Configurar o DeepCoder localmente com o Ollama é simples, mas transformador. Você instala o Ollama, baixa o DeepCoder, executa-o e o integra via API—tudo em poucas etapas. Ferramentas como o Apidog aprimoram ainda mais a experiência, garantindo que as APIs geradas funcionem perfeitamente. Seja você um desenvolvedor solo ou parte de uma equipe, essa configuração oferece um assistente de codificação robusto e de código aberto.