
A equipe Qwen da Alibaba mais uma vez ultrapassou os limites da inteligência artificial com o lançamento do modelo Qwen2.5-VL-32B-Instruct, um modelo inovador de visão-linguagem (VLM) que promete ser mais inteligente e leve.
Anunciado em 24 de março de 2025, este modelo de 32 bilhões de parâmetros encontra um equilíbrio ideal entre desempenho e eficiência, tornando-se uma escolha ideal para desenvolvedores e pesquisadores. Construindo sobre o sucesso da série Qwen2.5-VL, esta nova iteração apresenta avanços significativos em raciocínio matemático, alinhamento de preferências humanas e tarefas visuais, tudo isso mantendo um tamanho gerenciável para a implementação local.
Para desenvolvedores ansiosos para integrar este poderoso modelo em seus projetos, explorar ferramentas robustas de API é essencial. É por isso que recomendamos baixar o Apidog gratuitamente — uma plataforma de desenvolvimento de API amigável que simplifica o teste e a integração de modelos como o Qwen em suas aplicações. Com o Apidog, você pode interagir com a API do Qwen de forma fluida, otimizar fluxos de trabalho e desbloquear todo o potencial deste VLM inovador. Baixe o Apidog hoje e comece a construir aplicações mais inteligentes!
Esta ferramenta de API permite que você teste e depure os pontos finais do seu modelo sem esforço. Baixe o Apidog gratuitamente hoje e otimize seu fluxo de trabalho enquanto explora as capacidades do Mistral Small 3.1!
Qwen2.5-VL-32B: Um Modelo de Visão-Linguagem Mais Inteligente
O que Torna o Qwen2.5-VL-32B Único?
O Qwen2.5-VL-32B se destaca como um modelo de visão-linguagem de 32 bilhões de parâmetros projetado para abordar as limitações de modelos maiores e menores da família Qwen. Embora modelos de 72 bilhões de parâmetros, como o Qwen2.5-VL-72B, ofereçam capacidades robustas, eles geralmente exigem recursos computacionais significativos, tornando-os impraticáveis para implementação local. Em contrapartida, modelos de 7 bilhões de parâmetros, embora mais leves, podem carecer da profundidade necessária para tarefas complexas. O Qwen2.5-VL-32B preenche essa lacuna ao oferecer alto desempenho com uma pegada mais gerenciável.
Este modelo se baseia na série Qwen2.5-VL, que ganhou ampla aclamação por suas capacidades multimodais. No entanto, o Qwen2.5-VL-32B introduz melhorias críticas, incluindo otimização por meio de aprendizado por reforço (RL). Essa abordagem melhora o alinhamento do modelo com as preferências humanas, garantindo saídas mais detalhadas e amigáveis ao usuário. Além disso, o modelo demonstrou raciocínio matemático superior, uma característica vital para tarefas que envolvem resolução de problemas complexos e análise de dados.

Principais Melhorias Técnicas
O Qwen2.5-VL-32B utiliza aprendizado por reforço para refinar seu estilo de saída, tornando as respostas mais coerentes, detalhadas e formatadas para uma melhor interação humana. Além disso, suas capacidades de raciocínio matemático tiveram melhorias significativas, como evidenciado por seu desempenho em benchmarks como MathVista e MMMU. Essas melhorias decorrem de processos de treinamento ajustados que priorizam a precisão e a dedução lógica, particularmente em contextos multimodais onde texto e dados visuais se cruzam.
O modelo também se destaca na compreensão e raciocínio de imagens de forma detalhada, permitindo a análise precisa de conteúdo visual, como gráficos, diagramas e documentos. Essa capacidade posiciona o Qwen2.5-VL-32B como um forte concorrente para aplicações que exigem dedução lógica visual avançada e reconhecimento de conteúdo.
Benchmarks de Desempenho do Qwen2.5-VL-32B: Superando Modelos Maiores
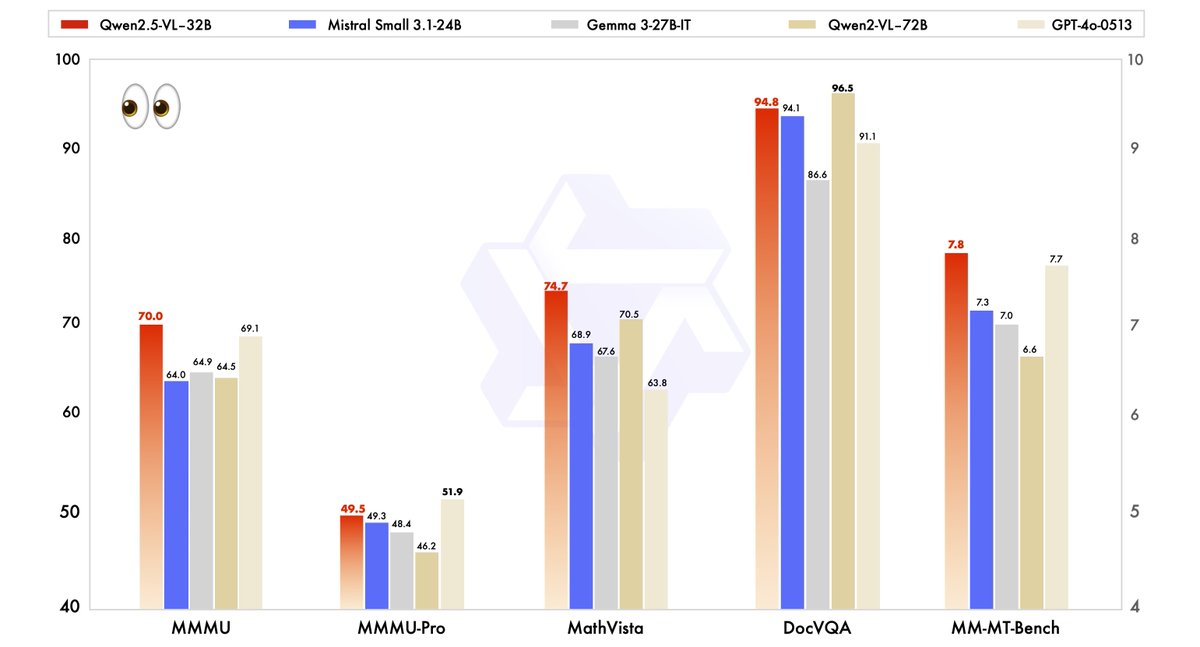
O desempenho do Qwen2.5-VL-32B foi rigorosamente avaliado em relação a modelos de última geração, incluindo seu irmão maior, Qwen2.5-VL-72B, bem como concorrentes como Mistral-Small-3.1–24B e Gemma-3–27B-IT. Os resultados destacam a superioridade do modelo em várias áreas-chave.
- MMMU (Massive Multitask Language Understanding): O Qwen2.5-VL-32B alcança uma pontuação de 70.0, superando os 64.5 do Qwen2.5-VL-72B. Este benchmark testa raciocínio complexo e de múltiplas etapas em diversas tarefas, demonstrando as capacidades cognitivas aprimoradas do modelo.
- MathVista: Com uma pontuação de 74.7, o Qwen2.5-VL-32B supera os 70.5 do Qwen2.5-VL-72B, sublinhando sua força em tarefas de raciocínio matemático e visual.
- MM-MT-Bench: Este benchmark de avaliação subjetiva da experiência do usuário mostra o Qwen2.5-VL-32B liderando seu predecessor por uma margem significativa, refletindo um melhor alinhamento de preferências humanas.
- Tarefas Baseadas em Texto (por exemplo, MMLU, MATH, HumanEval): O modelo compete efetivamente com modelos maiores como GPT-4o-Mini, alcançando pontuações de 78.4 no MMLU, 82.2 no MATH e 91.5 no HumanEval, apesar de seu menor número de parâmetros.
Esses benchmarks ilustram que o Qwen2.5-VL-32B não só iguala, mas muitas vezes supera o desempenho de modelos maiores, tudo isso enquanto requer menos recursos computacionais. Esse equilíbrio entre potência e eficiência torna-o uma opção atraente para desenvolvedores e pesquisadores que trabalham com hardware limitado.
Por que o Tamanho Importa: A Vantagem de 32B
O tamanho de 32 bilhões de parâmetros do Qwen2.5-VL-32B encontra um ponto ideal para a implementação local. Ao contrário dos modelos de 72B, que exigem extensos recursos de GPU, este modelo mais leve integra-se perfeitamente com motores de inferência como SGLang e vLLM, conforme observado em resultados da web relacionados. Essa compatibilidade garante uma implementação mais rápida e menor uso de memória, tornando-o acessível para uma variedade mais ampla de usuários, desde startups até grandes empresas.
Além disso, a otimização do modelo para velocidade e eficiência não compromete suas capacidades. Sua habilidade de lidar com tarefas multimodais — como reconhecer objetos, analisar gráficos e processar saídas estruturadas como faturas e tabelas — permanece robusta, posicionando-o como uma ferramenta versátil para aplicações do mundo real.

Executando o Qwen2.5-VL-32B Localmente com MLX
Para executar este poderoso modelo localmente no seu Mac com Apple Silicon, siga estes passos:
Requisitos do Sistema
- Um Mac com Apple Silicon (chip M1, M2 ou M3)
- Pelo menos 32GB de RAM (64GB recomendado)
- 60GB+ de espaço livre em disco
- macOS Sonoma ou mais recente
Passos para Instalação
- Instale as dependências do Python
pip install mlx mlx-llm transformers pillow
- Baixe o modelo
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- Converta o modelo para o formato MLX
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- Crie um script simples para interagir com o modelo
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# Carregue o modelo
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# Carregue uma imagem
image = Image.open("caminho/para/sua/imagem.jpg")
# Crie um prompt com a imagem
prompt = "O que você vê nesta imagem?"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
Aplicações Práticas: Aproveitando o Qwen2.5-VL-32B
Tarefas Visuais e Além
As capacidades visuais avançadas do Qwen2.5-VL-32B abrem portas para uma ampla gama de aplicações. Por exemplo, ele pode atuar como um agente visual, interagindo dinamicamente com interfaces de computador ou telefone para realizar tarefas como navegação ou extração de dados. Sua capacidade de entender vídeos longos (de até uma hora) e identificar segmentos relevantes aumenta ainda mais sua utilidade em análises de vídeo e localizações temporais.
No processamento de documentos, o modelo se destaca ao processar conteúdo multi-cena e multilíngue, incluindo texto manuscrito, tabelas, gráficos e fórmulas químicas. Isso o torna inestimável para indústrias como finanças, educação e saúde, onde a extração precisa de dados estruturados é crítica.
Raciocínio Textual e Matemático
Além das tarefas visuais, o Qwen2.5-VL-32B brilha em aplicações baseadas em texto, particularmente aquelas que envolvem raciocínio matemático e codificação. Suas altas pontuações em benchmarks como MATH e HumanEval indicam sua proficiência em resolver problemas algébricos complexos, interpretar gráficos de funções e gerar trechos de código precisos. Essa dupla proficiência em visão e texto posiciona o Qwen2.5-VL-32B como uma solução holística para desafios de IA multimodal.

Onde Você Pode Usar o Qwen2.5-VL-32B
Acesso Open-Source e API
O Qwen2.5-VL-32B está disponível sob a licença Apache 2.0, tornando-o open-source e acessível a desenvolvedores em todo o mundo. Você pode acessar o modelo por meio de várias plataformas:
- Hugging Face: O modelo está hospedado no Hugging Face, onde você pode baixá-lo para uso local ou integrá-lo via a biblioteca Transformers.
- ModelScope: A plataforma ModelScope da Alibaba oferece outra via para acessar e implantar o modelo.
Para uma integração sem costura, os desenvolvedores podem usar a API do Qwen, que simplifica a interação com o modelo. Se você está construindo uma aplicação personalizada ou experimentando com tarefas multimodais, a API do Qwen garante conectividade eficiente e desempenho robusto.
Implantação com Motores de Inferência
O Qwen2.5-VL-32B suporta implantação com motores de inferência como SGLang e vLLM. Essas ferramentas otimizam o modelo para inferência rápida, reduzindo a latência e o uso de memória. Ao aproveitar esses motores, os desenvolvedores podem implantar o modelo em hardware local ou plataformas em nuvem, adaptando-o a casos de uso específicos.
Para começar, instale as bibliotecas necessárias (por exemplo, transformers, vllm) e siga as instruções na página do GitHub do Qwen ou na documentação do Hugging Face. Esse processo garante uma integração suave, permitindo que você aproveite todo o potencial do modelo.
Otimizando o Desempenho Local
Ao executar o Qwen2.5-VL-32B localmente, considere estas dicas de otimização:
- Quantização: Adicione a flag
--quantizedurante a conversão para reduzir os requisitos de memória. - Gerencie o comprimento do contexto: Limite os tokens de entrada para respostas mais rápidas.
- Feche aplicativos que consomem muitos recursos ao executar o modelo.
- Processamento em lote: Para várias imagens, processe-as em lotes em vez de individualmente.
Conclusão: Por que o Qwen2.5-VL-32B é Importante
O Qwen2.5-VL-32B representa um marco significativo na evolução dos modelos de visão-linguagem. Ao combinar raciocínio mais inteligente, requisitos de recursos mais leves e desempenho robusto, este modelo de 32 bilhões de parâmetros atende às necessidades de desenvolvedores e pesquisadores. Seus avanços em raciocínio matemático, alinhamento de preferências humanas e tarefas visuais o posicionam como uma escolha principal para a implantação local e aplicações do mundo real.
Seja construindo ferramentas educacionais, sistemas de inteligência empresarial ou soluções de suporte ao cliente, o Qwen2.5-VL-32B oferece a versatilidade e eficiência necessárias. Com acesso por meio de plataformas open-source e da API do Qwen, integrar este modelo em seus projetos nunca foi tão fácil. À medida que a equipe do Qwen continua a inovar, podemos esperar desenvolvimentos ainda mais empolgantes no futuro da IA multimodal.
Esta ferramenta de API permite que você teste e depure os pontos finais do seu modelo sem esforço. Baixe o Apidog gratuitamente hoje e otimize seu fluxo de trabalho enquanto explora as capacidades do Mistral Small 3.1!