
Bem-vindo! Se você já se perguntou como aproveitar ferramentas de IA de ponta para raspagem de dados e análise de conteúdo, então você está no lugar certo. Hoje, vamos mergulhar em um projeto empolgante que combina OpenAI SWARM, Streamlit e sistemas multiagentes para tornar a raspagem de dados mais inteligente e a análise de conteúdo mais perspicaz. Também exploraremos como o Apidog pode simplificar os testes de API e servir como uma alternativa mais acessível para suas necessidades de API.
Agora, vamos começar a construir um sistema totalmente funcional de raspagem de dados e análise de conteúdo!
1. O que é OpenAI SWARM?
OpenAI SWARM é uma abordagem emergente para aproveitar a IA e sistemas multiagentes para automatizar várias tarefas, incluindo raspagem de dados e análise de conteúdo. Em sua essência, o SWARM foca em usar múltiplos agentes que podem trabalhar de forma independente ou colaborar em tarefas específicas para alcançar um objetivo comum.

Como o SWARM Funciona
Imagine que você deseja raspar múltiplos sites para coletar dados para análise. Usar um único bot de raspagem pode funcionar, mas está sujeito a gargalos, erros ou até ser bloqueado pelo site. SWARM, no entanto, permite que você implante vários agentes para abordar diferentes aspectos da tarefa—alguns agentes se concentram na extração de dados, outros na limpeza de dados, e outros ainda na transformação dos dados para análise. Esses agentes podem se comunicar entre si, garantindo um manuseio eficiente das tarefas.
Ao combinar os poderosos modelos de linguagem da OpenAI e as metodologias do SWARM, você pode construir sistemas inteligentes e adaptativos que imitam a resolução de problemas humanos. Usaremos técnicas do SWARM para uma raspagem de dados mais inteligente e processamento de dados neste tutorial.
2. Introdução aos Sistemas Multiagentes
Um sistema multiagente (MAS) é uma coleção de agentes autônomos que interagem em um ambiente compartilhado para resolver problemas complexos. Os agentes podem realizar tarefas em paralelo, tornando os MAS ideais para situações onde dados precisam ser coletados de várias fontes ou diferentes estágios de processamento são necessários.
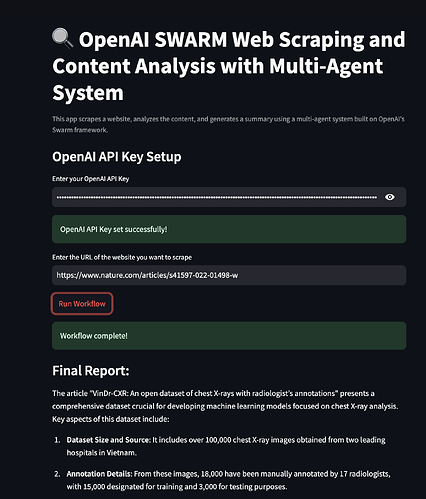
No contexto da raspagem de dados, um sistema multiagente pode envolver agentes para:
- Extração de Dados: Raspagem de diferentes páginas web para coletar dados relevantes.
- Processamento de Conteúdo: Limpeza e organização dos dados para análise.
- Análise de Dados: Aplicação de algoritmos para derivar insights dos dados coletados.
- Relatórios: Apresentação dos resultados em um formato amigável ao usuário.
Por que usar Sistemas Multiagentes para Raspagem de Dados?
Sistemas multiagentes são robustos contra falhas e podem operar de forma assíncrona. Isso significa que, mesmo se um agente falhar ou encontrar um problema, os demais podem continuar suas tarefas. A abordagem SWARM, portanto, garante maior eficiência, escalabilidade e tolerância a falhas em projetos de raspagem de dados.
3. Streamlit: Uma Visão Geral
Streamlit é uma popular biblioteca Python de código aberto que facilita a criação e compartilhamento de aplicações web personalizadas para análise de dados, aprendizado de máquina e projetos de automação. Ela fornece uma estrutura onde você pode construir interfaces interativas sem ter experiência em front-end.
Por que Streamlit?
- Facilidade de Uso: Escreva código em Python, e Streamlit o converte em uma interface web amigável.
- Prototipagem Rápida: Permite testes e implantação rápidas de novas ideias.
- Integração com Modelos de IA: Integra-se perfeitamente com bibliotecas e APIs de aprendizado de máquina.
- Personalização: Flexível o suficiente para construir aplicativos sofisticados para diferentes casos de uso.
Em nosso projeto, usaremos o Streamlit para visualizar os resultados da raspagem de dados, exibir métricas de análise de conteúdo e criar uma interface interativa para controlar nosso sistema multiagente.
4. Por que o Apidog é um divisor de águas
Apidog é uma alternativa robusta aos tradicionais ferramentas de desenvolvimento e teste de API. Ele suporta todo o ciclo de vida da API, desde o design até os testes e implantação, tudo dentro de uma plataforma unificada.
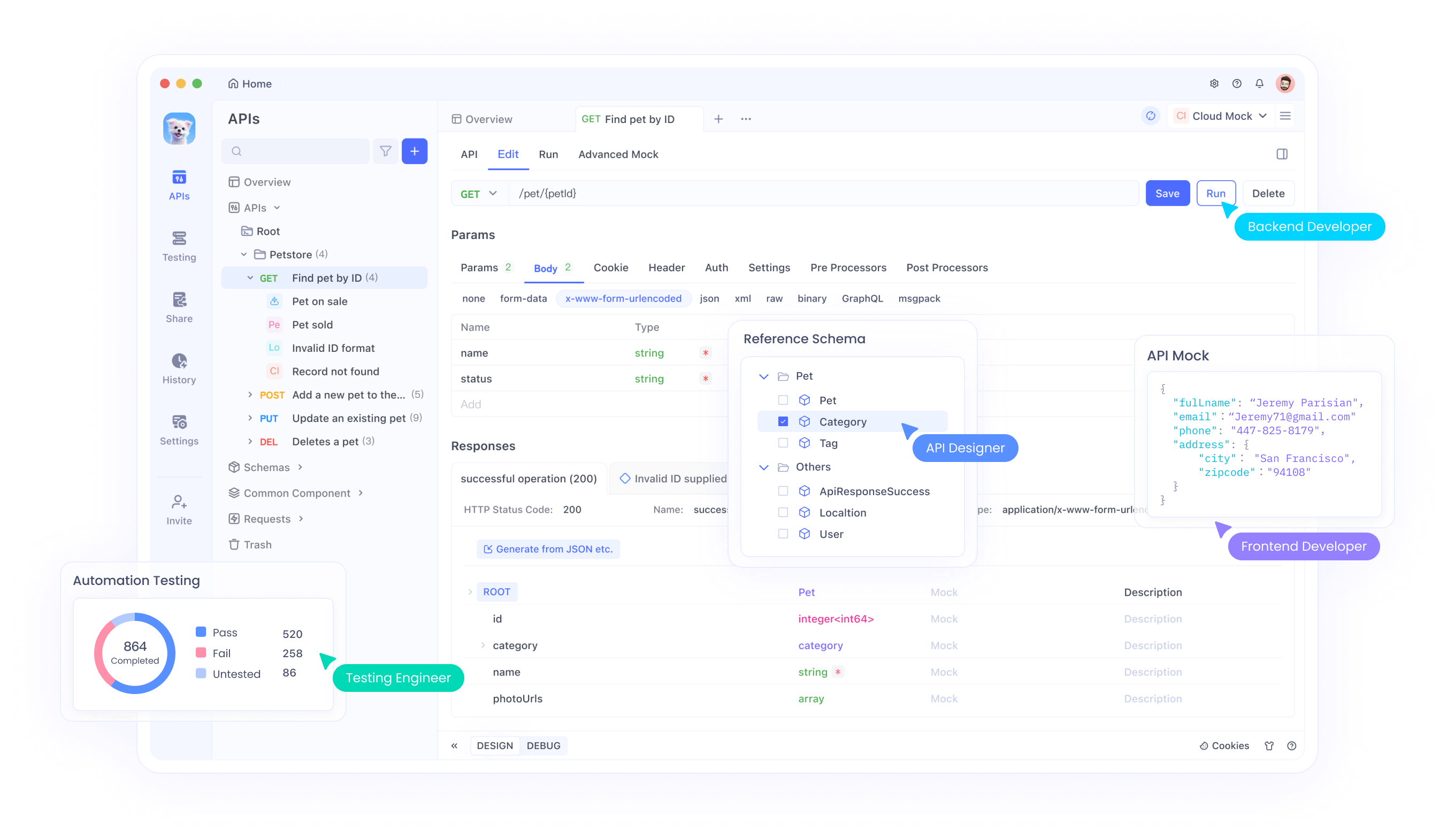
Principais Recursos do Apidog:
- Interface Amigável: Design de API fácil de usar, arrastando e soltando.
- Testes Automatizados: Realização de testes abrangentes de API sem escrever scripts adicionais.
- Documentação Integrada: Geração automática de documentação detalhada da API.
- Planos de Preços Mais Baratos: Oferece uma opção mais acessível em comparação com concorrentes.
O Apidog é uma combinação perfeita para projetos onde a integração e o teste de API são essenciais, tornando-se uma solução econômica e abrangente.
Baixe o Apidog gratuitamente para vivenciar esses benefícios em primeira mão.
5. Configurando Seu Ambiente de Desenvolvimento
Antes de mergulhar no código, vamos garantir que nosso ambiente esteja pronto. Você precisará:
- Python 3.7+
- Streamlit: Instale com
pip install streamlit - BeautifulSoup para raspagem de dados: Instale com
pip install beautifulsoup4 - Requests: Instale com
pip install requests - Apidog: Para testes de API, você pode baixá-lo do site oficial do Apidog
Certifique-se de que você tem tudo instalado. Agora, vamos configurar o ambiente.
6. Construindo um Sistema Multiagente para Raspagem de Dados
Vamos construir um sistema multiagente para raspagem de dados usando OpenAI SWARM e bibliotecas Python. O objetivo aqui é criar múltiplos agentes para realizar tarefas como raspagem, processamento e análise de dados de vários sites.
Passo 1: Definindo os Agentes
Vamos criar agentes para diferentes tarefas:
- Agente Raspador: Coleta HTML bruto de páginas web.
- Agente Parser: Extrai informações significativas.
- Agente de Análise: Processa os dados em busca de insights.
Aqui está como você pode definir um simples CrawlerAgent em Python:
import requests
from bs4 import BeautifulSoup
class CrawlerAgent:
def __init__(self, url):
self.url = url
def fetch_content(self):
try:
response = requests.get(self.url)
if response.status_code == 200:
return response.text
else:
print(f"Falha ao buscar conteúdo de {self.url}")
except Exception as e:
print(f"Erro: {str(e)}")
return None
crawler = CrawlerAgent("https://example.com")
html_content = crawler.fetch_content()
Passo 2: Adicionando um Agente Parser
O ParserAgent irá limpar e estruturar o HTML bruto:
class ParserAgent:
def __init__(self, html_content):
self.html_content = html_content
def parse(self):
soup = BeautifulSoup(self.html_content, 'html.parser')
parsed_data = soup.find_all('p') # Exemplo: Extraindo todos os parágrafos
return [p.get_text() for p in parsed_data]
parser = ParserAgent(html_content)
parsed_data = parser.parse()
Passo 3: Adicionando um Agente de Análise
Este agente aplicará técnicas de processamento de linguagem natural (NLP) para analisar o conteúdo.
from collections import Counter
class AnalyzerAgent:
def __init__(self, text_data):
self.text_data = text_data
def analyze(self):
word_count = Counter(" ".join(self.text_data).split())
return word_count.most_common(10) # Exemplo: 10 palavras mais comuns
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
print(analysis_result)
7. Análise de Conteúdo com SWARM e Streamlit
Agora que temos os agentes trabalhando juntos, vamos visualizar os resultados usando Streamlit.
Passo 1: Criando um Aplicativo Streamlit
Comece importando o Streamlit e configurando a estrutura básica do aplicativo:
import streamlit as st
st.title("Raspagem de Dados e Análise de Conteúdo com Sistemas Multiagentes")
st.write("Usando OpenAI SWARM e Streamlit para extração de dados mais inteligente.")
Passo 2: Integrando Agentes
Vamos integrar nossos agentes no aplicativo Streamlit, permitindo que os usuários insiram uma URL e vejam os resultados da raspagem e análise.
url = st.text_input("Digite uma URL para raspar:")
if st.button("Raspar e Analisar"):
if url:
crawler = CrawlerAgent(url)
html_content = crawler.fetch_content()
if html_content:
parser = ParserAgent(html_content)
parsed_data = parser.parse()
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
st.subheader("10 Palavras Mais Comuns")
st.write(analysis_result)
else:
st.error("Falha ao buscar conteúdo. Por favor, tente uma URL diferente.")
else:
st.warning("Por favor, insira uma URL válida.")
Passo 3: Implantando o Aplicativo
Você pode implantar o aplicativo usando o comando:
streamlit run your_script_name.py

8. Testando APIs com Apidog
Agora, vamos ver como o Apidog pode ajudar com os testes de APIs em nossa aplicação de raspagem de dados.
Passo 1: Configurando o Apidog
Baixe e instale o Apidog do site oficial do Apidog. Siga o guia de instalação para configurar o ambiente.
Passo 2: Criando Solicitações de API
Você pode criar e testar suas solicitações de API diretamente dentro do Apidog. Ele suporta vários tipos de solicitações, como GET, POST, PUT e DELETE, tornando-o versátil para qualquer cenário de raspagem de dados.
Passo 3: Automatizando Testes de API
Com o Apidog, automatize testes scripts para validar a resposta do seu sistema multiagente ao se conectar a serviços externos. Isso garante que seu sistema permaneça robusto e consistente ao longo do tempo.
9. Implantando sua Aplicação Streamlit
Uma vez que sua aplicação esteja completa, implante-a para acesso público. O Streamlit facilita isso com seu serviço de Streamlit Sharing.
- Hospede seu código no GitHub.
- Navegue para Streamlit Sharing e conecte seu repositório GitHub.
- Implante seu aplicativo com um único clique.
10. Conclusão
Parabéns! Você aprendeu como construir um poderoso sistema de raspagem de dados e análise de conteúdo usando OpenAI SWARM, Streamlit e sistemas multiagentes. Exploramos como as técnicas do SWARM podem tornar a raspagem mais inteligente e a análise de conteúdo mais precisa. Ao integrar o Apidog, você também adquiriu insights sobre testes e validação de APIs para garantir a confiabilidade do seu sistema.
Agora, vá em frente e baixe o Apidog gratuitamente para aprimorar ainda mais seus projetos com poderosos recursos de teste de API. O Apidog se destaca como uma alternativa mais acessível e eficiente em relação a outras soluções, oferecendo uma experiência sem interrupções para desenvolvedores.
Com este tutorial, você está pronto para enfrentar tarefas complexas de raspagem e análise de dados de forma mais eficaz. Boa sorte e boas codificações!