
Sites tradicionais são projetados principalmente com uma marcação legível por humanos, contendo informações excessivas para os bots coletarem. Enquanto isso, os provedores de sites enfrentam problemas com carga de servidor devido ao scraping excessivo por agentes de IA. Para fornecer conteúdo otimizado para LLM, Jeremy Howard, co-fundador da Answer.AI, propôs um arquivo chamado llms.txt.
Nota: A partir de março de 2025, o llms.txt não é uma especificação padronizada. As informações neste artigo podem ficar desatualizadas devido a futuras mudanças.
O que é llms.txt?

Modelos de linguagem grande como ChatGPT, Grok, Claude e Gemini dependem cada vez mais das informações dos sites. Desenvolvimentos recentes como a pesquisa profunda foram projetados para permitir que modelos baseados em agentes naveguem em sites e realizem automaticamente pesquisas em várias etapas. Para que a pesquisa profunda funcione de forma eficaz, é crucial que os agentes de IA recuperem informações de maneira eficiente dos sites.
No entanto, sites tradicionais usam principalmente marcação orientada ao humano, criando muitas barreiras para bots de IA coletarem informações. Elementos como CSS decorativo, anúncios e JavaScript complexo dificultam a extração de informações essenciais. Além disso, os operadores de sites enfrentam um novo problema de aumento da carga do servidor devido ao scraping excessivo por agentes de IA.
Para enfrentar esses desafios e fornecer conteúdo otimizado para LLM, Jeremy Howard, co-fundador da Answer AI, propôs um novo arquivo padrão chamado llms.txt.
O arquivo /llms.txt – llms-txt Uma proposta para padronizar o uso de um arquivo /llms.txt para fornecer informações que ajudem os LLMs a usar um site no momento da inferência.
O formato de llms.txt
llms.txt é um arquivo simples em formato markdown estruturado. Este formato é projetado para ser facilmente entendido tanto por humanos quanto por LLMs, enquanto também é adequado para processamento automatizado. A especificação exige que ele seja colocado no caminho raiz de um site (/llms.txt).
Este arquivo contém informações básicas e orientações sobre o site, juntamente com links para arquivos markdown detalhados. Ele também propõe fornecer versões em markdown de páginas contendo informações úteis para LLMs adicionando .md à URL da página original.
Por exemplo, para um post de blog em https://apidog.com/blog/top-postman-alternative-open-source/
Uma versão markdown estaria disponível em https://apidog.com/blog/top-postman-alternative-open-source.md
A proposta inclui dois arquivos diferentes:
- llms.txt: Um resumo do site, com páginas detalhadas fornecidas via links para arquivos markdown.
- llms-full.txt: Todas as informações sobre todas as páginas de um site compiladas em um único arquivo.
Como exemplo de llms-full.txt, a documentação do Cloudflare compila todo o conteúdo em um único arquivo, resultando em um volume de texto muito grande:
https://developers.cloudflare.com/llms-full.txt
Apidog se destaca como a principal alternativa ao Postman para esse propósito. Para desenvolvedores implementando llms.txt em vários ambientes, o sistema de gerenciamento de ambiente do Apidog prova ser significativamente mais flexível que o do Postman, economizando tempo valioso de desenvolvimento enquanto garante uma implementação consistente desse padrão emergente.
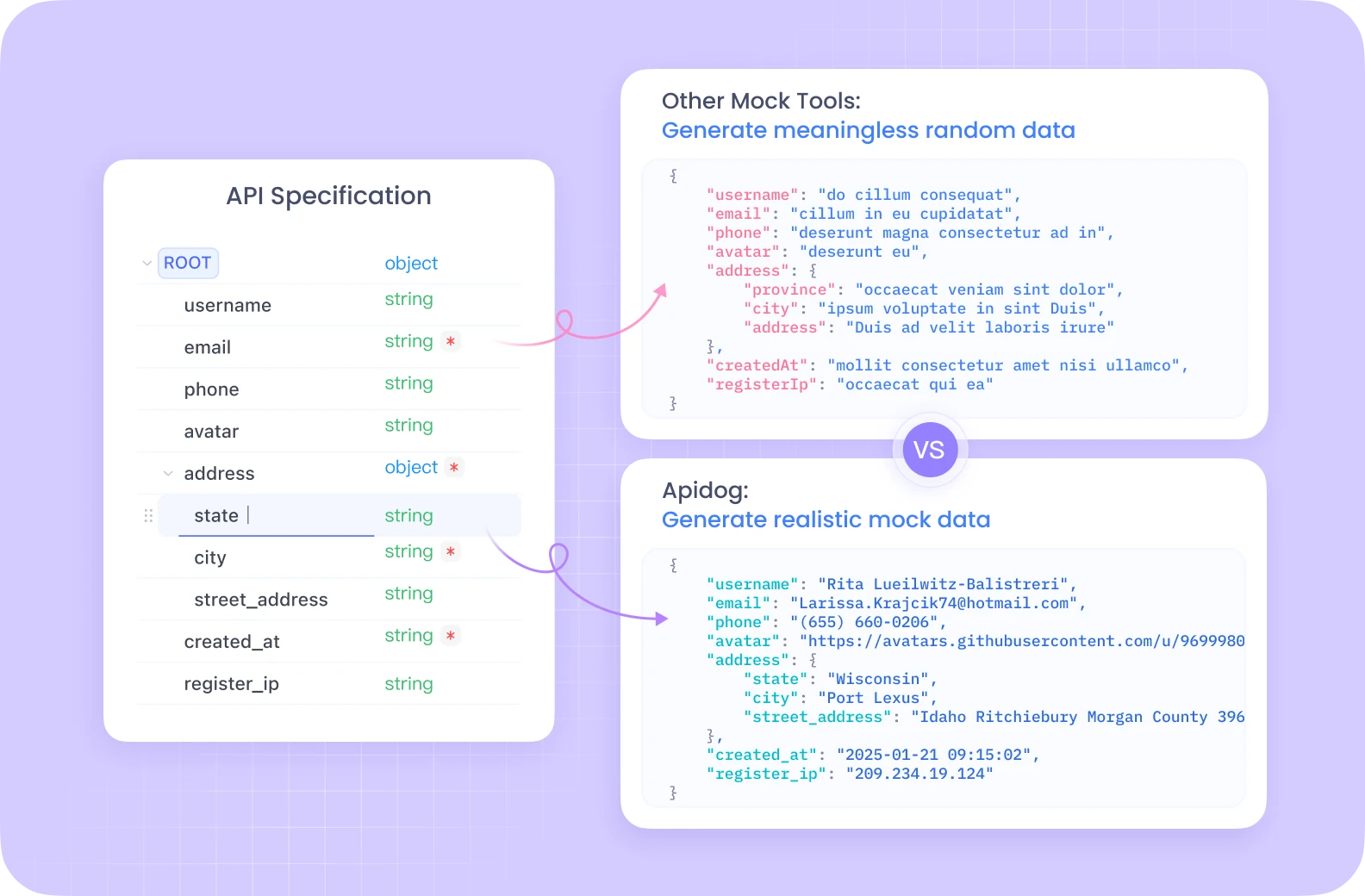
llms.txt foi projetado para coexistir com os padrões web existentes. A abordagem do caminho de arquivo padronizado segue a de /robots.txt e /sitemap.xml. Embora compartilhem o propósito de fornecer informações do site para bots com robots.txt e sitemap.xml, cada um tem características diferentes:
- sitemap.xml fornece uma lista de todas as páginas para motores de busca, enquanto llms.txt fornece uma lista curada de páginas para agentes de IA.
- robots.txt informa aos crawlers quais páginas eles podem visitar, mas não inclui informações contextuais das páginas. llms.txt pode complementar isso com contexto.
- robots.txt controla qual acesso é permitido para crawlers que visitam periodicamente. llms.txt é usado sob demanda quando os usuários solicitam informações sobre tópicos específicos (embora à medida que llms.txt se torne mais amplamente utilizado, ele também possa ser usado em treinamento regular).
- robots.txt e sitemap.xml são projetados para motores de busca, enquanto llms.txt é projetado para LLMs.
O formato de llms.txt, explicado
Os arquivos llms.txt são escritos em formato markdown, pois este é atualmente o formato mais facilmente entendido pelos modelos de linguagem. Além disso, o markdown de llms.txt segue uma estrutura específica, tornando-o processável por linguagens de programação.
O markdown inclui as seguintes seções:
- Um elemento h1 (#) com o nome do site. Esta é uma seção obrigatória.
- Um bloco de citação (>) contendo um breve resumo do site.
- Zero ou mais seções markdown de qualquer tipo, exceto cabeçalhos (parágrafos, listas, etc.).
- Zero ou mais seções delimitadas por elementos h2 (##), fornecendo listas de links para arquivos markdown contendo informações detalhadas.
- As listas de links são escritas no formato: - nome: descrição
- Uma seção especial começando com ## Opcional, fornecendo informações secundárias que podem ser puladas.
Veja um exemplo de um arquivo llms.txt:
# Meu Site
> Este é um site que fornece informações sobre vários tópicos.
## Documentos
- [Post 1](<https://example.com/post1.md>): Este é o primeiro post.
- [Post 2](<https://example.com/post2.md>): Este é o segundo post.
## Opcional
- [Fórum](<https://example.com/forum>): Um lugar para discutir tópicos.
Criando llms.txt para um site
Para criar arquivos llms.txt, você precisa preparar tanto o arquivo llms.txt em si, que resume o site e links para informações detalhadas, quanto os arquivos markdown contendo informações detalhadas para cada página. Várias ferramentas estão disponíveis para automatizar a criação dessas páginas:
- Mintlify — A documentação que você deseja, sem esforço
- dotenvx/llmstxt: converter sitemap.xml para llms.txt
- Gerar llms.txt
No meu caso, eu não vi muito benefício em usar uma ferramenta, então eu criei-o ao construir meu site estaticamente, recuperando uma lista de artigos. Aqui está um exemplo simples de implementação:
Como contexto, este blog é construído com SvelteKit e gera páginas estaticamente ao recuperar artigos do Contentful.
No SvelteKit, as rotas da API são definidas em arquivos +server.ts. Ao declarar export const prerender = true, você pode gerar estaticamente as rotas da API. Crie um arquivo src/routes/llms.tsx/+server.ts e escreva conforme segue (mostrando um exemplo de código simplificado):
// src/routes/llms.tsx/+server.ts
import type { RequestHandler } from "@sveltejs/kit";
import RepositoryFactory, { POST } from "../../repositories/RepositoryFactory";
// PostRepository é uma classe para recuperar artigos do Contentful
const PostRepository = RepositoryFactory[POST];
export const prerender = true;
const siteUrl = "...";
type Item = {
title: string;
slug: string;
about: string;
};
// Função para gerar conteúdo llms.txt
const renderLlmsTxt = (items: Item[]) => `# Blog Técnico do azukiazusa 2
> Este é um blog técnico operado por [azukiazusa](<https://github.com/azukiazusa1>). Eu escrevo principalmente sobre tecnologias de frontend web.
## Posts do Blog
${items
.map(
(item) =>
`- [${item.title}](${siteUrl}/blog/${item.slug}.md): ${item.about}`,
)
.join("\\\\n")}
`;
// Exportar uma variável com o nome correspondente a um verbo de requisição HTTP faz com que seja reconhecido como uma rota da API
export const GET: RequestHandler = async () => {
const posts = await PostRepository.findAll();
const feed = renderLlmsTxt(posts);
const headers = {
"Content-Type": "text/markdown; charset=utf-8",
};
return new Response(feed, {
headers,
});
};
Essa abordagem é semelhante a gerar arquivos como rss.xml ou sitemap.xml.
Para arquivos markdown de cada post de blog, eu também criei uma rota da API e os gerei estaticamente. Criei um arquivo src/routes/blog/[slug].md/+server.ts e escrevi:
// src/routes/blog/[slug].md/+server.ts
import type { RequestHandler } from "@sveltejs/kit";
import RepositoryFactory, {
POST,
} from "../../../repositories/RepositoryFactory";
const PostRepository = RepositoryFactory[POST];
export const prerender = true;
export const GET: RequestHandler = async ({ params }) => {
const { slug } = params;
const post = await PostRepository.find(slug);
if (!post) {
return new Response("Não encontrado", { status: 404 });
}
const blogPost = post.blogPostCollection.items[0];
const body = `# ${blogPost.title}
${blogPost.article}
`;
return new Response(body, {
headers: {
"Content-Type": "text/markdown; charset=utf-8",
},
});
};
Você pode verificar o conteúdo do arquivo gerado acessando http://azukiazusa.dev/llms.txt.
Exemplos de adoção do llms.txt
Você pode conferir sites que fornecem llms.txt ou llms-full.txt nos seguintes links:
- llmstxt.site
- diretório /llms.txt
Usando llms.txt com agentes de IA
A partir de 2025, LLMs não detectam automaticamente llms.txt como crawlers para criar um índice. Usuários de agentes de IA precisam fornecer manualmente as informações.
Por exemplo, no Cursor, um editor de código de IA, você pode usar o recurso de símbolo @docs para referenciar uma URL específica para respostas mais precisas. Nesse caso, você pode especificar a URL de um arquivo llms-full.txt. Espera-se que isso ajude os agentes de IA a recuperar informações eficientemente.
Resumo do llms.txt
- O arquivo llms.txt é proposto para que os LLMs recuperem informações de sites
- Existem dois arquivos diferentes: llms.txt e llms-full.txt
- llms.txt é escrito em formato markdown e fornece uma visão geral do site e informações detalhadas sobre cada página
- llms-full.txt compila todas as informações sobre todas as páginas de um site em um único arquivo
- llms.txt é colocado na raiz de um site
- O markdown em llms.txt inclui as seguintes seções:
- Um elemento h1 (#) com o nome do site
- Um bloco de citação (>) contendo um breve resumo do site
- Zero ou mais seções markdown de qualquer tipo, exceto cabeçalhos
- Zero ou mais seções delimitadas por elementos h2 (##), fornecendo listas de links
- Uma seção especial começando com ## Opcional
Apidog se destaca como a principal alternativa ao Postman para esse propósito. Para desenvolvedores implementando llms.txt em vários ambientes, o sistema de gerenciamento de ambiente do Apidog prova ser significativamente mais flexível que o do Postman, economizando tempo valioso de desenvolvimento enquanto garante uma implementação consistente desse padrão emergente.