이전에는 ClawdBot으로 알려졌던 MoltBot은 Telegram, WhatsApp, Discord, Slack과 같은 메시징 플랫폼과 직접 통합되는 자체 호스팅 에이전트입니다. 이는 개인 정보를 보호하고 낮은 지연 시간을 유지하면서 사용자의 기기에서 실제 작업을 실행합니다.
Kimi K2.5를 MoltBot에 연결하면 다재다능하고 비용 효율적인 비서가 탄생합니다. 사용자는 Claude 3.5 Sonnet 또는 GPT-4o와 같은 모델 비용의 일부만으로 일반 작업, 창의적인 작업 및 에이전트 동작에 대한 강력한 성능을 얻을 수 있습니다. 개인 정보 보호에 중점을 둔 설정의 경우, 양자화된 GGUF 가중치를 사용한 로컬 배포는 외부 데이터 전송을 제거합니다.
이 가이드는 API 및 로컬 방법을 자세히 설명합니다. 구성 예제, 확인 단계 및 자주 발생하는 문제에 대한 해결책이 포함되어 있습니다.
MoltBot과 Kimi K2.5를 페어링하는 이유
MoltBot은 실행 계층 역할을 하며, LLM은 인텔리전스를 제공합니다. Kimi K2.5는 이 역할에서 뚜렷한 이점을 제공합니다.
이 모델은 MoE 설계를 통해 관련 전문가를 효율적으로 활성화하여 높은 용량을 제공합니다. 멀티모달 입력을 기본적으로 처리하여 MoltBot이 시각 자료에서 코드 생성과 같은 작업을 위해 스크린샷, UI 디자인 또는 짧은 비디오를 처리할 수 있게 합니다.
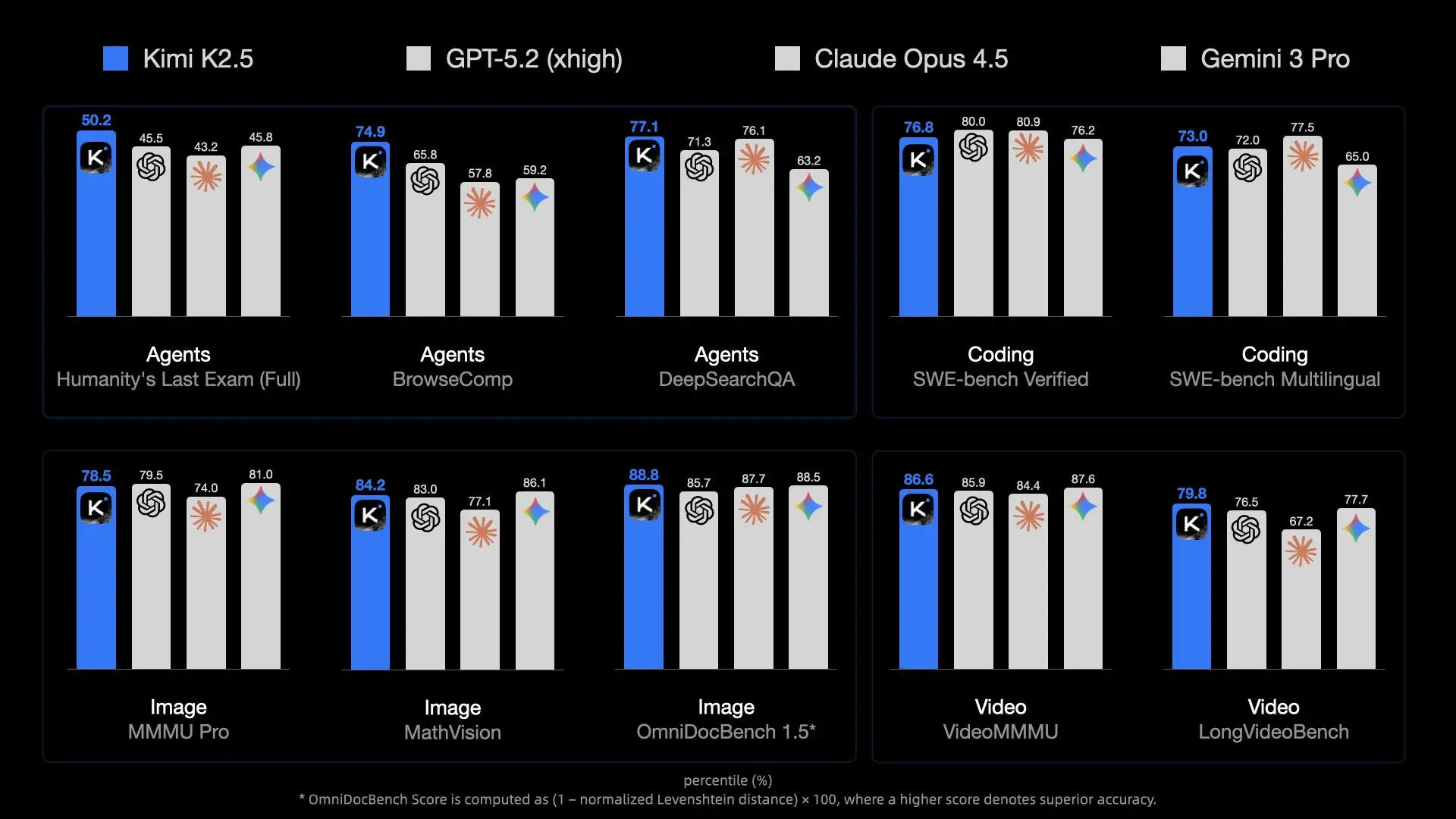
대부분의 배포에서 컨텍스트 길이는 256K 토큰에 달하며, 이는 방대한 프로젝트 코드베이스, 문서 또는 대화 기록을 보존할 수 있게 합니다. 이는 지속적인 비서에게 필수적입니다.
API 비용은 서구 대안에 비해 낮습니다. 헤비 사용자들은 시간이 지남에 따라 상당한 비용을 절약할 수 있습니다. 지속적인 비용 없이 최대의 제어를 위해서는 양자화를 통해 소비자 하드웨어에서 로컬 추론이 작동합니다.
Kimi K2.5는 최대 100개의 하위 에이전트가 병렬 도구 실행을 수행하는 자율적인 스웜을 포함하여 강력한 에이전트 기능을 보여줍니다. MoltBot의 스킬 시스템을 통해 라우팅될 때 이러한 기능은 채팅 메시지에서 직접 복잡한 워크플로를 자동화합니다.
MoltBot의 유연성은 모든 OpenAI 호환 엔드포인트를 지원합니다. 공급자를 전환하려면 구성 업데이트만 필요하므로 사용자가 쉽게 실험할 수 있습니다.
선행 조건
구성 전에 다음 요소를 준비하세요.
MoltBot을 완전히 설치하세요. 아직 설치하지 않았다면 설치 스크립트를 실행하세요:
curl -fsSL https://molt.bot/install.sh | bash
이 프로젝트는 Anthropic의 상표권 요청에 따라 2026년 1월 27일에 ClawdBot에서 MoltBot으로 브랜드가 변경되었습니다. 이전 설치는 `~/.clawdbot` 디렉토리를 유지할 수 있지만, 최근 버전은 `moltbot` 명령과 `~/.moltbot` 또는 유사한 경로를 사용합니다. 정확한 설정은 `molt.bot` 또는 GitHub 저장소(github.com/moltbot/moltbot)의 문서를 확인하세요.
Kimi K2.5 접근 권한을 얻으세요:
- API 경로: platform.moonshot.ai에서 계정을 생성하고 API 키를 생성한 다음 프로젝트 예산 제한 사항을 기록해 두세요.
- 로컬 경로: 양자화된 가중치(예: Hugging Face moonshotai/Kimi-K2.5 또는 unsloth/Kimi-K2.5-GGUF와 같은 커뮤니티 저장소)를 다운로드하세요. llama.cpp를 설치하고 서버를 시작하세요.
테스트를 위해 Apidog를 설치하세요. 이는 인증 헤더, JSON 본문 및 응답 스트리밍을 효과적으로 처리합니다.
MoltBot을 위해 Node.js가 실행되는지 확인하세요. JSON 파일을 편집하는 데 기본적인 터미널 익숙함이 도움이 됩니다.
방법 1: Moonshot API를 통한 연결 (대부분의 사용자에게 권장)
이 접근 방식은 최소한의 하드웨어 요구 사항으로 전체 256K 컨텍스트 및 멀티모달 지원을 제공합니다.
단계 1: Apidog를 사용하여 API 연결 유효성 검사
Apidog를 실행하고 새 POST 요청을 생성합니다.
URL을 다음으로 설정합니다:
https://api.moonshot.ai/v1/chat/completions
헤더를 추가합니다:
Authorization: Bearer sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
(실제 키로 교체하세요.)
기본 테스트를 위해 이 본문을 사용합니다:
{
"model": "kimi-k2.5",
"messages": [
{
"role": "user",
"content": "Confirm you are Kimi K2.5 and describe your capabilities briefly."
}
],
"temperature": 0.7,
"max_tokens": 256
}
요청을 보냅니다. 일관된 출력과 함께 성공적인 200 응답이 오면 키가 작동함을 확인합니다. 여기에서 속도 제한 또는 예산 오류를 기록해 두세요.
단계 2: 구성 파일 찾기 및 편집
MoltBot은 일반적으로 다음 JSON 파일에 설정을 저장합니다:
~/.moltbot/moltbot.json- 또는 레거시:
~/.clawdbot/moltbot.json/~/.clawdbot/agents/default/config.json
편집기로 엽니다.
공급자 섹션을 추가하거나 수정합니다:
{
"agent": {
"model": {
"primary": "moonshot/kimi-k2.5"
}
},
"models": {
"providers": {
"moonshot": {
"baseUrl": "https://api.moonshot.ai/v1",
"apiKey": "sk-your-moonshot-api-key-here",
"api": "openai-completions",
"models": [
{
"id": "kimi-k2.5",
"name": "Kimi K2.5 (API)",
"contextWindow": 262144,
"maxTokens": 8192
}
]
}
}
}
}
보안 참고: 프로덕션에서 키를 하드코딩하지 마세요. 환경 변수(예: export MOONSHOT_API_KEY=sk-...)를 설정하고 MoltBot이 확장을 지원하는 경우 이를 참조하세요.
단계 3: 변경 사항 적용 및 다시 시작
파일을 저장한 다음 다시 시작합니다:
moltbot restart
또는 필요에 따라 게이트웨이/서비스를 중지하고 시작합니다.
방법 2: 로컬 Kimi K2.5 배포를 통한 연결
로컬 실행은 개인 정보 보호를 우선시하고 반복 비용을 제거하지만, 상당한 VRAM/RAM을 요구합니다.
단계 1: 로컬 추론 서버 시작
호환성을 위해 llama.cpp를 사용합니다.
가능한 경우 GPU 지원으로 llama.cpp를 빌드합니다:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make LLAMA_CUDA=1 # 또는 적절한 플래그
양자화된 GGUF 변형(예: 균형을 위한 UD-TQ1_0)을 다운로드합니다:
huggingface-cli 또는 직접 다운로드를 사용하세요.
OpenAI 호환 서버를 시작합니다:
./llama-server \
-m /path/to/Kimi-K2.5-UD-TQ1_0.gguf \
--port 8080 \
--ctx-size 32768 \ # 하드웨어 한도까지 조정; 256K는 극도의 리소스 필요
--n-gpu-layers 99 \
--host 0.0.0.0
http://localhost:8080/v1/models를 탐색하여 확인합니다.
단계 2: 로컬 엔드포인트에 대한 MoltBot 구성 업데이트
JSON 파일을 편집합니다:
{
"agent": {
"model": {
"primary": "local-kimi/kimi-k2.5"
}
},
"models": {
"providers": {
"local-kimi": {
"baseUrl": "http://127.0.0.1:8080/v1",
"apiKey": "sk-no-key-required",
"api": "openai-completions",
"models": [
{
"id": "kimi-k2.5-local",
"name": "Kimi K2.5 Local",
"contextWindow": 32768, // --ctx-size와 일치해야 합니다.
"maxTokens": 4096
}
]
}
}
}
}
Docker 참고: MoltBot이 컨테이너화되어 실행되는 경우, 127.0.0.1을 host.docker.internal로 교체하세요.
단계 3: 다시 시작 및 리소스 사용량 모니터링
MoltBot을 다시 시작하고 시스템 모니터를 확인하세요. 로컬 추론은 상당한 메모리를 소비합니다. 필요한 경우 계층을 오프로드하거나 컨텍스트를 줄이세요.
테스트 및 확인
통합이 작동하는지 확인합니다.
MoltBot 인스턴스(연결된 앱을 통해)에 메시지를 보냅니다:
"지금 당신은 누구의 지원을 받고 있나요?"
Kimi K2.5는 일반적으로 Moonshot AI를 식별하여 응답합니다.
로그를 확인합니다:
moltbot logs
api.moonshot.ai 또는 localhost:8080으로 라우팅된 요청을 찾으세요.
API를 사용하는 경우 멀티모달을 테스트합니다: 채팅을 통해 이미지를 업로드하고 설명 또는 코드 생성을 요청합니다.
일반적인 문제 해결
- 공급자 확인 실패 → Apidog에서 정확한 baseUrl + 키를 다시 테스트하세요. 네트워크 프록시 또는 방화벽이 종종 방해합니다.
- 컨텍스트 오버플로 오류 → JSON의 contextWindow를 서버의 --ctx-size와 일치시키세요. MoltBot은 한도에 도달하면 잘라내거나 요약합니다. 값이 일치하지 않으면 충돌이 발생합니다.
- 로컬에서 응답 속도가 느림 → gpu-layers를 줄이거나, 낮은 양자화를 사용하거나, llama.cpp에서 flash attention을 활성화하세요.
- 예상치 못한 형식/환각 → temperature(0.6-1.0)를 실험하거나 Kimi 특정 튜닝을 위해 MoltBot 에이전트 구성에 사용자 지정 시스템 프롬프트를 추가하세요.
- API 예산 소진 → platform.moonshot.ai에서 사용량을 모니터링하고 일일 한도를 설정하세요.
결론
Kimi K2.5를 MoltBot과 통합하면 고성능, 경제적이며 선택적으로 완전히 비공개적인 개인 AI 에이전트를 제공합니다. API 방법은 편의성과 최대 기능을 제공하며, 로컬 설정은 완전한 데이터 주권을 보장합니다.
두 가지 접근 방식을 모두 실험해 보세요. Apidog를 사용하여 문제를 신속하게 격리하세요. Moonshot이 Kimi 모델을 계속 업데이트하고 MoltBot이 발전함에 따라 이 조합은 사용자를 접근 가능한 에이전트 AI의 선두에 서게 합니다.
지금 구성하세요. 향상된 비서가 기다리고 있습니다.