
매주 새로운 AI 이미지 생성 모델이 놀라운 비주얼을 창조하는 것을 가능하게 하고 있는 것 같습니다. 그 중 하나인 HiDream-I1-Full 모델은 매우 강력합니다. 이러한 모델을 로컬에서 실행할 경우 자원이 많이 소모될 수 있지만, API를 활용하면 이 기술을 애플리케이션이나 워크플로우에 통합하는 편리하고 확장 가능한 방법을 제공합니다.
이 튜토리얼은 다음을 안내합니다:
- HiDream-I1-Full 이해하기: 이 모델이 무엇이며 그 기능.
- API 옵션: Replicate와 Fal.ai를 통해 HiDream-I1-Full를 제공하는 두 개의 인기 있는 플랫폼 탐색.
- Apidog로 테스트하기: Apidog 도구를 사용하여 이러한 API와 상호작용하고 테스트하는 단계별 가이드.
개발 팀이 최대 생산성으로 협력할 수 있도록 통합된 올인원 플랫폼을 원하십니까?
Apidog는 모든 요구를 충족시키며, Postman을 보다 저렴한 가격으로 대체합니다!
대상 청중: 개발자, 디자이너, AI 애호가 및 복잡한 로컬 설정 없이 고급 AI 이미지 생성을 사용하고자 하는 모든 사람.
전제 조건:
- API의 기본 이해 (HTTP 요청, JSON).
- API 키를 얻기 위해 Replicate 및/또는 Fal.ai에 계정 생성.
- Apidog 설치 (또는 웹 버전 접근).
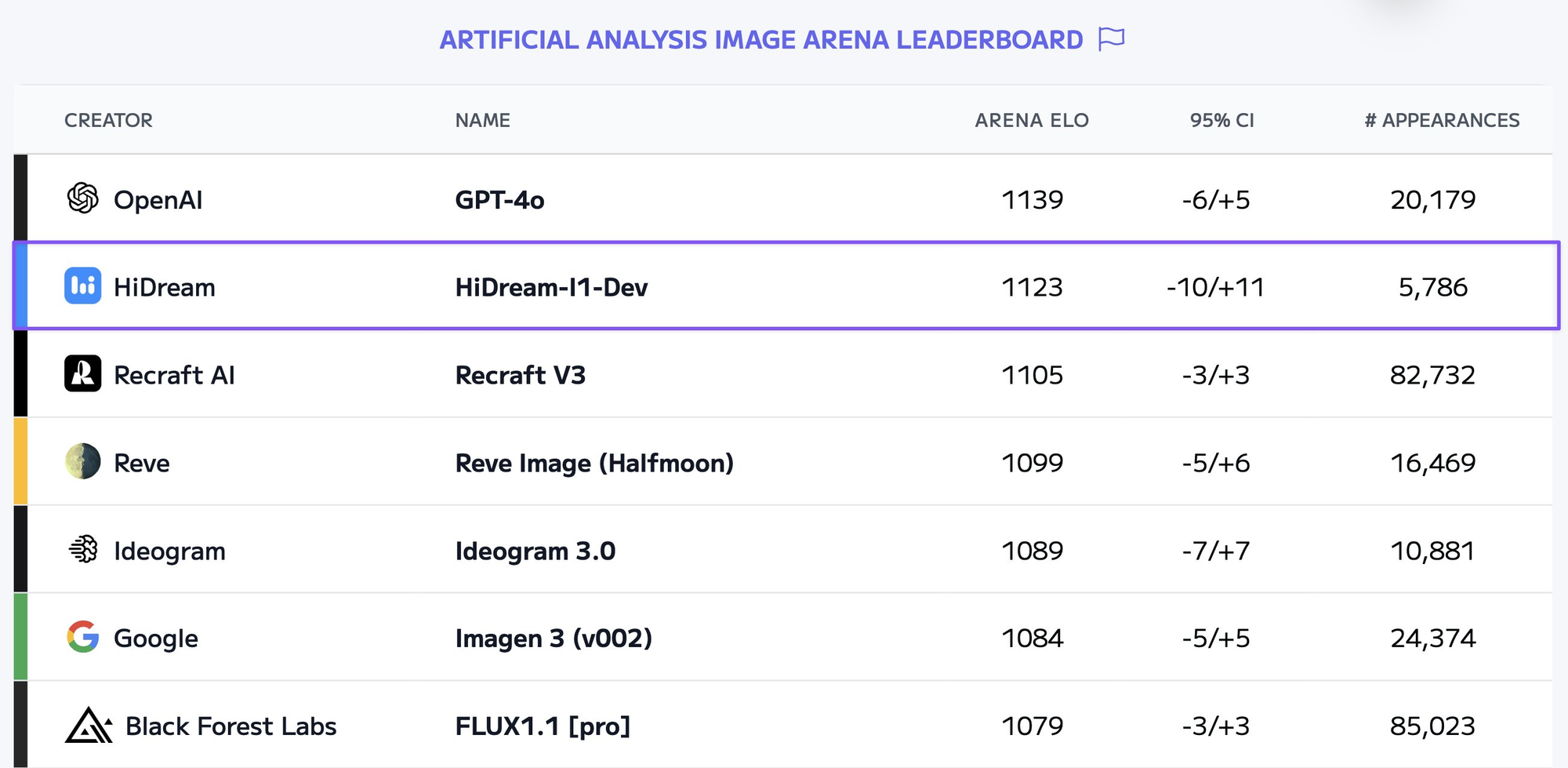
HiDream-I1-Full은 무엇인가요?

HiDream-I1-Full은 HiDream AI에서 개발한 고급 텍스트-투-이미지 확산 모델입니다. 텍스트 설명(프롬프트)를 바탕으로 고품질, 일관성 있는, 미적으로 매력적인 이미지를 생성하도록 설계된 모델 패밀리에 속합니다.

모델 세부정보: 공식 모델 카드 및 기술적 정보는 Hugging Face에서 확인할 수 있습니다: https://huggingface.co/HiDream-ai/HiDream-I1-Full
주요 기능 (이 클래스의 모델에 일반적임):
- 텍스트-투-이미지 생성: 자세한 텍스트 프롬프트로부터 이미지를 생성합니다.
- 고해상도: 다양한 애플리케이션에 적합한 상당히 높은 해상도로 이미지를 생성할 수 있습니다.
- 스타일 준수: 프롬프트 내에 있는 스타일적 신호를 해석할 수 있습니다 (예: "반 고흐 스타일", "사진처럼 사실적인", "애니메이션").
- 복잡한 장면 구성: 여러 대상, 상호작용 및 프롬프트의 복잡성에 따라 상세한 배경을 가진 이미지를 생성할 수 있는 능력.
- 제어 매개변수: 부정적인 프롬프트(피해야 할 것들), 시드(재현 가능성을 위한), 안내 스케일(프롬프트를 따르는 강도) 및 특정 API 구현에 따라 이미지-투-이미지 변형 또는 제어 입력을 통한 미세 조정을 종종 허용합니다.
왜 API를 사용하나요?
HiDream-I1-Full과 같은 대규모 AI 모델을 로컬에서 실행하는 것은 상당한 컴퓨터 자원(강력한 GPU, 충분한 RAM 및 저장소)을 요구하며 기술적 설정(종속성 관리, 모델 가중치, 환경 설정)이 필요합니다. API를 사용하면 여러 가지 이점이 있습니다:
- 하드웨어 요구 사항 없음: 계산을 강력한 클라우드 인프라에 오프로드합니다.
- 확장성: 인프라를 관리하지 않고도 다양한 부하를 쉽게 처리할 수 있습니다.
- 통합 용이성: 표준 HTTP 요청을 사용하여 웹사이트, 앱 또는 스크립트에 이미지 생성 기능을 통합합니다.
- 유지보수 불필요: API 제공자가 모델 업데이트, 유지보수 및 백엔드 관리를 처리합니다.
- 사용량 기준 결제: 보통 사용하는 컴퓨팅 시간에 대해서만 비용을 지불합니다.
HiDream-I1-Full을 API를 통해 사용하는 방법
여러 플랫폼이 AI 모델을 호스팅하고 API 액세스를 제공합니다. 우리는 HiDream-I1-Full에 대해 두 개의 인기 있는 선택지에 집중할 것입니다:
옵션 1: Replicate의 HiDream API 사용
Replicate는 인프라를 관리할 필요 없이 간단한 API를 통해 머신러닝 모델을 실행할 수 있는 플랫폼입니다. 커뮤니티에서 게시한 모델의 방대한 라이브러리를 호스팅합니다.
- HiDream-I1-Full에 대한 Replicate 페이지: https://replicate.com/prunaai/hidream-l1-full (참고: URL에
l1-full이 언급되지만, Replicate의 HiDream 모델에 대한 프롬프트에서 제공된 관련 링크입니다. 이 튜토리얼에 의도된 모델에 해당한다고 가정합니다).
Replicate 작동 방식:
- 인증: Replicate API 토큰이 필요합니다. 이 토큰은 계정 설정에서 찾을 수 있습니다. 이 토큰은
Authorization헤더에 전달됩니다. - 예측 시작: 예측을 위한 Replicate API 엔드포인트에 POST 요청을 보냅니다. 요청 본문에는 모델 버전과 입력 매개변수(예:
prompt,negative_prompt,seed등)가 포함됩니다. - 비동기 운영: Replicate는 일반적으로 비동기식으로 작동합니다. 초기 POST 요청은 예측 ID 및 상태를 확인할 URL과 함께 즉시 반환됩니다.
- 결과 받기: 상태 URL(초기 응답에 제공됨)을 GET 요청을 사용하여 폴링해야 합니다. 상태가
succeeded(또는failed)가 될 때까지 계속합니다. 최종 성공적인 응답에는 생성된 이미지의 URL이 포함됩니다.
개념적 파이썬 예시 (requests 사용):
import requests
import time
import os
REPLICATE_API_TOKEN = "YOUR_REPLICATE_API_TOKEN" # 프로덕션에서는 환경 변수를 사용
MODEL_VERSION = "TARGET_MODEL_VERSION_FROM_REPLICATE_PAGE" # 예: "9a0b4534..."
# 1. 예측 시작
headers = {
"Authorization": f"Token {REPLICATE_API_TOKEN}",
"Content-Type": "application/json"
}
payload = {
"version": MODEL_VERSION,
"input": {
"prompt": "해질녘의 멋진 사이버펑크 도시 풍경, 젖은 거리에서 네온 불빛이 반사되는 모습, 상세한 일러스트",
"negative_prompt": "못생긴, 변형된, 흐릿한, 품질이 낮은, 텍스트, 워터마크",
"width": 1024,
"height": 1024,
"seed": 12345
# Replicate 모델 페이지에 따라 필요 시 다른 매개변수를 추가
}
}
start_response = requests.post("<https://api.replicate.com/v1/predictions>", json=payload, headers=headers)
start_response_json = start_response.json()
if start_response.status_code != 201:
print(f"예측 시작 오류: {start_response_json.get('detail')}")
exit()
prediction_id = start_response_json.get('id')
status_url = start_response_json.get('urls', {}).get('get')
print(f"예측이 ID: {prediction_id}로 시작되었습니다.")
print(f"상태 URL: {status_url}")
# 2. 결과 폴링
output_image_url = None
while True:
print("상태 확인 중...")
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status')
if status == 'succeeded':
output_image_url = status_response_json.get('output') # 일반적으로 URL 목록
print("예측 성공!")
print(f"출력: {output_image_url}")
break
elif status == 'failed' or status == 'canceled':
print(f"예측 실패 또는 취소: {status_response_json.get('error')}")
break
elif status in ['starting', 'processing']:
# 다시 폴링하기 전에 잠시 대기
time.sleep(5) # 필요에 따라 폴링 간격 조정
else:
print(f"알 수 없는 상태: {status}")
print(status_response_json)
break
# 이제 output_image_url을 사용할 수 있습니다.
가격: Replicate은 하드웨어에서 모델의 실행 시간에 따라 요금을 부과합니다. 자세한 내용은 가격 페이지를 확인하세요.
옵션 2: Fal.ai
Fal.ai는 API를 통해 AI 모델의 빠르고 확장 가능하며 비용 효율적인 추론을 제공하는 데 중점을 둔 또 다른 플랫폼입니다. 그들은 일반적으로 실시간 성능을 강조합니다.
Fal.ai 작동 방식:
- 인증: Fal API 자격증명(Key ID 및 Key Secret, 일반적으로
KeyID:KeySecret로 결합됨)이 필요합니다. 이는Authorization헤더에 전달되며 보통Key YourKeyID:YourKeySecret형태입니다. - API 엔드포인트: Fal.ai는 특정 모델 기능에 대한 직접 엔드포인트 URL을 제공합니다.
- 요청 형식: 모델의 엔드포인트 URL에 POST 요청을 보냅니다. 요청 본문은 일반적으로 모델이 요구하는 입력 매개변수를 포함하는 JSON입니다(Replicate와 유사:
prompt등). - 동기 vs. 비동기: Fal.ai는 두 가지 모두 제공할 수 있습니다. 이미지 생성과 같은 장시간 실행되는 작업의 경우 다음과 같은 방식으로 수행할 수 있습니다:
- 서버리스 함수: 표준 요청/응답 주기로, 일반적으로 더 긴 타임아웃을 지원합니다.
- 큐: Replicate와 유사한 비동기 패턴으로 작업을 제출하고 요청 ID를 사용하여 결과를 폴링합니다. 구체적인 API 페이지에 해당하는 예상 상호작용 패턴이 상세히 설명되어 있습니다.
개념적 파이썬 예시 (requests 사용 - 비동기 큐 가정):
import requests
import time
import os
FAL_API_KEY = "YOUR_FAL_KEY_ID:YOUR_FAL_KEY_SECRET" # 환경 변수를 사용
MODEL_ENDPOINT_URL = "<https://fal.run/fal-ai/hidream-i1-full>" # Fal.ai에서 정확한 URL 확인
# 1. 큐에 요청 제출 (예시 - Fal 문서에서 정확한 구조 확인)
headers = {
"Authorization": f"Key {FAL_API_KEY}",
"Content-Type": "application/json"
}
payload = {
# 매개변수는 Fal.ai 서버리스 함수의 경우 페이로드에 직접 있을 수 있으며
# 설정에 따라 'input' 객체 내에 있을 수 있습니다. 문서 확인!
"prompt": "우주에서 떠 있는 우주비행사 초상화, 헬멧 바이저에 반사된 지구",
"negative_prompt": "만화, 드로잉, 일러스트, 스케치, 텍스트, 문자",
"seed": 98765
# Fal.ai 구현에서 지원되는 다른 매개변수를 추가
}
# Fal.ai는 비동기 처리를 위해 '/queue' 추가나 특정 쿼리 매개변수를 요구할 수 있습니다.
# 예: POST <https://fal.run/fal-ai/hidream-i1-full/queue>
# 문서를 확인하세요! 상태 URL을 반환하는 엔드포인트 가정:
submit_response = requests.post(f"{MODEL_ENDPOINT_URL}", json=payload, headers=headers, params={"fal_webhook": "OPTIONAL_WEBHOOK_URL"}) # 웹 후크와 같은 쿼리 매개변수 확인
if submit_response.status_code >= 300:
print(f"요청 제출 오류: {submit_response.status_code}")
print(submit_response.text)
exit()
submit_response_json = submit_response.json()
# Fal.ai의 비동기 응답은 다를 수 있습니다. 요청 ID 또는 직접 상태 URL을 반환할 수 있습니다.
# 이 개념적 예시에 대해 Replicate와 유사한 상태 URL을 반환한다고 가정합니다.
status_url = submit_response_json.get('status_url') # 또는 request_id로 구성, 문서 확인
request_id = submit_response_json.get('request_id') # 대체 식별자
if not status_url and request_id:
# 상태 URL을 구성해야 할 수 있습니다. 예: <https://fal.run/fal-ai/hidream-i1-full/requests/{request_id}/status>
# 또는 일반 상태 엔드포인트 쿼리: <https://fal.run/requests/{request_id}/status>
print("상태 URL을 구성하거나 request_id를 사용해야 합니다. Fal.ai 문서 확인.")
exit() # Fal 문서에 따른 특정 구현 필요
print(f"요청이 제출되었습니다. 상태 URL: {status_url}")
# 2. 결과 폴링 (비동기일 경우)
output_data = None
while status_url: # 상태 URL이 있는 경우에만 폴링
print("상태 확인 중...")
# 폴링 시 인증이 필요할 수 있습니다.
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status') # Fal.ai 문서에서 상태 키 확인 ('COMPLETED', 'FAILED' 등)
if status == 'COMPLETED': # 예시 상태
output_data = status_response_json.get('response') # 또는 'result', 'output' 문서 확인
print("요청 완료!")
print(f"출력: {output_data}") # 출력 구조는 Fal.ai의 모델에 따라 다르면 미리 확인
break
elif status == 'FAILED': # 예시 상태
print(f"요청 실패: {status_response_json.get('error')}") # 오류 필드 확인
break
elif status in ['IN_PROGRESS', 'IN_QUEUE']: # 예시 상태
# 다시 폴링하기 전에 잠시 대기
time.sleep(3) # 폴링 간격 조정
else:
print(f"알 수 없는 상태: {status}")
print(status_response_json)
break
# 출력 데이터 사용(이미지 URL 또는 기타 정보 포함 가능)
가격: Fal.ai는 일반적으로 실행 시간에 따라 요금을 부과하며 초 단위 과금 자주 사용합니다. 특정 모델 및 컴퓨팅 리소스에 대한 가격 세부정보를 확인하세요.
Apidog로 HiDream API 테스트하기
Apidog는 강력한 API 디자인, 개발 및 테스트 도구입니다. HTTP 요청을 보내고 응답을 검사하며 API 세부정보를 관리할 수 있는 사용자 친화적인 인터페이스를 제공하여 Replicate 및 Fal.ai API를 통합하기 전에 테스트하는 데 이상적입니다.
Apidog를 사용해 HiDream-I1-Full API를 테스트하는 단계:
1단계. Apidog 설치 및 열기: Apidog를 다운로드하고 설치하거나 웹 버전을 사용하세요. 필요한 경우 계정을 생성하세요.

2단계. 새 요청 생성:
- Apidog에서 새 프로젝트를 생성하거나 기존 프로젝트를 엽니다.
- "+" 버튼을 클릭하여 새 HTTP 요청을 추가합니다.
3단계. HTTP 메서드 및 URL 설정:
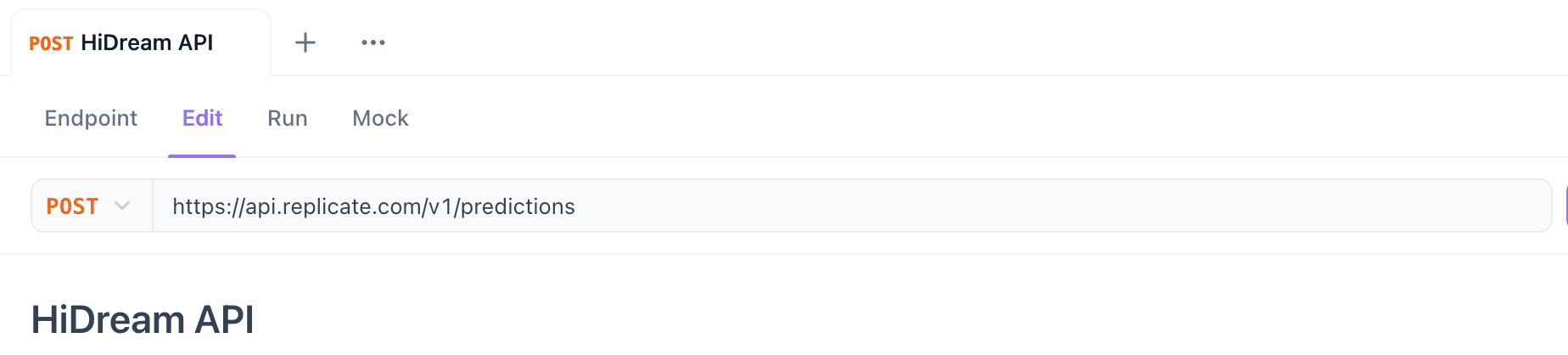
- 메서드:
POST선택. - URL: API 엔드포인트 URL 입력.
- Replicate (예측 시작)의 경우:
https://api.replicate.com/v1/predictions - Fal.ai (요청 제출)의 경우: 페이지에 제공된 특정 모델 엔드포인트 URL 사용 (예:
https://fal.run/fal-ai/hidream-i1-full- 비동기를 위한/queue또는 쿼리 매개변수가 필요한지 확인).
4단계. 헤더 구성:
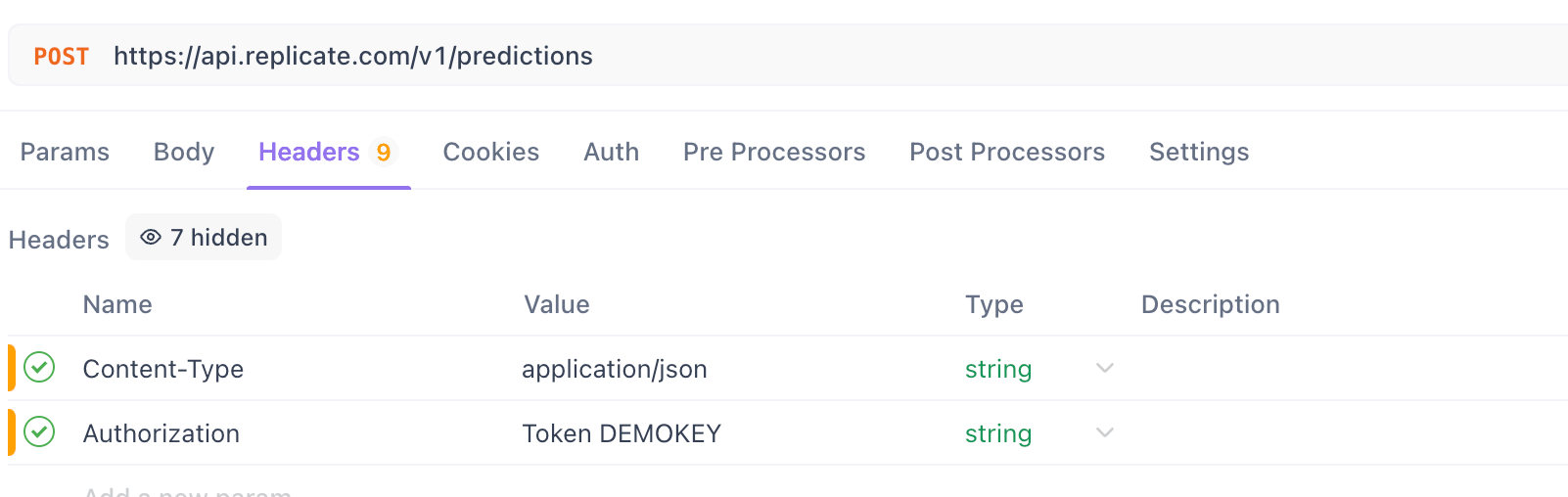
Headers탭으로 이동합니다.
Content-Type 헤더 추가:
- 키:
Content-Type - 값:
application/json
Authorization 헤더 추가:
Replicate의 경우:
- 키:
Authorization - 값:
Token YOUR_REPLICATE_API_TOKEN(실제 토큰으로 교체)
Fal.ai의 경우:
- 키:
Authorization - 값:
Key YOUR_FAL_KEY_ID:YOUR_FAL_KEY_SECRET(실제 자격증명으로 교체) - 전문 팁: Apidog의 환경 변수를 사용하여 API 키를 안전하게 저장하고 요청에 직접 하드코딩하지 마세요. 환경을 생성하고(예: "Replicate Dev", "Fal Dev")
REPLICATE_TOKEN또는FAL_API_KEY와 같은 변수를 정의합니다. 그런 다음 헤더 값에서Token {{REPLICATE_TOKEN}}또는Key {{FAL_API_KEY}}를 사용하세요.
5단계. 요청 본문 구성:
Body 탭으로 이동합니다.
raw 형식을 선택하고 드롭다운에서 JSON을 선택합니다.
플랫폼의 요구 사항에 따라 JSON 페이로드를 붙여넣습니다.
Replicate에 대한 JSON 본문의 예:
{
"version": "PASTE_MODEL_VERSION_FROM_REPLICATE_PAGE_HERE",
"input": {
"prompt": "편안한 도서관 구석에서 자고 있는 고양이를 그린 수채화",
"negative_prompt": "사진처럼 사실적인, 3D 렌더, 형편없는 예술, 변형된",
"width": 1024,
"height": 1024,
"seed": 55555
}
}
Fal.ai에 대한 JSON 본문의 예:
{
"prompt": "편안한 도서관 구석에서 자고 있는 고양이를 그린 수채화",
"negative_prompt": "사진처럼 사실적인, 3D 렌더, 형편없는 예술, 변형된",
"width": 1024,
"height": 1024,
"seed": 55555
// Fal.ai 설정에 따라 'model_name'과 같은 다른 매개변수가 필요할 수 있습니다.
}
중요: 사용 중인 HiDream-I1-Full 모델 버전에 대한 요구된 및 선택적 매개변수에 대한 구체적인 문서를 Replicate 또는 Fal.ai 페이지에서 참조하세요. guidance_scale, num_inference_steps 등의 매개변수가 있을 수 있습니다.
6단계. 요청 전송:
- "전송" 버튼을 클릭합니다.
- Apidog가 응답 상태 코드, 헤더 및 본문을 표시합니다.
- Replicate의 경우:
201 Created상태를 받을 수 있습니다. 응답 본문에는 예측의id와urls.getURL이 포함됩니다. 이getURL을 복사하세요. - Fal.ai (비동기)의 경우:
200 OK또는202 Accepted를 받을 수 있습니다. 응답 본문에는request_id, 직접status_url또는 그들의 구현 등에 따라 다른 세부정보가 포함될 수 있습니다. 폴링하는 데 필요한 관련 URL 또는 ID를 복사하세요. 동기식인 경우 처리 중에 직접 결과를 받을 수 있습니다 (이미지 생성을 위한 경우 그 가능성은 낮음).
결과 폴링 (비동기 API인 경우):
- Apidog에서 다른 새 요청을 만듭니다.
- 메서드:
GET선택. - URL: 초기 응답에서 복사한
상태 URL붙여넣습니다 (예: Replicate의urls.get또는 Fal.ai의 상태 URL). Fal.ai에서request_id를 제공했다면 그들의 문서에 따라 상태 URL을 구성합니다 (예:https://fal.run/requests/{request_id}/status). - 헤더 구성: POST 요청과 동일한
Authorization헤더를 추가합니다. (GET 요청에는 일반적으로 Content-Type이 필요하지 않습니다). - 요청 전송: "전송" 클릭.
- 응답 검사: JSON 응답에서
status필드를 확인합니다. - 만약
processing,starting,IN_PROGRESS,IN_QUEUE등이라면 잠시 기다리고 "전송"을 다시 클릭합니다. - 만약
succeeded또는COMPLETED라면 생성된 이미지의 URL을 포함하는output필드(Replicate의 경우) 또는response/result필드(Fal.ai의 경우)를 찾아보세요. - 만약
failed또는FAILED라면 세부정보를 보려면error필드를 확인하세요.
이미지 보기: 최종 성공적인 응답에서 이미지 URL을 복사하여 웹 브라우저에 붙여넣어 생성된 이미지를 확인하세요.
개발 팀이 최대 생산성으로 함께 작업할 수 있도록 통합된 올인원 플랫폼을 원하십니까?
Apidog는 모든 요구를 충족시키며, Postman을보다 저렴한 가격으로 대체합니다!

결론
HiDream-I1-Full은 강력한 이미지 생성 기능을 제공하며, Replicate 또는 Fal.ai와 같은 플랫폼의 API를 사용하면 복잡한 인프라를 관리하지 않고도 이 기술을 이용할 수 있습니다. API 워크플로우(요청, 잠재적 폴링, 응답)를 이해하고 Apidog와 같은 도구를 사용하여 테스트함으로써 최첨단 AI 이미지 생성 기능을 프로젝트에 쉽게 실험하고 통합할 수 있습니다.
Replicate 및 Fal.ai에 대한 구체적인 문서를 항상 참조하여 최신 엔드포인트 URL, 요구된 매개 변수, 인증 방법 및 가격 세부정보를 확인하세요. 이러한 사항은 시간이 지남에 따라 변경될 수 있습니다. 즐거운 생성이 되세요!