
DeepSeek은 추론과 효율성을 우선시하는 릴리스를 통해 대규모 언어 모델을 계속 발전시키고 있습니다. 이제 엔지니어와 연구원들은 복잡한 문제 해결 및 에이전트 워크플로우에 탁월한 DeepSeek-V3.2 및 DeepSeek-V3.2-Speciale 모델에 접근할 수 있습니다. 이러한 도구들은 애플리케이션에 완벽하게 통합되지만, 개발자들은 설정, 인증 및 최적화에서 종종 어려움에 직면합니다. 이 글은 이러한 모델을 효과적으로 활용하기 위한 단계별 기술 가이드를 제공합니다.
DeepSeek-V3.2 이해하기: 고급 추론을 위한 오픈소스 기반
개발자들은 투명성, 맞춤화 및 커뮤니티 주도 개선을 제공하는 오픈소스 모델을 기반으로 견고한 AI 시스템을 구축합니다. DeepSeek-V3.2는 희소 어텐션 메커니즘을 테스트하기 위해 DeepSeek이 이전에 출시했던 실험적인 V3.2-Exp 변형의 공식 후속 모델입니다. 이 모델은 총 6,710억 개의 파라미터 중 370억 개를 MoE(Mixture-of-Experts) 아키텍처에서 활성화하며, 14.8조 개의 고품질 토큰으로 훈련되었습니다. 이러한 규모를 통해 DeepSeek-V3.2는 자연어 생성부터 복잡한 수학적 증명에 이르기까지 다양한 작업을 처리할 수 있습니다.
이 모델의 핵심 혁신은 추론 중 계산 오버헤드를 줄이는 정교한 메커니즘인 DeepSeek 희소 어텐션(DSA)에 있습니다. 특히 최대 128,000 토큰에 이르는 긴 컨텍스트에 유용합니다. 엔지니어들은 이 기술이 출력 품질을 유지하면서 지연 시간을 단축한다는 점을 높이 평가하는데, 이는 챗봇이나 코드 어시스턴트와 같은 실시간 애플리케이션에 매우 중요합니다. 또한 DeepSeek-V3.2는 모델이 최종 출력 전에 중간 추론 단계를 생성하는 '사고(thinking)' 모드를 통합하여 AIME 2025 및 HMMT 2025와 같은 벤치마크에서 정확도를 높입니다.
오픈소스 버전은 Hugging Face의 deepseek-ai/DeepSeek-V3.2에서 접근할 수 있습니다. 개발자들은 가중치와 구성을 직접 다운로드하여 GPU 클러스터에 로컬 배포할 수 있습니다. 예를 들어, Transformers 라이브러리를 사용하여 모델을 로드합니다.
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "Solve this equation: x^2 + 3x - 4 = 0"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200, do_sample=False)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
이 코드 스니펫은 최신 NVIDIA GPU에서 효율성을 위해 bfloat16 정밀도로 모델을 초기화합니다. 하지만 로컬 실행은 상당한 하드웨어를 요구하며, 완전한 정밀도를 위해서는 최소 8개의 A100 GPU를 권장합니다. 결과적으로 많은 팀은 소비자 하드웨어에 맞추기 위해 bitsandbytes와 같은 라이브러리를 통해 양자화된 버전을 선택합니다.
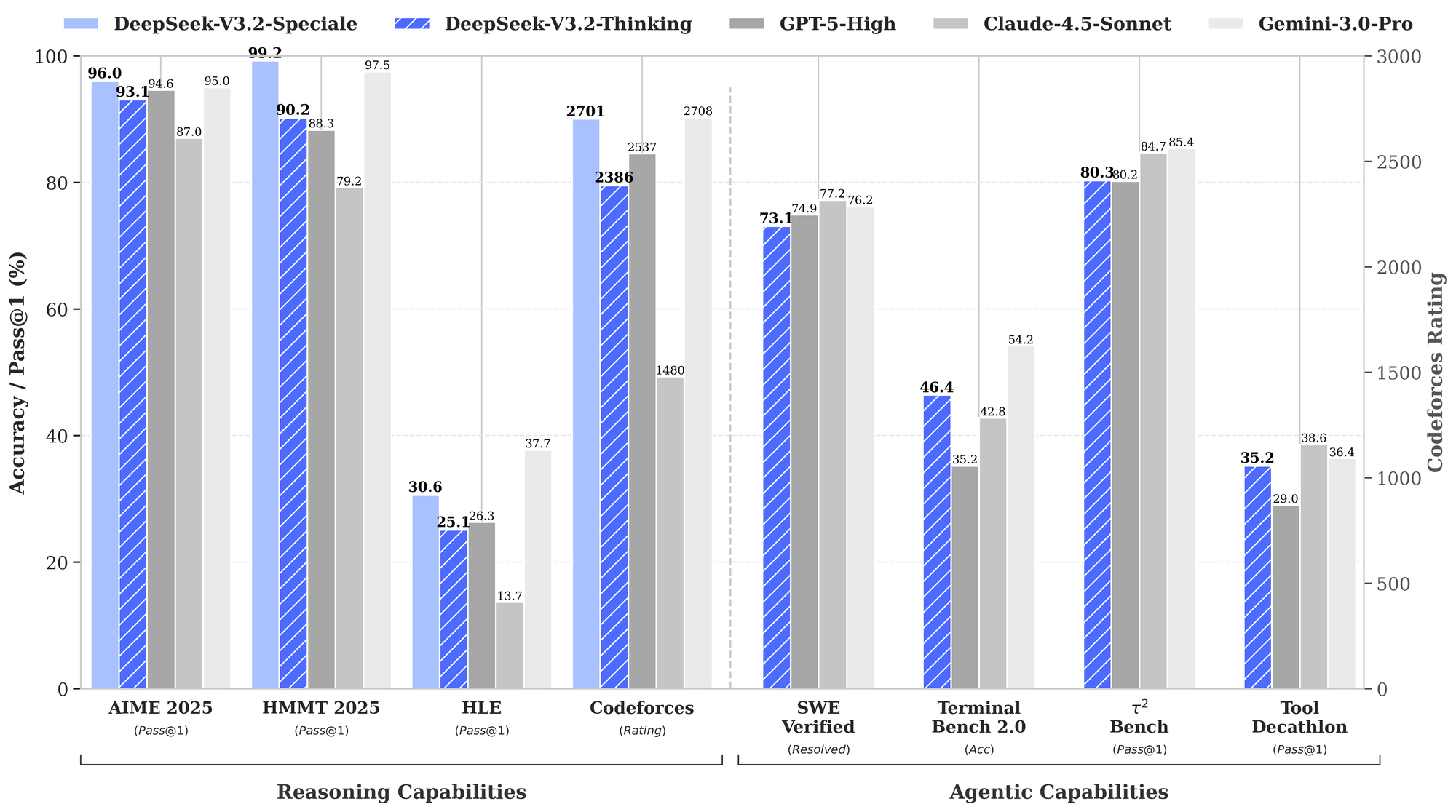
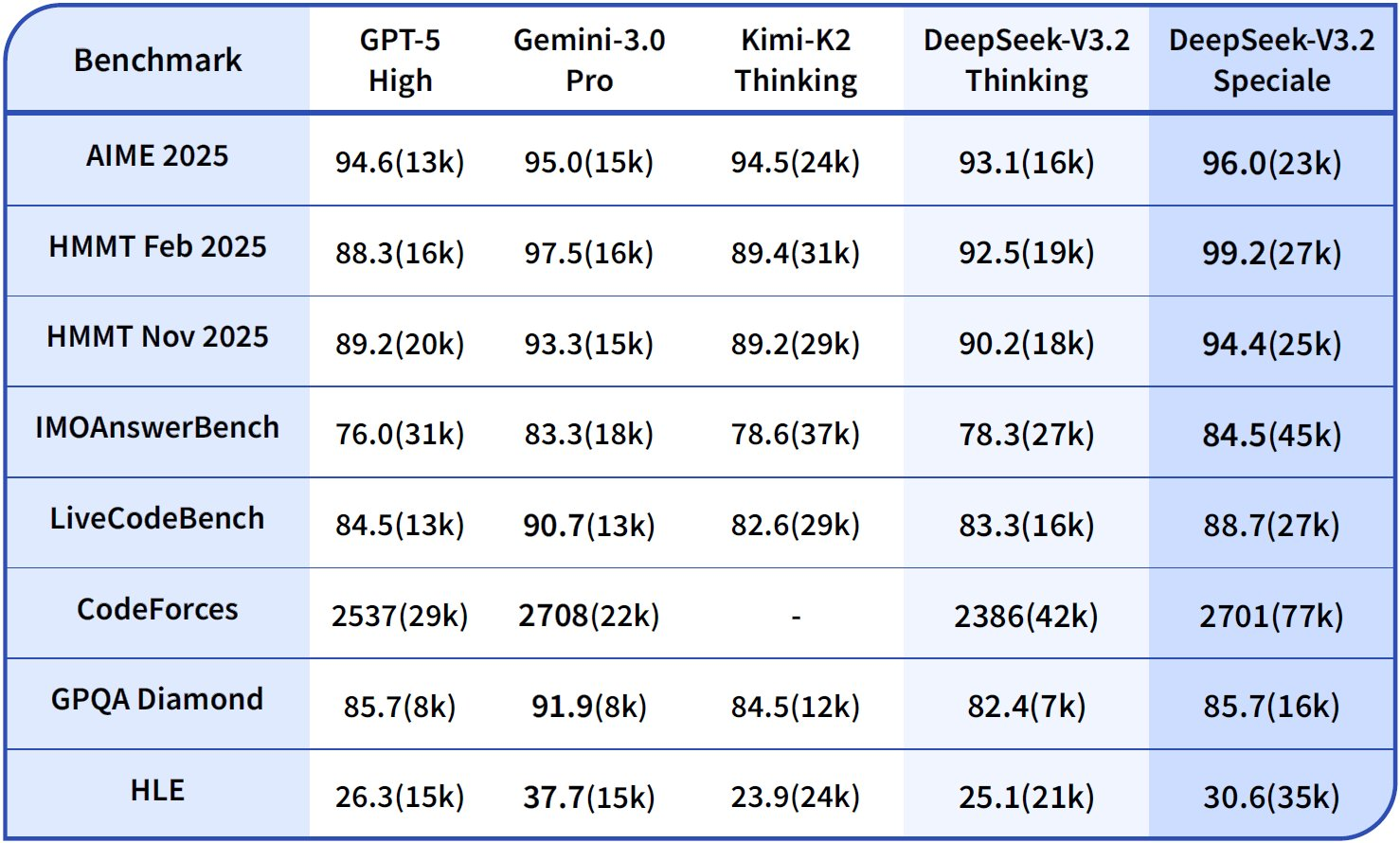
벤치마크는 DeepSeek-V3.2의 강점을 강조합니다. 추론 작업에서 AIME 2025 (pass@1)에서 93.1%를 달성하여 GPT-5-High의 90.2%를 능가합니다. 에이전트 기능의 경우 SWE-Bench Verified에서 2,537개의 문제를 해결하여 Claude-4.5-Sonnet의 2,536개를 앞섰습니다. 이러한 지표는 DeepSeek-V3.2를 추론 속도가 원시 지능만큼 중요한 생산 환경에서 균형 잡힌 '데일리 드라이버'로 자리매김하게 합니다.
또한 이 모델은 향후 업데이트에서 멀티모달 확장을 지원하지만, 현재 릴리스는 텍스트 기반 추론에 중점을 둡니다. 엔지니어들은 LoRA 어댑터를 사용하여 도메인별 데이터셋에 모델을 미세 조정하여 기본 기능을 유지하면서 법률 분석 또는 과학 시뮬레이션과 같은 특정 분야에 적응시킵니다. 결과적으로 오픈소스 접근은 벤더 종속 없이 신속한 프로토타이핑을 가능하게 합니다.
DeepSeek-V3.2-Speciale 탐색: 최고 추론 성능을 위한 최적화
DeepSeek-V3.2가 광범위한 유용성을 제공하는 반면, DeepSeek-V3.2-Speciale은 최대 인지 깊이를 요구하는 시나리오를 목표로 합니다. 이 변형은 엘리트 경쟁에서 Gemini-3.0-Pro와 경쟁하며 추론의 경계를 확장합니다. IMO 2025, CMO, ICPC World Finals 및 IOI 2025에서 금메달급 결과를 달성했는데, 이는 미묘한 논리적 연결과 창의적인 문제 해결 능력을 요구하는 업적입니다.
DeepSeek-V3.2-Speciale은 동일한 MoE 기반 위에 구축되었지만, 에이전트적 행동을 강조하는 향상된 인간 피드백 기반 강화 학습(RLHF) 단계를 통합합니다. 기본 모델과 달리 더 긴 내부 사고 과정을 생성하는데, 이는 더 많은 토큰을 소비하지만 다단계 환경에서의 도구 사용과 같은 작업에서 우수한 정확도를 제공합니다. 예를 들어, 1,800개 이상의 시뮬레이션 세계와 85,000개 이상의 지침에서 훈련 데이터를 통합하여, 보지 못한 시나리오를 견고하게 처리할 수 있게 합니다.
Hugging Face의 deepseek-ai/DeepSeek-V3.2-Speciale에서 모델 카드를 확인하세요. 다운로드 과정은 비슷합니다.
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
prompt = "Prove that the sum of angles in a triangle is 180 degrees."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=500, temperature=0.1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Speciale이 사용자 지정 어텐션 구현을 사용하므로 `trust_remote_code=True` 플래그에 유의하십시오. 이 설정은 비양자화 추론을 위해 최대 1TB의 VRAM을 요구하여 엣지 장치보다는 연구실에 이상적입니다.
성능 데이터는 이 모델의 우위를 강조합니다. 제공된 벤치마크 차트는 DeepSeek-V3.2-Speciale (파란색 막대)이 추론에서 선두를 달리고 있음을 보여줍니다: HMMT 2025 (pass@1)에서 99.0% 대 GPT-5-High의 97.5%, Codeforces (등급)에서 84.8% 정확도 대 Claude-4.5-Sonnet의 84.7%입니다. 에이전트 도메인에서는 Terminal-Bench v0.2 (84.3% 정확도) 및 Tool-Use (pass@1)에서 뛰어난 성능을 보이며, 종종 연쇄 작업에서 복합적으로 나타나는 미미한 차이로 우위를 점합니다. 그러나 V3.2보다 최대 50% 더 높은 토큰 사용량은 비용 관리를 위한 신중한 프롬프트 엔지니어링을 필요로 합니다.
Speciale은 초기 릴리스에서 기본 도구 사용 기능이 부족하므로, 개발자들은 하이브리드 에이전트를 위해 외부 API와 연결합니다. 이 접근 방식은 85,000개 이상의 지침 벤치마크에서 다른 모델들을 능가하는 평가에서 빛을 발합니다. 전반적으로 DeepSeek-V3.2-Speciale은 자동화된 정리 증명 또는 전략 계획 시뮬레이션과 같은 고위험 애플리케이션에 적합합니다.
오픈소스에서 API로 전환: 호스팅된 접근이 중요한 이유
로컬 배포는 제어권을 제공하지만, 확장은 하드웨어 프로비저닝 및 유지 관리와 같은 복잡성을 야기합니다. 개발자들은 즉각적인 접근, 사용량 기반 경제성, 관리형 인프라를 위해 API를 활용합니다. DeepSeek은 V3.2 및 V3.2-Speciale 모두에 대해 호스팅된 엔드포인트를 제공하여 OpenAI 스타일 인터페이스와의 호환성을 보장합니다. 이러한 전환은 팀이 설정 장벽을 우회하고 통합에 집중할 수 있도록 하여 프로토타이핑을 가속화합니다.
또한 API 접근은 속도 제한 및 캐싱과 같은 엔터프라이즈 기능을 제공하여 프로덕션 로드를 최적화합니다. 예를 들어, 캐시 히트는 입력 비용을 크게 절감하여 반복적인 쿼리를 경제적으로 만듭니다. 결과적으로 스타트업과 기업은 비용에 민감한 배포를 위해 이러한 엔드포인트를 채택합니다.
DeepSeek API 접근: 단계별 설정
엔지니어는 공식 플랫폼을 통해 DeepSeek API에 접근합니다. 먼저 계정을 생성하고 "API Keys" 섹션에서 API 키를 생성합니다. 이 키는 Authorization 헤더: Bearer YOUR_API_KEY를 통해 요청을 인증합니다.
기본 URL은 https://api.deepseek.com/v1입니다. DeepSeek-V3.2의 경우 모델 식별자 deepseek-v3.2를 사용합니다. DeepSeek-V3.2-Speciale은 임시 엔드포인트 https://api.deepseek.com/v3.2_speciale_expires_on_20251215에서 운영되며, 2025년 12월 15일 UTC 15:59까지 사용할 수 있습니다. 이 날짜 이후에는 표준 서비스에 통합됩니다.
간단히 OpenAI SDK를 설치합니다.
pip install openai
그런 다음 클라이언트를 구성합니다.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v1"
)
DeepSeek-V3.2에 대한 완료 요청을 보냅니다.
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant focused on reasoning."},
{"role": "user", "content": "Explain quantum entanglement in simple terms."}
],
max_tokens=300,
temperature=0.7
)
print(response.choices[0].message.content)
DeepSeek-V3.2-Speciale의 경우 base_url과 model을 조정합니다.
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215"
)
response = client.chat.completions.create(
model="deepseek-v3.2-speciale",
messages=[{"role": "user", "content": "Solve: Integrate e^x sin(x) dx."}],
max_tokens=500
)
이러한 호출은 프롬프트 및 완성 토큰을 포함한 사용량 통계와 함께 JSON 응답을 반환합니다. try-except 블록을 통해 오류를 처리하고, 속도 제한(예: V3.2의 경우 10,000 RPM)을 확인하세요.
또한 모델 이름에 /thinking을 추가하여 사고 모드를 활성화할 수 있습니다(예: deepseek-v3.2/thinking). 이는 단계별 추론을 트리거하여 복잡한 쿼리를 디버깅하는 데 이상적입니다.
API 가격: DeepSeek-V3.2 및 Speciale을 위한 비용 효율적인 확장
가격 책정은 API 채택의 핵심이며, DeepSeek은 백만 토큰당 투명하게 구조화합니다. 두 모델 모두 입력(캐시 히트/미스) 및 출력에 따라 동일한 요율로 청구됩니다. 캐시 히트는 세션 내에서 반복되는 접두사에 적용되어 반복적인 워크플로우의 비용을 줄입니다.
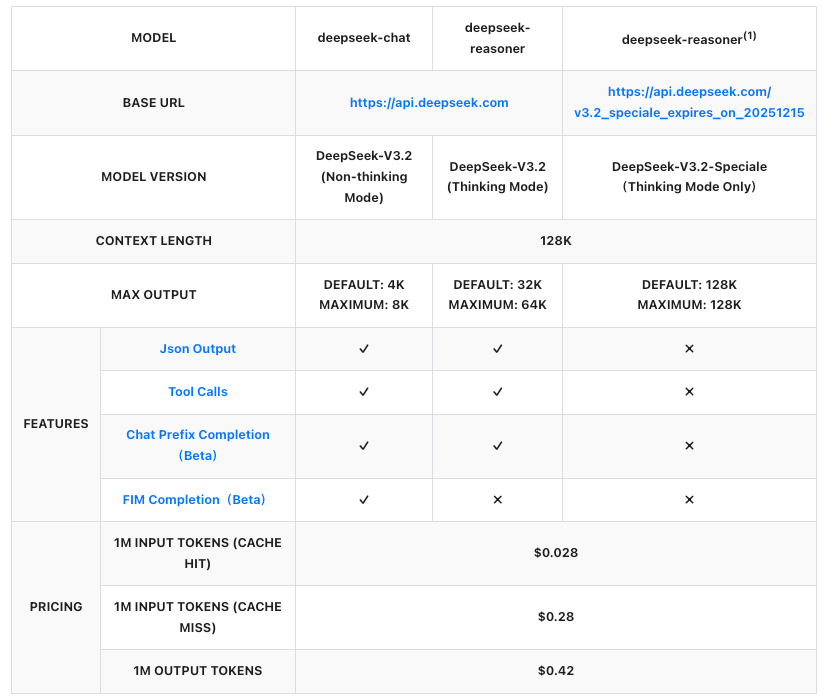
이 수치들은 이전 버전 대비 50% 이상의 비용 절감을 나타내며, DeepSeek을 독점 API와 경쟁력 있게 만듭니다. 예를 들어, 500토큰 프롬프트(캐시 미스)에 대해 1,000토큰 응답을 생성하는 데 약 0.00035달러가 소요되는데, 이는 대부분의 사용 사례에서 무시할 수 있는 수준입니다. 기업은 더 많은 볼륨에 대해 맞춤형 요금제를 협상하지만, 개발자에게는 종량제 방식이 적합합니다.
결과적으로 팀은 DeepSeek 대시보드의 토큰 예측기를 사용하여 비용을 예측합니다. Speciale의 더 높은 토큰 소비량을 고려해야 합니다. 추론 중심 쿼리는 비용을 두 배로 늘릴 수 있지만, Tau²와 같은 벤치마크(Speciale의 경우 pass@1에서 29.0% vs V3.2의 경우 25.1%)에서는 정확도를 네 배로 높일 수 있습니다.
Apidog와 통합: 효율적인 API 테스트 및 문서화
개발자들은 Apidog와 같은 도구를 사용하여 코딩 없이 API를 설계, 테스트 및 문서화하여 워크플로우를 간소화합니다. DeepSeek API 키를 Apidog의 환경 변수에 가져온 다음, V3.2 및 Speciale 엔드포인트에 대한 새 요청 컬렉션을 생성합니다.
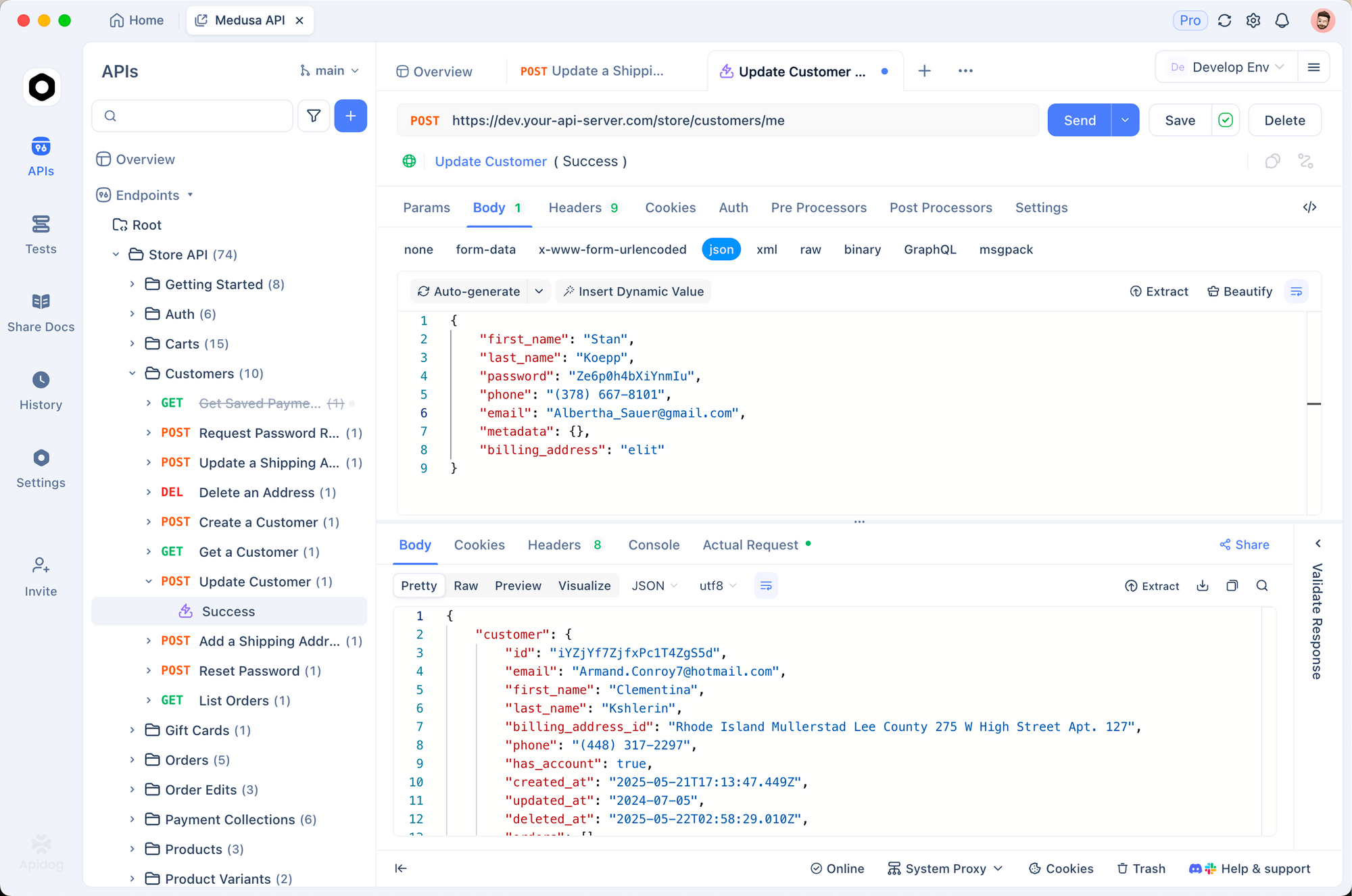
/chat/completions에 대한 POST 요청을 생성합니다.
- 헤더:
Authorization: Bearer {{api_key}},Content-Type: application/json - 본문: 모델, 메시지, 매개변수가 포함된 JSON 페이로드.
Apidog 인터페이스에서 테스트를 실행하면 응답과 어설션을 자동으로 생성합니다. 예를 들어, 수학 프롬프트에서 Speciale의 출력이 200토큰을 초과하는지 확인할 수 있습니다. 또한 Apidog는 OpenAPI 스펙을 내보내 팀 간의 인수인계를 용이하게 합니다.
이 통합은 시각적 차이점(visual diffs)으로 불일치를 강조하여 디버깅 시간을 40% 단축합니다. 팀은 또한 오프라인 개발을 위해 응답을 모의(mock)하여 실제 배포 전에 견고성을 확보합니다.
고급 기술: 도구 사용 및 에이전트 워크플로우
DeepSeek-V3.2는 도구 사용에 있어 사고(thinking) 기능을 도입하여 내부 추론과 외부 호출을 결합합니다. API 페이로드에 도구를 지정하세요:
tools = [
{
"type": "function",
"function": {
"name": "calculator",
"description": "Perform basic math",
"parameters": {
"type": "object",
"properties": {"expression": {"type": "string"}}
}
}
}
]
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "user", "content": "What is 15% of 250?"}],
tools=tools,
tool_choice="auto"
)
모델은 단계별로 추론한 다음, 필요한 경우 도구를 호출합니다. 현재 도구가 없는 Speciale은 다중 모델 체인에서 추론 오라클 역할을 훌륭하게 수행합니다.
에이전트의 경우 LangChain을 통해 오케스트레이션합니다. DeepSeek 호출을 작업을 동적으로 라우팅하는 에이전트에 래핑합니다. 이 설정은 벤치마크에 따라 SWE-Bench Verified 문제의 73.1%를 해결합니다.
프로덕션 배포를 위한 모범 사례
사고 모드를 활용하기 위해 연쇄 사고(chain-of-thought) 템플릿으로 프롬프트를 최적화하세요. API 메타데이터를 통해 토큰 사용량을 모니터링하고, 예산 한도에 대한 폴백을 구현하세요. 높은 처리량의 앱을 위해 Python의 비동기 클라이언트로 확장하세요.
보안은 키 로테이션과 IP 화이트리스팅을 요구합니다. 마지막으로, 기술 보고서의 벤치마크와 같은 기준으로 반복적으로 평가하고, 도메인에 맞게 하이퍼파라미터를 조정하세요.
결론: 지금 DeepSeek의 힘을 활용하세요
DeepSeek-V3.2 및 DeepSeek-V3.2-Speciale은 접근 가능한 AI 추론을 재정의합니다. 오픈소스의 유연성부터 API 효율성까지, 이 모델들은 개발자들이 더 스마트한 에이전트를 구축할 수 있도록 지원합니다. 로컬 실험으로 시작하여 호스팅된 엔드포인트로 마이그레이션하고, Apidog를 통합하여 원활한 테스트를 진행하세요. 벤치마크가 발전함에 따라 DeepSeek의 궤적은 훨씬 더 뛰어난 기능을 약속합니다. 여러분의 프로젝트를 선두에 세우세요.