
Tongyi DeepResearch dari Alibaba mendefinisikan ulang agen AI otonom dengan model Mixture of Experts (MoE) berparameter 30 miliar, mengaktifkan hanya 3 miliar parameter per token untuk riset web yang efisien dan fidelitas tinggi. Kekuatan sumber terbuka ini mengalahkan tolok ukur seperti Humanity's Last Exam (32.9% vs. OpenAI o3 24.9%) dan xbench-DeepSearch (75.0% vs. 67.0%), memungkinkan pengembang untuk menangani kueri kompleks multi-langkah—mulai dari analisis hukum hingga rencana perjalanan—tanpa keterikatan pada produk berpemilik.
Para insinyur di Tongyi Lab merekayasa agen ini untuk menaklukkan penalaran jangka panjang dan penggunaan alat dinamis secara langsung. Akibatnya, ia mengungguli model tertutup dalam sintesis dunia nyata, semuanya sambil berjalan secara lokal melalui Hugging Face. Dalam rincian teknis ini, kami membedah arsitektur jarang (sparse)nya, alur data otomatis, pelatihan yang dioptimalkan RL, dominasi tolok ukur, dan kiat penerapan. Pada akhirnya, Anda akan melihat bagaimana Tongyi DeepResearch—dan alat seperti Apidog—membuka AI agentik yang dapat diskalakan untuk proyek Anda.
Memahami Tongyi DeepResearch: Konsep Inti dan Inovasi
Tongyi DeepResearch mendefinisikan ulang AI agentik dengan berfokus pada pengambilan dan sintesis informasi mendalam. Tidak seperti model bahasa besar (LLM) tradisional yang unggul dalam generasi bentuk pendek, agen ini menavigasi lingkungan dinamis seperti peramban web untuk mengungkap wawasan yang bernuansa. Secara khusus, ia menggunakan arsitektur Mixture of Experts (MoE), di mana 30 miliar parameter penuh aktif secara selektif hanya 3 miliar per token. Efisiensi ini memungkinkan kinerja yang kuat pada perangkat keras dengan sumber daya terbatas sambil mempertahankan kesadaran kontekstual tinggi hingga 128K token.
Selain itu, model ini terintegrasi dengan mulus dengan paradigma inferensi yang meniru pengambilan keputusan mirip manusia. Dalam mode ReAct, ia berputar melalui langkah-langkah pemikiran, tindakan, dan observasi secara native, melewati rekayasa prompt yang berat. Untuk tugas yang lebih menuntut, mode Berat mengaktifkan kerangka kerja IterResearch, yang mengatur eksplorasi agen paralel untuk menghindari kelebihan konteks. Akibatnya, pengguna mencapai hasil yang unggul dalam skenario yang membutuhkan penyempurnaan berulang, seperti ulasan literatur akademik atau analisis pasar.
Apa yang membedakan Tongyi DeepResearch terletak pada komitmennya terhadap keterbukaan. Seluruh tumpukan—mulai dari bobot model hingga kode pelatihan—berada di platform seperti Hugging Face dan GitHub. Pengembang mengakses varian Tongyi-DeepResearch-30B-A3B secara langsung, memfasilitasi penyetelan halus untuk kebutuhan domain-spesifik. Selain itu, kompatibilitasnya dengan lingkungan Python standar menurunkan hambatan masuk. Misalnya, instalasi melibatkan perintah pip sederhana setelah menyiapkan lingkungan Conda dengan Python 3.10.
Beralih ke kegunaan praktis, Tongyi DeepResearch menggerakkan aplikasi yang menuntut keluaran yang dapat diverifikasi. Dalam penelitian hukum, ia menganalisis undang-undang dan yurisprudensi, mengutip sumber secara akurat. Demikian pula, dalam perencanaan perjalanan, ia menyusun rencana perjalanan multi-hari dengan merujuk silang data waktu nyata. Kemampuan ini berasal dari filosofi desain yang disengaja: memprioritaskan penalaran agentik daripada sekadar prediksi.
Arsitektur Tongyi DeepResearch: Efisiensi Berpadu dengan Kekuatan
Pada intinya, Tongyi DeepResearch memanfaatkan desain MoE jarang (sparse) untuk menyeimbangkan tuntutan komputasi dengan kekuatan ekspresif. Model ini hanya mengaktifkan sebagian ahli per token, merutekan input secara dinamis berdasarkan kompleksitas kueri. Pendekatan ini mengurangi latensi hingga 90% dibandingkan dengan rekanan padat, membuatnya layak untuk penerapan agen waktu nyata. Selain itu, jendela konteks 128K mendukung interaksi yang diperpanjang, penting untuk tugas yang melibatkan rantai dokumen panjang atau pencarian web berulir.
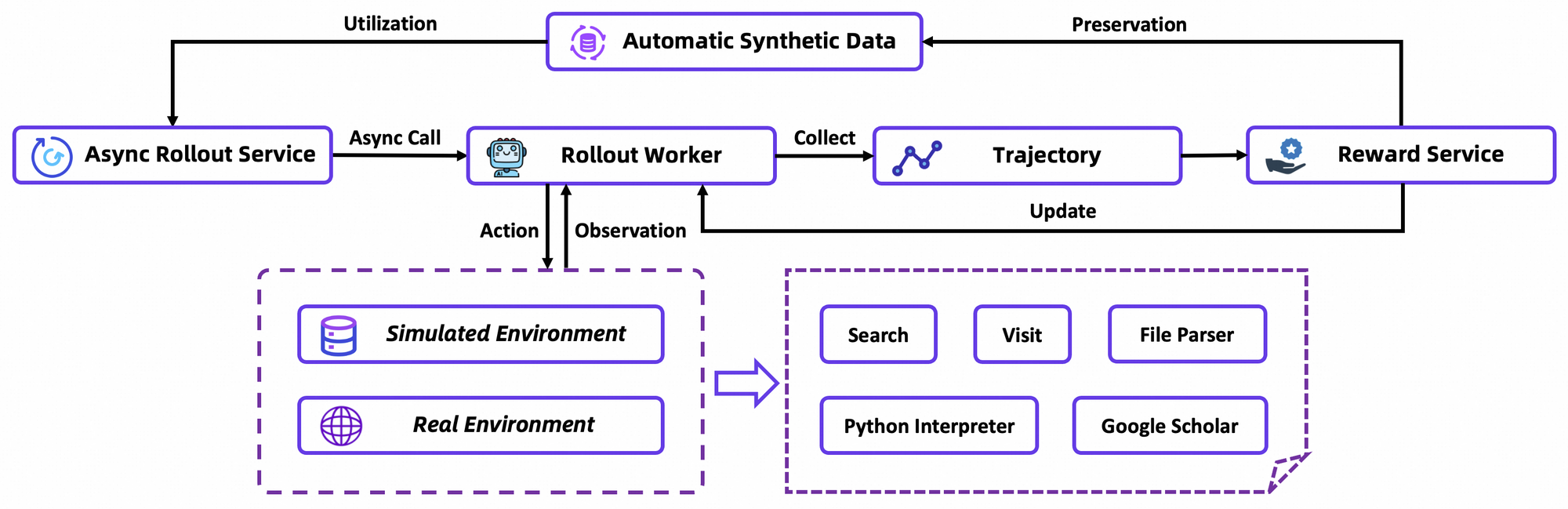
Komponen arsitektur utama meliputi tokenizer kustom yang dioptimalkan untuk token agentik—seperti awalan tindakan dan pembatas observasi—dan rangkaian alat tertanam untuk navigasi browser, pengambilan, dan komputasi. Kerangka kerja ini mendukung integrasi pembelajaran penguatan (RL) on-policy, di mana agen belajar dari simulasi rollout di lingkungan yang stabil. Akibatnya, model menunjukkan lebih sedikit halusinasi dalam pemanggilan alat, sebagaimana dibuktikan oleh skor tingginya pada tolok ukur penggunaan alat.
Selain itu, Tongyi DeepResearch menggabungkan memori pengetahuan berlabuh entitas, yang berasal dari sintesis data berbasis grafik. Mekanisme ini mengaitkan respons ke entitas faktual, meningkatkan keterlacakan. Misalnya, selama kueri tentang kemajuan komputasi kuantum, agen mengambil dan mensintesis makalah melalui alat mirip WebSailor, mendasari keluaran pada sumber yang dapat diverifikasi. Jadi, arsitektur tidak hanya memproses informasi tetapi juga secara aktif mengkurasinya.
Sebagai ilustrasi, pertimbangkan penanganan input multi-modal oleh model. Meskipun terutama berbasis teks, ekstensi melalui repo GitHub memungkinkan integrasi dengan parser gambar atau eksekutor kode. Pengembang mengkonfigurasi ini dalam skrip inferensi, menentukan jalur untuk dataset dalam format JSONL. Dengan demikian, arsitektur ini mendorong ekstensibilitas, mengundang kontribusi dari komunitas sumber terbuka.
Sintesis Data Otomatis: Mendorong Kemampuan Tongyi DeepResearch
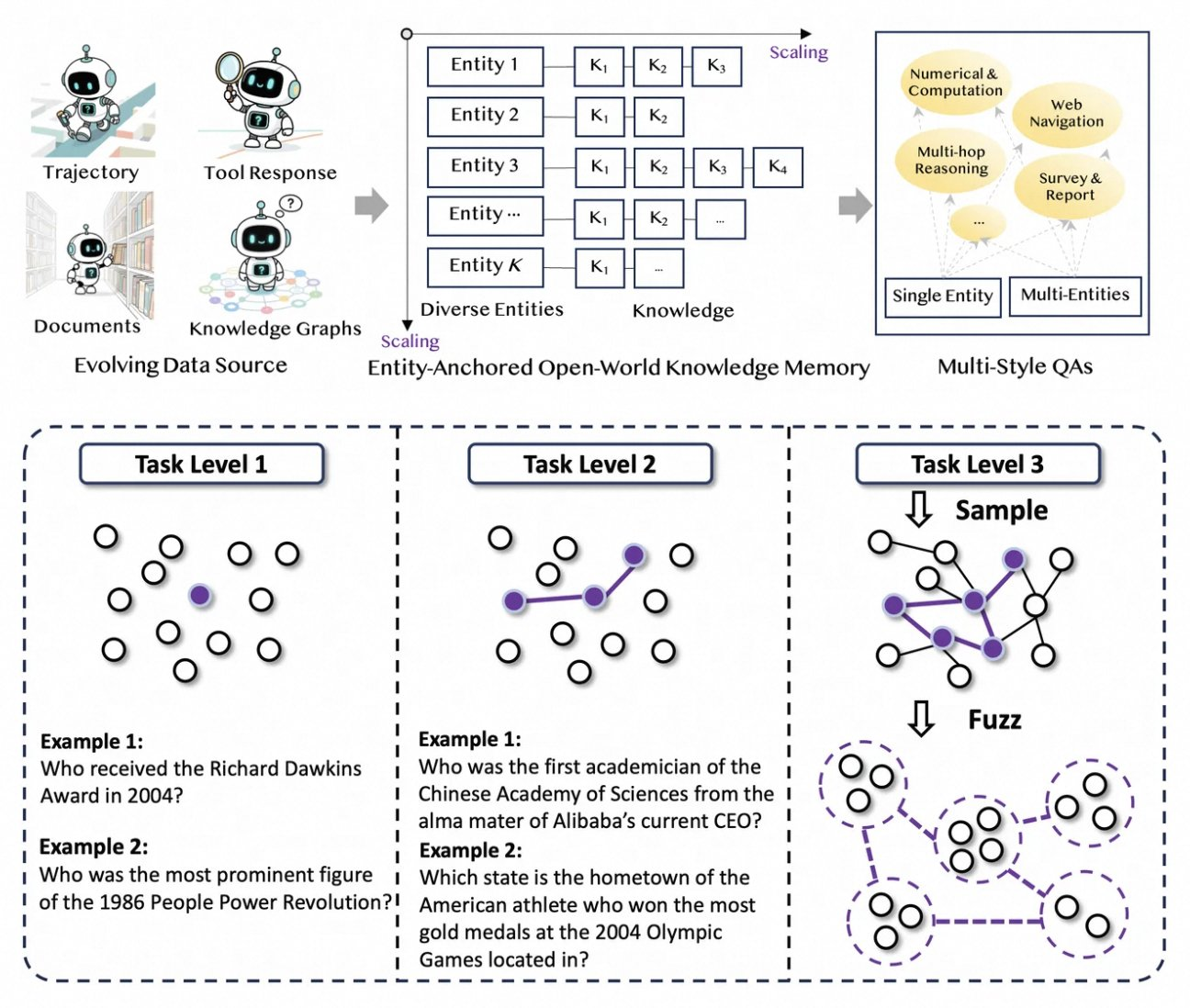
Tongyi DeepResearch berkembang pesat pada alur data baru yang sepenuhnya otomatis yang menghilangkan hambatan anotasi manusia. Proses dimulai dengan AgentFounder, mesin sintesis yang mengatur ulang korpus mentah—dokumen, penelusuran web, dan grafik pengetahuan—menjadi pasangan QA berlabuh entitas. Langkah ini menghasilkan lintasan yang beragam untuk pra-pelatihan berkelanjutan (CPT), mencakup rantai penalaran, panggilan alat, dan pohon keputusan.
Selanjutnya, alur meningkatkan kesulitan melalui peningkatan berulang. Untuk pasca-pelatihan, ia menggunakan metode berbasis grafik seperti WebSailor-V2 untuk mensimulasikan tantangan "super-manusia", seperti pertanyaan tingkat PhD yang dimodelkan melalui teori himpunan. Akibatnya, dataset mencakup jutaan interaksi fidelitas tinggi, memastikan model menggeneralisasi di seluruh domain. Khususnya, otomatisasi ini berskala linier dengan komputasi, memungkinkan pembaruan berkelanjutan tanpa kurasi manual.
Selain itu, Tongyi DeepResearch menggabungkan data multi-gaya untuk ketahanan. Catatan sintesis tindakan menangkap pola penggunaan alat, sementara pasangan QA multi-tahap menyempurnakan keterampilan perencanaan. Dalam praktiknya, ini menghasilkan agen yang beradaptasi dengan lingkungan web yang bising, menyaring cuplikan yang tidak relevan secara efektif. Untuk pengembang, repo menyediakan skrip untuk mereplikasi alur ini, memungkinkan pembuatan dataset kustom.
Dengan memprioritaskan kualitas daripada kuantitas, strategi sintesis mengatasi jebakan umum dalam pelatihan agen, seperti pergeseran distribusi. Akibatnya, model yang dilatih dengan cara ini menunjukkan keselarasan yang unggul dengan tugas-tugas dunia nyata, seperti yang terlihat dalam dominasi tolok ukurnya.
Alur Pelatihan Ujung-ke-Ujung: Dari CPT hingga Optimasi RL
Pelatihan Tongyi DeepResearch berlangsung dalam alur yang mulus: CPT Agentik, Penyetelan Halus Terawasi (SFT), dan Pembelajaran Penguatan (RL). Pertama, CPT mengekspos model dasar ke data agentik yang luas, memasukkannya dengan prior navigasi web dan sinyal kebaruan. Fase ini mengaktifkan kemampuan laten, seperti perencanaan implisit, melalui pemodelan bahasa bertopeng pada lintasan.

Setelah CPT, SFT menyelaraskan model dengan format instruksional, menggunakan rollout sintetis untuk mengajarkan formulasi tindakan yang tepat. Di sini, model belajar menghasilkan siklus ReAct yang koheren, meminimalkan kesalahan dalam penguraian observasi. Beralih dengan mulus, tahap RL menggunakan Group Relative Policy Optimization (GRPO), algoritma on-policy kustom.
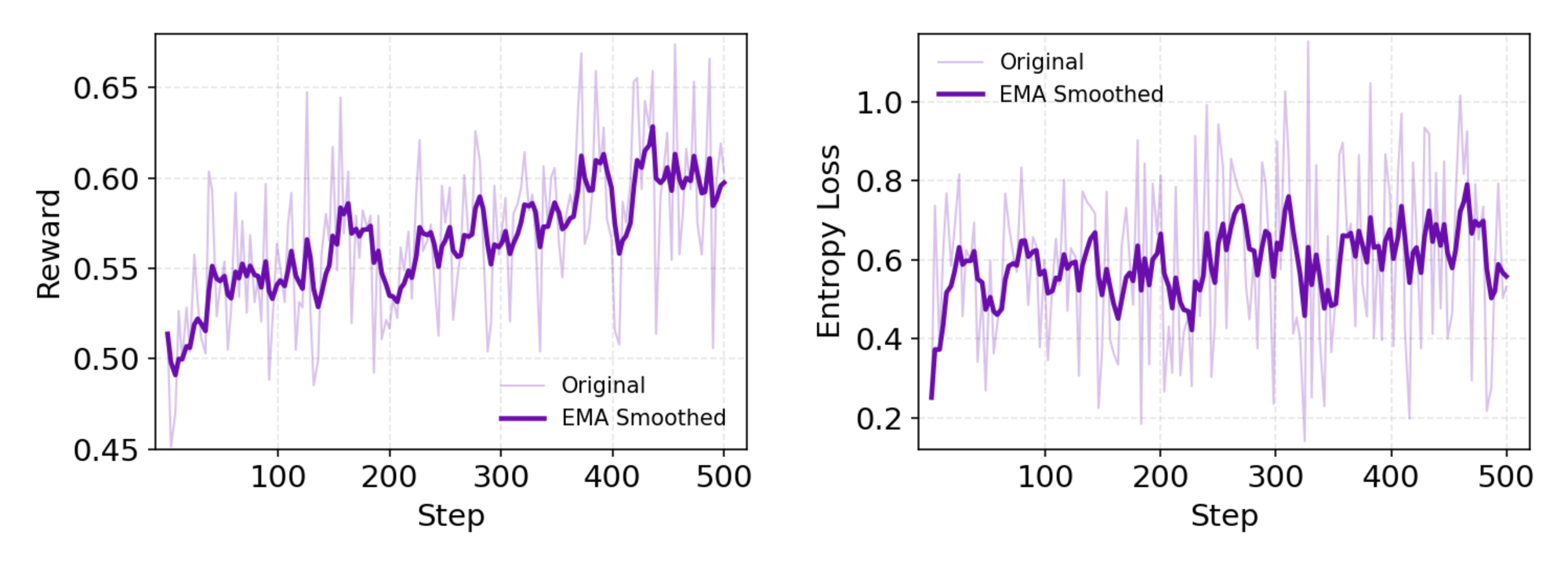
GRPO menghitung gradien kebijakan tingkat token dengan estimasi keuntungan leave-one-out, mengurangi varian dalam pengaturan non-stasioner. Ini juga menyaring sampel negatif secara konservatif, menstabilkan pembaruan dalam simulator kustom—basis data Wikipedia offline yang dipasangkan dengan kotak pasir alat. Rollout asinkron melalui kerangka kerja rLLM mempercepat konvergensi, mencapai SOTA (State-of-the-Art) dengan komputasi yang moderat.
Secara rinci, lingkungan RL mensimulasikan interaksi browser dengan setia, memberi penghargaan pada keberhasilan multi-langkah daripada tindakan tunggal. Ini mendorong perencanaan jangka panjang, di mana agen berulang kali mencoba kegagalan parsial. Sebagai catatan teknis, fungsi kerugian menggabungkan divergensi KL untuk konservatisme, mencegah keruntuhan mode. Pengembang mereplikasi ini melalui skrip evaluasi repo, membandingkan kebijakan kustom.
Secara keseluruhan, alur ini menandai terobosan: ia menghubungkan pra-pelatihan ke penerapan tanpa silo, menghasilkan agen yang berkembang melalui coba-coba.
Kinerja Tolok Ukur: Bagaimana Tongyi DeepResearch Unggul
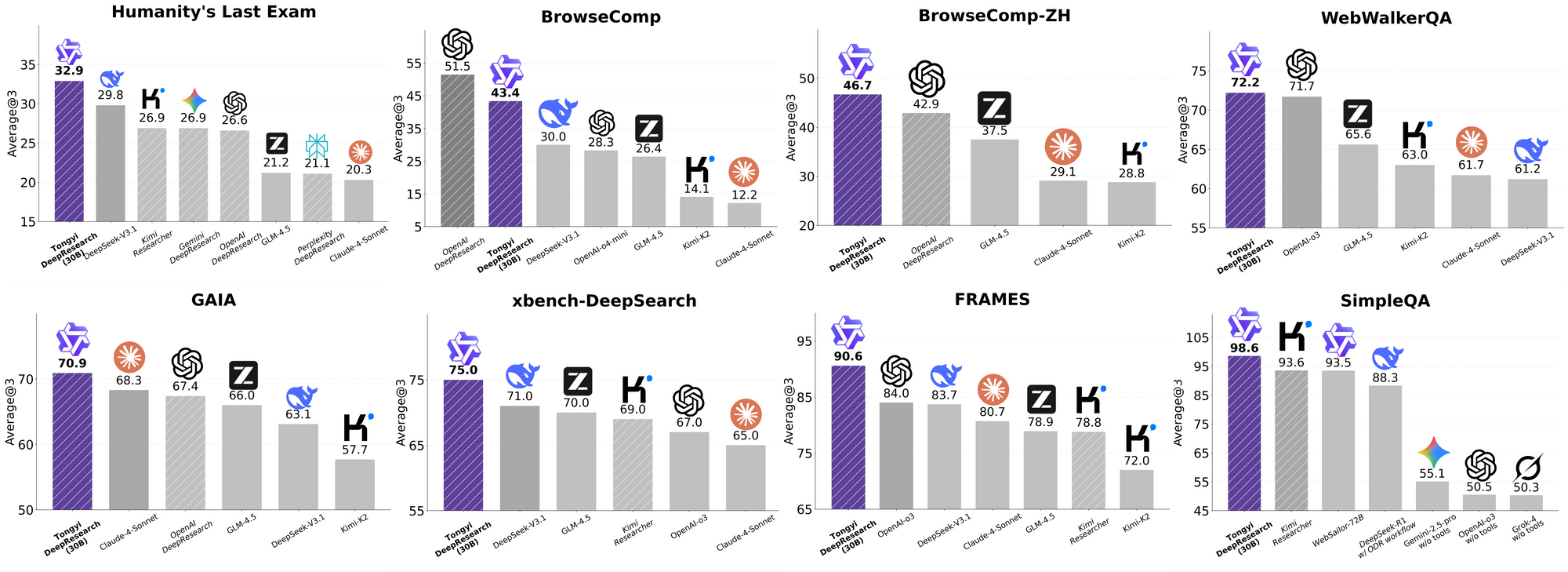
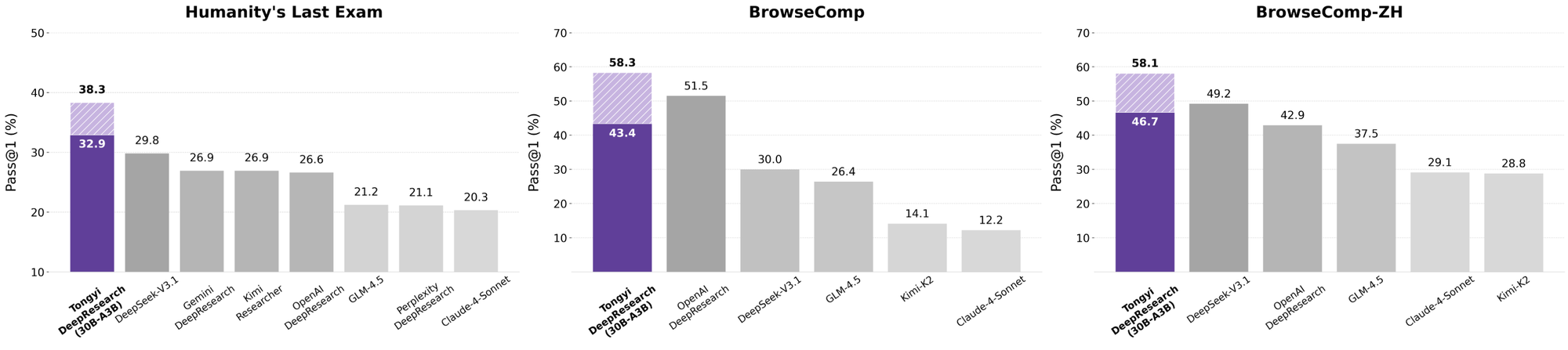
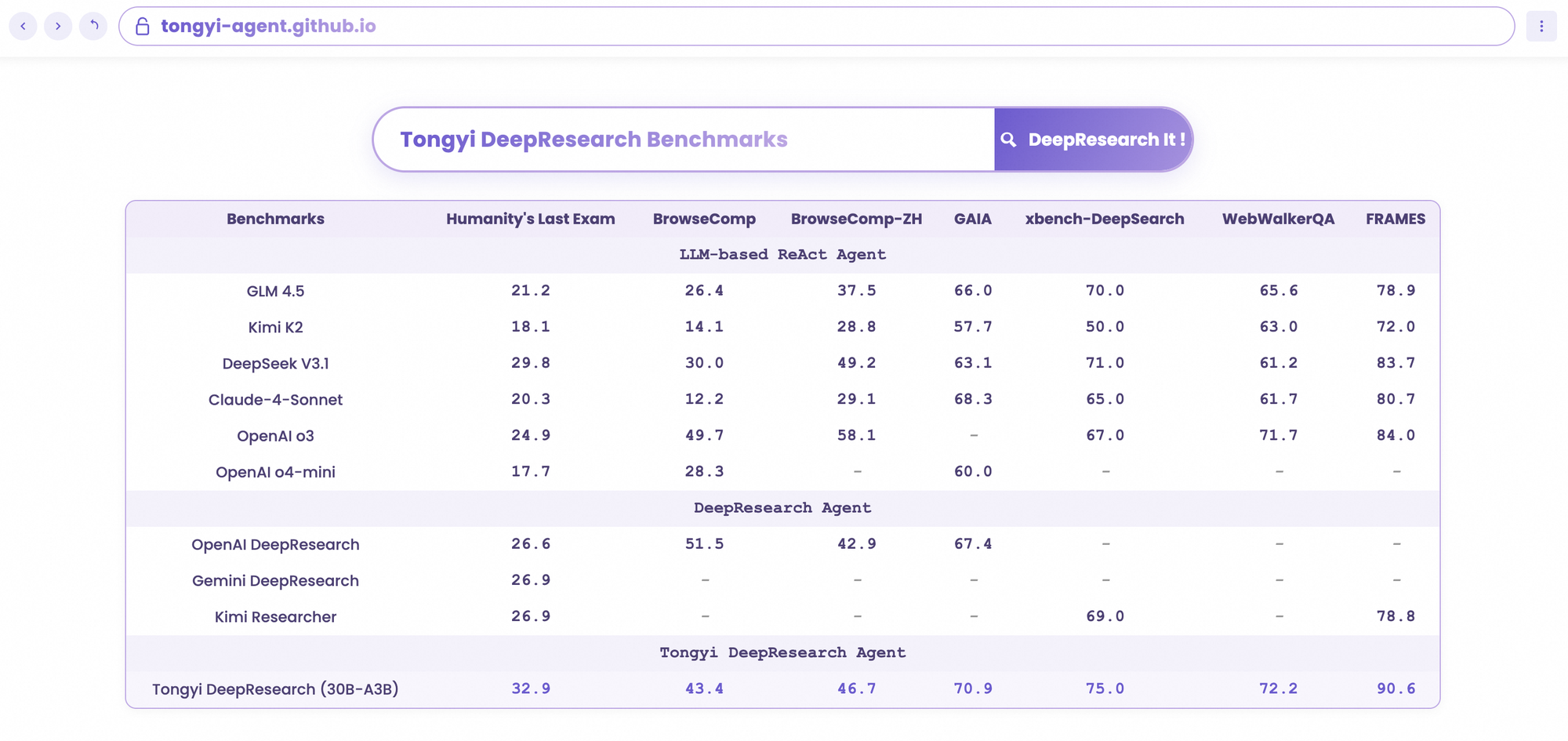
Tongyi DeepResearch bersinar dalam tolok ukur agentik yang ketat, memvalidasi desainnya. Pada Humanity's Last Exam (HLE), uji penalaran akademik, ia mencetak 32.9 dalam mode ReAct—melampaui o3 OpenAI di 24.9. Selisih ini melebar dalam mode Berat menjadi 38.3, menyoroti efikasi IterResearch.
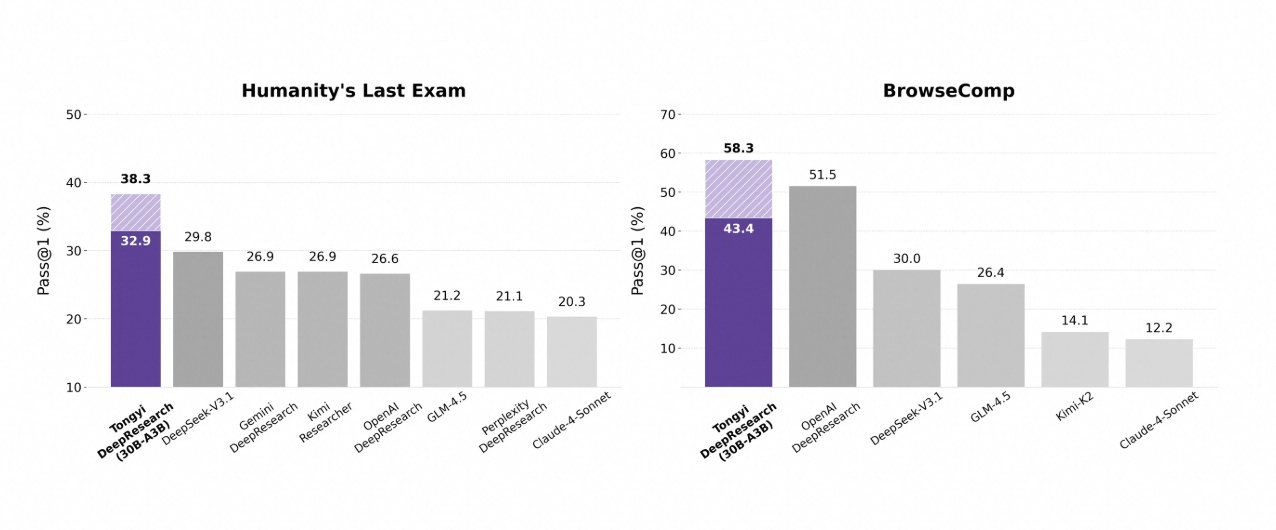
Demikian pula, BrowseComp mengevaluasi pencarian informasi yang kompleks; Tongyi mencapai 43.4 (EN) dan 46.7 (ZH), sedikit mengungguli o3 yang 49.7 dan 58.1 masing-masing dalam efisiensi. Tolok ukur xbench-DeepSearch, berpusat pada pengguna untuk kueri mendalam, menunjukkan Tongyi di 75.0 versus o3 di 67.0, menggarisbawahi sintesis pengambilan yang unggul.
Metrik lain memperkuat ini: FRAMES di 90.6 (vs. o3 84.0), GAIA di 70.9, dan SimpleQA di 95.0. Bagan komparatif memvisualisasikan ini, dengan batang untuk Tongyi DeepResearch menjulang di atas Gemini, Claude, dan lainnya di HLE, BrowseComp, xbench, FRAMES, dan lainnya. Batang biru menunjukkan keunggulan Tongyi, garis dasar abu-abu menunjukkan kekurangan pesaing.
Hasil ini berasal dari optimasi yang ditargetkan, seperti perutean ahli selektif untuk tugas pencarian. Jadi, Tongyi DeepResearch tidak hanya bersaing tetapi memimpin dalam agentik sumber terbuka.
Membandingkan Tongyi DeepResearch dengan Pemimpin Industri
Ketika pengembang mengevaluasi agen AI, perbandingan mengungkapkan nilai sebenarnya. Tongyi DeepResearch, pada 30B-A3B, mengungguli o3 OpenAI di HLE (32.9 vs. 24.9) dan xbench (75.0 vs. 67.0), meskipun skala o3 lebih besar. Terhadap Gemini Google, ia mengklaim 35.2 di BrowseComp-ZH, keunggulan 10 poin.
Model berpemilik seperti Claude 3.5 Sonnet tertinggal dalam penggunaan alat; 90.6 Tongyi pada FRAMES mengerdilkan 84.3 Sonnet. Rekan sumber terbuka, seperti varian Llama, tertinggal lebih jauh—misalnya, 21.1 pada HLE. Kepadatan MoE Tongyi memungkinkan kesetaraan ini, mengonsumsi lebih sedikit komputasi inferensi.
Selain itu, aksesibilitas memiringkan timbangan: sementara o3 menuntut kredit API, Tongyi berjalan secara lokal melalui Hugging Face. Untuk alur kerja yang padat API, pasangkan dengan Apidog untuk memalsukan titik akhir, mensimulasikan panggilan alat secara efisien.
Intinya, Tongyi DeepResearch mendemokratisasikan kinerja elit, menantang ekosistem tertutup.
Aplikasi Dunia Nyata: Tongyi DeepResearch Beraksi
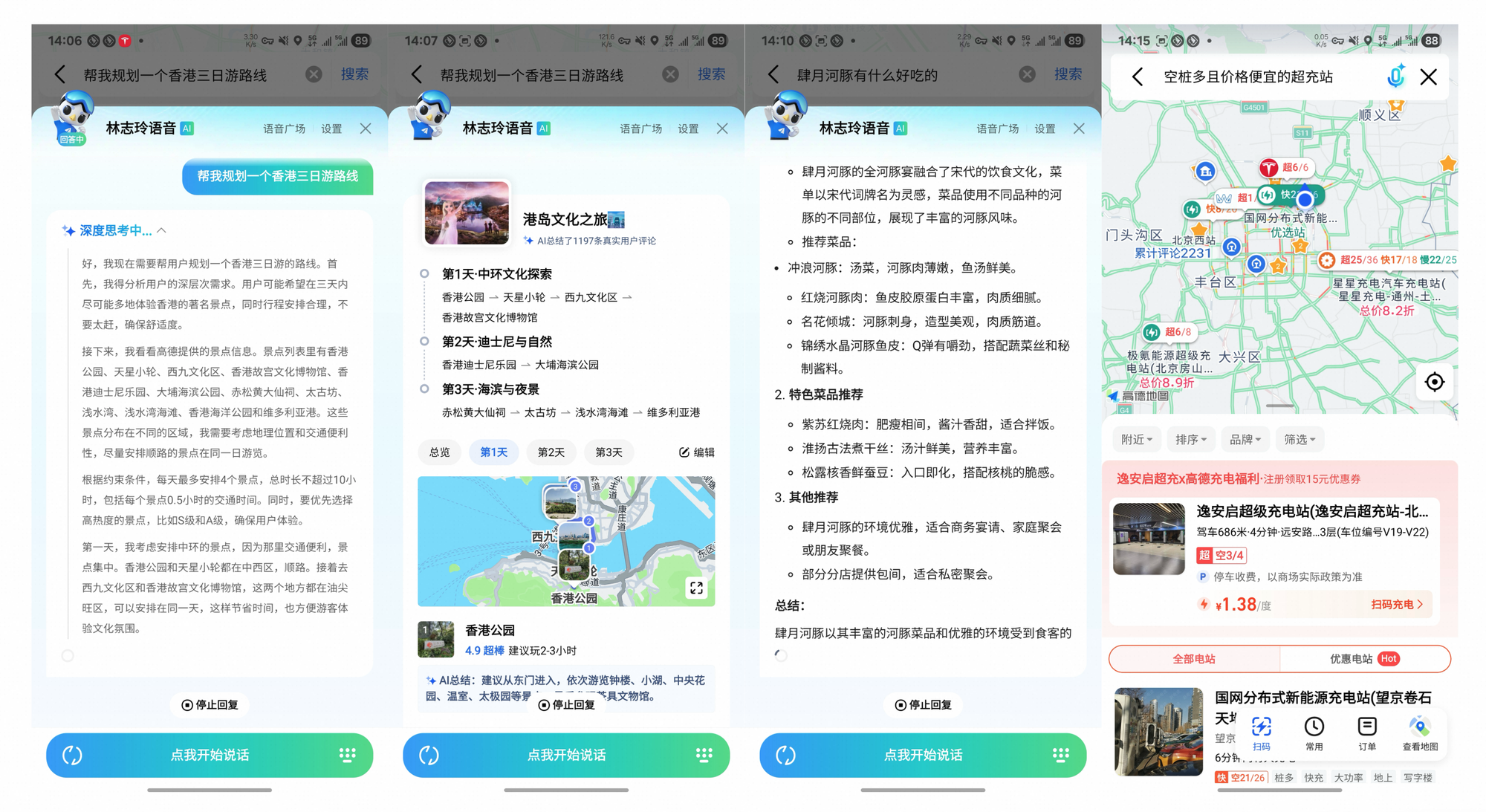
Tongyi DeepResearch melampaui tolok ukur, mendorong dampak nyata. Di Gaode Mate, aplikasi navigasi Alibaba, ia merencanakan perjalanan yang rumit—mengkueri penerbangan, hotel, dan acara secara paralel melalui mode Berat. Pengguna menerima rencana perjalanan yang disintesis dengan kutipan, mengurangi waktu perencanaan sebesar 70%.
Demikian pula, Tongyi FaRui merevolusi penelitian hukum. Agen menganalisis undang-undang, merujuk silang preseden, dan menghasilkan ringkasan dengan tautan yang dapat diverifikasi. Profesional memverifikasi keluaran dengan cepat, meminimalkan kesalahan dalam domain berisiko tinggi.
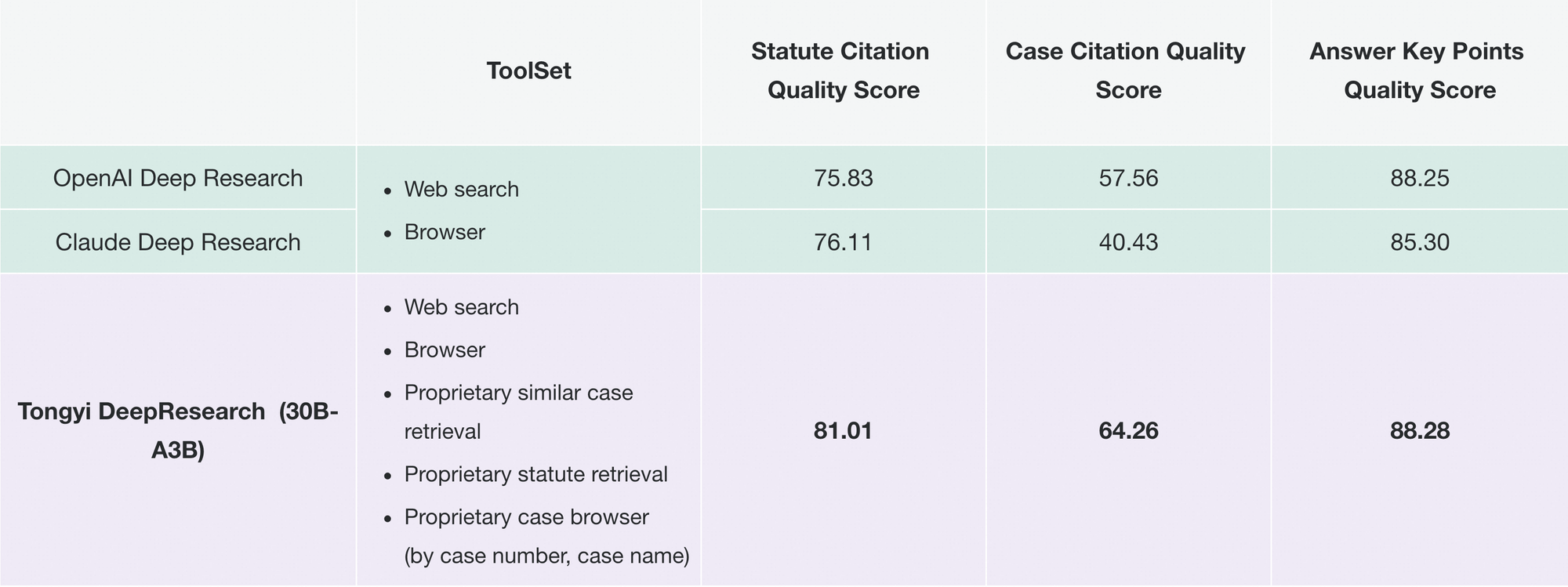
Di luar ini, perusahaan mengadaptasinya untuk intelijen pasar: mengikis data pesaing, mensintesis tren. Modularitas repo mendukung ekstensi semacam itu—menambahkan alat kustom melalui konfigurasi JSON.
Seiring pertumbuhan adopsi, Tongyi DeepResearch berintegrasi ke dalam ekosistem seperti LangChain, memperkuat swarm agen. Untuk pengembang API, Apidog melengkapi ini dengan memvalidasi integrasi sebelum penerapan.
Kasus-kasus ini menunjukkan skalabilitas: dari aplikasi konsumen hingga alat B2B, model memberikan otonomi yang andal.
Memulai dengan Tongyi DeepResearch: Panduan Pengembang
Implementasikan Tongyi DeepResearch dengan mudah menggunakan repo GitHub-nya. Mulai dengan membuat lingkungan Conda: conda create -n deepresearch python=3.10. Aktifkan dan instal: pip install -r requirements.txt.
Siapkan data di eval_data/ sebagai JSONL, dengan kunci question dan answer. Untuk file, tambahkan nama di awal pertanyaan dan simpan di file_corpus/. Edit run_react_infer.sh untuk jalur model (misalnya, URL Hugging Face) dan kunci API untuk alat.
Jalankan: bash run_react_infer.sh. Keluaran akan berada di jalur yang ditentukan, siap untuk analisis.
Untuk mode Berat, konfigurasikan parameter IterResearch dalam kode—atur jumlah agen dan putaran. Bandingkan melalui skrip evaluation/, bandingkan dengan baseline.
Pecahkan masalah dengan log; masalah umum seperti ketidakcocokan tokenizer diselesaikan melalui pemeriksaan tensor BF16. Untuk meningkatkan, unduh Apidog gratis untuk simulasi API, menguji titik akhir alat tanpa panggilan langsung.
Pengaturan ini membekali Anda untuk membuat prototipe agen dengan cepat.
Arah Masa Depan: Menskalakan Tongyi DeepResearch Lebih Lanjut
Ke depan, Tongyi Lab menargetkan perluasan konteks di luar 128K, memungkinkan cakrawala ultra-panjang seperti analisis sepanjang buku. Mereka merencanakan validasi pada basis MoE yang lebih besar, menyelidiki batas skalabilitas.
Peningkatan RL mencakup rollout parsial untuk efisiensi dan metode off-policy untuk mengurangi pergeseran. Kontribusi komunitas dapat mengintegrasikan alat visi atau multi-bahasa, memperluas cakupan.
Saat sumber terbuka berkembang, Tongyi DeepResearch akan menjadi jangkar kemajuan kolaboratif, mendorong pencarian AGI.
Kesimpulan: Rangkul Era Tongyi DeepResearch
Tongyi DeepResearch mengubah AI agentik, memadukan efisiensi, keterbukaan, dan keunggulan. Tolok ukur, arsitektur, dan aplikasinya menempatkannya sebagai pemimpin, mengungguli pesaing seperti penawaran OpenAI. Para pengembang, manfaatkan kekuatan ini—unduh modelnya, bereksperimen, dan integrasikan dengan Apidog untuk API yang mulus.
Dalam bidang yang berlomba menuju otonomi, Tongyi DeepResearch mempercepat kemajuan. Mulai membangun hari ini; wawasan menanti.