
Pengembang mencari cara efisien untuk mengintegrasikan model bahasa canggih ke dalam aplikasi mereka. INTELLECT-3 muncul sebagai pilihan menarik berkat fondasi sumber terbuka dan kinerja yang kuat dalam tugas penalaran. Model ini, yang dikembangkan oleh Prime Intellect, menonjol dengan arsitektur Mixture-of-Experts (MoE) berparameter 106 miliar, yang memungkinkan efisiensi tinggi dalam menangani komputasi kompleks.
Memahami INTELLECT-3: Kekuatan Sumber Terbuka
Prime Intellect merilis INTELLECT-3 sebagai model sumber terbuka sepenuhnya, yang memberdayakan peneliti dan pengembang untuk menyesuaikan dan memperluas kemampuannya tanpa batasan hak milik. Transparansi ini mendorong inovasi di bidang seperti pembelajaran penguatan (RL) dan sistem AI agen. Anda dapat mengakses paket lengkap, termasuk bobot model, kerangka kerja pelatihan, dataset, lingkungan RL, dan alat evaluasi, langsung dari repositori Prime Intellect.

Intinya, INTELLECT-3 menggunakan arsitektur MoE berparameter 106 miliar, dibangun di atas model dasar GLM-4.5-Air. Desain MoE mengarahkan input ke sub-jaringan "pakar" khusus, yang mengoptimalkan penggunaan komputasi dan mempercepat inferensi. Misalnya, selama pemrosesan, model hanya mengaktifkan sebagian kecil parameter yang relevan dengan kueri, mengurangi latensi sambil mempertahankan akurasi. Pengaturan ini terbukti sangat efektif untuk tugas yang membutuhkan keahlian selektif, seperti penurunan matematis atau pembuatan kode.
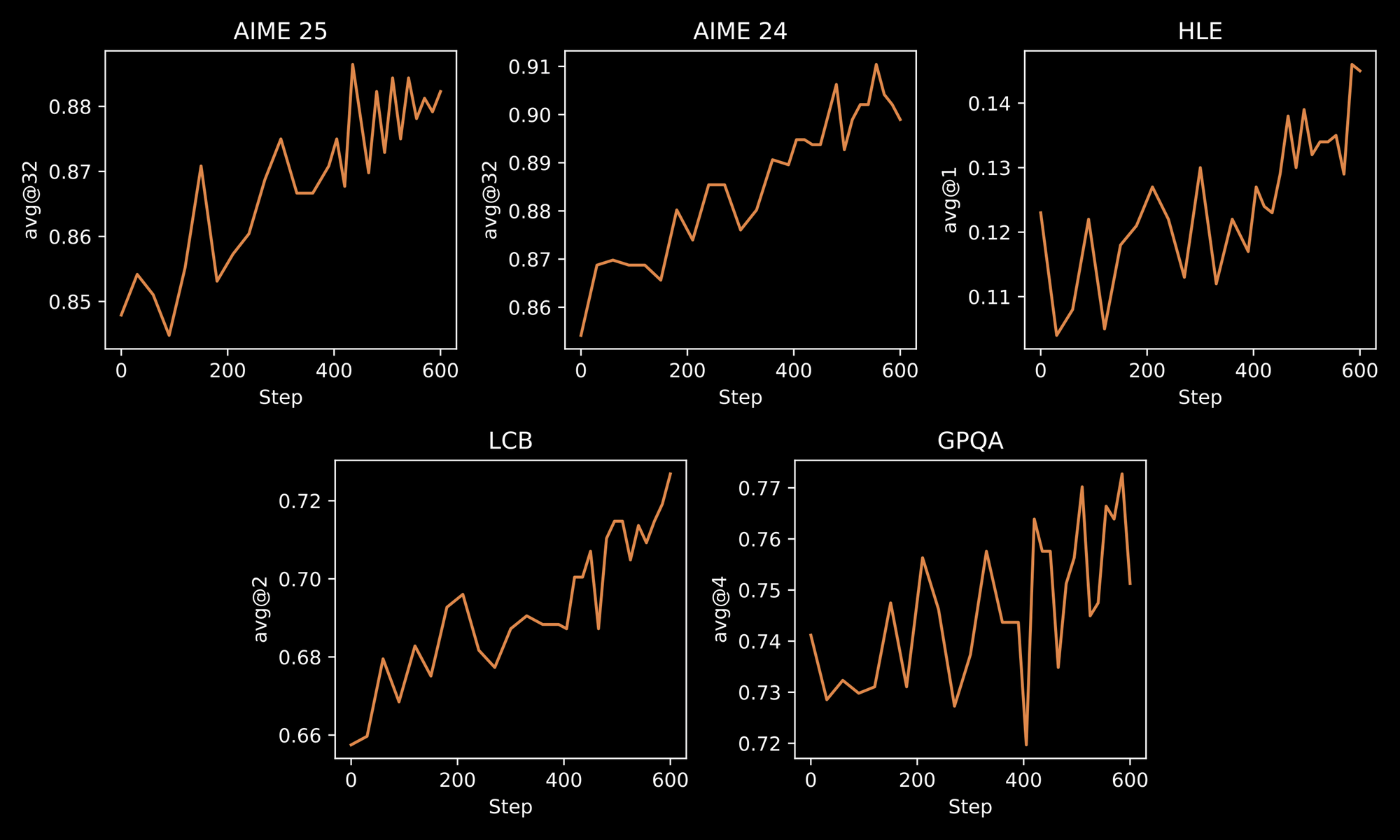
Proses pelatihan menggarisbawahi ketahanan INTELLECT-3. Para insinyur menerapkan metodologi dua tahap: Supervised Fine-Tuning (SFT) awal pada dataset terpilih, diikuti oleh RL skala besar menggunakan kerangka kerja prime-rl kustom. prime-rl beroperasi sebagai sistem RL off-policy asinkron, yang menangani simulasi paralel yang luas secara efisien. Anda mendapatkan manfaat dari ini melalui perilaku model yang lebih baik di lingkungan dinamis, seperti pemecahan masalah iteratif atau perencanaan multi-langkah.
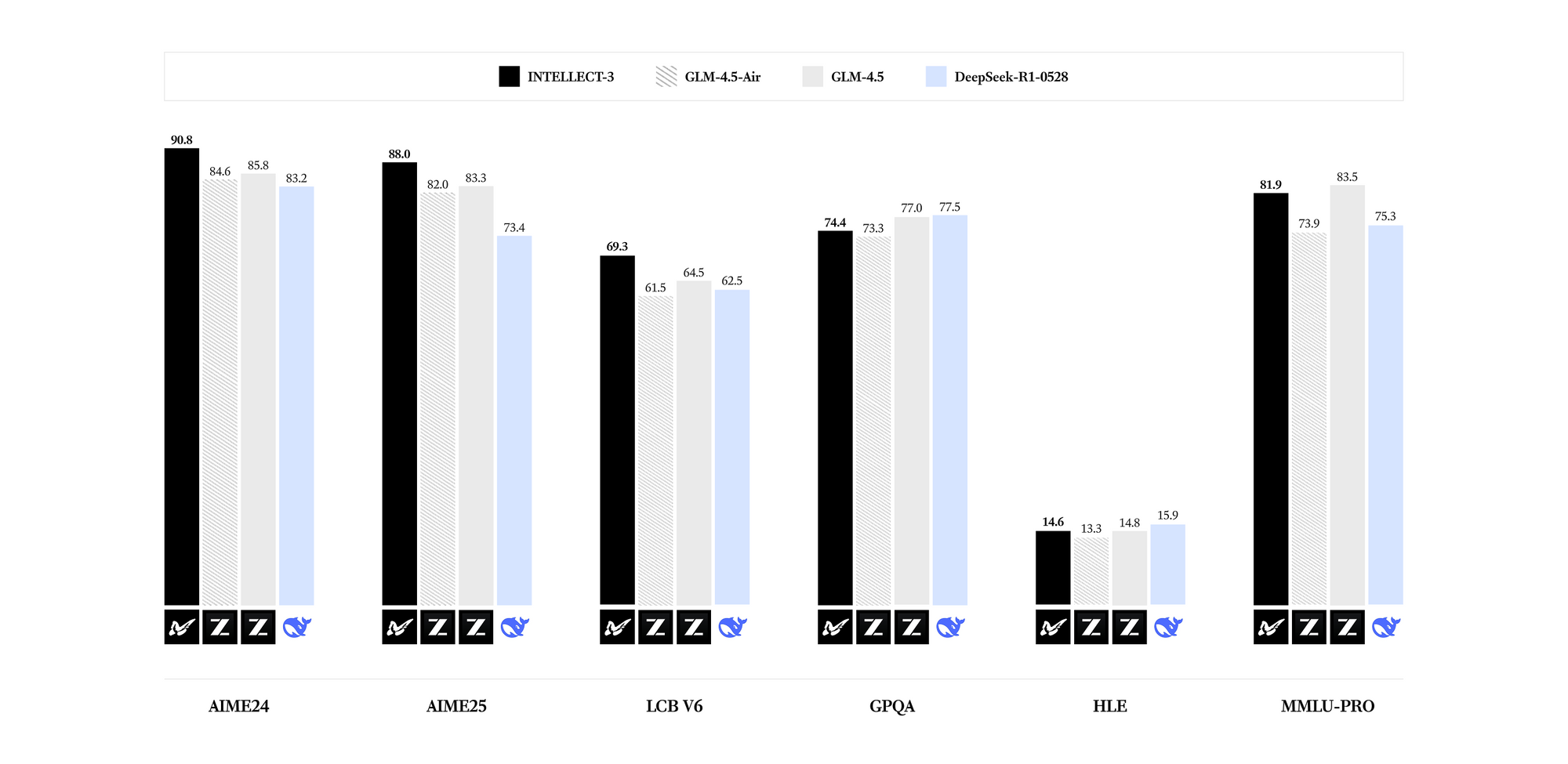
INTELLECT-3 unggul dalam domain khusus. Tolok ukur menunjukkan hasil terbaik di kelasnya untuk jumlah parameternya di seluruh bidang matematika (misalnya, skor GSM8K melebihi 95%), pengkodean (tingkat kelulusan HumanEval di atas 85%), sains (akurasi GPQA di atas 60%), dan penalaran (skor MMLU mendekati 80%). Dibandingkan dengan model yang lebih padat seperti Llama 3.1 70B, INTELLECT-3 mencapai efisiensi superior—hingga 2x inferensi lebih cepat pada perangkat keras yang setara—karena pola aktivasi yang jarang. Akibatnya, Anda dapat menerapkannya dalam pengaturan yang dibatasi sumber daya tanpa mengorbankan kualitas output.
Infrastruktur pendukung meningkatkan daya tarik sumber terbukanya. Verifiers & Environments Hub menyediakan lebih dari 500 lingkungan RL, mulai dari teka-teki sederhana hingga pembuktian teorema canggih.
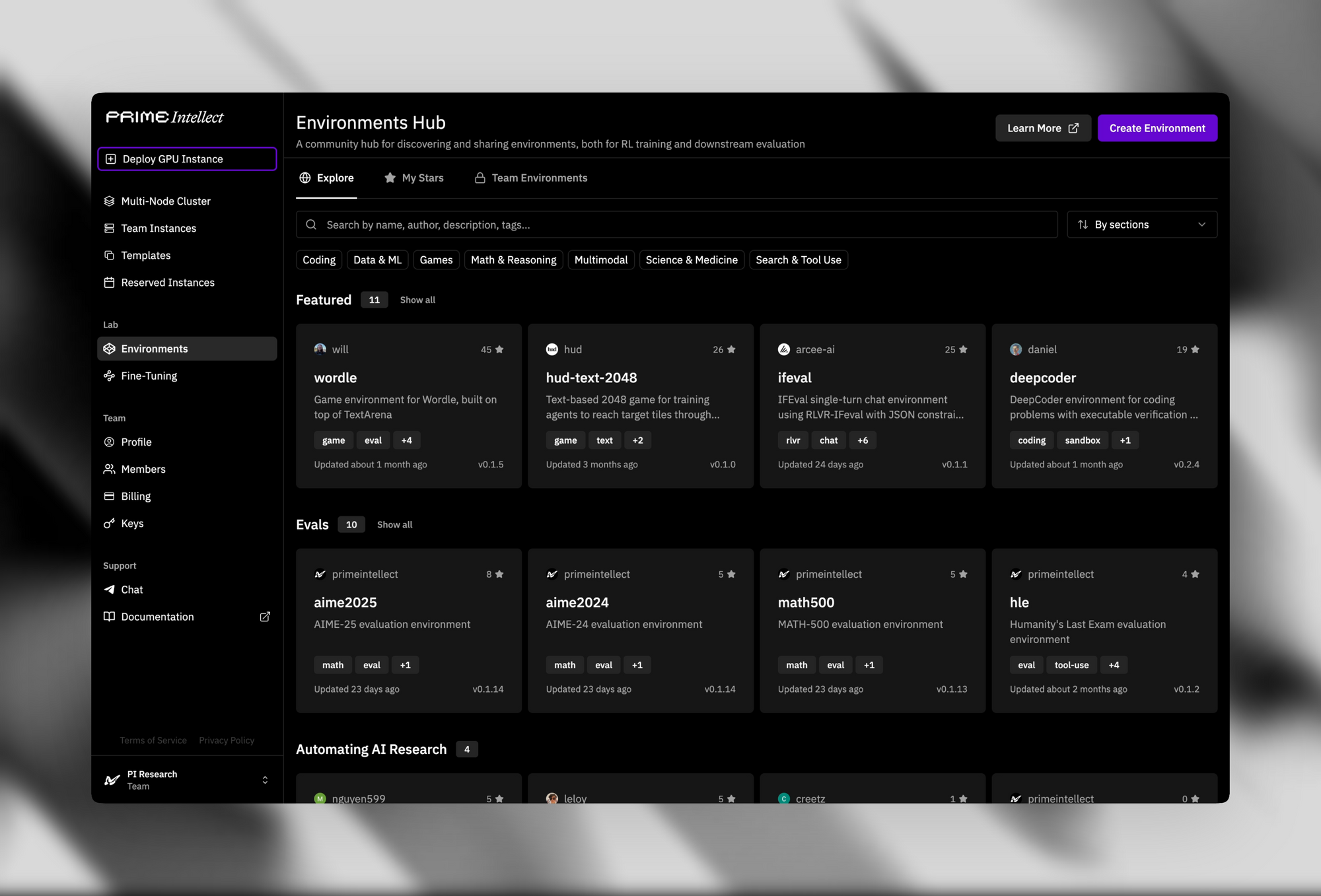
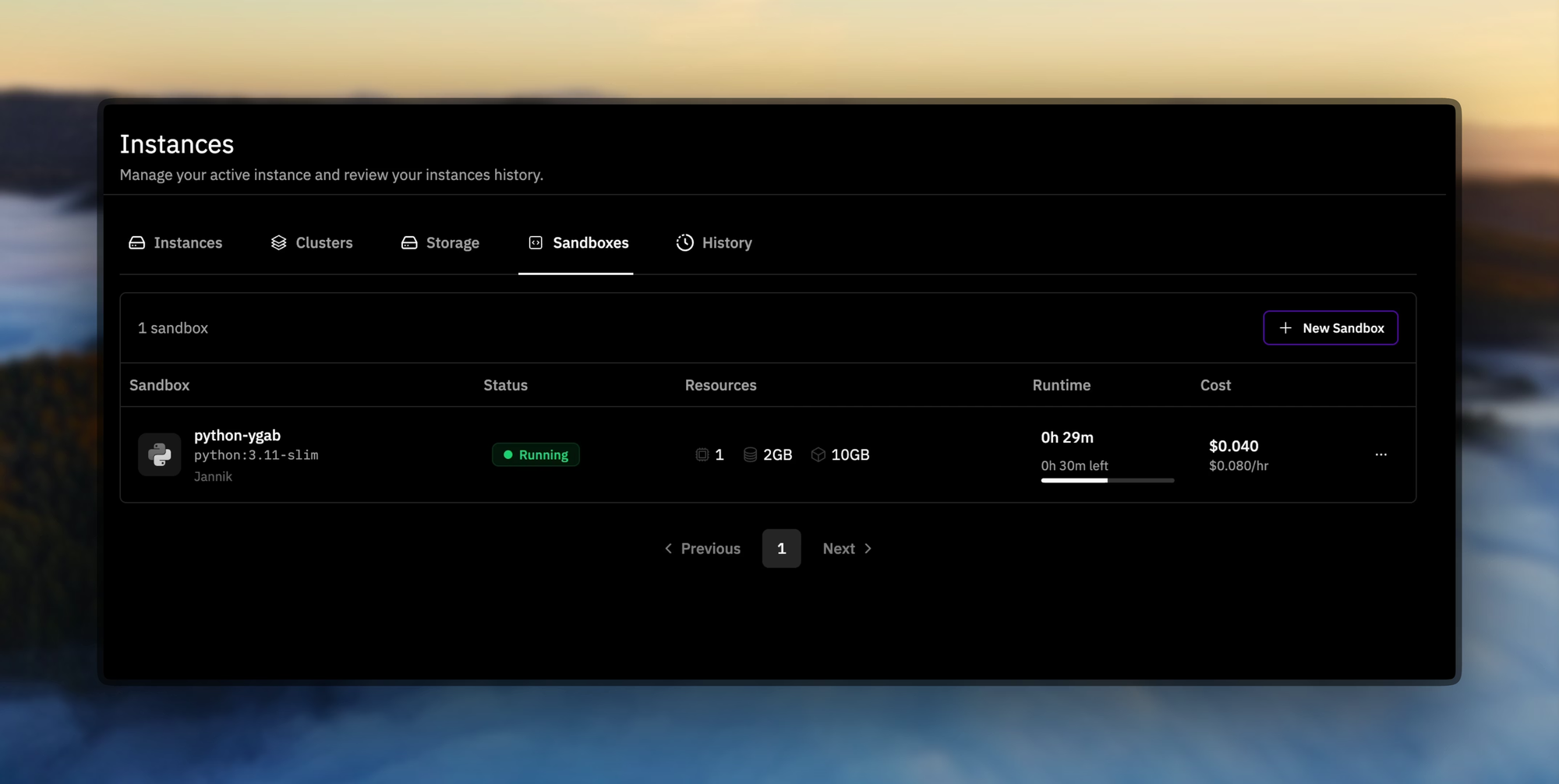
Prime Sandboxes menyediakan eksekusi kode yang aman dan berthroughput tinggi, yang mengisolasi tindakan agen selama pelatihan atau inferensi. Pengembang memanfaatkan alat ini untuk menyempurnakan INTELLECT-3 untuk aplikasi khusus, seperti agen otonom dalam pipeline pengembangan perangkat lunak.
Dalam praktiknya, Anda mengunduh bobot model melalui Hugging Face atau GitHub Prime Intellect. Instalasi membutuhkan dependensi standar seperti PyTorch dan pustaka Transformers. Skrip dasar untuk memuat model terlihat seperti ini:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
Kode ini menginisialisasi model pada perangkat keras yang mendukung GPU. Namun, untuk penggunaan skala produksi, Anda beralih ke API yang dihosting, karena self-hosting menuntut komputasi yang signifikan (misalnya, beberapa GPU A100). Jadi, akses sumber terbuka meletakkan dasar, tetapi integrasi API menskalakan penerapan Anda secara efektif.
Beralih dari eksperimen lokal, kini Anda akan mengeksplorasi cara mengakses INTELLECT-3 melalui layanan terkelola. Pergeseran ini memastikan keandalan dan menangani kompleksitas inferensi terdistribusi.
Mengakses API INTELLECT-3: Penyiapan dan Otentikasi
Pilihan 1 – Titik Akhir Asli Prime Intellect (Direkomendasikan untuk kinerja maksimum & latensi terendah)
Anda memulai akses API dengan mendapatkan kredensial dari platform Prime Intellect. Kunjungi dasbor Prime Intellect di app.primeintellect.ai dan buat akun jika diperlukan.
Setelah masuk, navigasikan ke bagian kunci API dan buat kunci baru dengan izin Inferensi diaktifkan. Kunci ini mengotentikasi semua permintaan berikutnya, memastikan akses aman ke INTELLECT-3.
Selanjutnya, konfigurasikan lingkungan Anda. Atur kunci API sebagai variabel lingkungan untuk integrasi yang mulus:
export PRIME_API_KEY="your-api-key-here"
Untuk alur kerja berbasis tim, sertakan header X-Prime-Team-ID dalam permintaan. Pengidentifikasi ini mengarahkan penggunaan ke kumpulan tagihan yang benar, mencegah biaya lintas-akun. Anda dapat mengambil ID tim dari dasbor di bawah pengaturan akun.
API mengadopsi antarmuka yang kompatibel dengan OpenAI, yang menyederhanakan adopsi jika Anda sudah menggunakan pustaka seperti openai-python. Tentukan URL dasar sebagai https://api.pinference.ai/api/v1. Titik akhir ini memproxy permintaan ke penyedia inferensi yang dioptimalkan, termasuk Parasail dan Nebius, yang menghosting instance INTELLECT-3. Hasilnya, Anda mencapai respons latensi rendah tanpa mengelola klaster dasar.
Untuk memverifikasi akses, kueri titik akhir model. Ini mencantumkan model yang tersedia, mengonfirmasi keberadaan INTELLECT-3 (biasanya di bawah nama seperti prime-intellect/intellect-3). Gunakan alat CLI untuk pemeriksaan cepat:
prime inference models
Atau, kirim permintaan GET melalui curl:
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
Respons mengembalikan array JSON objek model, masing-masing merinci parameter seperti id, max_tokens, dan context_window. INTELLECT-3 mendukung konteks token 128K, yang mengakomodasi rantai penalaran bentuk panjang.
Otentikasi meluas ke pembatasan laju dan kuota. Prime Intellect memberlakukan batas per menit dan harian berdasarkan paket Anda, yang terlihat di dasbor. Anda memantau penggunaan melalui tab Penagihan, yang mencatat token yang diproses dan panggilan API yang dilakukan. Jika batas membatasi alur kerja Anda, tingkatkan secara mulus melalui platform.
Selain itu, integrasikan dengan Apidog untuk pengujian yang ditingkatkan. Impor skema OpenAI ke Apidog, lalu simulasikan permintaan ke titik akhir INTELLECT-3. Praktik ini mengidentifikasi masalah lebih awal, seperti payload JSON yang salah format. Tingkat gratis Apidog cukup untuk penyiapan awal, menjembatani pengembangan lokal ke API produksi.
Dengan otentikasi yang sudah ada, Anda dapat melanjutkan membuat permintaan. Bagian berikut menguraikan format yang tepat untuk mendapatkan respons optimal dari INTELLECT-3.
Pilihan 2 – OpenRouter (Akses Instan & Kredit Terpadu)
Selain menghosting sendiri atau menggunakan platform inferensi asli Prime Intellect, INTELLECT-3 juga tersedia secara resmi di OpenRouter. Ini memberi Anda gateway alternatif dengan penagihan terpadu, perutean fallback otomatis, dan akses instan—tidak memerlukan akun Prime Intellect terpisah jika Anda sudah menggunakan OpenRouter.
- URL Dasar: https://openrouter.ai/api/v1
- Nama model: prime-intellect/intellect-3
- Otentikasi: Kunci API OpenRouter Anda (OPENROUTER_API_KEY)
- Perutean penyedia otomatis (saat ini dilayani oleh klaster Prime Intellect)
- Bayar sesuai penggunaan dengan kredit OpenRouter; biaya per-token sedikit lebih tinggi karena biaya platform
Kedua titik akhir mendukung skema permintaan/respons, streaming, panggilan alat, dan mode JSON yang identik.
Membuat Permintaan ke API INTELLECT-3: Format dan Contoh
Anda memulai interaksi melalui titik akhir /chat/completions, yang menangani prompt percakapan dan berorientasi tugas. Buat permintaan sebagai objek JSON dengan bidang untuk model, messages, temperature, dan max_tokens. Array messages meniru riwayat obrolan, menggunakan peran seperti "system", "user", dan "assistant".
Pertimbangkan contoh dasar untuk pembuatan kode. Anda mengirim:
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
Kode ini menghasilkan implementasi Fibonacci rekursif dengan memoization, memanfaatkan kehebatan pengkodean INTELLECT-3. Parameter temperature mengontrol kreativitas—nilai yang lebih rendah (misalnya, 0.2) mendukung output deterministik untuk kueri faktual, sementara nilai yang lebih tinggi (hingga 1.0) mendorong jalur penalaran yang beragam.
Untuk penalaran matematis, Anda menyusun prompt untuk merangkai pemikiran. Pelatihan RL INTELLECT-3 bersinar di sini, karena mensimulasikan verifikasi langkah demi langkah. Contoh:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
Model merespons dengan bukti yang ketat, mengutip aksioma dan teorema. Anda menguraikan output melalui response.choices[0].message.content, yang tiba sebagai string. Untuk data terstruktur, aktifkan mode JSON dengan menambahkan "response_format": {"type": "json_object"} ke permintaan, memastikan respons yang dapat diuraikan.
Penggunaan tingkat lanjut melibatkan panggilan alat, di mana INTELLECT-3 mengintegrasikan fungsi eksternal. Definisikan alat dalam permintaan:
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
Jika model memanggil alat, ia mengembalikan argumen di response.choices[0].message.tool_calls. Anda mengeksekusi fungsi secara eksternal dan memasukkan hasilnya kembali dalam pesan lanjutan. Pola ini membangun alur kerja agen, memanfaatkan perilaku INTELLECT-3 yang dilatih lingkungan.
Penanganan kesalahan merupakan bagian penting. Masalah umum meliputi 401 (kunci tidak valid), 429 (batas laju), dan 400 (permintaan salah format). Terapkan percobaan ulang dengan backoff eksponensial:
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
Respons mencakup metadata seperti usage (prompt_tokens, completion_tokens, total_tokens), yang Anda catat untuk optimasi. INTELLECT-3 memproses hingga 4096 token per penyelesaian, menyeimbangkan kedalaman dan kecepatan.
Streaming respons meningkatkan aplikasi real-time. Tambahkan stream=True ke panggilan buat; klien menghasilkan potongan sebagai Server-Sent Events. Uraikan secara iteratif:
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Teknik ini cocok untuk chatbot atau asisten kode langsung, di mana pengguna mengharapkan umpan balik bertahap.
Setelah menguasai pembuatan permintaan, Anda mengevaluasi kinerja. Segmen berikutnya memperkenalkan alat tolok ukur yang disesuaikan dengan INTELLECT-3.
Mengoptimalkan dan Mengevaluasi Penggunaan API INTELLECT-3
Anda mengoptimalkan panggilan API dengan menyetel parameter secara empiris. Mulailah dengan mengelompokkan beberapa pesan menjadi satu permintaan untuk peningkatan throughput—efisiensi hingga 10x dalam suite evaluasi. CLI Prime Intellect mendukung ini:
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
Perintah ini menjalankan 100 sampel GSM8K, mengumpulkan metrik akurasi dan latensi. Anda menganalisis hasil untuk menyesuaikan top_p atau frequency_penalty, yang mengurangi pengulangan dalam generasi panjang.
Evaluasi meluas ke lingkungan kustom dari Verifiers Hub. Muat lingkungan RL dan kueri INTELLECT-3 sebagai kebijakan:
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
Hadiah mengukur peningkatan, memandu penyempurnaan jika Anda menghosting secara lokal. Untuk pengguna API-only, catat interaksi ke database vektor dan hitung metrik hilir seperti tingkat keberhasilan tugas.
Pertimbangan keamanan juga penting. Sanitasi input pengguna untuk mencegah injeksi prompt, dan gunakan prompt sistem untuk menegakkan batasan. Latar belakang RL INTELLECT-3 mengurangi halusinasi, tetapi Anda memvalidasi output terhadap verifier untuk aplikasi berisiko tinggi.
Penskalaan melibatkan pemantauan melalui dasbor. Atur peringatan untuk ambang batas token, dan integrasikan dengan alat observabilitas seperti Prometheus, yang Prime Intellect ekspos untuk klaster. Dengan demikian, Anda menjaga keandalan seiring pertumbuhan penggunaan.
Setelah Anda menangani optimasi, pertimbangkan biaya. Transparansi harga memastikan integrasi yang berkelanjutan.
Harga API INTELLECT-3: Model Berbasis Token yang Transparan
Prime Intellect menyusun harga berdasarkan konsumsi token, menagih secara terpisah untuk input dan output. Anda membayar per 1.000 token, dengan tarif bervariasi berdasarkan model dan penyedia. Untuk INTELLECT-3, harapkan angka yang kompetitif—sekitar $0.50 per juta token input dan $1.50 per juta output—meskipun nilai pastinya muncul dalam respons titik akhir model.
| Penyedia | Input ($$ /1 juta token) | Output ( $$/1 juta token) | Catatan |
|---|---|---|---|
| Prime Intellect Langsung | ~$0.45–$0.60 | ~$1.30–$1.80 | Biaya terendah, diskon volume |
| OpenRouter | ~$0.60–$0.80 | ~$1.80–$2.40 | Termasuk biaya platform OpenRouter |
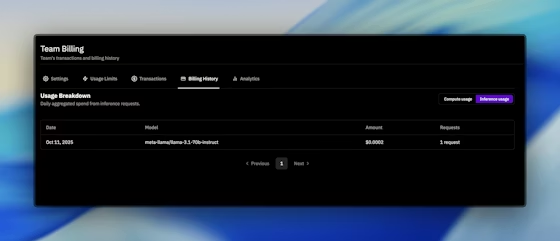
Tarif pasti berfluktuasi; selalu periksa nilai terbaru di dasbor Anda atau melalui titik akhir model.
Mana yang Harus Anda Pilih?
- Pilih Prime Intellect langsung jika Anda menginginkan kecepatan maksimum, biaya terendah, atau merencanakan penggunaan volume tinggi.
- Pilih OpenRouter jika Anda lebih suka satu kunci API di lebih dari 50 model, membutuhkan orientasi instan, atau menginginkan perutean fallback bawaan.
Kedua opsi memberikan kinerja INTELLECT-3 yang sama. Pilih yang sesuai dengan alur kerja Anda—banyak tim bahkan menggunakan keduanya secara bersamaan untuk redundansi.
Sisa panduan ini (format permintaan, streaming, panggilan alat, optimasi, dll.) berlaku sama apakah Anda memanggil Prime Intellect secara langsung atau melalui OpenRouter.
Lanjutkan dengan detail implementasi teknis lengkap di bawah ini, dan mulailah membangun dengan INTELLECT-3 hari ini—melalui gateway mana pun yang terbaik untuk Anda.
Integrasi Lanjutan dengan API INTELLECT-3
Anda memperluas INTELLECT-3 ke dalam ekosistem seperti LangChain atau LlamaIndex untuk orkestrasi. Di LangChain:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
Ini mengikat API ke pipeline `retrieval-augmented generation` (RAG), meningkatkan akurasi dengan pengetahuan eksternal.
Untuk microservice, terapkan melalui wrapper FastAPI yang proxy ke INTELLECT-3:
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
Ekspos titik akhir ini secara aman, dengan pembatasan laju menggunakan Redis. Pengaturan seperti itu menggerakkan alat SaaS, mulai dari generator konten hingga asisten penelitian.
Kasus-kasus khusus memerlukan perhatian. Tangani luapan token dengan memotong input secara dinamis, dan fallback ke model yang lebih kecil jika INTELLECT-3 mengantre. Forum komunitas di situs Prime Intellect menawarkan utas pemecahan masalah.
Kesimpulan: Terapkan API INTELLECT-3 dengan Percaya Diri
Anda kini memiliki perangkat lengkap untuk penggunaan API INTELLECT-3. Dari akar sumber terbukanya hingga penanganan permintaan yang tepat dan manajemen biaya, panduan ini membekali Anda untuk penerapan di dunia nyata. Bereksperimenlah dengan Apidog untuk menyempurnakan alur kerja Anda, dan pantau dokumentasi yang terus berkembang untuk pembaruan.
Terapkan teknik ini secara bertahap—mulai dengan obrolan sederhana, lalu skalakan ke agen. Efisiensi dan keterbukaan INTELLECT-3 menempatkannya sebagai pilihan utama untuk proyek AI teknis. Mulailah pengkodean hari ini, dan saksikan dampaknya pada aplikasi Anda.