
Model gpt-oss-safeguard dari OpenAI mengatasi kebutuhan ini dengan memungkinkan penalaran berbasis kebijakan untuk tugas klasifikasi. Para insinyur mengintegrasikan model-model ini untuk mengklasifikasikan konten yang dibuat pengguna, mendeteksi pelanggaran, dan menjaga integritas platform.
tombol
Memahami GPT-OSS-Safeguard: Fitur dan Kemampuan
Insinyur OpenAI mengembangkan gpt-oss-safeguard sebagai model penalaran open-weight yang disesuaikan untuk klasifikasi keamanan. Mereka menyempurnakan model-model ini dari basis gpt-oss, merilisnya di bawah lisensi Apache 2.0. Pengembang mengunduh model-model ini dari Hugging Face dan menerapkannya secara bebas. Jajarannya meliputi gpt-oss-safeguard-20b dan gpt-oss-safeguard-120b, di mana angka-angka tersebut menunjukkan skala parameter.
Model-model ini memproses dua masukan utama: kebijakan yang ditentukan pengembang dan konten untuk evaluasi. Sistem menerapkan penalaran chain-of-thought untuk menginterpretasikan kebijakan dan mengklasifikasikan konten. Misalnya, sistem ini menentukan apakah pesan pengguna melanggar aturan tentang kecurangan di forum game. Pendekatan ini memungkinkan pembaruan kebijakan yang dinamis tanpa pelatihan ulang, yang dibutuhkan oleh pengklasifikasi tradisional.
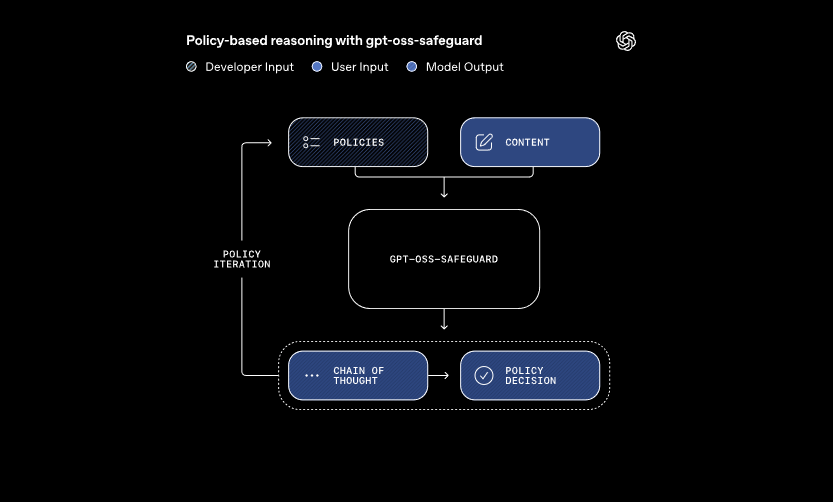
Selain itu, gpt-oss-safeguard mendukung beberapa kebijakan secara bersamaan. Pengembang memasukkan beberapa aturan ke dalam satu panggilan inferensi, dan model mengevaluasi konten terhadap semua aturan tersebut. Kemampuan ini menyederhanakan alur kerja untuk platform yang menangani berbagai risiko, seperti misinformasi atau ujaran berbahaya. Namun, kinerja mungkin sedikit menurun dengan penambahan kebijakan, jadi tim harus menguji konfigurasi secara menyeluruh.
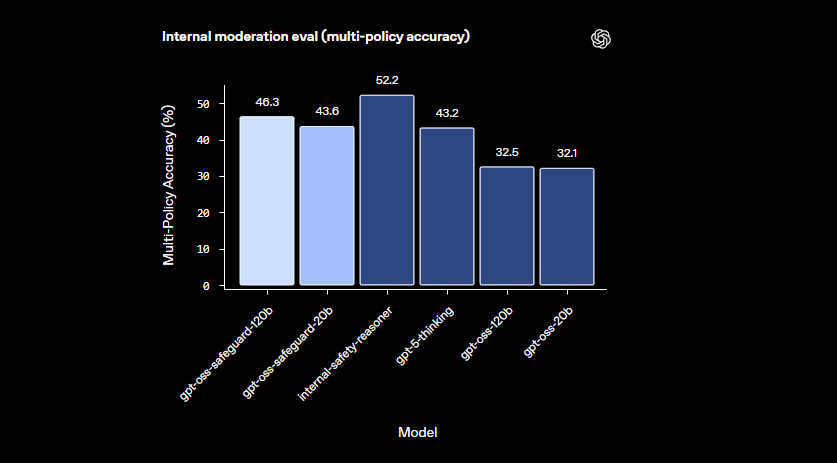
Model-model ini unggul dalam domain bernuansa di mana pengklasifikasi yang lebih kecil sering gagal. Mereka menangani bahaya yang muncul dengan cepat beradaptasi dengan kebijakan yang direvisi. Selain itu, keluaran chain-of-thought memberikan transparansi—pengembang meninjau jejak penalaran untuk mengaudit keputusan. Fitur ini terbukti sangat berharga bagi tim kepatuhan yang membutuhkan AI yang dapat dijelaskan.
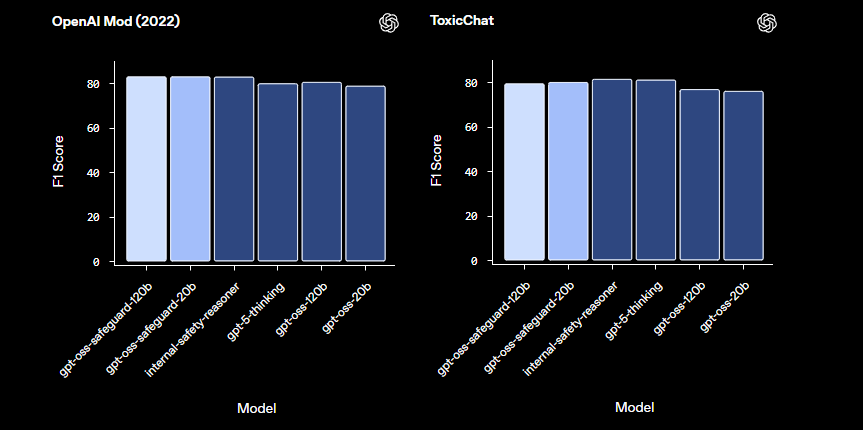
Dibandingkan dengan model keamanan bawaan seperti LlamaGuard, gpt-oss-safeguard menawarkan kustomisasi yang lebih besar. Ini menghindari taksonomi tetap, memberdayakan organisasi untuk menentukan ambang batas mereka sendiri. Akibatnya, integrasi ini cocok untuk insinyur Trust & Safety yang membangun pipeline moderasi yang skalabel. Sekarang setelah kita memahami dasar-dasarnya, mari kita lanjutkan ke pengaturan lingkungan.
Menyiapkan Lingkungan Anda untuk Akses API GPT-OSS-Safeguard
Pengembang memulai dengan menyiapkan sistem mereka untuk menjalankan gpt-oss-safeguard. Karena model-model ini bersifat open-weight, Anda dapat menerapkannya secara lokal atau melalui penyedia hosting. Fleksibilitas ini mengakomodasi berbagai pengaturan perangkat keras, mulai dari mesin pribadi hingga server cloud.
Pertama, instal dependensi yang diperlukan. Python 3.10 atau yang lebih tinggi berfungsi sebagai dasarnya. Gunakan pip untuk menambahkan pustaka seperti Hugging Face Transformers: pip install transformers. Untuk inferensi yang dipercepat, sertakan torch dengan dukungan CUDA jika Anda memiliki GPU yang kompatibel. Insinyur dengan perangkat keras NVIDIA mengaktifkan ini untuk pemrosesan yang lebih cepat.
Selanjutnya, unduh model-model dari Hugging Face. Akses koleksinya. Pilih gpt-oss-safeguard-20b untuk kebutuhan sumber daya yang lebih ringan atau gpt-oss-safeguard-120b untuk akurasi yang lebih unggul. Perintah transformers-cli download openai/gpt-oss-safeguard-20b mengambil file-file tersebut.
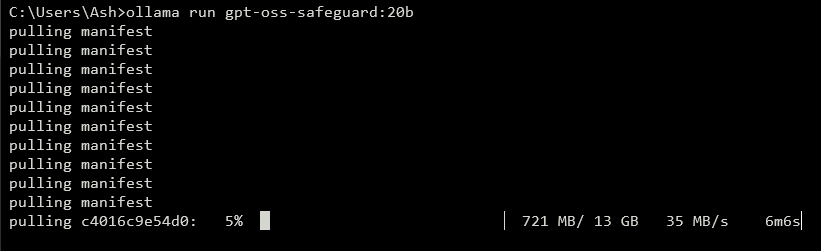
Untuk mengekspos API, jalankan server lokal. Alat seperti vLLM menangani ini secara efisien. Instal vLLM dengan pip install vllm. Kemudian, luncurkan server: vllm serve openai/gpt-oss-safeguard-20b. Perintah ini memulai endpoint yang kompatibel dengan OpenAI di http://localhost:8000/v1. Demikian pula, Ollama menyederhanakan penerapan: ollama run gpt-oss-safeguard:20b. Ini menyediakan API REST untuk integrasi.
Untuk pengujian lokal, LM Studio menawarkan antarmuka yang ramah pengguna. Jalankan lms get openai/gpt-oss-safeguard-20b untuk mengambil model. Perangkat lunak ini meniru API Chat Completions OpenAI, memungkinkan transisi kode yang mulus ke produksi.
Opsi hosting menghilangkan kekhawatiran perangkat keras. Penyedia seperti Groq mendukung gpt-oss-safeguard-20b melalui API mereka. Daftar di https://console.groq.com, buat kunci API, dan targetkan model dalam permintaan. Harga dimulai dari $0,075 per juta token masukan. OpenRouter juga menghostingnya.
Setelah diatur, verifikasi instalasi. Kirim permintaan uji melalui curl: curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-safeguard-20b", "messages": [{"role": "system", "content": "Test policy"}, {"role": "user", "content": "Test content"}]}'. Respons yang berhasil mengonfirmasi kesiapan. Dengan lingkungan yang telah dikonfigurasi, Anda selanjutnya membuat kebijakan.
Merancang Kebijakan yang Efektif untuk GPT-OSS-Safeguard
Kebijakan membentuk tulang punggung operasi gpt-oss-safeguard. Pengembang menulisnya sebagai prompt terstruktur yang memandu klasifikasi. Kebijakan yang dirancang dengan baik memaksimalkan kekuatan penalaran model, memastikan keluaran yang akurat dan dapat dijelaskan.
Strukturkan kebijakan Anda dengan bagian-bagian yang berbeda. Mulailah dengan Instruksi, yang menentukan tugas model. Misalnya, arahkan untuk mengklasifikasikan konten sebagai melanggar (1) atau aman (0). Lanjutkan dengan Definisi, mengklarifikasi istilah-istilah kunci seperti "bahasa yang merendahkan martabat manusia." Kemudian, uraikan Kriteria untuk pelanggaran dan konten yang aman. Terakhir, sertakan Contoh—berikan 4-6 kasus batas yang diberi label sesuai.
Gunakan suara aktif dalam kebijakan: "Tandai konten yang mempromosikan kekerasan" alih-alih alternatif pasif. Jaga agar bahasa tetap tepat; hindari ambiguitas seperti "umumnya tidak aman." Jika terjadi konflik antar aturan, definisikan prioritas secara eksplisit. Untuk skenario multi-kebijakan, gabungkan mereka dalam pesan sistem.
Kontrol kedalaman penalaran melalui parameter "reasoning_effort": atur ke "high" untuk kasus kompleks atau "low" untuk kecepatan. Format harmoni, yang terintegrasi dalam gpt-oss-safeguard, memisahkan penalaran dari keluaran akhir. Ini memastikan respons API yang bersih sambil mempertahankan jejak audit.
Optimalkan panjang kebijakan sekitar 400-600 token. Kebijakan yang lebih pendek berisiko terlalu menyederhanakan, sementara yang lebih panjang dapat membingungkan model. Uji secara iteratif: klasifikasikan konten sampel dan perbaiki berdasarkan keluaran. Alat seperti penghitung token di Hugging Face membantu di sini.
Untuk format keluaran, pilih biner untuk kesederhanaan: Return exactly 0 or 1. Tambahkan alasan untuk kedalaman: {"violation": 1, "rationale": "Explanation here"}. Struktur JSON ini mudah diintegrasikan dengan sistem hilir. Saat Anda menyempurnakan kebijakan, beralihlah ke implementasi API.
Mengimplementasikan Panggilan API dengan GPT-OSS-Safeguard
Pengembang berinteraksi dengan gpt-oss-safeguard melalui endpoint yang kompatibel dengan OpenAI. Baik lokal maupun dihosting, prosesnya mengikuti pola penyelesaian obrolan standar.
Siapkan klien Anda. Di Python, impor OpenAI: from openai import OpenAI. Inisialisasi dengan URL dasar dan kunci: client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy") untuk lokal, atau nilai spesifik penyedia.
Buat pesan. Peran sistem memegang kebijakan: {"role": "system", "content": "Your detailed policy here"}. Peran pengguna berisi konten: {"role": "user", "content": "Content to classify"}.
Panggil API: completion = client.chat.completions.create(model="openai/gpt-oss-safeguard-20b", messages=messages, max_tokens=500, temperature=0.0). Suhu pada 0 memastikan keluaran yang deterministik untuk tugas keamanan.
Uraikan responsnya: result = completion.choices[0].message.content. Untuk keluaran terstruktur, gunakan parsing JSON. Groq meningkatkan ini dengan caching prompt—gunakan kembali kebijakan di seluruh panggilan untuk memangkas biaya hingga 50%.
Tangani streaming untuk umpan balik waktu nyata: atur stream=True dan iterasi melalui chunk. Ini cocok untuk moderasi volume tinggi.
Sertakan alat jika diperlukan, meskipun gpt-oss-safeguard berfokus pada klasifikasi. Definisikan fungsi dalam parameter tools untuk kemampuan yang diperluas, seperti mengambil data eksternal.
Pantau penggunaan token: masukan mencakup kebijakan ditambah konten, keluaran menambahkan penalaran. Batasi max_tokens untuk mencegah luapan. Dengan panggilan yang telah dikuasai, jelajahi contoh.
Fitur Lanjutan dalam API GPT-OSS-Safeguard
gpt-oss-safeguard menawarkan alat canggih untuk kontrol yang lebih baik. Prompt caching di Groq menggunakan kembali kebijakan, mengurangi latensi dan biaya.
Sesuaikan reasoning_effort dalam pesan sistem: "Reasoning: high" untuk analisis mendalam. Ini menangani konten yang ambigu dengan lebih baik.
Manfaatkan jendela konteks 128k untuk obrolan atau dokumen panjang. Berikan seluruh percakapan untuk klasifikasi holistik.
Integrasikan dengan sistem yang lebih besar: Salurkan keluaran ke antrean eskalasi atau pencatatan. Gunakan webhook untuk peringatan waktu nyata.
Sempurnakan lebih lanjut jika diperlukan, meskipun dasarnya unggul dalam mengikuti kebijakan. Gabungkan dengan model yang lebih kecil untuk pra-penyaringan, mengoptimalkan komputasi.
Masalah keamanan: Amankan kunci API dan pantau injeksi prompt. Validasi masukan untuk mencegah eksploitasi.
Penskalaan: Terapkan pada kluster dengan vLLM untuk throughput tinggi. Penyedia seperti Groq memberikan 1000+ token/detik.
Fitur-fitur ini mengangkat gpt-oss-safeguard dari pengklasifikasi dasar menjadi alat perusahaan. Namun, ikuti praktik terbaik untuk hasil yang optimal.
Praktik Terbaik dan Optimasi untuk GPT-OSS-Safeguard
Insinyur mengoptimalkan gpt-oss-safeguard dengan mengulang kebijakan. Uji dengan kumpulan data yang beragam, mengukur akurasi melalui metrik seperti F1-score.
Seimbangkan ukuran model: Gunakan 20b untuk kecepatan, 120b untuk presisi. Kuantisasi bobot untuk mengurangi jejak memori.
Pantau kinerja: Catat jejak penalaran untuk audit. Sesuaikan suhu seminimal mungkin—0,0 cocok untuk kebutuhan deterministik.
Tangani keterbatasan: Model mungkin kesulitan dengan domain yang sangat terspesialisasi; lengkapi dengan data domain.
Pastikan penggunaan etis: Selaraskan kebijakan dengan peraturan. Hindari bias dengan mendiversifikasi contoh.
Perbarui secara teratur: Seiring OpenAI mengembangkan gpt-oss-safeguard, masukkan perbaikan.
Manajemen biaya: Untuk API yang dihosting, lacak pengeluaran token. Penerapan lokal meminimalkan biaya.
Dengan menerapkan praktik-praktik ini, Anda memaksimalkan efisiensi. Singkatnya, gpt-oss-safeguard memberdayakan sistem keamanan yang kuat.
Kesimpulan: Mengintegrasikan GPT-OSS-Safeguard ke dalam Alur Kerja Anda
Pengembang memanfaatkan gpt-oss-safeguard untuk membangun pengklasifikasi keamanan yang adaptif. Dari pengaturan hingga penggunaan lanjutan, panduan ini membekali Anda dengan pengetahuan teknis. Terapkan kebijakan, jalankan panggilan API, dan optimalkan untuk kebutuhan Anda. Seiring berkembangnya platform, gpt-oss-safeguard beradaptasi dengan mulus, memastikan lingkungan yang aman.
tombol