
Para insinyur dan pengembang terus-menerus mencari model efisien yang memberikan kinerja tinggi tanpa tuntutan sumber daya yang berlebihan. GLM-4.7-Flash muncul sebagai pilihan menarik dalam lanskap ini. Model Mixture-of-Experts (MoE) 30B-A3B ini, yang dikembangkan oleh Zhipu AI (Z.ai), menonjol karena keseimbangan kekuatan dan efisiensinya. Ia unggul dalam tolok ukur pengkodean, tugas penalaran, dan integrasi alat, sehingga cocok untuk skenario penerapan lokal.
Menjalankan GLM-4.7-Flash secara lokal memberdayakan pengguna untuk menjaga privasi data, mengurangi latensi, dan menyesuaikan integrasi. Alat seperti Ollama, LM Studio, dan Hugging Face menyederhanakan proses ini.
Saat Anda melanjutkan panduan ini, Anda akan mendapatkan wawasan praktis tentang instalasi dan penggunaan. Pertama, pertimbangkan persyaratan dasar sistem.
Apa Itu GLM-4.7-Flash dan Mengapa Menggunakannya Secara Lokal?
GLM-4.7-Flash mewakili kemajuan dalam model bahasa sumber terbuka. Dibangun di atas arsitektur glm4_moe_lite, ia menggunakan tipe tensor BF16 dan F32 di bawah lisensi MIT. Makalah modelnya, "GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models," merinci pelatihannya untuk penggunaan alat dan penalaran, mengacu pada arXiv:2508.06471.
Fitur utama meliputi dukungan untuk bahasa Inggris dan Mandarin, generasi teks, dan tugas percakapan. Ia menangani input multimodal sebagai teks tetapi berfokus pada output teks saja. Keterbatasan muncul dari skalanya—meskipun efisien, ia mungkin tidak menandingi model yang lebih besar di domain khusus tanpa penyetelan halus. Detail data pelatihan tetap dirahasiakan, tetapi evaluasi mengkonfirmasi keunggulannya dalam skenario pengkodean dan agen.
Pengguna memilih menjalankan secara lokal untuk menghindari biaya API. Z.ai menawarkan tingkatan gratis untuk GLM-4.7-Flash melalui platform mereka, tetapi penerapan lokal menghilangkan ketergantungan pada layanan eksternal. Pendekatan ini cocok untuk pengembang yang membangun aplikasi kustom, peneliti yang menguji hipotesis, atau perusahaan yang memprioritaskan keamanan. Misalnya, Anda mengontrol tingkat kuantisasi agar sesuai dengan batasan perangkat keras, memastikan kinerja optimal.
Persyaratan Sistem untuk Menjalankan GLM-4.7-Flash Secara Lokal
Perangkat keras memainkan peran penting dalam inferensi model. GLM-4.7-Flash membutuhkan setidaknya 16 GB memori sistem untuk operasi dasar, sebagaimana ditentukan dalam pedoman LM Studio. Namun, akselerasi GPU secara signifikan meningkatkan kecepatan.
Untuk varian Ollama:
- q4_K_M: 19 GB VRAM
- q8_0: 32 GB VRAM
- bf16: 60 GB VRAM
Hugging Face merekomendasikan torch.bfloat16 untuk efisiensi, membutuhkan GPU NVIDIA yang kompatibel (arsitektur Ampere atau yang lebih baru). Inferensi CPU-only berfungsi tetapi melambat secara signifikan untuk konteks besar.
Prasyarat perangkat lunak meliputi Python 3.8+, pip, dan Git. Kerangka kerja seperti Transformers memerlukan instalasi tambahan. Pastikan OS Anda mendukung CUDA untuk penggunaan GPU—Ubuntu 20.04 atau Windows dengan WSL2 berfungsi dengan baik.
Jika sumber daya tidak mencukupi, kuantisasi mengurangi jejak memori. Alat seperti llama.cpp atau Unsloth menawarkan versi 4-bit atau 2-bit, menurunkan persyaratan menjadi 15-20 GB VRAM. Fleksibilitas ini memungkinkan penyebaran pada perangkat keras konsumen seperti RTX 4090.
Dengan persyaratan yang terpenuhi, jelajahi metode instalasi. Mulailah dengan Ollama karena kesederhanaannya.
Cara Menginstal dan Menggunakan GLM-4.7-Flash dengan Ollama
Ollama menyediakan platform yang mudah diakses untuk menjalankan model besar secara lokal. Ia mengelola kuantisasi dan penyajian API secara otomatis.
Pertama, instal Ollama. Unduh executable-nya untuk OS Anda dan jalankan.

Verifikasi instalasi dengan ollama --version, pastikan versi 0.14.3 atau yang lebih baru, karena GLM-4.7-Flash membutuhkannya.

Selanjutnya, tarik model: jalankan ollama pull glm-4.7-flash.

Pilih varian seperti glm-4.7-flash:q4_K_M untuk penggunaan memori yang lebih rendah. Perintah ini mengunduh sekitar 19 GB untuk versi q4.
Jalankan model secara interaktif: ketik ollama run glm-4.7-flash. Masukkan perintah seperti "Hasilkan kode Python untuk deret Fibonacci." Model akan merespons dengan output yang beralasan, memanfaatkan kekuatan pengkodeannya.
Untuk akses terprogram, gunakan API. Kirim permintaan curl:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
Ini mengembalikan JSON dengan responsnya. Di Python, integrasikan dengan pustaka ollama:
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
JavaScript mengikuti dengan cara serupa dengan paket npm ollama.
Sesuaikan konfigurasi dengan mengedit Modelfile. Atur suhu ke 0.7 untuk output deterministik dalam tugas pengkodean. Mode terbaru Ollama mengambil postingan terbaru jika diperlukan, tetapi fokus pada inferensi lokal di sini.
Metode ini cocok untuk pengaturan cepat. Namun, untuk antarmuka grafis, beralihlah ke LM Studio.
Menyiapkan GLM-4.7-Flash di LM Studio
LM Studio menawarkan GUI yang ramah pengguna untuk manajemen model. Unduh dan instal.
Cari "zai-org/glm-4.7-flash" di hub model. Pilih versi terkuantisasi—MLX-4bit, 6bit, atau 8bit—dari repo Hugging Face yang tertaut. Pengunduhan selesai di aplikasi.
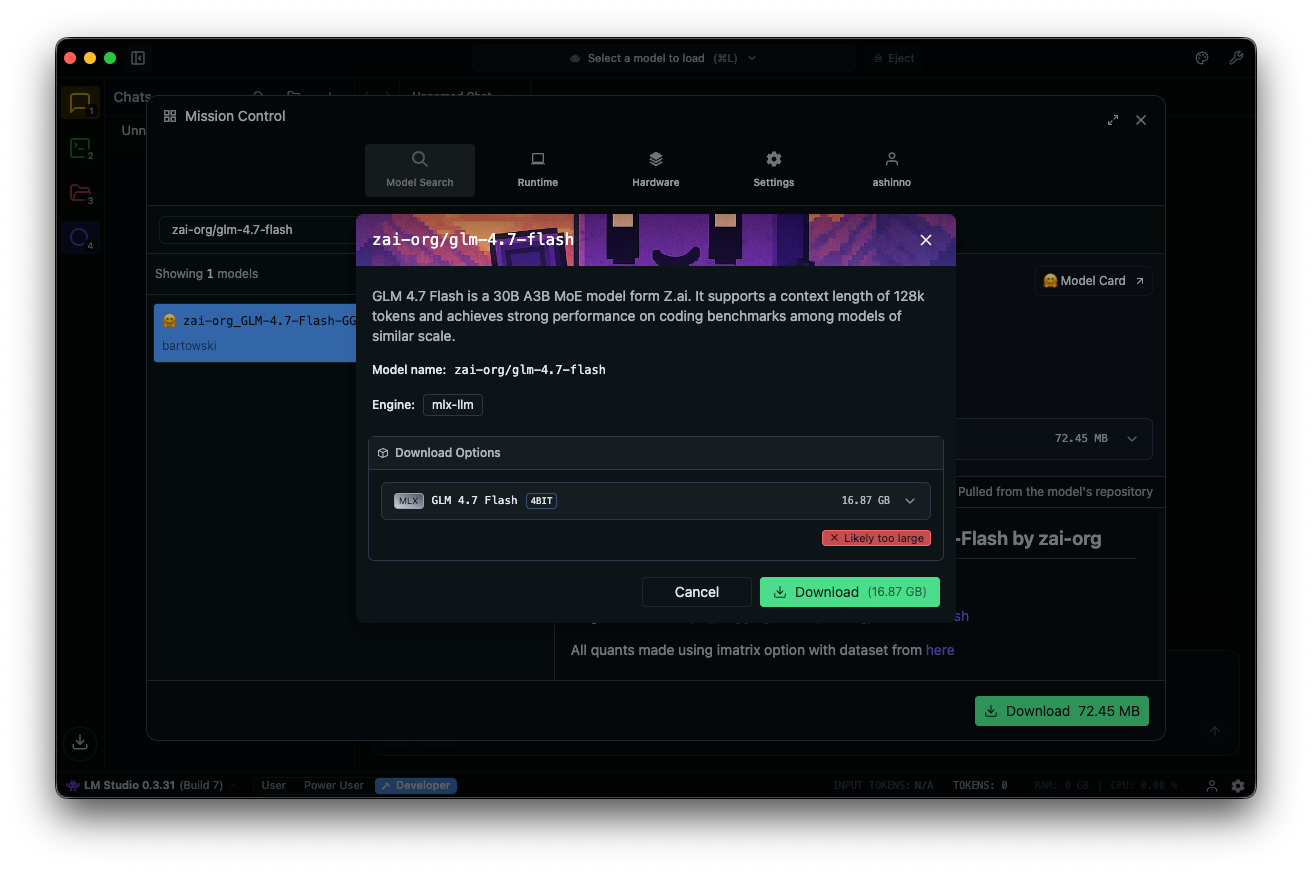
Muat model: navigasikan ke antarmuka obrolan, pilih GLM-4.7-Flash, dan sesuaikan parameter. Aktifkan berpikir (default: true) untuk penalaran langkah demi langkah. Atur suhu ke 1, top_k ke 50, top_p ke 0.95, dan nonaktifkan penalti pengulangan.
Uji dengan perintah: "Rancang API REST untuk otentikasi pengguna." LM Studio menampilkan output dengan kecepatan token, membantu penyetelan kinerja.
Bidang kustom seperti clear_thinking (default: false) mengelola riwayat. Untuk model MoE, pantau pakar aktif—A3B berarti tiga aktif per forward pass, mengoptimalkan efisiensi.
LM Studio mendukung deeplink untuk akses model langsung. Jika muncul masalah, periksa memori sistem—minimal 16 GB mencegah crash.
Alat ini sangat baik untuk eksperimen. Untuk skrip tingkat lanjut, integrasikan dengan Hugging Face.
Menggunakan GLM-4.7-Flash dengan Hugging Face Transformers
Hugging Face menyediakan pustaka yang kuat untuk kontrol terperinci. Instal Transformers dari cabang utama:
pip install git+https://github.com/huggingface/transformers.git
Muat model:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
Siapkan input:
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
Hasilkan:
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
Pengaturan ini mendukung kuantisasi melalui bitsandbytes untuk VRAM yang lebih rendah. Tambahkan load_in_4bit=True dalam pemuatan model.
Untuk penyajian, gunakan vLLM atau SGLang. Instal vLLM:
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
Jalankan server:
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
Akses melalui endpoint yang kompatibel dengan OpenAI. SGLang memerlukan instalasi dari sumber dan mengikuti langkah-langkah serupa.
Kerangka kerja ini memungkinkan penerapan tingkat produksi. Sekarang, pertimbangkan pengujian API dengan Apidog.
Mengintegrasikan Apidog untuk Pengujian API dengan GLM-4.7-Flash Lokal
Setelah Anda menyajikan GLM-4.7-Flash melalui Ollama atau vLLM, uji endpoint secara efisien. Apidog, platform API all-in-one, memfasilitasi hal ini.
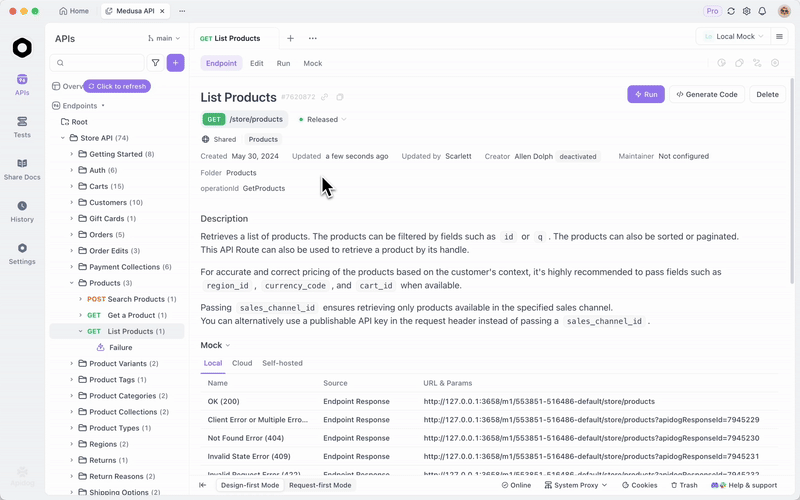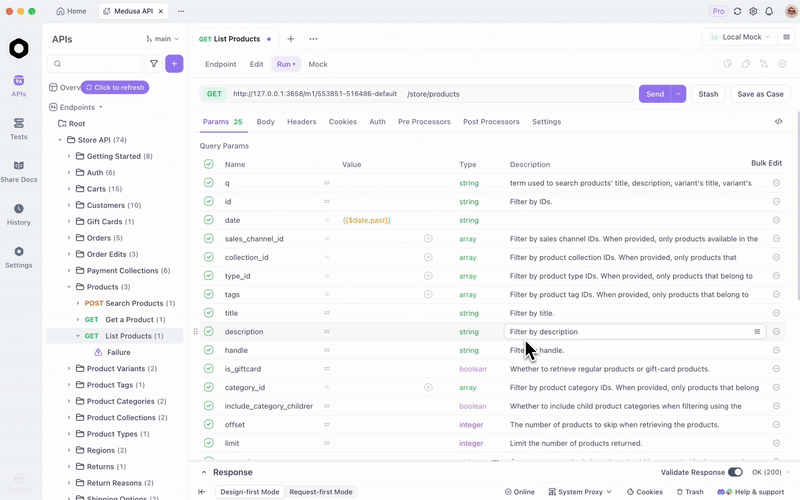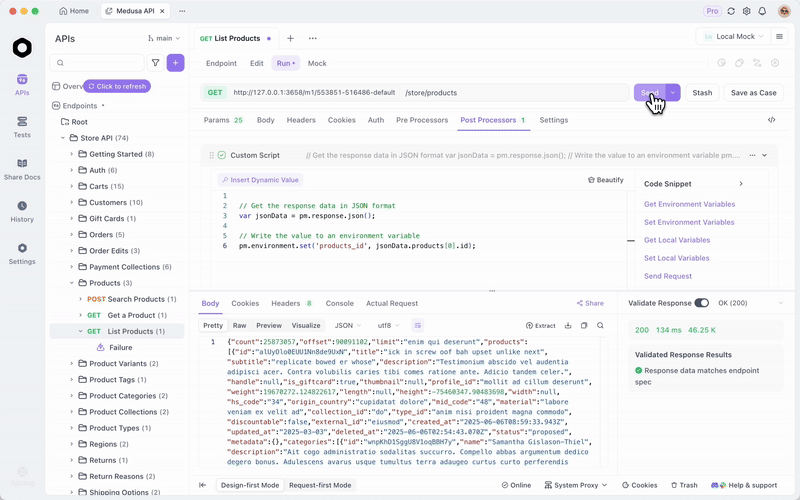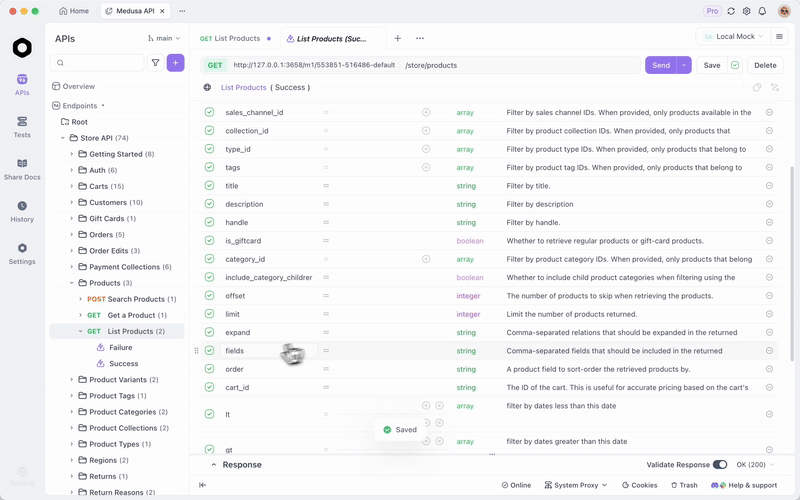
Unduh Apidog secara gratis. Ia mendukung fitur AI dengan mengkonfigurasi model lokal Anda sebagai penyedia—gunakan kunci API jika berlaku, atau endpoint langsung.
MCP Server Apidog terintegrasi dengan IDE seperti Cursor, menggunakan spesifikasi API untuk generasi kode. Ini terhubung kembali ke kemampuan pengkodean GLM-4.7-Flash—uji output agen secara langsung.
Misalnya, kueri server lokal Anda dan validasi respons. Ini memastikan keandalan dalam aplikasi.
Membangun dari dasar, maju ke optimasi.
Kiat Lanjutan untuk Mengoptimalkan Kinerja GLM-4.7-Flash
Sempurnakan parameter untuk tugas. Atur suhu ke 0.7 untuk pengkodean, 1.0 untuk penulisan kreatif. Gunakan top_p 0.95 untuk menyeimbangkan keragaman.
Kuantisasi lebih lanjut dengan format GGUF melalui llama.cpp. Kompilasi llama.cpp dengan CUDA, lalu konversi:
./llama-gguf-split --model GLM-4.7-Flash.gguf
Jalankan dengan --jinja untuk dukungan templat.
Tangani konteks panjang: Pisahkan input jika melebihi 128K. Aktifkan berpikir untuk kueri kompleks.
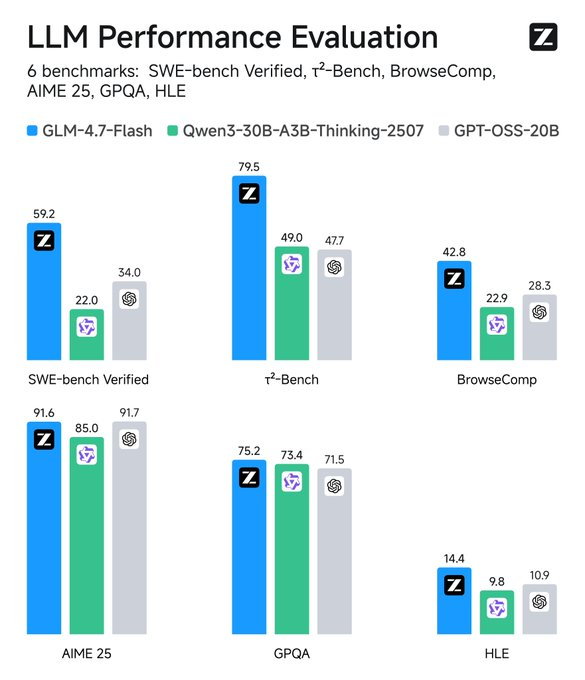
Pantau metrik: Alat seperti TensorBoard melacak latensi. Bandingkan dengan baseline—GLM-4.7-Flash mengalahkan pesaing di SWE-bench dengan 37.2 poin.
Integrasikan alat: Tambahkan panggilan fungsi dalam perintah untuk perilaku agen.
Keamanan: Jalankan di lingkungan terisolasi untuk mencegah kebocoran data.
Strategi ini memaksimalkan utilitas. Renungkan aplikasi selanjutnya.
Pemecahan Masalah Umum
Menemukan kesalahan kehabisan memori? Kurangi ukuran batch atau kuantisasi lebih rendah.
Inferensi lambat? Tingkatkan GPU atau gunakan kerangka kerja yang lebih cepat seperti vLLM.
Masalah kompatibilitas? Perbarui Transformers ke main.
Jika Ollama gagal, periksa ketersediaan port 11434.
LM Studio crash? Verifikasi integritas model.
Atasi masalah ini secara proaktif.
Kesimpulan: Berdayakan Alur Kerja Anda dengan GLM-4.7-Flash
Menjalankan GLM-4.7-Flash secara lokal membuka kemampuan AI yang kuat. Dari kemudahan Ollama hingga fleksibilitas Hugging Face, banyak pilihan tersedia. Gabungkan Apidog untuk manajemen API yang mulus—unduh gratis untuk meningkatkan pengaturan Anda.
Seiring berkembangnya teknologi, model seperti ini menjembatani kinerja dan aksesibilitas. Terapkan langkah-langkah ini, dan Anda akan mencapai penerapan AI yang efisien dan pribadi. Penyesuaian kecil pada parameter atau alat menghasilkan peningkatan yang signifikan, mengubah tugas rutin menjadi proses yang efisien.