Pengembang terus mencari model bahasa canggih yang memberikan kinerja tangguh di berbagai aplikasi. Zhipu AI memperkenalkan GLM-4.6, sebuah iterasi lanjutan dalam seri GLM yang mendorong batas kemampuan kecerdasan buatan. Model ini dibangun di atas versi sebelumnya dengan menggabungkan peningkatan signifikan dalam penanganan konteks, penalaran, dan utilitas praktis. Para insinyur mengintegrasikan GLM-4.6 ke dalam alur kerja mereka untuk menangani tugas-tugas kompleks, mulai dari pembuatan kode hingga pembuatan konten, dengan efisiensi dan akurasi yang lebih besar.
Zhipu AI merancang GLM-4.6 sebagai bagian dari GLM Coding Plan, layanan berbasis langganan yang dimulai dengan harga terjangkau. Pengguna mengakses model ini melalui alat terintegrasi seperti Claude Code, Cline, OpenCode, dan lainnya, memungkinkan pengembangan yang dibantu AI tanpa hambatan. Model ini unggul dalam skenario dunia nyata, di mana ia memproses konteks yang luas dan menghasilkan keluaran berkualitas tinggi. Selain itu, GLM-4.6 menunjukkan kinerja superior dalam tolok ukur, menyaingi pemimpin internasional seperti Claude Sonnet 4. Ini menempatkannya sebagai pilihan utama bagi pengembang di Tiongkok dan di seluruh dunia yang membutuhkan dukungan AI yang andal.
Beralih dari pemahaman dasar model, mari kita periksa fitur intinya dan bagaimana fitur tersebut menguntungkan implementasi teknis.
Apa Itu GLM-4.6?
Zhipu AI mengembangkan GLM-4.6 sebagai model bahasa besar yang dioptimalkan untuk berbagai tugas teknis dan kreatif. Model ini menampilkan arsitektur Mixture of Experts (MoE) 355B-parameter, yang memungkinkan komputasi efisien sambil mempertahankan kinerja tinggi. Pengguna menghargai jendela konteksnya yang diperluas hingga 200K token, peningkatan signifikan dari batas 128K pada versi sebelumnya. Perluasan ini memungkinkan model untuk mengelola interaksi yang rumit dan panjang tanpa kehilangan koherensi.
Selain itu, GLM-4.6 mendukung modalitas input dan output teks, membuatnya serbaguna untuk aplikasi yang menuntut pemrosesan bahasa yang tepat. Batas token output maksimum mencapai 128K, menyediakan ruang yang cukup untuk respons terperinci. Pengembang memanfaatkan spesifikasi ini untuk membangun sistem yang menangani data ekstensif, seperti analisis dokumen atau rantai penalaran multi-langkah.
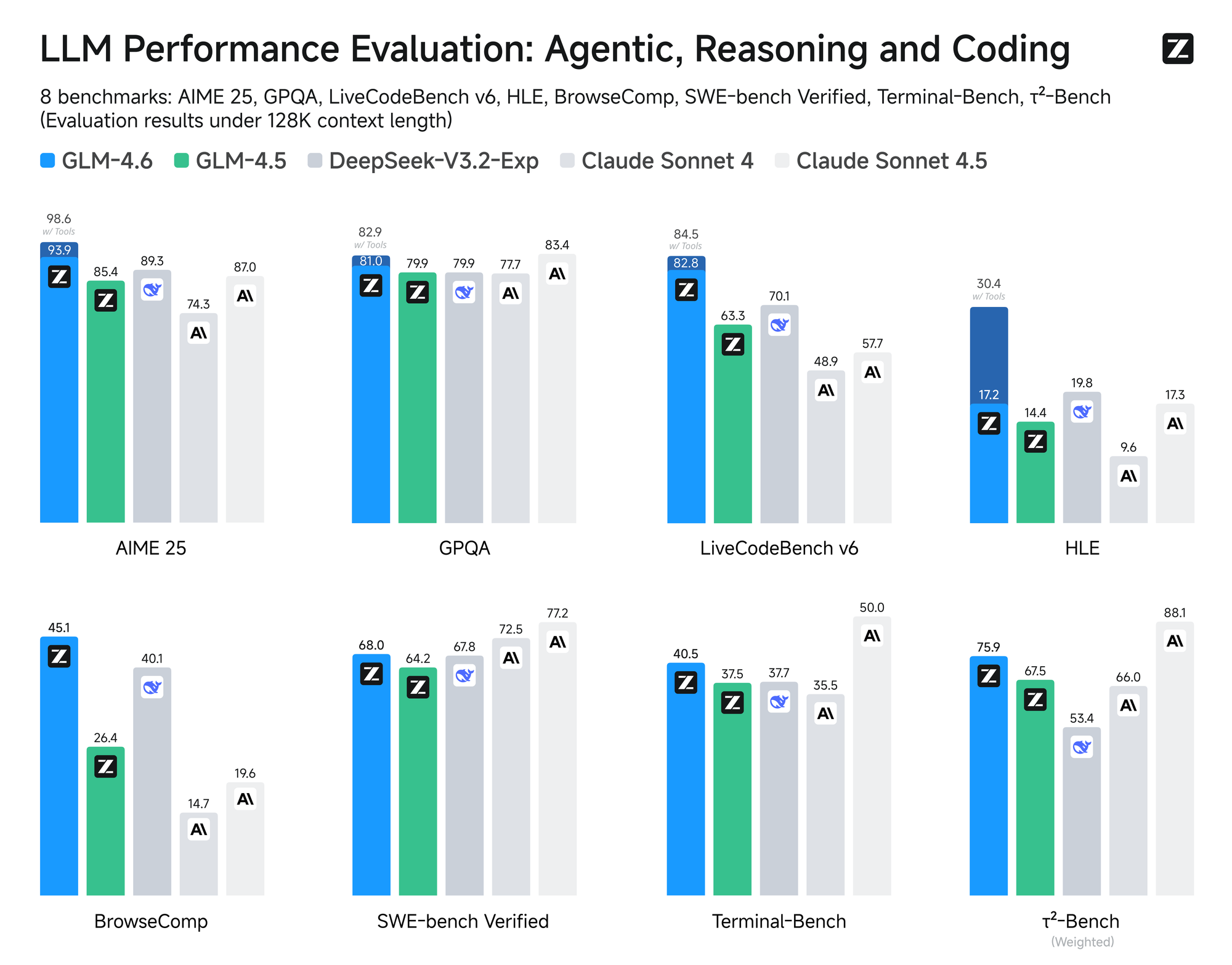
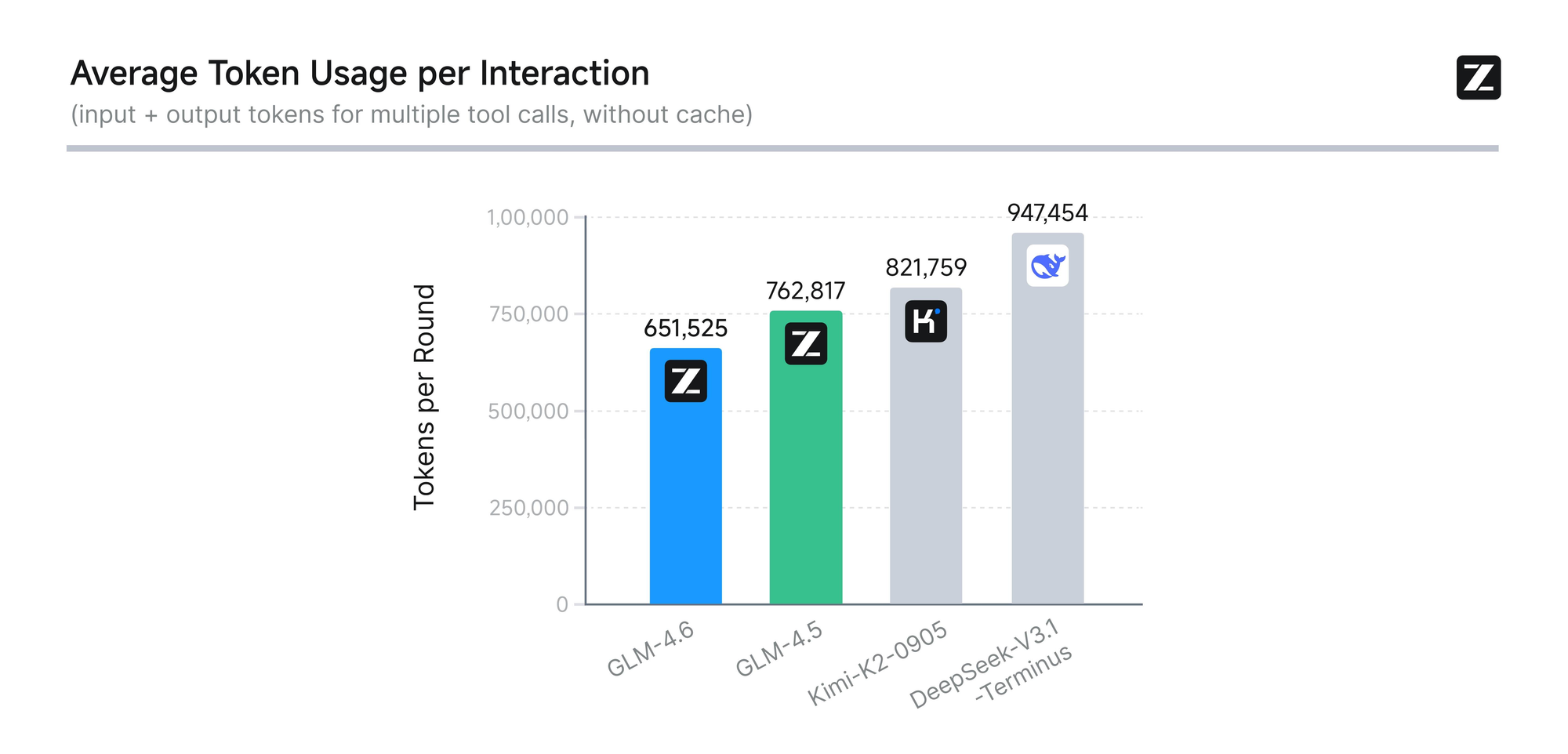
Model ini menjalani evaluasi ketat di delapan tolok ukur otoritatif, termasuk AIME 25, GPQA, LCB v6, HLE, dan SWE-Bench Verified. Hasil menunjukkan bahwa GLM-4.6 berkinerja setara dengan model terkemuka seperti Claude Sonnet 4 dan 4.6. Misalnya, dalam tes pengkodean dunia nyata yang dilakukan di lingkungan Claude Code, GLM-4.6 mengungguli pesaing dalam 74 skenario praktis. Ini dicapai dengan efisiensi lebih dari 30% dalam konsumsi token, mengurangi biaya operasional untuk pengguna bervolume tinggi.
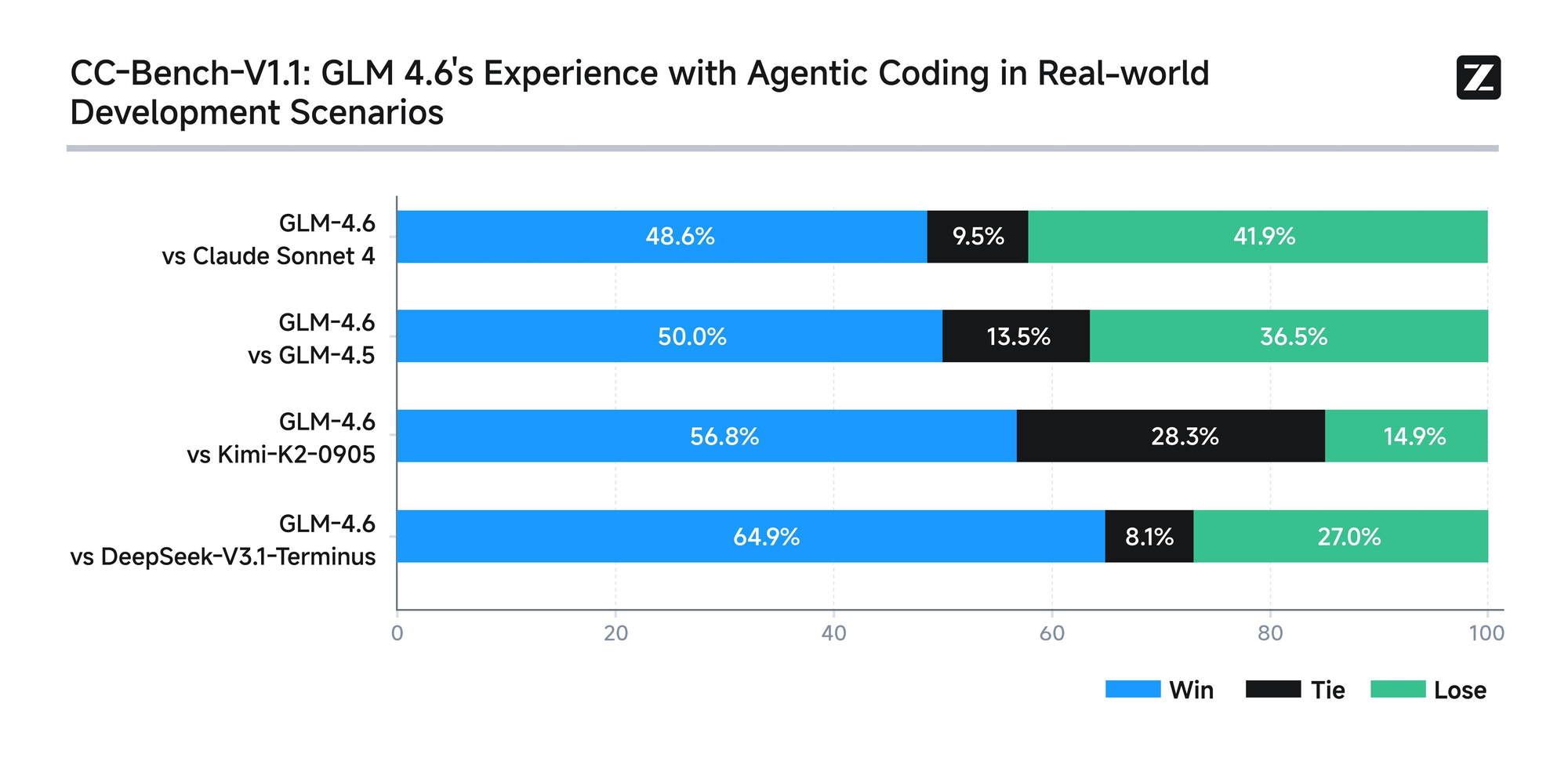
Selain itu, Zhipu AI berkomitmen terhadap transparansi dengan merilis semua pertanyaan tes dan lintasan agen secara publik. Praktik ini memungkinkan pengembang untuk memverifikasi klaim dan mereproduksi hasil, menumbuhkan kepercayaan pada teknologi. GLM-4.6 juga mengintegrasikan kemampuan penalaran canggih, mendukung penggunaan alat selama inferensi. Fitur ini meningkatkan utilitasnya dalam kerangka kerja agen, di mana model secara otonom merencanakan dan melaksanakan tugas.
Di luar pengkodean, GLM-4.6 bersinar di domain lain. Ini menyempurnakan penulisan agar selaras dengan preferensi manusia, meningkatkan gaya, keterbacaan, dan keaslian permainan peran. Dalam tugas terjemahan, model ini dioptimalkan untuk bahasa minoritas seperti Prancis, Rusia, Jepang, dan Korea, memastikan koherensi semantik dalam konteks informal. Pembuat konten menggunakannya untuk novel, skrip, dan penulisan iklan, memanfaatkan perluasan kontekstual dan nuansa emosional.
Pengembangan karakter virtual mewakili kekuatan lain, karena GLM-4.6 mempertahankan nada yang konsisten di seluruh percakapan multi-giliran. Ini membuatnya ideal untuk AI sosial dan personifikasi merek. Dalam pencarian cerdas dan penelitian mendalam, model ini meningkatkan pemahaman maksud dan sintesis hasil, memberikan keluaran yang mendalam.
Secara keseluruhan, GLM-4.6 memberdayakan pengembang untuk membuat aplikasi yang lebih cerdas. Kombinasi pemrosesan konteks panjang, penggunaan token yang efisien, dan penerapan yang luas membedakannya dalam lanskap AI. Sekarang setelah kita memahami esensi model, kita beralih ke akses API-nya untuk implementasi praktis.
Cara Mengakses GLM-4.6 API
Zhipu AI menyediakan akses langsung ke GLM-4.6 API melalui platform terbuka mereka. Pengembang mulai dengan mendaftar akun di situs web Zhipu AI, khususnya di open.bigmodel.cn atau z.ai. Proses ini memerlukan verifikasi email atau nomor telepon untuk memastikan pendaftaran yang aman.
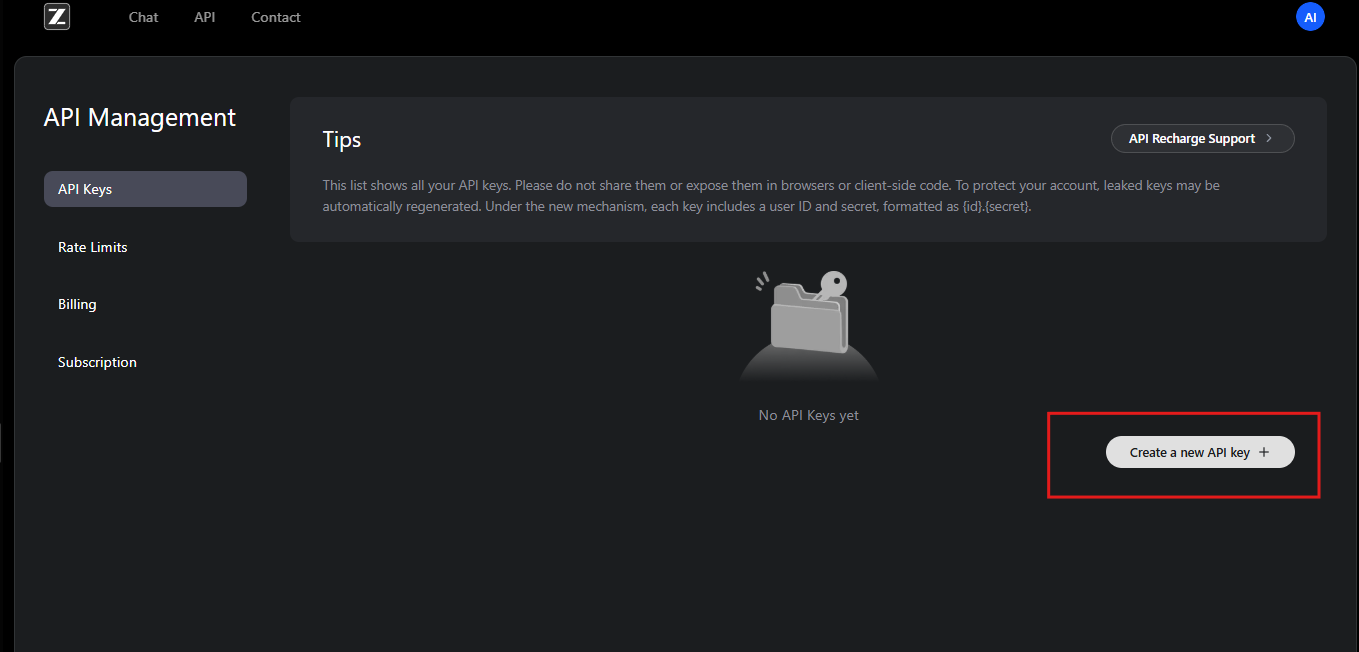
Setelah terdaftar, pengguna berlangganan GLM Coding Plan. Paket ini membuka GLM-4.6 dan model terkait. Pelanggan mendapatkan akses ke dasbor API, di mana mereka membuat kunci API. Kunci ini berfungsi sebagai kredensial untuk mengautentikasi permintaan.
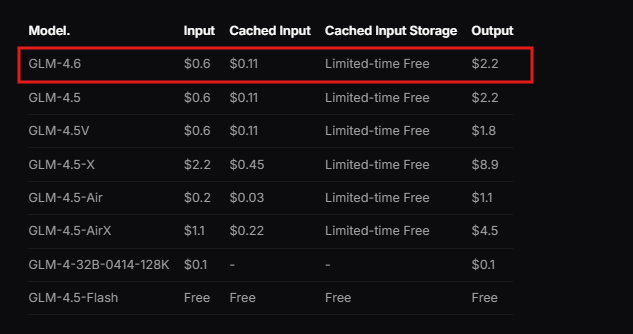
Selain itu, Zhipu AI menawarkan dokumentasi, yang merinci langkah-langkah integrasi. Pengembang meninjau sumber daya ini untuk memahami prasyarat, seperti lingkungan pemrograman yang kompatibel. API mengikuti desain RESTful, kompatibel dengan klien HTTP standar.
Untuk memulai, pengguna menavigasi ke bagian manajemen API di akun mereka. Di sini, mereka membuat kunci API baru dan mencatat nilainya dengan aman. Zhipu AI merekomendasikan untuk merotasi kunci secara berkala demi keamanan. Selain itu, platform ini menyediakan kuota penggunaan berdasarkan tingkatan langganan, mencegah penggunaan berlebihan.
Jika pengembang menghadapi masalah, tim dukungan Zhipu AI membantu melalui email atau forum. Mereka juga menawarkan sumber daya komunitas untuk memecahkan masalah akses umum. Dengan akses yang aman, langkah selanjutnya melibatkan pengaturan autentikasi untuk berinteraksi dengan GLM-4.6 API secara efektif.
Autentikasi dan Pengaturan untuk GLM-4.6 API
Autentikasi membentuk tulang punggung interaksi API yang aman. Zhipu AI menggunakan autentikasi token Bearer untuk GLM-4.6 API. Pengembang menyertakan kunci API di header Otorisasi setiap permintaan.
Untuk pengaturan, instal pustaka yang diperlukan di lingkungan pengembangan Anda. Pengguna Python, misalnya, menggunakan pustaka requests. Anda mengimpornya dan mengonfigurasi header sebagai berikut:
import requests
api_key = "kunci-api-anda"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
Kode ini menyiapkan lingkungan untuk mengirim permintaan. Demikian pula, dalam JavaScript dengan Node.js, pengembang menggunakan API fetch atau pustaka axios. Mereka mengatur header dalam objek opsi.
Selain itu, pastikan sistem Anda memenuhi persyaratan jaringan. Titik akhir GLM-4.6 API berada di https://api.z.ai/api/paas/v4/chat/completions. Uji konektivitas dengan melakukan ping domain atau mengirim permintaan sederhana.
Selama pengaturan, pengembang mengonfigurasi variabel lingkungan untuk menyimpan kunci API dengan aman. Praktik ini menghindari pengkodean informasi sensitif dalam skrip. Alat seperti dotenv di Python atau process.env di Node.js memfasilitasi hal ini.
Jika menggunakan proxy atau VPN, verifikasi bahwa itu memungkinkan lalu lintas ke server Zhipu AI. Kegagalan autentikasi sering kali berasal dari format kunci yang salah atau langganan yang kedaluwarsa. Zhipu AI mencatat kesalahan dalam respons, membantu mendiagnosis masalah.
Setelah diautentikasi, pengembang melanjutkan untuk menjelajahi titik akhir. Pengaturan ini memastikan akses yang andal dan aman ke kemampuan GLM-4.6.
Menjelajahi Titik Akhir GLM-4.6 API
GLM-4.6 API berpusat pada titik akhir utama untuk penyelesaian obrolan. Pengembang mengirim permintaan POST ke https://api.z.ai/api/paas/v4/chat/completions untuk menghasilkan respons.
Titik akhir ini menangani mode dasar dan streaming. Dalam mode dasar, server memproses seluruh permintaan dan mengembalikan respons lengkap. Mode streaming, bagaimanapun, memberikan keluaran secara bertahap, ideal untuk aplikasi real-time.
Untuk memanggil titik akhir, buat payload JSON dengan parameter yang diperlukan. Bidang model menentukan "glm-4.6". Array pesan berisi pasangan peran-konten, mensimulasikan percakapan.
Misalnya, permintaan curl dasar terlihat seperti ini:
curl -X POST "https://api.z.ai/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer kunci-api-anda" \
-d '{
"model": "glm-4.6",
"messages": [
{"role": "user", "content": "Hasilkan fungsi Python untuk mengurutkan daftar."}
]
}'
Server merespons dengan JSON yang berisi konten yang dihasilkan. Pengembang menguraikannya untuk mengekstrak pesan asisten.
Selain itu, titik akhir mendukung fitur-fitur canggih seperti langkah-langkah berpikir. Atur objek berpikir untuk mengaktifkan penalaran terperinci dalam keluaran.
Memahami titik akhir ini memungkinkan pengembang untuk membangun sistem AI interaktif. Selanjutnya, kita akan menguraikan parameter permintaan secara terperinci.
Penjelasan Rinci Parameter Permintaan GLM-4.6 API
Parameter permintaan mengontrol perilaku GLM-4.6 API. Parameter model mewajibkan "glm-4.6" untuk memilih versi spesifik ini.
Array pesan mendorong percakapan. Setiap objek mencakup peran – "user" untuk input, "assistant" untuk respons sebelumnya – dan konten sebagai string teks. Pengembang menyusun dialog multi-giliran dengan bergantian peran.
Selain itu, max_tokens membatasi panjang respons, mencegah keluaran yang berlebihan. Atur ke 4096 untuk hasil yang seimbang. Temperature menyesuaikan keacakan; nilai yang lebih rendah seperti 0.6 menghasilkan keluaran deterministik, sementara nilai yang lebih tinggi mendorong kreativitas.
Untuk streaming, sertakan "stream": true. Ini mengubah format respons menjadi data berpotongan.
Parameter thinking memungkinkan penalaran langkah demi langkah. Atur "thinking": {"type": "enabled"} untuk menyertakan pemikiran perantara dalam respons.
Parameter opsional lainnya termasuk top_p untuk pengambilan sampel inti dan presence_penalty untuk mencegah pengulangan. Pengembang menyesuaikan ini berdasarkan kasus penggunaan.
Parameter yang tidak valid memicu respons kesalahan dengan kode seperti 400 untuk permintaan yang buruk. Selalu validasi payload sebelum mengirim.
Dengan menguasai parameter ini, pengembang dapat menyesuaikan panggilan GLM-4.6 API untuk kinerja optimal.
Menangani Respons dari GLM-4.6 API
Respons dari GLM-4.6 API tiba dalam format JSON. Pengembang mengurai array pilihan untuk mengakses konten yang dihasilkan.
Dalam mode dasar, respons mencakup:
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1694123456,
"model": "glm-4.6",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Teks yang Anda hasilkan di sini."
},
"finish_reason": "stop"
}
]
}
Ekstrak bidang konten untuk digunakan dalam aplikasi.
Dalam mode streaming, respons mengalir sebagai Server-Sent Events (SSE). Setiap bagian mengikuti:
data: {"id":"chatcmpl-...","choices":[{"delta":{"content":" teks sebagian"}}]}
Pengembang mengumpulkan delta untuk membangun keluaran penuh.
Penanganan kesalahan melibatkan pemeriksaan kode status. Kode 401 menunjukkan kegagalan autentikasi, sementara 429 menandakan batas laju.
Catat respons untuk debugging. Pendekatan ini memastikan integrasi yang kuat dengan GLM-4.6 API.
Contoh Kode untuk Mengintegrasikan GLM-4.6 API
Pengembang mengimplementasikan GLM-4.6 API dalam berbagai bahasa. Dalam Python, gunakan requests untuk panggilan dasar:
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
payload = {
"model": "glm-4.6",
"messages": [{"role": "user", "content": "Jelaskan komputasi kuantum."}],
"max_tokens": 500,
"temperature": 0.7
}
headers = {
"Authorization": "Bearer kunci-api-anda",
"Content-Type": "application/json"
}
response = requests.post(url, data=json.dumps(payload), headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Kode ini mengirim kueri dan mencetak respons.
Dalam JavaScript dengan Node.js:
const fetch = require('node-fetch');
const url = 'https://api.z.ai/api/paas/v4/chat/completions';
const payload = {
model: 'glm-4.6',
messages: [{ role: 'user', content: 'Tulis haiku tentang AI.' }],
max_tokens: 100
};
const headers = {
'Authorization': 'Bearer kunci-api-anda',
'Content-Type': 'application/json'
};
fetch(url, {
method: 'POST',
body: JSON.stringify(payload),
headers
})
.then(res => res.json())
.then(data => console.log(data.choices[0].message.content));
Untuk streaming di Python, gunakan pustaka penguraian SSE seperti sseclient.
Contoh-contoh ini menunjukkan integrasi praktis, memungkinkan pengembang untuk membuat prototipe dengan cepat.
Menggunakan Apidog untuk Pengujian GLM-4.6 API
Apidog berfungsi sebagai alat yang sangat baik untuk menguji GLM-4.6 API. Platform all-in-one ini memungkinkan pengembang untuk merancang, men-debug, mengejek, dan mengotomatiskan interaksi API.
Mulai dengan mengunduh Apidog dari apidog.com dan membuat proyek. Impor titik akhir GLM-4.6 API dengan menambahkan API baru dengan URL https://api.z.ai/api/paas/v4/chat/completions.
Atur autentikasi di bagian header Apidog, tambahkan "Authorization: Bearer kunci-api-anda". Konfigurasikan badan permintaan dengan parameter JSON seperti model dan pesan.
Apidog memungkinkan pengiriman permintaan dan melihat respons dalam antarmuka yang ramah pengguna. Pengembang menguji variasi dengan menduplikasi permintaan dan menyesuaikan parameter.
Selain itu, otomatiskan pengujian dengan membuat skenario di Apidog. Tentukan pernyataan untuk memvalidasi konten respons, memastikan GLM-4.6 API berperilaku seperti yang diharapkan.
Server mock di Apidog mensimulasikan respons untuk pengembangan offline. Fitur ini mempercepat pembuatan prototipe tanpa panggilan API langsung.

Dengan menggabungkan Apidog, pengembang merampingkan alur kerja GLM-4.6 API, mengurangi kesalahan, dan mempercepat penerapan.
Praktik Terbaik dan Batas Laju untuk GLM-4.6 API
Mematuhi praktik terbaik memaksimalkan potensi GLM-4.6 API. Pengembang memantau penggunaan untuk tetap berada dalam batas laju, yang biasanya ditentukan oleh token per menit atau permintaan per hari berdasarkan langganan.
Terapkan exponential backoff untuk percobaan ulang pada kesalahan seperti 429. Ini mencegah server kewalahan.
Optimalkan prompt untuk kejelasan guna meningkatkan kualitas respons. Gunakan pesan sistem untuk mengatur konteks, membimbing model secara efektif.
Amankan kunci API di lingkungan produksi. Hindari mengeksposnya dalam kode sisi klien.
Catat interaksi untuk audit dan analisis kinerja. Data ini menginformasikan penyempurnaan.
Tangani kasus ekstrem, seperti respons kosong atau waktu habis, dengan mekanisme fallback.
Zhipu AI memperbarui batas laju dalam dokumentasi; periksa secara teratur.
Mengikuti praktik ini memastikan penggunaan GLM-4.6 API yang efisien dan andal.
Penggunaan Lanjutan GLM-4.6 API
Pengguna tingkat lanjut menjelajahi streaming untuk aplikasi interaktif. Atur "stream": true dan proses potongan secara real-time.
Gabungkan alat dengan menyertakan panggilan fungsi dalam pesan. GLM-4.6 mendukung pemanggilan alat, memungkinkan agen untuk melaksanakan tindakan eksternal.
Misalnya, definisikan alat dalam payload:
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Dapatkan cuaca saat ini",
"parameters": {...}
}
}
]
Model merespons dengan panggilan alat jika diperlukan.
Sesuaikan suhu untuk tugas-tugas tertentu; rendah untuk kueri faktual, tinggi untuk yang kreatif.
Gabungkan dengan konteks panjang untuk ringkasan dokumen. Masukkan teks besar dalam pesan.
Integrasikan ke dalam kerangka kerja agen seperti LangChain untuk alur kerja yang kompleks.
Teknik-teknik ini membuka potensi penuh GLM-4.6 dalam sistem yang canggih.
Kesimpulan
GLM-4.6 API menawarkan alat yang ampuh bagi pengembang untuk inovasi AI. Dengan mengikuti panduan ini, Anda dapat mengintegrasikannya dengan mulus ke dalam proyek. Bereksperimenlah dengan fitur-fitur, uji menggunakan Apidog, dan terapkan praktik terbaik untuk keberhasilan. Zhipu AI terus mengembangkan GLM-4.6, menjanjikan kemampuan yang lebih besar di masa depan.