
Les développeurs et les passionnés d'IA se tournent de plus en plus vers des modèles génératifs puissants comme Wan 2.2 pour créer des vidéos cinématographiques à partir d'entrées simples. Ce modèle se distingue par son architecture "Mixture-of-Experts" (MoE), qui augmente la capacité sans sacrifier la vitesse. En combinant l'API Wan 2.2 (avec LoRA), vous obtenez la capacité d'affiner les sorties pour des styles ou des mouvements spécifiques, ce qui la rend idéale pour la génération de vidéos personnalisées.
Qu'est-ce que Wan 2.2 ?
Wan 2.2 représente un modèle génératif vidéo avancé à grande échelle et open-source développé par l'équipe Wan. Les ingénieurs l'ont conçu pour gérer des tâches complexes telles que la génération de texte-vers-vidéo (T2V), d'image-vers-vidéo (I2V) et de parole-vers-vidéo (S2V). Le modèle utilise un cadre "Mixture-of-Experts" (MoE), qui divise le processus de débruitage dans les modèles de diffusion entre des experts spécialisés. Par exemple, les experts à bruit élevé gèrent les premières étapes temporelles, tandis que ceux à faible bruit affinent les étapes ultérieures. Cette approche aboutit à un total de 27 milliards de paramètres, avec seulement 14 milliards actifs par étape d'inférence, garantissant ainsi l'efficacité.
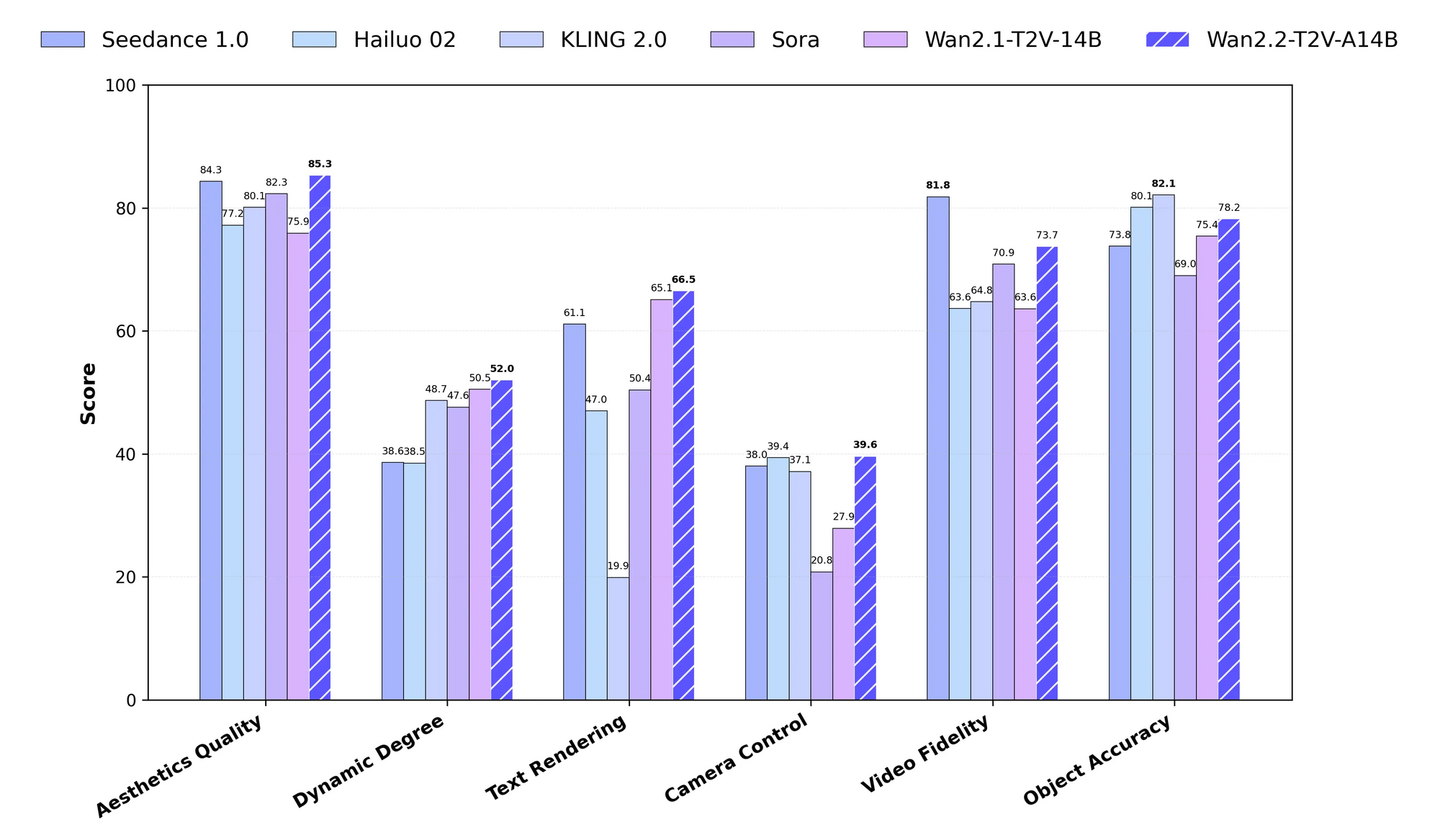
De plus, Wan 2.2 intègre une esthétique cinématographique grâce à des ensembles de données sélectionnés qui mettent l'accent sur l'éclairage, la composition et les tons de couleur. Les données d'entraînement s'étendent considérablement par rapport aux versions précédentes, incluant 65,6 % d'images et 83,2 % de vidéos en plus, ce qui améliore la complexité du mouvement et la compréhension sémantique. Vous avez accès à des variantes comme le modèle TI2V à 5 milliards de paramètres, qui génère des vidéos 720P à 24 FPS sur du matériel grand public comme une RTX 4090.
L'aspect API se manifeste principalement par des scripts comme generate.py dans le dépôt officiel, mais les plateformes hébergées l'étendent à des points d'accès basés sur le web. Par conséquent, vous choisissez entre l'exécution locale pour un contrôle total ou les services cloud pour l'évolutivité lorsque vous travaillez avec l'API Wan 2.2 (avec LoRA).
Qu'est-ce que LoRA dans le contexte de Wan 2.2 ?
LoRA, ou Low-Rank Adaptation, est une méthode de fine-tuning économe en paramètres pour les grands modèles comme Wan 2.2. Les développeurs appliquent LoRA pour adapter le modèle de base à des ensembles de données spécifiques sans réentraîner l'architecture entière. Dans Wan 2.2, LoRA cible les poids du transformeur, vous permettant d'injecter des styles, des personnages ou des mouvements personnalisés dans les générations de vidéos.
Par exemple, vous entraînez un LoRA sur un ensemble de données de prises de vue orbitales pour spécialiser la variante I2V dans la création de mouvements de caméra rotatifs. La documentation officielle met en garde contre l'utilisation de LoRA entraîné sur Wan 2.2 pour certaines tâches comme l'animation en raison d'une instabilité potentielle, mais les outils communautaires y remédient. Des plateformes comme fal.ai intègrent LoRA directement dans leur API, où vous spécifiez les chemins vers les poids LoRA et les facteurs d'échelle.
Par conséquent, l'intégration de LoRA dans l'API Wan 2.2 (avec LoRA) réduit les coûts d'entraînement et permet une personnalisation rapide. Vous fusionnez les adaptateurs LoRA au moment de l'inférence, préservant l'efficacité du modèle de base tout en obtenant des sorties ciblées.
Pourquoi utiliser l'API Wan 2.2 avec LoRA ?
Vous optez pour l'API Wan 2.2 (avec LoRA) pour équilibrer puissance et flexibilité dans les applications d'IA vidéo. Le fine-tuning traditionnel exige des ressources massives, mais LoRA minimise cela en ne mettant à jour que des matrices de faible rang. Cette méthode réduit l'utilisation de la mémoire et le temps d'entraînement, la rendant accessible aux développeurs individuels.
De plus, la structure MoE de Wan 2.2 complète LoRA en permettant des adaptations spécifiques aux experts. Vous générez des vidéos avec une esthétique ou des mouvements améliorés que les modèles de base peinent à produire. Par exemple, dans la création de contenu, vous utilisez LoRA pour maintenir des styles de personnages cohérents à travers les scènes.
Les API hébergées amplifient ces avantages en déchargeant le calcul vers le cloud. Des services comme fal.ai gèrent le gros du travail, vous permettant de vous concentrer sur les prompts et les paramètres. Par conséquent, cette combinaison convient au prototypage, à la production et à l'expérimentation, surtout lorsque vous intégrez des outils comme Apidog pour une gestion API fluide.
Comment configurer votre environnement pour l'utilisation locale de l'API Wan 2.2 ?
Vous commencez par cloner le dépôt Wan 2.2 depuis GitHub. Exécutez la commande git clone https://github.com/Wan-Video/Wan2.2.git dans votre terminal, puis naviguez dans le répertoire avec cd Wan2.2. Ensuite, installez les dépendances en utilisant pip install -r requirements.txt. Pour les tâches S2V, ajoutez pip install -r requirements_s2v.txt.
Assurez-vous que votre système exécute PyTorch version 2.4.0 ou supérieure. Vous installez également l'interface CLI de Hugging Face avec pip install "huggingface_hub[cli]" pour les téléchargements de modèles. Définissez les variables d'environnement si vous prévoyez d'utiliser l'extension de prompt, comme export DASH_API_KEY=your_key pour l'intégration de Dashscope.
Pour les configurations multi-GPU, configurez Fully Sharded Data Parallel (FSDP) et DeepSpeed Ulysses. Vous les activez avec des drapeaux comme --dit_fsdp et --ulysses_size 8. Les utilisateurs de GPU unique activent les optimisations de mémoire via --offload_model et --convert_model_dtype. Cette configuration vous prépare à exécuter le script generate.py, le cœur de l'API Wan 2.2 locale (avec LoRA).
Comment télécharger et installer les modèles Wan 2.2 ?
Vous téléchargez les modèles depuis Hugging Face ou ModelScope. Pour la variante T2V-A14B, utilisez huggingface-cli download Wan-AI/Wan2.2-T2V-A14B --local-dir ./Wan2.2-T2V-A14B. Répétez cette opération pour d'autres variantes comme I2V-A14B ou TI2V-5B.
Placez les checkpoints dans les répertoires appropriés. Les modèles 14B nécessitent une VRAM substantielle – environ 80 Go pour l'inférence multi-GPU – tandis que le TI2V 5B tient sur une carte de 24 Go. Après le téléchargement, vérifiez les fichiers pour éviter la corruption.
Si vous rencontrez des problèmes, passez aux miroirs ModelScope pour les régions avec des restrictions d'accès. Cette étape garantit que vous avez les modèles de base prêts avant d'appliquer les adaptateurs LoRA dans l'API Wan 2.2 (avec LoRA).
Comment utiliser le script generate.py pour les tâches de base dans Wan 2.2 ?
Vous invoquez le script generate.py pour effectuer des générations. Pour une tâche T2V simple sur un seul GPU, exécutez python generate.py --task t2v-A14B --size 1280x720 --ckpt_dir ./Wan2.2-T2V-A14B --offload_model True --convert_model_dtype --prompt "Deux chats anthropomorphes en tenue de boxe confortable se battent intensément sur une scène éclairée.".
Ajustez les paramètres pour d'autres modes. En I2V, ajoutez --image examples/i2v_input.JPG. Pour S2V, incluez --audio examples/audio_input.wav et activez la synthèse vocale (TTS) avec --enable_tts. L'exécution multi-GPU utilise torchrun --nproc_per_node=8 generate.py avec les drapeaux FSDP.
Ces commandes constituent l'épine dorsale de l'API Wan 2.2 locale (avec LoRA). Vous expérimentez avec les prompts et les tailles pour affiner les sorties, passant en douceur à l'intégration de LoRA pour des personnalisations avancées.
Comment entraîner un LoRA pour Wan 2.2 ?
Vous entraînez LoRA en utilisant des outils communautaires comme AI Toolkit ou les entraîneurs Trooper.AI. Tout d'abord, préparez votre ensemble de données — sélectionnez des vidéos ou des images alignées avec votre style cible. Pour un LoRA I2V, concentrez-vous sur des clips spécifiques au mouvement comme les prises de vue orbitales.
Configurez l'environnement d'entraînement sur des plateformes comme RunPod pour l'accès GPU. Chargez les poids de base de Wan 2.2 dans les répertoires attendus. Configurez les hyperparamètres : définissez le taux d'apprentissage à 1e-5, la taille du lot à 1 et les époques à 10-20 selon la taille de l'ensemble de données.
Exécutez le script d'entraînement, en surveillant les métriques de perte. Des outils comme la bibliothèque PEFT de Hugging Face facilitent cela, vous permettant de sauvegarder le LoRA sous forme de fichier .safetensors. Une fois entraîné, vous appliquez cet adaptateur dans les générations, améliorant l'API Wan 2.2 (avec LoRA) pour les tâches spécialisées.
Comment appliquer LoRA dans la génération locale de Wan 2.2 ?
Vous intégrez LoRA dans les configurations locales via ComfyUI ou des scripts personnalisés. Dans ComfyUI, utilisez le nœud LoadLoRAModelOnly entre le chargeur de modèle et l'échantillonneur. Spécifiez le chemin et la force de LoRA (par exemple, 0.8).
Pour generate.py, les forks communautaires ou les extensions ajoutent le support LoRA, car la version officielle manque d'intégration directe. Alternativement, utilisez le pipeline Diffusers pour les modes d'animation, en chargeant LoRA avec pipe.load_lora_weights("path/to/lora").
Cette application transforme les sorties standard en vidéos personnalisées. Par conséquent, vous obtenez une cohérence dans les styles ou les mouvements, rendant l'API Wan 2.2 (avec LoRA) plus polyvalente pour une utilisation en production.
Quels sont les meilleurs services hébergés pour l'API Wan 2.2 avec LoRA ?
Vous accédez à l'API Wan 2.2 hébergée (avec LoRA) via des plateformes comme fal.ai. Leur point d'accès à https://api.fal.ai/v1/fal-ai/wan/v2.2-a14b/text-to-video/lora prend en charge LoRA nativement. Inscrivez-vous pour obtenir une clé API et configurez-la dans votre client.
D'autres services incluent WaveSpeed.ai pour LoRA I2V et Trooper.AI pour l'entraînement. Ceux-ci éliminent le besoin de matériel local, s'adaptant sans effort aux hautes résolutions. Par conséquent, vous prototypez plus rapidement, en vous intégrant à des outils comme Apidog pour la gestion des requêtes.
Comment s'authentifier et envoyer des requêtes à l'API fal.ai Wan 2.2 ?
Vous vous authentifiez en définissant la variable d'environnement FAL_KEY. Installez le client fal-ai avec npm install --save @fal-ai/client pour JavaScript, ou utilisez des équivalents Python.
Envoyez une requête POST avec une charge utile JSON incluant prompt et un tableau loras. Par exemple : {"prompt": "Une ville cyberpunk la nuit", "loras": [{"path": "https://example.com/loras/cyberpunk.safetensors", "scale": 0.8}]}.
Surveillez les réponses pour les URL de vidéo. Ce processus exploite l'API Wan 2.2 (avec LoRA) dans des environnements cloud, garantissant des performances fiables.
Comment utiliser Apidog pour tester l'API Wan 2.2 avec LoRA ?
Vous commencez par installer Apidog et créer un nouveau projet API. Importez les détails du point d'accès fal.ai, en définissant la méthode sur POST et l'URL sur le chemin LoRA texte-vers-vidéo.
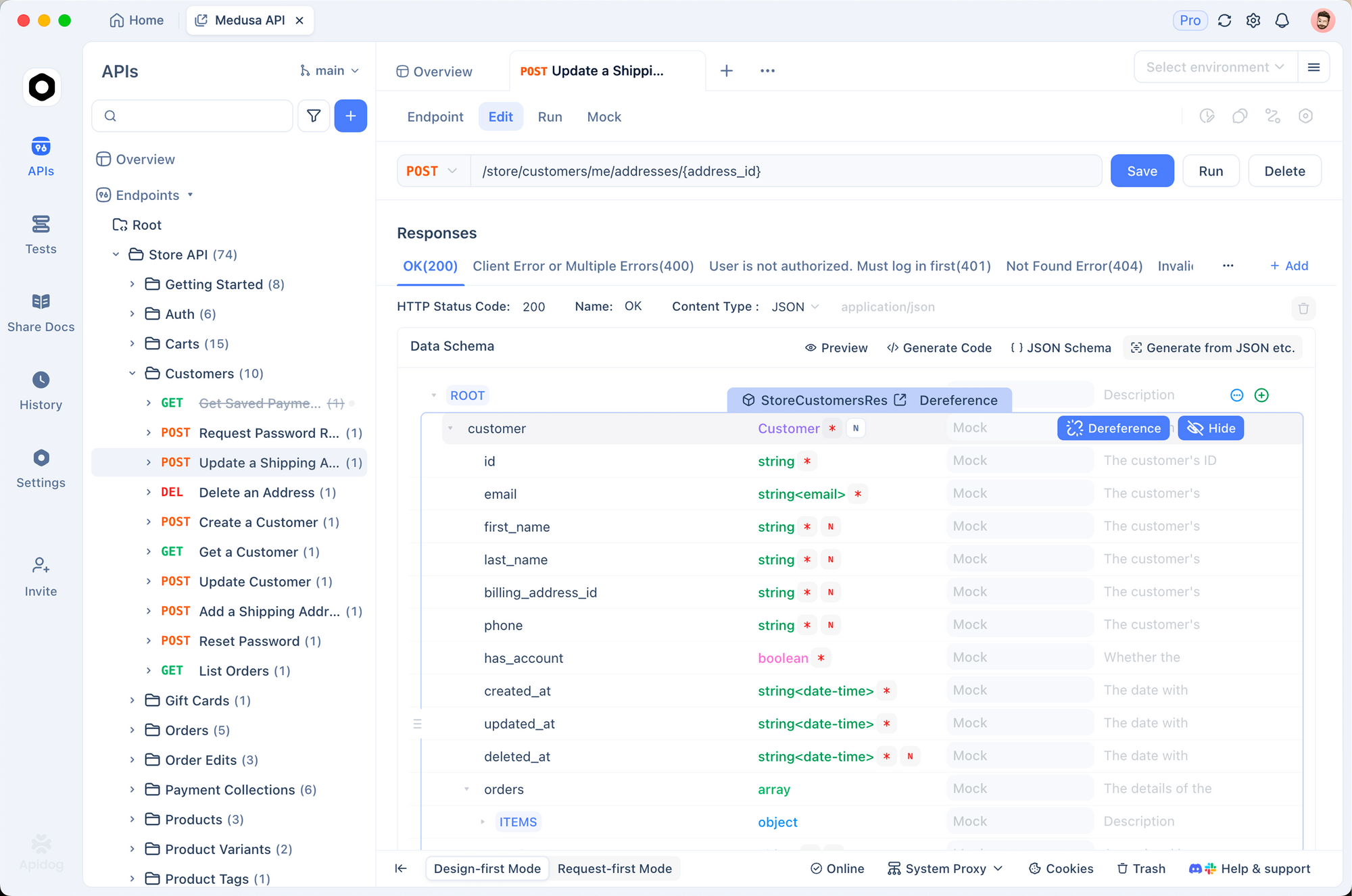
Ajoutez des en-têtes pour l'authentification, tels que Authorization: Key votre_clé_fal. Dans l'onglet corps, construisez un JSON avec le prompt et les paramètres LoRA. Envoyez la requête et inspectez la réponse, qui inclut le lien vidéo généré.
Les fonctionnalités d'Apidog, telles que les variables d'environnement et la validation des réponses, simplifient le débogage. Par exemple, vous enregistrez les configurations LoRA courantes en tant que collections. Ainsi, Apidog améliore votre flux de travail lors du test de l'API Wan 2.2 (avec LoRA), permettant des itérations rapides.
Quels paramètres devez-vous ajuster dans l'API Wan 2.2 avec LoRA ?
Vous ajustez les paramètres clés pour optimiser les sorties. Définissez num_inference_steps à 27 pour un bon équilibre, ou plus haut pour la qualité. Les échelles de guidance comme 3.5 influencent l'adhérence aux prompts.
Pour LoRA, ajustez le scale entre 0.5 et 1.0 pour contrôler la force de l'adaptateur. Les options de résolution incluent 720p, tandis que les FPS varient de 4 à 60. Activez l'accélération pour des générations plus rapides, bien que cela puisse réduire la fidélité.
De plus, utilisez des prompts négatifs pour éviter les éléments indésirables. Ces ajustements affinent l'API Wan 2.2 (avec LoRA), l'adaptant aux besoins spécifiques du projet.
Comment gérer les entrées multimodales dans Wan 2.2 avec LoRA ?
Vous incorporez des images ou de l'audio en spécifiant --image ou --audio dans les scripts locaux, ou les champs équivalents dans les API hébergées. Appliquez LoRA pour les améliorer, par exemple en stylisant les sorties I2V.
Dans fal.ai, ajoutez image_url pour les modes TI2V. LoRA adapte la fusion, garantissant des vidéos cohérentes. Par conséquent, vous créez du contenu dynamique comme des personnages animés, en exploitant tout le potentiel de l'API Wan 2.2 (avec LoRA).
Quelles sont les techniques d'optimisation avancées pour l'inférence Wan 2.2 ?
Vous utilisez des optimisations de mémoire comme le déchargement de modèle (model offloading) et la conversion de type de données (dtype conversion) pour fonctionner sur du matériel limité. Pour le multi-GPU, FSDP distribue les sharding efficacement.
Dans les configurations hébergées, mettez en file d'attente les requêtes asynchrones pour gérer les lots. Utilisez l'expansion de prompt avec des LLM pour enrichir les entrées. Ces techniques accélèrent l'API Wan 2.2 (avec LoRA), la rendant adaptée aux applications en temps réel.
Comment intégrer l'API Wan 2.2 avec LoRA dans des applications ?
Vous construisez des applications en encapsulant les appels API dans des services backend. Par exemple, créez un serveur Node.js qui proxy les requêtes fal.ai, ajoutant LoRA en fonction des entrées de l'utilisateur.
Gérez les webhooks pour les tâches de longue durée, informant les utilisateurs une fois terminées. Intégrez avec des frontends pour la génération vidéo interactive. Cette intégration ancre l'API Wan 2.2 (avec LoRA) dans des outils comme les plateformes de contenu.
Quels exemples démontrent Wan 2.2 avec LoRA en action ?
Imaginez générer une scène cyberpunk : utilisez le prompt "Rues éclairées au néon avec des voitures volantes" et un LoRA entraîné sur de l'art dystopique. Le résultat produit des vidéos stylisées avec des détails améliorés.
Autre exemple : entraînez LoRA sur des mouvements de danse pour S2V, synchronisant l'audio avec la chorégraphie. Ces cas illustrent les utilisations pratiques de l'API Wan 2.2 (avec LoRA).
Comment résoudre les problèmes courants avec l'API Wan 2.2 et LoRA ?
Vous résolvez les erreurs de manque de mémoire en activant les drapeaux de déchargement (offload flags) ou en réduisant la résolution. Si LoRA provoque une instabilité, baissez les échelles ou réentraînez avec des ensembles de données stables.
Pour les échecs d'API, vérifiez l'authentification et la validité des paramètres dans Apidog. Les problèmes réseau nécessitent une logique de réessai. Ainsi, vous résolvez les problèmes efficacement, en maintenant des opérations fluides avec l'API Wan 2.2 (avec LoRA).
Quels développements futurs pourraient impacter Wan 2.2 avec LoRA ?
Les chercheurs continuent de faire progresser les modèles de diffusion, intégrant potentiellement des variantes LoRA plus efficaces. Les contributions de la communauté pourraient ajouter un support LoRA natif aux scripts officiels.
Les services hébergés pourraient étendre les modalités. Rester à jour vous assure de tirer parti des évolutions de l'API Wan 2.2 (avec LoRA).
Conclusion
Vous possédez désormais une compréhension approfondie de l'accès et de l'utilisation de l'API Wan 2.2 (avec LoRA). Des configurations locales aux API hébergées, et avec des outils comme Apidog, vous générez des vidéos impressionnantes. Appliquez ces techniques pour innover dans la création de contenu pilotée par l'IA.