
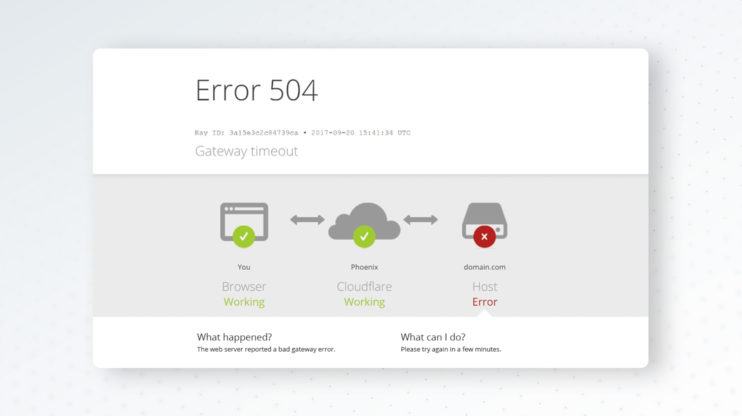
Vous naviguez sur un site web, et au lieu de voir la page se charger, vous fixez un message indiquant "504 Gateway Timeout". Le petit cercle de chargement tourne depuis ce qui semble être une éternité. Vous actualisez la page, mais la même erreur apparaît. Le site web n'est pas techniquement "hors ligne", mais quelque chose dans son infrastructure a cessé d'attendre une réponse.
Cette expérience frustrante est causée par l'une des erreurs côté serveur les plus courantes sur le web moderne : le code de statut 504 Gateway Timeout.
Contrairement aux erreurs côté client comme 404 Not Found, qui sont généralement la "faute" de l'utilisateur, ou aux erreurs côté serveur comme 500 Internal Server Error, qui se produisent à l'intérieur de l'application, le 504 est une rupture de communication entre serveurs. C'est l'équivalent numérique d'un intermédiaire qui lève les bras en disant : "J'ai attendu trop longtemps la personne à qui vous voulez vraiment parler, et j'abandonne."
Mais qu'est-ce que le code de statut HTTP 504 : Gateway Timeout exactement, et pourquoi se produit-il ? Plus important encore, comment pouvez-vous le corriger ou l'empêcher d'apparaître dans votre application, API ou site web ?
Si vous êtes développeur, administrateur système ou simplement un utilisateur web curieux, comprendre ce qui cause une erreur 504 et comment la corriger est incroyablement précieux.
Nous couvrirons tout cela en détail, de la signification de ce code aux causes courantes et aux solutions pratiques.
Explorons maintenant ce qui se passe en coulisses lorsque vous rencontrez un 504 Gateway Timeout.
L'architecture web moderne : il n'y a jamais un seul serveur
Pour comprendre le 504, nous devons comprendre comment les sites web et applications modernes sont construits. Très peu d'applications fonctionnent encore sur un seul serveur. La plupart utilisent une architecture multi-niveaux qui ressemble à ceci :
- Navigateur de l'utilisateur : Effectue la requête initiale.
- Équilibreur de charge / Proxy inverse : Distribue le trafic à plusieurs serveurs backend (par exemple, NGINX, HAProxy, AWS ALB).
- Serveurs web/d'application : Exécutent le code d'application réel (par exemple, Node.js, Python/Django, PHP).
- Services backend / API : Gèrent des tâches spécifiques comme l'authentification, les paiements ou le traitement des données (souvent des microservices).
- Base de données / Cache : Stockent et récupèrent les données.
L'erreur 504 se produit généralement entre les étapes 2 et 3, ou entre les étapes 3 et 4. Le "gateway" (passerelle) dans "Gateway Timeout" fait référence au serveur agissant comme intermédiaire, l'équilibreur de charge ou le proxy inverse.
Que signifie réellement le HTTP 504 Gateway Timeout ?
Le code de statut 504 Gateway Timeout indique qu'un serveur agissant comme passerelle ou proxy n'a pas reçu de réponse en temps voulu d'un serveur en amont auquel il devait accéder pour compléter la requête.
En termes plus simples : "Moi (la passerelle) j'ai demandé de l'aide à un autre serveur, mais ce serveur a mis trop de temps à me répondre, alors j'abandonne et je vous dis qu'il y a un problème."
Une réponse 504 typique est assez minimale :
HTTP/1.1 504 Gateway TimeoutContent-Type: text/htmlContent-Length: 125
<html><head><title>504 Gateway Timeout</title></head><body><center><h1>504 Gateway Timeout</h1></center></body></html>
Contrairement à d'autres erreurs, il n'y a généralement pas de corps de réponse personnalisé car la passerelle elle-même est souvent une pièce d'infrastructure simple qui ne sait pas comment générer des pages d'erreur sophistiquées.
Pensez-y de cette façon :
Vous demandez à votre ami de vérifier si un restaurant est ouvert. Votre ami appelle le restaurant, mais personne ne répond. Après avoir attendu un moment, votre ami vous dit :
« Désolé, ils n'ont pas répondu, j'ai eu un timeout. »
C'est exactement ce qui se passe avec un 504 Gateway Timeout.
La passerelle (généralement un proxy inverse comme NGINX ou un équilibreur de charge) essaie de se connecter à un serveur en amont (comme votre application web ou votre base de données). Si ce serveur en amont met trop de temps à répondre, la passerelle renvoie une 504 et annule la requête.
La chaîne de responsabilité : comment un 504 se produit
Examinons un exemple concret en utilisant une architecture e-commerce courante.
1. La Requête : Un utilisateur recherche un produit. Son navigateur envoie une requête à https://shop.example.com/search?q=laptop.
2. Le Rôle de l'Équilibreur de Charge : La requête atteint d'abord un équilibreur de charge (la passerelle). Le rôle de l'équilibreur de charge est de transmettre cette requête à l'un des plusieurs serveurs d'application disponibles. L'équilibreur de charge a un paramètre de délai d'attente de, disons, 30 secondes.
3. La Tâche du Serveur d'Application : Le serveur d'application reçoit la requête. Pour la satisfaire, il doit appeler deux autres services :
- Il appelle le Service de Recherche pour obtenir les résultats des produits.
- Il appelle le Service de Profil Utilisateur pour obtenir des recommandations personnalisées.
4. Le Problème : Le Service de Profil Utilisateur subit une charge élevée ou un blocage de base de données. Il se bloque et ne répond pas.
5. Le Délai d'Attente : Le serveur d'application attend... 25 secondes... 28 secondes... 29 secondes... L'équilibreur de charge, toujours en attente d'une réponse du serveur d'application, atteint sa limite de délai d'attente de 30 secondes.
6. La Réponse 504 : L'équilibreur de charge abandonne. Il ne peut pas renvoyer les résultats de la recherche car il ne les a jamais reçus du serveur d'application. Il renvoie donc un 504 Gateway Timeout au navigateur de l'utilisateur.
L'idée cruciale ici est que le serveur d'application pourrait encore fonctionner, essayant d'obtenir une réponse du Service de Profil Utilisateur. Mais l'équilibreur de charge a déjà annulé la requête de son point de vue.
Quand s'attendre à un 504
Les erreurs 504 sont les plus courantes dans les scénarios où :
- Votre application repose sur plusieurs services en aval ou microservices.
- Le service en amont est temporairement indisponible en raison de maintenance ou d'une charge élevée.
- Une API ou une base de données tierce est lente ou ne répond pas.
- Les chemins réseau subissent une latence transitoire ou une perte de paquets.
Étant donné que le 504 est généralement temporaire, les stratégies de réessai et les disjoncteurs entrent souvent en jeu dans le cadre d'un plan de résilience robuste.
Quand un 504 peut être acceptable
Il existe des cas légitimes où un délai d'attente de passerelle est attendu ou acceptable :
- Périodes de maintenance où les services en amont sont intentionnellement ralentis ou hors ligne.
- Pics de trafic temporaires que les services en amont ne peuvent pas absorber immédiatement.
- Problèmes de dépendance intermittents en cours de restauration ou d'atténuation.
Dans ces cas, une communication transparente et des politiques de réessai bien conçues aident à minimiser l'impact sur l'utilisateur.
Exemple concret d'un 504 Gateway Timeout
Imaginez que vous construisez un site web e-commerce. Votre processus de paiement appelle plusieurs API : paiement, inventaire, expédition et authentification utilisateur.
Maintenant, si l'API de paiement ralentit soudainement ou devient indisponible, votre serveur (qui agit comme une passerelle) attend une réponse. S'il n'en reçoit pas une dans la limite de temps impartie (disons, 30 secondes), il renvoie :
504 Gateway Timeout
Pour les utilisateurs, il semble que votre site web soit en panne. Mais techniquement, le problème réside dans la chaîne de communication entre les services.
504 vs. autres erreurs 5xx : connaître la différence
Il est facile de confondre les erreurs de serveur, mais chacune raconte une histoire différente sur ce qui a mal tourné.
504 Gateway Timeout vs. 502 Bad Gateway :
504signifie "Le serveur en amont a mis trop de temps à répondre." (Problème de délai d'attente)502signifie "Le serveur en amont m'a renvoyé quelque chose d'invalide ou d'incohérent." (La réponse était mal formée, ou la connexion a été entièrement refusée).
504 Gateway Timeout vs. 500 Internal Server Error :
504se produit au niveau de l'infrastructure entre les serveurs.500se produit au niveau de l'application à l'intérieur de votre code (par exemple, une exception non gérée dans votre code Python ou JavaScript).
504 Gateway Timeout vs. 408 Request Timeout :
504est un délai d'attente côté serveur : une passerelle a expiré en attendant un autre serveur.408est un délai d'attente côté client : un serveur a expiré en attendant que le client envoie la requête complète.
Causes courantes du 504 Gateway Timeout
Comprendre les causes est la première étape vers la prévention et la résolution.
1. Serveurs backend surchargés
C'est la cause la plus courante. Vos serveurs d'application peuvent être soumis à une forte charge, ce qui les amène à répondre lentement ou pas du tout. Cela pourrait être dû à :
- Un pic de trafic
- Des requêtes de base de données inefficaces
- Des ressources serveur insuffisantes (CPU, RAM)
2. Problèmes réseau
Des problèmes de connectivité entre votre passerelle et vos serveurs backend peuvent entraîner des délais d'attente.
- Congestion du réseau
- Règles de pare-feu bloquant le trafic
- Problèmes de résolution DNS
3. Opérations gourmandes en ressources
Certaines opérations prennent naturellement beaucoup de temps :
- Génération de rapports complexes
- Traitement de gros téléchargements de fichiers
- Exécution d'inférences d'apprentissage automatique
Si ces opérations dépassent le seuil de délai d'attente de votre passerelle, elles provoqueront des erreurs 504.
4. Dépendances de service
Si votre application dépend d'API externes ou de microservices lents ou en panne, votre serveur d'application les attendra, ce qui pourrait déclencher le délai d'attente de la passerelle.
5. Délais d'attente mal configurés
Parfois, les délais d'attente sont simplement réglés trop bas. Une passerelle peut avoir un délai d'attente de 10 secondes, mais une opération complexe légitime peut prendre 15 secondes.
Tester et déboguer les API avec Apidog
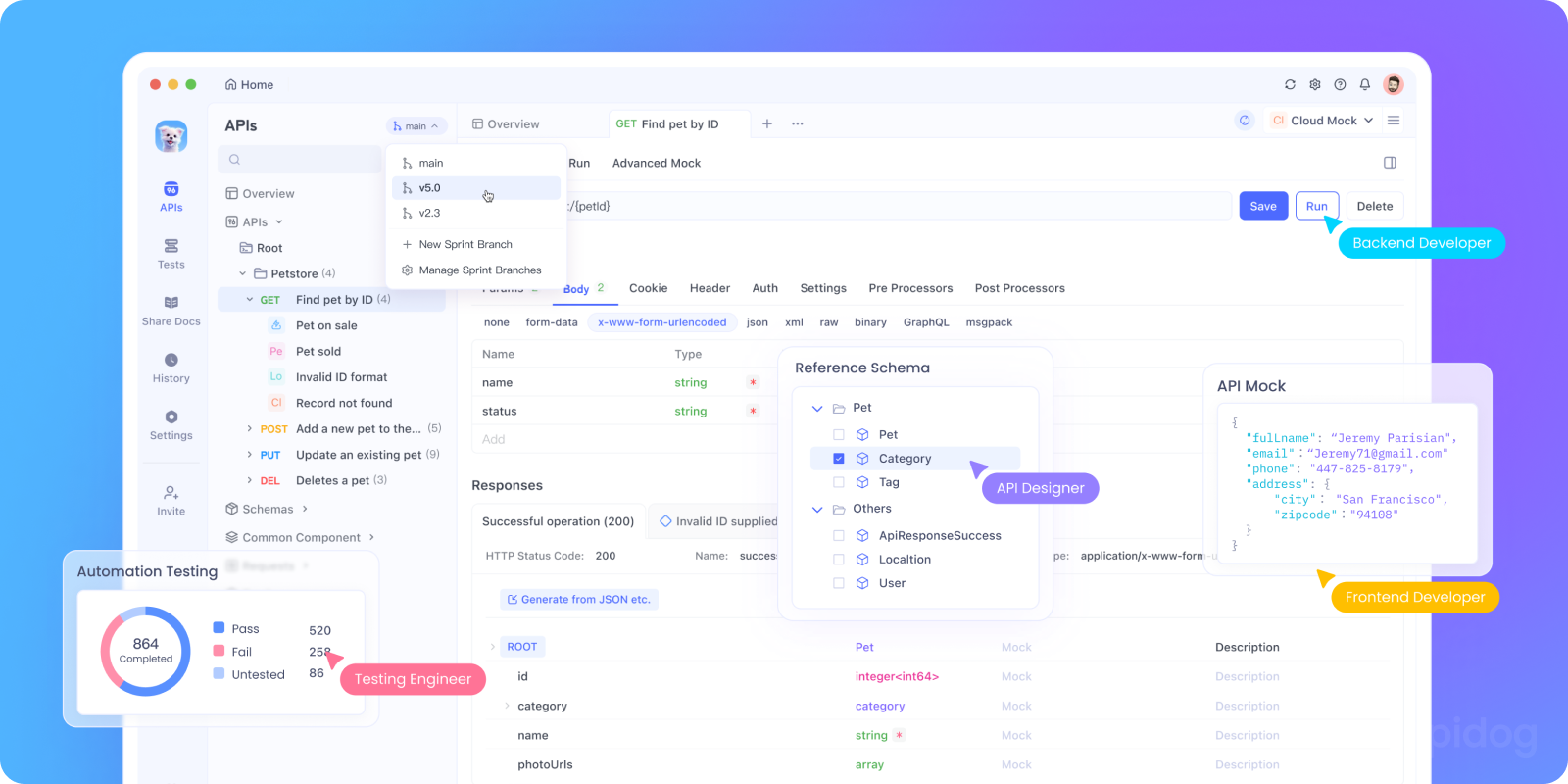
Identifier la cause première des erreurs 504 intermittentes peut être comme chercher une aiguille dans une botte de foin. Lors du débogage des 504, les développeurs ont souvent du mal à avoir une visibilité pour déterminer quel serveur, service ou requête est en cause. Apidog offre plusieurs fonctionnalités qui facilitent grandement cette tâche.
Avec Apidog, vous pouvez :
- Tests de Performance : Utilisez Apidog pour envoyer plusieurs requêtes concurrentes à votre API et mesurer les temps de réponse. Cela peut vous aider à identifier si certains endpoints sont lents sous charge, ce qui pourrait entraîner des 504.
- Mettre en Place la Surveillance : Créez des moniteurs automatisés dans Apidog qui vérifient périodiquement vos endpoints. Si une requête prend plus de temps qu'un seuil que vous avez défini (par exemple, 25 secondes lorsque votre délai d'attente de passerelle est de 30), Apidog peut vous alerter avant que les utilisateurs ne commencent à voir des 504.
- Tester les Dépendances de Service : Si votre API appelle d'autres services, utilisez Apidog pour tester ces dépendances indépendamment. Cela vous aide à isoler si le problème se situe dans votre application ou dans un service en aval.
- Simuler des Réponses Lentes : Utilisez les serveurs de maquette d'Apidog pour simuler des réponses backend lentes. Cela vous permet de tester comment votre passerelle et votre application gèrent les délais d'attente sans réellement surcharger votre système de production.
- Documenter les Attentes de Délai d'Attente : Utilisez les fonctionnalités de documentation d'Apidog pour noter quels endpoints sont censés être de longue durée, aidant ainsi votre équipe à définir des valeurs de délai d'attente appropriées dans l'infrastructure.
Et oui, vous pouvez télécharger Apidog gratuitement. Ce n'est pas juste une autre alternative à Postman, c'est un écosystème complet pour la conception, le test et la surveillance des performances des API.
Dépannage et correction des erreurs 504
Étapes immédiates :
- Vérifier les ressources du serveur : Examinez l'utilisation du CPU, de la mémoire et des E/S disque sur vos serveurs d'application.
- Examiner les journaux : Vérifiez les journaux de votre application et de votre passerelle pour détecter les erreurs survenues au moment des 504.
- Vérifier les dépendances externes : Assurez-vous que toutes les API ou services tiers utilisés par votre application sont sains.
Solutions à long terme :
- Optimiser les performances de l'application : Identifiez et corrigez les requêtes de base de données lentes, optimisez le code et implémentez la mise en cache.
- Ajuster les paramètres de délai d'attente : Augmentez les valeurs de délai d'attente sur votre passerelle si vous avez des opérations légitimes de longue durée.
- Implémenter des disjoncteurs : Utilisez des modèles qui arrêtent d'appeler un service défaillant après plusieurs échecs, empêchant ainsi les délais d'attente en cascade.
- Mettre à l'échelle votre infrastructure : Ajoutez plus de serveurs d'application ou passez à des instances plus puissantes.
- Implémenter le traitement asynchrone : Pour les tâches de longue durée, utilisez une file d'attente de tâches (comme Redis Queue ou AWS SQS) et renvoyez immédiatement un
202 Accepted, puis informez l'utilisateur lorsque la tâche est terminée.
Bonnes pratiques pour prévenir les erreurs 504 à long terme
Concluons la partie technique avec quelques stratégies préventives qui vous épargneront des maux de tête à l'avenir.
1. Utilisez la mise en cache partout où c'est possible
La mise en cache des réponses (au niveau de l'application, du CDN ou du proxy) réduit la charge du backend et le temps de réponse.
2. Optimisez les requêtes de base de données
Les requêtes SQL mal optimisées provoquent souvent des goulots d'étranglement au niveau du backend : ajustez les index et évitez les jointures volumineuses.
3. Surveillez la santé des API
Utilisez des outils comme Apidog, Datadog ou Pingdom pour surveiller en permanence la disponibilité et les performances des API.
4. Implémentez des disjoncteurs
Ajoutez un modèle de disjoncteur dans votre API pour interrompre temporairement les requêtes vers les services défaillants.
5. Mettez à l'échelle automatiquement
Utilisez l'auto-scaling dans les environnements cloud comme AWS ou Azure pour gérer les pics de trafic soudains.
6. Enregistrez tout
La journalisation centralisée vous aide à détecter les endpoints lents avant qu'ils ne deviennent des pannes complètes.
Le côté humain : la communication pendant les pannes
Une communication transparente pendant les délais d'attente de la passerelle est essentielle. Informez les utilisateurs lorsqu'un service subit des retards, offrez un délai de récupération estimé si possible et fournissez des mises à jour de statut. Un plan de réponse aux incidents bien géré réduit la frustration des utilisateurs et renforce la confiance.
Modèles architecturaux pour atténuer les problèmes de passerelle
- Service mesh avec politiques de timeout : Centraliser les configurations de timeout et la gestion des échecs.
- Timeouts par saut : Configurer des timeouts appropriés à chaque saut de la chaîne de requêtes pour éviter de longues attentes.
- Rétro-pression et mise en file d'attente : Mettre en tampon les requêtes pendant la congestion pour lisser les pics.
- Déploiements Canary : Déployer les changements progressivement pour réduire le risque de retards généralisés en amont.
- Upstreams redondants : Fournir des services alternatifs pour réduire les points de défaillance uniques.
Ces modèles vous aident à contenir l'impact des retards en amont et à maintenir une expérience utilisateur intacte.
Conclusion : Le prix des systèmes distribués
Le code de statut HTTP 504 Gateway Timeout est une conséquence naturelle de l'architecture web moderne et distribuée. Bien que frustrant pour les utilisateurs, il remplit un objectif important : empêcher les requêtes de rester en suspens indéfiniment et garantir que le système global reste réactif.
Comprendre qu'une erreur 504 est fondamentalement un problème de communication entre serveurs – et pas nécessairement un bug d'application – est la clé d'un dépannage efficace. En surveillant les performances, en optimisant les opérations lentes et en configurant correctement votre infrastructure, vous pouvez minimiser ces erreurs et offrir une meilleure expérience à vos utilisateurs.
La prochaine fois que vous verrez une erreur 504, vous saurez que c'est l'histoire d'un serveur passerelle patient qui a finalement dû abandonner l'attente. Et lorsque vous construisez les systèmes qui doivent éviter ces délais d'attente, un outil comme Apidog peut être votre meilleur allié pour identifier les goulots d'étranglement de performance et garantir que vos API répondent en temps voulu.