
Les développeurs recherchent des moyens efficaces d'intégrer des modèles de langage avancés dans leurs applications. INTELLECT-3 apparaît comme une option convaincante grâce à sa fondation open-source et ses solides performances dans les tâches de raisonnement. Ce modèle, développé par Prime Intellect, se distingue par son architecture de mélange d'experts (MoE) de 106 milliards de paramètres, qui permet une grande efficacité dans le traitement des calculs complexes.
Comprendre INTELLECT-3 : La puissance open-source
Prime Intellect publie INTELLECT-3 en tant que modèle entièrement open-source, ce qui permet aux chercheurs et développeurs de personnaliser et d'étendre ses capacités sans barrières propriétaires. Cette transparence favorise l'innovation dans des domaines tels que l'apprentissage par renforcement (RL) et les systèmes d'IA agentiques. Vous accédez au package complet, y compris les poids du modèle, les frameworks d'entraînement, les ensembles de données, les environnements RL et les outils d'évaluation, directement depuis les référentiels de Prime Intellect.

À la base, INTELLECT-3 utilise une architecture MoE de 106 milliards de paramètres, construite sur le modèle de base GLM-4.5-Air. Les conceptions MoE acheminent les entrées vers des sous-réseaux "experts" spécialisés, ce qui optimise l'utilisation du calcul et accélère l'inférence. Par exemple, pendant le traitement, le modèle n'active qu'un sous-ensemble de paramètres pertinents pour la requête, réduisant la latence tout en maintenant la précision. Cette configuration s'avère particulièrement efficace pour les tâches nécessitant une expertise sélective, telles que les dérivations mathématiques ou la génération de code.
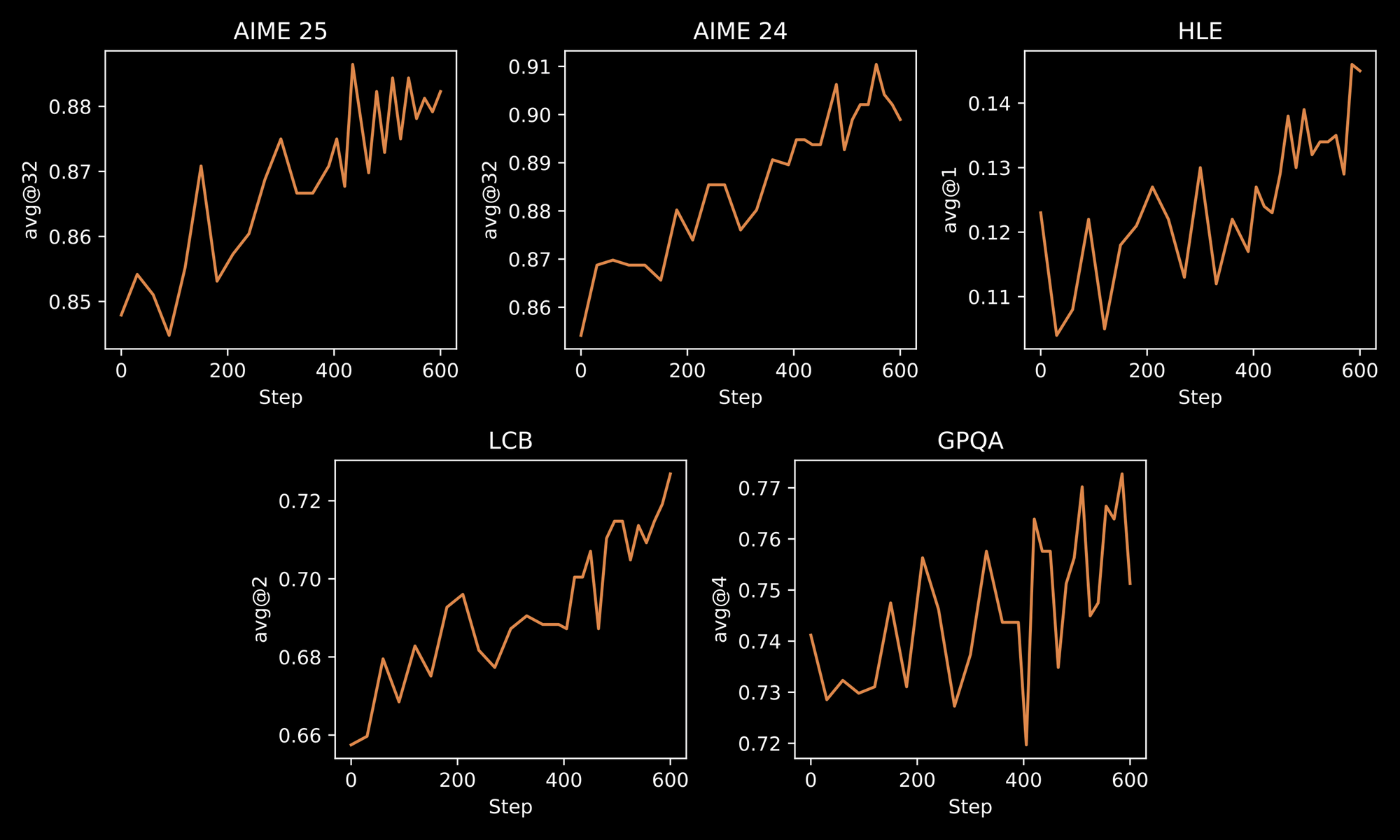
Le processus d'entraînement souligne la robustesse d'INTELLECT-3. Les ingénieurs appliquent une méthodologie en deux étapes : un affinage supervisé (SFT) initial sur des ensembles de données sélectionnés, suivi d'un RL à grande échelle utilisant le framework `prime-rl` personnalisé. `prime-rl` fonctionne comme un système RL asynchrone hors politique, qui gère efficacement de vastes simulations parallèles. Vous en bénéficiez grâce à des comportements de modèle améliorés dans des environnements dynamiques, tels que la résolution itérative de problèmes ou la planification multi-étapes.
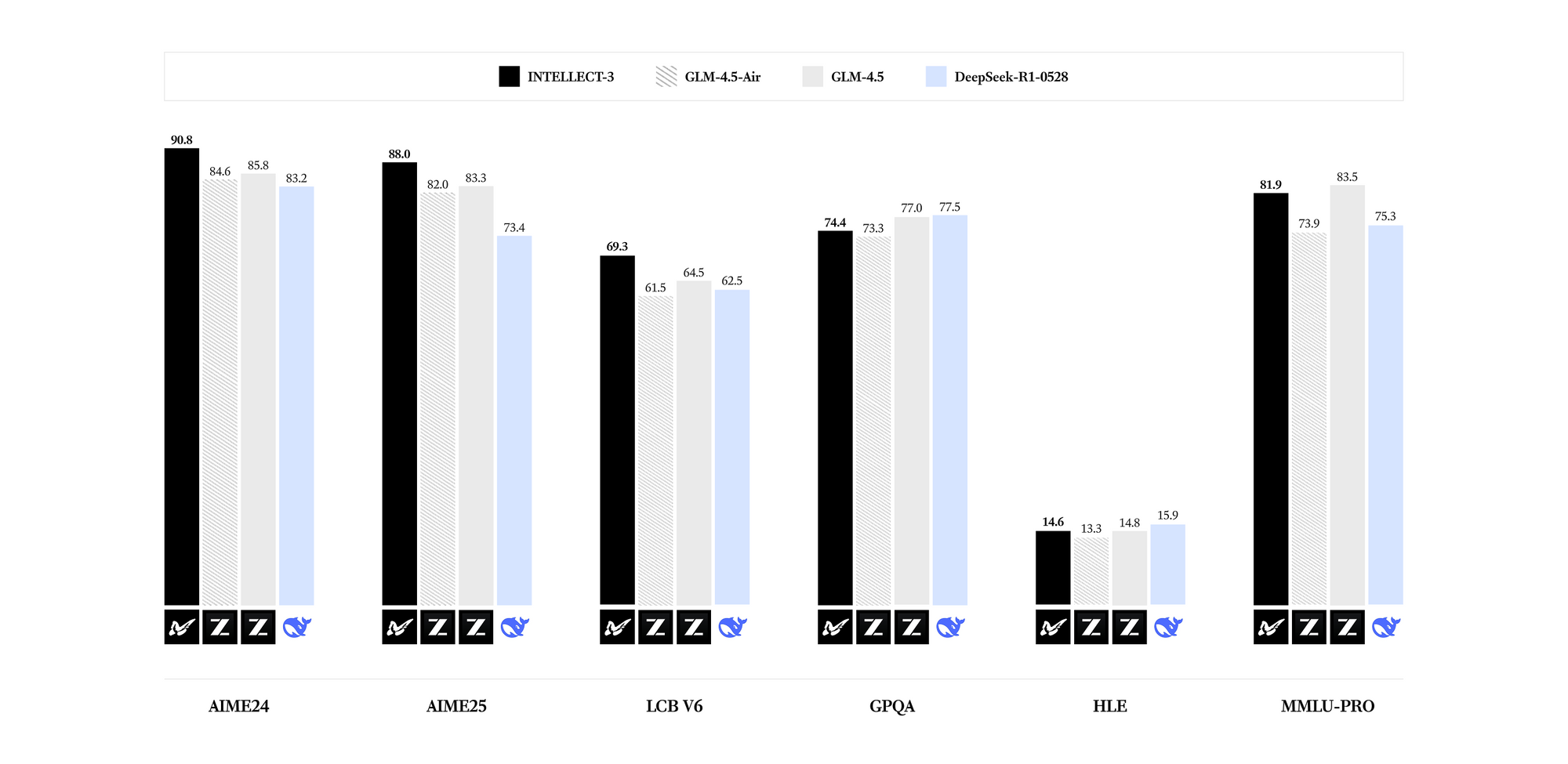
INTELLECT-3 excelle dans les domaines spécialisés. Les benchmarks révèlent des résultats de pointe pour son nombre de paramètres en mathématiques (par exemple, des scores GSM8K dépassant 95%), en codage (taux de réussite HumanEval supérieurs à 85%), en science (précision GPQA supérieure à 60%) et en raisonnement (scores MMLU proches de 80%). Comparé à des modèles plus denses comme Llama 3.1 70B, INTELLECT-3 atteint une efficacité supérieure – jusqu'à 2 fois plus rapide en inférence sur du matériel équivalent – grâce à ses schémas d'activation clairsemés. Par conséquent, vous le déployez dans des environnements à ressources contraintes sans sacrifier la qualité de sortie.
L'infrastructure de support renforce son attrait open-source. Le Verifiers & Environments Hub propose plus de 500 environnements RL, allant des puzzles simples aux prouveurs de théorèmes avancés.
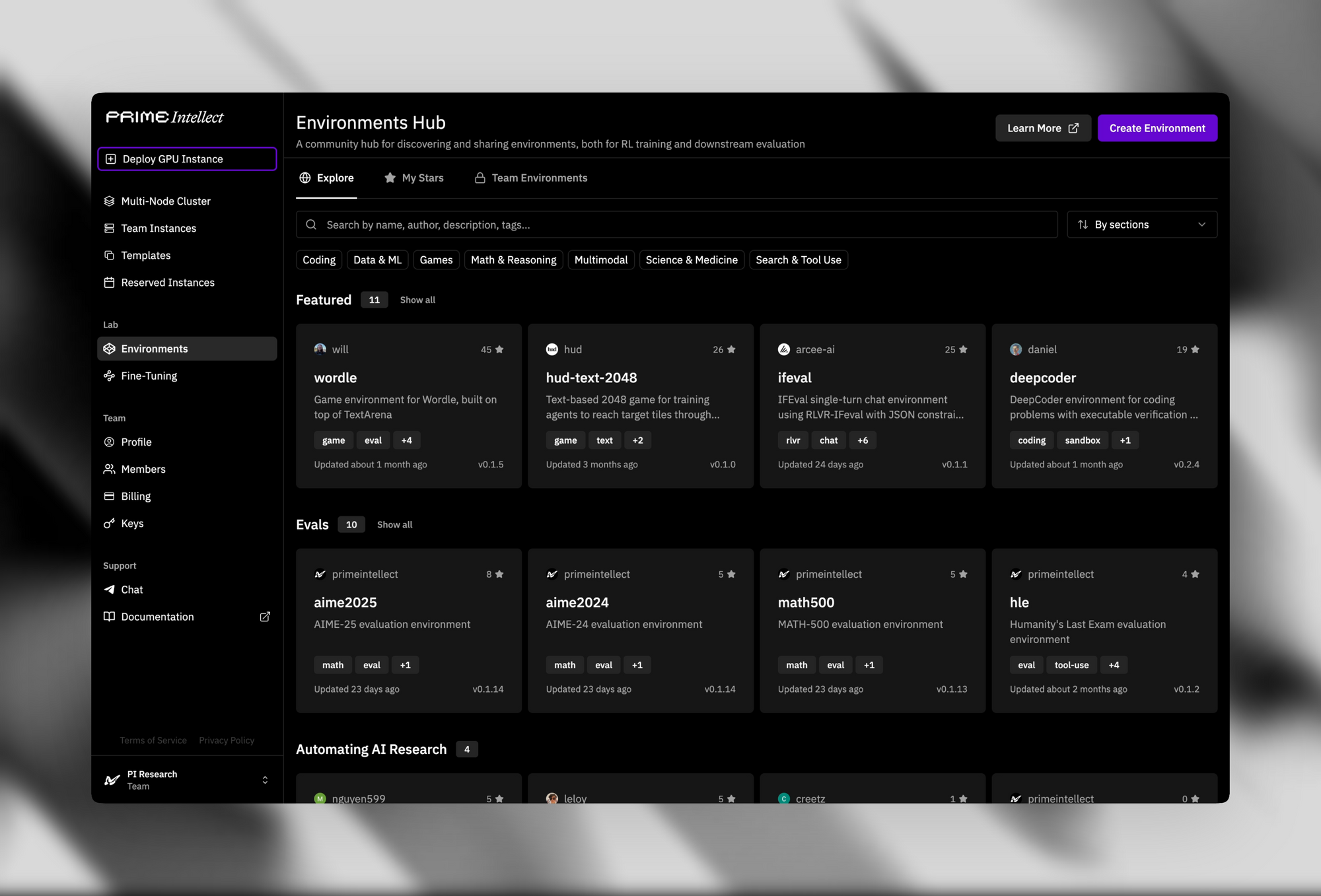
Les Prime Sandboxes offrent une exécution de code sécurisée et à haut débit, qui isole les actions des agents pendant l'entraînement ou l'inférence. Les développeurs exploitent ces outils pour affiner INTELLECT-3 pour des applications personnalisées, telles que des agents autonomes dans les pipelines de développement logiciel.
En pratique, vous téléchargez les poids du modèle via Hugging Face ou le GitHub de Prime Intellect. L'installation nécessite des dépendances standard comme PyTorch et la bibliothèque Transformers. Un script de base pour charger le modèle ressemble à ceci :
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
Ce code initialise le modèle sur du matériel compatible GPU. Cependant, pour une utilisation à l'échelle de la production, vous passez aux API hébergées, car l'auto-hébergement exige des ressources de calcul importantes (par exemple, plusieurs GPU A100). Ainsi, l'accès open-source jette les bases, mais l'intégration d'API met à l'échelle vos déploiements efficacement.
Passant de l'expérimentation locale, vous explorez maintenant comment accéder à INTELLECT-3 via des services gérés. Ce changement assure la fiabilité et gère les complexités de l'inférence distribuée.
Accéder à l'API INTELLECT-3 : Configuration et authentification
Option 1 – Point d'accès natif Prime Intellect (Recommandé pour des performances maximales et la latence la plus faible)
Vous commencez l'accès à l'API en obtenant des identifiants depuis la plateforme de Prime Intellect. Visitez le tableau de bord de Prime Intellect à l'adresse app.primeintellect.ai et créez un compte si nécessaire.
Une fois connecté, naviguez vers la section des clés API et générez une nouvelle clé avec les permissions d'inférence activées. Cette clé authentifie toutes les requêtes ultérieures, garantissant un accès sécurisé à INTELLECT-3.
Ensuite, configurez votre environnement. Définissez la clé API comme variable d'environnement pour une intégration transparente :
export PRIME_API_KEY="your-api-key-here"
Pour les workflows basés sur des équipes, incluez l'en-tête `X-Prime-Team-ID` dans les requêtes. Cet identifiant achemine l'utilisation vers le bon pool de facturation, évitant les frais inter-comptes. Vous récupérez l'ID de l'équipe depuis le tableau de bord sous les paramètres du compte.
L'API adopte une interface compatible OpenAI, ce qui simplifie son adoption si vous utilisez déjà des bibliothèques comme `openai-python`. Spécifiez l'URL de base comme `https://api.pinference.ai/api/v1`. Ce point d'accès relaie les requêtes vers des fournisseurs d'inférence optimisés, y compris Parasail et Nebius, qui hébergent des instances d'INTELLECT-3. En conséquence, vous obtenez des réponses à faible latence sans gérer les clusters sous-jacents.
Pour vérifier l'accès, interrogez le point d'accès des modèles. Cela liste les modèles disponibles, confirmant la présence d'INTELLECT-3 (généralement sous un identifiant comme `prime-intellect/intellect-3`). Utilisez l'outil CLI pour des vérifications rapides :
prime inference models
Alternativement, envoyez une requête GET via curl :
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
La réponse renvoie un tableau JSON d'objets modèles, chacun détaillant des paramètres comme `id`, `max_tokens` et `context_window`. INTELLECT-3 prend en charge un contexte de 128K tokens, ce qui permet des chaînes de raisonnement de longue durée.
L'authentification s'étend à la limitation de débit et aux quotas. Prime Intellect applique des limites par minute et quotidiennes en fonction de votre plan, visibles dans le tableau de bord. Vous surveillez l'utilisation via l'onglet Facturation, qui enregistre les tokens traités et les appels API effectués. Si les limites entravent votre workflow, effectuez une mise à niveau en toute transparence via la plateforme.
De plus, intégrez avec Apidog pour des tests améliorés. Importez le schéma OpenAI dans Apidog, puis simulez des requêtes vers les points d'accès INTELLECT-3. Cette pratique identifie les problèmes tôt, tels que les charges utiles JSON mal formées. Le niveau gratuit d'Apidog suffit pour les configurations initiales, faisant le pont entre le développement local et les API de production.
Une fois l'authentification en place, vous passez à la création de requêtes. La section suivante décrit les formats précis pour obtenir des réponses optimales d'INTELLECT-3.
Option 2 – OpenRouter (Accès instantané et crédits unifiés)
Outre l'auto-hébergement ou l'utilisation de la plateforme d'inférence native de Prime Intellect, INTELLECT-3 est également officiellement disponible sur OpenRouter. Cela vous offre une passerelle alternative avec une facturation unifiée, un routage de secours automatique et un accès instantané – aucun compte Prime Intellect séparé n'est requis si vous utilisez déjà OpenRouter.
- URL de base : https://openrouter.ai/api/v1
- Nom du modèle : prime-intellect/intellect-3
- Authentification : Votre clé API OpenRouter (OPENROUTER_API_KEY)
- Routage automatique du fournisseur (actuellement servi par les clusters Prime Intellect)
- Paiement à l'utilisation avec les crédits OpenRouter ; coût par token légèrement plus élevé en raison des frais de plateforme
Les deux points d'accès prennent en charge des schémas de requête/réponse identiques, le streaming, l'appel d'outils et le mode JSON.
Effectuer des requêtes à l'API INTELLECT-3 : Formats et exemples
Vous initiez les interactions via le point d'accès `/chat/completions`, qui gère les invites conversationnelles et orientées tâches. Construisez les requêtes comme des objets JSON avec des champs pour `model`, `messages`, `temperature` et `max_tokens`. Le tableau `messages` imite les historiques de chat, utilisant des rôles comme "system", "user" et "assistant".
Considérez un exemple de base pour la génération de code. Vous envoyez :
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
Ce code génère une implémentation récursive de Fibonacci avec mémoïsation, tirant parti de la puissance de codage d'INTELLECT-3. Le paramètre `temperature` contrôle la créativité – des valeurs plus basses (par exemple, 0.2) favorisent des sorties déterministes pour les requêtes factuelles, tandis que des valeurs plus élevées (jusqu'à 1.0) encouragent des chemins de raisonnement diversifiés.
Pour le raisonnement mathématique, vous structurez les invites pour enchaîner les pensées. La formation RL d'INTELLECT-3 brille ici, car elle simule une vérification étape par étape. Exemple :
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
Le modèle répond avec une preuve rigoureuse, citant axiomes et théorèmes. Vous analysez la sortie via `response.choices[0].message.content`, qui arrive sous forme de chaîne de caractères. Pour les données structurées, activez le mode JSON en ajoutant `"response_format": {"type": "json_object"}` à la requête, garantissant des réponses analysables.
L'utilisation avancée implique l'appel d'outils, où INTELLECT-3 intègre des fonctions externes. Définissez les outils dans la requête :
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
Si le modèle invoque l'outil, il renvoie des arguments dans `response.choices[0].message.tool_calls`. Vous exécutez la fonction en externe et renvoyez les résultats dans un message de suivi. Ce modèle construit des workflows agentiques, capitalisant sur les comportements d'INTELLECT-3 entraînés en environnement.
La gestion des erreurs est une partie essentielle. Les problèmes courants incluent 401 (clé invalide), 429 (limite de débit) et 400 (requête mal formée). Implémentez des tentatives avec un délai d'attente exponentiel :
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
Les réponses incluent des métadonnées comme `usage` (prompt_tokens, completion_tokens, total_tokens), que vous enregistrez pour l'optimisation. INTELLECT-3 traite jusqu'à 4096 tokens par complétion, équilibrant profondeur et vitesse.
Les réponses en streaming améliorent les applications en temps réel. Ajoutez `stream=True` à l'appel de création ; le client produit des fragments sous forme d'événements envoyés par le serveur. Analysez-les itérativement :
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Cette technique convient aux chatbots ou aux assistants de code en direct, où les utilisateurs attendent un retour incrémental.
Après avoir maîtrisé la création de requêtes, vous évaluez les performances. Le segment suivant présente des outils de benchmarking adaptés à INTELLECT-3.
Optimisation et évaluation de l'utilisation de l'API INTELLECT-3
Vous optimisez les appels API en ajustant les paramètres empiriquement. Commencez par regrouper plusieurs messages en une seule requête pour des gains de débit – jusqu'à 10x d'efficacité dans les suites d'évaluation. La CLI de Prime Intellect prend en charge cela :
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
Cette commande exécute 100 échantillons GSM8K, agrégeant les métriques de précision et de latence. Vous analysez les résultats pour ajuster `top_p` ou `frequency_penalty`, qui atténuent la répétition dans les longues générations.
L'évaluation s'étend aux environnements personnalisés du Verifiers Hub. Chargez un environnement RL et interrogez INTELLECT-3 comme politique :
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
Les récompenses quantifient les améliorations, guidant l'affinage si vous hébergez localement. Pour les utilisateurs uniquement API, enregistrez les interactions dans une base de données vectorielle et calculez des métriques en aval comme le taux de réussite des tâches.
Les considérations de sécurité sont également importantes. Nettoyez les entrées utilisateur pour prévenir l'injection d'invite, et utilisez des invites système pour appliquer des limites. Le background RL d'INTELLECT-3 réduit les hallucinations, mais vous validez les sorties par rapport aux vérificateurs pour les applications à enjeux élevés.
La mise à l'échelle implique une surveillance via le tableau de bord. Définissez des alertes pour les seuils de tokens et intégrez avec des outils d'observabilité comme Prometheus, que Prime Intellect expose pour les clusters. Ainsi, vous maintenez la fiabilité à mesure que l'utilisation augmente.
Maintenant que vous gérez l'optimisation, considérez les coûts. La transparence des prix assure une intégration durable.
Tarification de l'API INTELLECT-3 : Modèle transparent basé sur les tokens
Prime Intellect structure sa tarification autour de la consommation de tokens, facturant séparément l'entrée et la sortie. Vous payez par 1 000 tokens, avec des tarifs variant selon le modèle et le fournisseur. Pour INTELLECT-3, attendez-vous à des chiffres compétitifs – environ 0,50 $ par million de tokens d'entrée et 1,50 $ par million de sortie – bien que les valeurs exactes apparaissent dans la réponse du point d'accès des modèles.
| Fournisseur | Entrée ($$ /1M tokens) | Sortie ( $$/1M tokens) | Remarques |
|---|---|---|---|
| Prime Intellect Direct | ~0,45 $–0,60 $ | ~1,30 $–1,80 $ | Coût le plus bas, remises sur volume |
| OpenRouter | ~0,60 $–0,80 $ | ~1,80 $–2,40 $ | Inclut les frais de plateforme OpenRouter |
Les taux exacts fluctuent ; vérifiez toujours les dernières valeurs dans votre tableau de bord ou via le point d'accès des modèles.
Lequel choisir ?
- Choisissez Prime Intellect direct si vous voulez une vitesse maximale, un coût le plus bas ou prévoyez une utilisation à grand volume.
- Choisissez OpenRouter si vous préférez une seule clé API pour plus de 50 modèles, avez besoin d'une intégration instantanée ou souhaitez un routage de secours intégré.
Les deux options offrent les mêmes performances INTELLECT-3. Choisissez celle qui correspond à votre workflow – de nombreuses équipes utilisent même les deux simultanément pour la redondance.
Le reste de ce guide (formats de requête, streaming, appel d'outils, optimisation, etc.) s'applique de la même manière, que vous appeliez Prime Intellect directement ou via OpenRouter.
Poursuivez avec les détails complets de l'implémentation technique ci-dessous, et commencez à construire avec INTELLECT-3 dès aujourd'hui – via la passerelle qui vous convient le mieux.
Intégrations avancées avec l'API INTELLECT-3
Vous étendez INTELLECT-3 à des écosystèmes comme LangChain ou LlamaIndex pour l'orchestration. Dans LangChain :
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
Cela lie l'API aux pipelines de génération augmentée de récupération (RAG), améliorant la précision grâce aux connaissances externes.
Pour les microservices, déployez via des wrappers FastAPI qui proxyfient vers INTELLECT-3 :
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
Exposez ce point d'accès en toute sécurité, en limitant le débit avec Redis. De telles configurations alimentent des outils SaaS, des générateurs de contenu aux assistants de recherche.
Les cas limites exigent une attention particulière. Gérez les débordements de tokens en tronquant dynamiquement les entrées et revenez à des modèles plus petits si INTELLECT-3 est en file d'attente. Les forums communautaires sur le site de Prime Intellect proposent des fils de discussion sur le dépannage.
Conclusion : Déployez l'API INTELLECT-3 en toute confiance
Vous disposez désormais d'une boîte à outils complète pour l'utilisation de l'API INTELLECT-3. De ses origines open-source à la gestion précise des requêtes et des coûts, ce guide vous équipe pour les déploiements réels. Expérimentez avec Apidog pour affiner vos workflows et surveillez l'évolution de la documentation pour les mises à jour.
Mettez en œuvre ces techniques de manière incrémentale – commencez par de simples conversations, puis passez aux agents. L'efficacité et l'ouverture d'INTELLECT-3 le positionnent comme une référence pour les projets d'IA techniques. Commencez à coder dès aujourd'hui et constatez l'impact sur vos applications.